
1. Introducción
En este codelab, aprenderás a usar GKE Dynamic Slicing para optimizar el uso de los recursos de Cloud TPU. El corte dinámico es una capacidad potente que te permite desacoplar el aprovisionamiento de TPU sin procesar de la programación de cargas de trabajo.
En particular, explorarás dos patrones clave:
- Sub-slicing: Divide un bloque de TPU aprovisionado grande en porciones más pequeñas y aisladas para cargas de trabajo más pequeñas.
- Super-slicing: Une varios bloques de TPU aprovisionados para formar una porción virtual más grande para cargas de trabajo a gran escala.
Aplicarás estos patrones para implementar una arquitectura de Disaggregated Serving (Prefill/Decode disaggregation) de alto rendimiento para un modelo de lenguaje grande (Qwen 397B) con Kueue, LeaderWorkerSet (LWS) y la API de Gateway.
Arquitectura
Esta es la arquitectura de alto nivel de la configuración de TPU Dynamic Slicing y Disaggregated Serving:
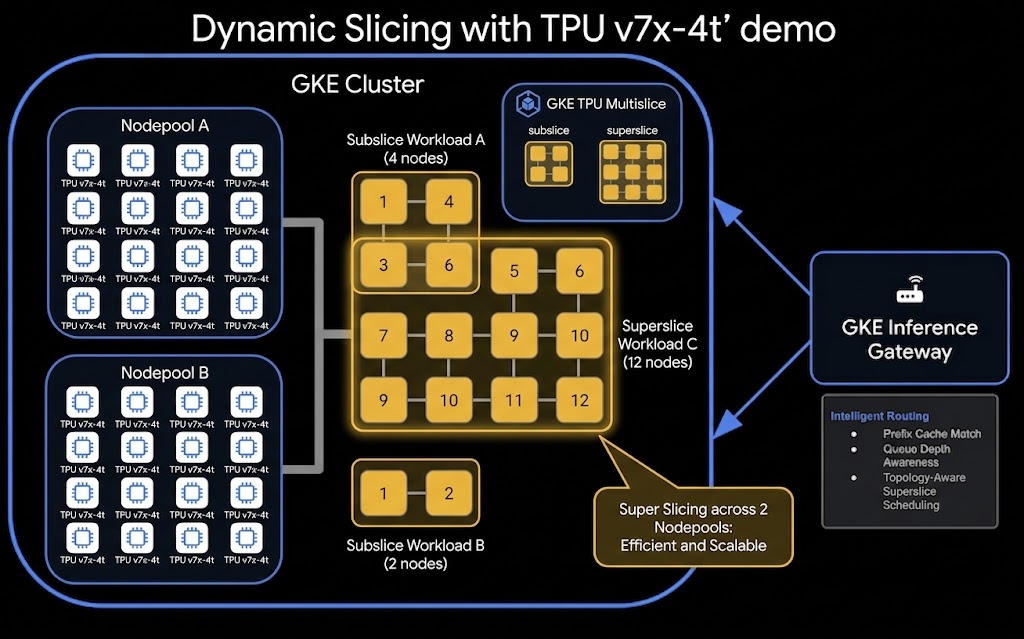
Actividades
- Aprovisiona un clúster de GKE con el controlador de porciones de GKE habilitado.
- Crea grupos de nodos TPU de GKE configurados para el aprovisionamiento incremental.
- Implementa Kueue y LeaderWorkerSet para administrar cargas de trabajo de TPU.
- Ejecuta una carga de trabajo de subslicing para verificar el acceso a la TPU de JAX en porciones más pequeñas.
- Ejecuta una carga de trabajo de superslicing para verificar el acceso a la TPU de JAX en varios grupos de nodos combinados.
- Implementa una configuración de Disaggregated Serving en la que las etapas de Prefill y Decode se ejecutan en porciones de TPU separadas y asignadas de forma dinámica, coordinadas por un router de LLM.
Requisitos
- Un navegador web, como Chrome.
- Un proyecto de Google Cloud con facturación habilitada.
- IMPORTANTE: Acceso a una reserva de modo de capacidad total de Cloud TPU7x (Ironwood).
2. Antes de comenzar
Crea o selecciona un proyecto de Google Cloud
Cómo crear un proyecto de Google Cloud
- En la consola de Google Cloud, en la página del selector de proyectos, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se espera, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Clona el repositorio de demostración
Clona el repositorio que contiene los manifiestos y las secuencias de comandos auxiliares para este codelab:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Configura el entorno
Antes de aprovisionar recursos, debes configurar las variables de entorno. Se proporciona una secuencia de comandos auxiliar 01_setup_env.sh para generar un archivo env.sh.
Ejecuta la secuencia de comandos de configuración:
./01_setup_env.sh
Se te solicitarán varios valores. Presiona [ENTER] para aceptar los valores predeterminados, pero asegúrate de proporcionar el nombre de la reserva y el bloque de reserva correctos que te proporcionó el instructor del evento:
- ID del proyecto de GCP: Es el ID de tu proyecto actual.
- Número del proyecto de GCP: Es el número de tu proyecto.
- Nombre del clúster de GKE:
tpu-serving-cluster(predeterminado). - Zona del grupo de nodos TPU:
us-central1-ai1a(predeterminado). - Espacio de nombres de Kubernetes:
llm-d-pd-disaggregation(predeterminado). - Nombre de la reserva de Cloud TPU: [Ingresa el nombre de la reserva proporcionado]
- Nombre del bloque de reserva de Cloud TPU:
block-0(predeterminado). - Nombre del bucket de GCS para los pesos:
model-weights(predeterminado). - Tipo de máquina de TPU:
tpu7x-standard-4t(predeterminado). - Token de Hugging Face: [Ingresa tu token de HF si es necesario o presiona ENTER si usas pesos precargados]
Después de ejecutar la secuencia de comandos, aplica las variables a tu sesión actual:
source env.sh
4. Habilita las APIs y las funciones de la zona de IA
Ahora que tu entorno está configurado, debes habilitar las APIs de Google Cloud necesarias y la función de visibilidad de la zona de IA. Se proporciona una secuencia de comandos auxiliar 02_enable_apis_and_features.sh.
Ejecuta la secuencia de comandos:
./02_enable_apis_and_features.sh
Esta secuencia de comandos hace lo siguiente:
- Habilita las APIs de GKE, Compute, IAM, Resource Manager, Filestore y Network Services.
- Habilita la función de versión preliminar
ai-zones-visibilitypara GKE Dynamic Slicing.
5. Aprovisiona el clúster de GKE y los grupos de nodos TPU
En este paso, aprovisionarás la infraestructura de red subyacente, el clúster de GKE y los grupos de nodos TPU.
Los grupos de nodos TPU se configurarán con el aprovisionamiento incremental (con --placement-policy=superslice-policy y --reservation-affinity=specific), que asigna cada grupo de nodos a un “cubo” de 16 nodos (subbloque) de capacidad de TPU sin procesar.
Ejecuta la secuencia de comandos de aprovisionamiento:
./03_create_cluster_and_nodes.sh
¿Qué hace esta secuencia de comandos?
- Crea redes y subredes de VPC: Configura una red de VPC principal con una MTU grande (8896) optimizada para el tráfico de TPU, una subred de TPU y una subred solo de proxy que requiere la puerta de enlace de GKE.
- Crea un clúster de GKE: Aprovisiona un clúster de GKE Standard con el controlador de porciones habilitado (
--enable-slice-controller). - Crea una política de carga de trabajo: Define una política de recursos llamada
superslice-policyde tipoHIGH_THROUGHPUTcon una topología de4x4x4. - Crea grupos de nodos TPU de GKE: Aprovisiona dos grupos de nodos (
tpu7-pool-1ytpu7-pool-2), cada uno con 16 nodos detpu7x-standard-4t. Estos representan dos cubos de 16 nodos separados.
Verifica los nodos
Una vez que se complete la secuencia de comandos, verifica que los 32 nodos TPU estén aprovisionados y registrados:
kubectl get nodes -l google.com/tpu=present
Deberías ver 32 nodos en la lista.
6. Instala las herramientas de organización
El corte dinámico se basa en varios controladores de Kubernetes para coordinar los trabajos y la asignación de porciones. Instalarás lo siguiente:
- JobSet: Para administrar grupos de trabajos (necesario para el superslicing).
- Kueue: Para la administración de colas y recursos, y la programación con reconocimiento de topología (TAS).
- LeaderWorkerSet (LWS): Para administrar implementaciones de TPU replicadas de varios nodos (necesario para la entrega de LLM).
- Controlador de porciones de GKE (espacio de usuario): Conecta Kueue con el Cluster Director de TPU para administrar de forma dinámica las porciones físicas.
Ejecuta la secuencia de comandos de instalación:
./04_install_kueue_lws_slice_controller.sh
Verifica que el controlador de porciones se esté ejecutando correctamente:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Configura los recursos de Kueue
Ahora debes definir los recursos de Kueue que representan tu topología de hardware de TPU y configurar las verificaciones de admisión.
Ejecuta la secuencia de comandos de implementación:
./05_deploy_kueue_resources.sh
Recursos clave implementados:
- Topología (
slice-topology): Define los niveles jerárquicos de las particiones de TPU (desde el bloque hasta el nombre de host) que Kueue debe considerar cuando realiza la programación. - ResourceFlavor (
slice-rf): Asociaslice-topologycon el aceleradortpu7x. - AdmissionCheck (
ac): Configura Kueue para usar el controlador de porciones de GKE (accelerator.gke.io/slice) para aprovisionar porciones de forma dinámica cuando se admite un trabajo. - ClusterQueue (
cq) & LocalQueue (lq): Configura las colas a las que se enviarán las cargas de trabajo. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): Define los niveles de prioridad para habilitar la prioridad y la programación basada en la prioridad.
Verifica los recursos:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Implementa y verifica el acceso a la TPU con subslicing
El subslicing te permite ejecutar varias cargas de trabajo más pequeñas dentro de un solo bloque de TPU aprovisionado. En este paso, enviarás una carga de trabajo que solicita una topología 2x2x2 (8 chips / 2 VMs) a un clúster compuesto por bloques 4x4x4 (64 chips / 16 VMs).
Implementa la carga de trabajo de subslicing:
./06_deploy_simple_subslicing.sh
Esta secuencia de comandos aplica kueue-jobset-simple-subslicing.yaml.
Cómo funciona:
- La especificación de JobSet incluye la anotación
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Configura
replicas: 6yparallelism: 2(finalizaciones: 2). Esto significa que Kueue programará 6 trabajos independientes, cada uno de los cuales consta de 2 pods. - Cada pod solicita
google.com/tpu: "4"(1 VM de TPU). - Kueue y el controlador de porciones de GKE dividen de forma dinámica el clúster de 32 nodos para asignar seis porciones
2x2x2.
Verifica la ejecución de JAX
Supervisa los pods hasta que se estén ejecutando:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Comprueba los registros de uno de los pods para verificar que JAX detectó correctamente los 8 dispositivos TPU (núcleos) en su subporción:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Deberías ver un resultado que indique lo siguiente: Total TPU devices (cores): 8
9. Implementa y verifica el acceso a la TPU con superslicing
El superslicing es una potente función de GKE que permite que una sola carga de trabajo abarque varios bloques de TPU físicos (a menudo denominados cubos o topologías como 4x4x4). Al unir estos bloques, puedes formar una porción virtual más grande para el entrenamiento a gran escala o la entrega de cargas de trabajo. En este paso, implementarás un JobSet que solicita una topología 4x4x8 (128 chips / 32 VMs). Dado que un solo bloque 4x4x4 solo contiene 64 chips, esta carga de trabajo excede el tamaño de un solo bloque y requiere que GKE una de forma dinámica los grupos de nodos tpu7-pool-1 y tpu7-pool-2 para satisfacer la solicitud.
Implementa la carga de trabajo de superslicing:
./07_deploy_simple_superslicing.sh
Esta secuencia de comandos aplica kueue-jobset-simple-superslicing.yaml.
Cómo funciona:
- La plantilla de JobSet incluye la anotación
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Configura
parallelism: 32ycompletions: 32. - Cada pod solicita
google.com/tpu: "4". - Dado que una topología
4x4x8requiere los 32 nodos, el controlador de porciones configura de forma dinámica la red OCS (Optical Circuit Switching) para interconectar los dos grupos de 16 nodos en una sola malla ICI de 32 nodos.
Verifica que los pods de JobSet se ejecuten correctamente y que JAX detecte los 128 dispositivos:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Verifica los registros de uno de los pods:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Deberías ver el resultado de JAX que muestra el recuento de dispositivos globales: Global device count: 128
10. Implementa Disaggregated Serving (Prefill/Decode)
Ahora implementarás la pila de entrega de LLM de extremo a extremo con Disaggregated Serving (Prefill/Decode).
En la entrega estándar, el prefill (procesamiento de la solicitud) y la decodificación (generación de tokens) se ejecutan en las mismas TPUs. Dado que el prefill está vinculado a la capacidad de procesamiento y la decodificación está vinculada al ancho de banda de la memoria, entran en conflicto. Disaggregated Serving los ejecuta en porciones de TPU separadas y transfiere la caché de KV a través de la red.
Configura LLM-D y la puerta de enlace
Configura los espacios de nombres, los secretos de Hugging Face y la puerta de enlace de GKE:
./08_setup_llm_d.sh
Implementa el router de LLM-D
Implementa el router que recibirá las solicitudes del cliente y coordinará el enrutamiento entre las porciones de Prefill y Decode:
./09_deploy_llm_d_router.sh
Implementa las cargas de trabajo de Prefill y Decode
Implementa los servidores de modelos vLLM en porciones de TPU asignadas de forma dinámica:
./10_deploy_subslicing_pd_workload.sh
Qué hace:
- Implementa
kueue-vllm-prefill-model-streamer(LWS que solicita una porción de TPU2x2x2). - Implementa
kueue-vllm-decode-model-streamer(LWS que solicita una porción de TPU2x2x2). - La porción de prefill carga los pesos del modelo Qwen 397B y actúa como
kv_producer. - La porción de decodificación actúa como
kv_consumer. - Se comunican con
TPUConnectorHMApara transferir cachés de KV.
Espera hasta que se ejecuten los pods de prefill y decodificación:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Verifica la entrega
Con el router, el prefill y las cargas de trabajo de decodificación en ejecución, ahora puedes verificar la API de entrega.
Ejecuta la secuencia de comandos de verificación:
./11_verify_serving.sh
Cómo funciona:
- La secuencia de comandos recupera la IP interna de la puerta de enlace de GKE.
- Activa un pod temporal (
curl-debug-comp) para enviar una solicitud de finalización ahttp://${GATEWAY_IP}/v1/completions. - Activa otro pod (
curl-debug-chat) para enviar una solicitud de chat ahttp://${GATEWAY_IP}/v1/chat/completions.
Deberías ver una respuesta JSON exitosa del modelo Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Limpia
Para evitar cargos continuos en tu cuenta de Google Cloud, borra los recursos creados durante este codelab.
Ejecuta la secuencia de comandos "teardown":
./12_teardown_cleanup.sh
¿Qué hace esta secuencia de comandos?
- Borra los grupos de nodos de GKE (
tpu7-pool-1,tpu7-pool-2). - Borra el clúster de GKE (
tpu-serving-cluster). - Borra las políticas de recursos (
superslice-policy). - Borra las redes de VPC (
qwen-serving-main).
Como alternativa, si creaste un proyecto dedicado para este codelab, puedes borrar todo el proyecto:
gcloud projects delete ${PROJECT_ID}
13. Felicitaciones
¡Felicitaciones! Exploraste correctamente GKE Dynamic Slicing y, además, implementaste una arquitectura de Disaggregated LLM Serving.
Qué aprendiste
- Cómo habilitar el controlador de porciones de GKE y configurar grupos de nodos para el aprovisionamiento incremental.
- Cómo usar Kueue para solicitar topologías de TPU específicas.
- Cómo el subslicing divide un bloque de TPU grande para cargas de trabajo de JAX más pequeñas e independientes.
- Cómo el superslicing une varios grupos de nodos en una sola porción de TPU virtual más grande.
- Cómo implementar Disaggregated Serving (Prefill/Decode) con LWS, la API de Gateway y vLLM.