
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه از GKE Dynamic Slicing برای بهینهسازی استفاده از منابع Cloud TPU استفاده کنید. Dynamic slicing یک قابلیت قدرتمند است که به شما امکان میدهد تأمین TPU خام را از برنامهریزی بار کاری جدا کنید.
به طور خاص، شما دو الگوی کلیدی را بررسی خواهید کرد:
- زیربخشبندی : تقسیم یک بلوک TPU بزرگ به بخشهای کوچکتر و ایزوله برای حجم کاری کمتر.
- برش فوقالعاده (Super-slicing ): دوختن چندین بلوک TPU آماده به یکدیگر برای تشکیل یک برش مجازی بزرگتر برای بارهای کاری در مقیاس بزرگ.
شما این الگوها را برای استقرار یک معماری سرویسدهی تفکیکشده (تفکیکسازی پیشپرسازی/رمزگشایی) با کارایی بالا برای یک مدل زبانی بزرگ (Qwen 397B) با استفاده از Kueue ، LeaderWorkerSet (LWS) و Gateway API اعمال خواهید کرد.
معماری
در اینجا معماری سطح بالای تنظیمات TPU Dynamic Slicing و Disaggregated Serving آمده است:
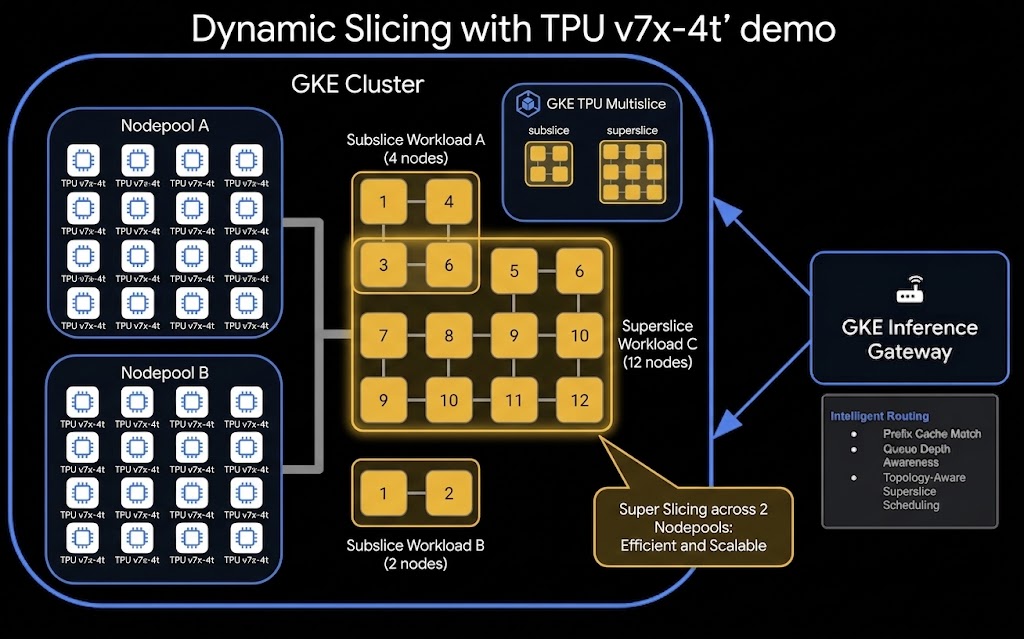
کاری که انجام خواهید داد
- یک کلاستر GKE با فعال بودن GKE Slice Controller تهیه کنید.
- ایجاد مجموعه گرههای GKE TPU که برای تأمین افزایشی پیکربندی شدهاند.
- Kueue و LeaderWorkerSet را برای مدیریت بارهای کاری TPU مستقر کنید.
- برای تأیید دسترسی JAX TPU روی برشهای کوچکتر، یک بار کاری subslicing اجرا کنید.
- برای تأیید دسترسی JAX TPU در چندین مجموعه گره ترکیبی، یک بار کاری فوق برش (superslicing) اجرا کنید.
- یک تنظیمات سرویسدهی تفکیکشده را مستقر کنید که در آن مراحل پیشپرسازی و رمزگشایی روی برشهای TPU جداگانه و پویا که توسط یک روتر LLM هماهنگ میشوند، اجرا شوند.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم .
- یک پروژه گوگل کلود با قابلیت پرداخت.
- مهم : دسترسی به رزرو حالت تمام ظرفیت Cloud TPU7x (Ironwood).
۲. قبل از شروع
یک پروژه Google Cloud ایجاد یا انتخاب کنید
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
مخزن نسخه آزمایشی را کلون کنید
مخزن حاوی مانیفستها و اسکریپتهای کمکی برای این codelab را کلون کنید:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
۳. پیکربندی محیط
قبل از تأمین منابع، باید متغیرهای محیطی خود را پیکربندی کنید. یک اسکریپت کمکی 01_setup_env.sh برای تولید فایل env.sh ارائه شده است.
اسکریپت راهاندازی را اجرا کنید:
./01_setup_env.sh
از شما چندین مقدار خواسته میشود. برای پذیرش مقادیر پیشفرض، [ENTER] را فشار دهید، اما مطمئن شوید که نام رزرو و بلوک رزرو صحیح ارائه شده توسط مربی رویداد خود را وارد میکنید:
- شناسه پروژه GCP : شناسه پروژه فعلی شما.
- شماره پروژه GCP : شماره پروژه شما.
- نام خوشه GKE :
tpu-serving-cluster(پیشفرض). - منطقهی مخزن گرهی TPU :
us-central1-ai1a(پیشفرض). - فضای نام Kubernetes :
llm-d-pd-disaggregation(پیشفرض). - نام رزرو Cloud TPU : [نام رزرو ارائه شده را وارد کنید]
- نام بلوک رزرو TPU ابری :
block-0(پیشفرض). - نام سطل GCS برای وزنها :
model-weights(پیشفرض). - نوع دستگاه TPU :
tpu7x-standard-4t(پیشفرض). - توکن چهره در آغوش گرفته : [در صورت نیاز، توکن HF خود را وارد کنید، یا در صورت استفاده از وزنههای از پیش بارگذاری شده، ENTER را فشار دهید]
پس از اجرای اسکریپت، متغیرها را در جلسه فعلی خود اعمال کنید:
source env.sh
۴. فعال کردن APIها و ویژگیهای AI Zone
اکنون که محیط شما پیکربندی شده است، باید APIهای مورد نیاز Google Cloud و ویژگی قابلیت مشاهده منطقه هوش مصنوعی را فعال کنید. یک اسکریپت کمکی 02_enable_apis_and_features.sh ارائه شده است.
اسکریپت را اجرا کنید:
./02_enable_apis_and_features.sh
این اسکریپت:
- رابطهای برنامهنویسی کاربردی (API) سرویسهای GKE، محاسبات، IAM، مدیریت منابع، ذخیرهسازی فایل و خدمات شبکه را فعال میکند.
- قابلیت پیشنمایش
ai-zones-visibilityرا برای برش پویای GKE فعال میکند.
۵. فراهمسازی خوشه GKE و مجموعههای گره TPU
در این مرحله، زیرساخت شبکه زیربنایی، خوشه GKE و مجموعه گرههای TPU را فراهم خواهید کرد.
مجموعه گرههای TPU با Incremental Provisioning (با استفاده از --placement-policy=superslice-policy و --reservation-affinity=specific ) پیکربندی خواهند شد، که هر مجموعه گره را به یک "مکعب" (زیربلوک) 16 گرهای از ظرفیت خام TPU نگاشت میکند.
اسکریپت آمادهسازی را اجرا کنید:
./03_create_cluster_and_nodes.sh
کارهایی که این اسکریپت انجام میدهد:
- ایجاد شبکه و زیرشبکههای VPC : یک شبکه اصلی VPC با MTU بزرگ (8896) بهینه شده برای ترافیک TPU، یک زیرشبکه TPU و یک زیرشبکه فقط پروکسی مورد نیاز GKE Gateway راهاندازی میکند.
- ایجاد خوشه GKE : یک خوشه استاندارد GKE با کنترلکننده برش فعال (
--enable-slice-controller) فراهم میکند. - ایجاد سیاست حجم کار : یک سیاست منبع به نام
superslice-policyاز نوعHIGH_THROUGHPUTبا توپولوژی4x4x4تعریف میکند. - ایجاد استخرهای گره GKE TPU : دو استخر گره (
tpu7-pool-1وtpu7-pool-2) را فراهم میکند که هر کدام شامل ۱۶ گره ازtpu7x-standard-4tهستند. اینها دو مکعب ۱۶ گرهای مجزا را نشان میدهند.
گرهها را تأیید کنید
پس از اتمام اسکریپت، تأیید کنید که هر 32 گره TPU آمادهسازی و ثبت شدهاند:
kubectl get nodes -l google.com/tpu=present
شما باید ۳۲ گره را در لیست ببینید.
۶. ابزارهای ارکستراسیون را نصب کنید
برش پویا برای هماهنگی کارها و تخصیص برش به چندین کنترلکننده Kubernetes متکی است. شما موارد زیر را نصب خواهید کرد:
- JobSet : برای مدیریت گروهی از کارها (مورد نیاز برای سوپراسلایسینگ).
- Kueue : برای صفبندی، مدیریت منابع و زمانبندی مبتنی بر توپولوژی (TAS).
- LeaderWorkerSet (LWS) : برای مدیریت استقرارهای TPU چند گرهای تکثیر شده (مورد نیاز برای سرویس LLM).
- کنترلکننده برش GKE (فضای کاربر) : Kueue را به مدیر خوشه TPU متصل میکند تا برشهای فیزیکی را به صورت پویا مدیریت کند.
اسکریپت نصب را اجرا کنید:
./04_install_kueue_lws_slice_controller.sh
تأیید کنید که Slice Controller با موفقیت اجرا میشود:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
۷. پیکربندی منابع Kueue
حالا باید منابع Kueue را که نشاندهنده توپولوژی سختافزار TPU شما هستند، تعریف کنید و بررسیهای پذیرش را پیکربندی کنید.
اسکریپت استقرار را اجرا کنید:
./05_deploy_kueue_resources.sh
منابع کلیدی به کار گرفته شده:
- توپولوژی (
slice-topology) : سطوح سلسله مراتبی پارتیشنهای TPU (از بلوک تا نام میزبان) را تعریف میکند که Kueue هنگام برنامهریزی باید در نظر بگیرد. - ResourceFlavor (
slice-rf) :slice-topologyرا با شتابدهندهtpu7xمرتبط میکند. - AdmissionCheck (
ac) : کوئو را طوری پیکربندی میکند که از کنترلر برش GKE (accelerator.gke.io/slice) برای تهیهی پویای برشها هنگام پذیرش یک کار استفاده کند. - ClusterQueue (
cq) و LocalQueue (lq) : صفهایی را که بارهای کاری به آنها ارسال میشوند، تنظیم میکند. - کلاس اولویت بار کاری (
low-priority-1000،medium-priority-2000،high-priority-3000) : سطوح اولویت را برای فعال کردن حق تقدم و زمانبندی مبتنی بر اولویت تعریف میکند.
منابع را تأیید کنید:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
۸. استقرار و تأیید دسترسی TPU با Subslicing
برش فرعی به شما امکان میدهد چندین بار کاری کوچکتر را در یک بلوک TPU آماده اجرا کنید. در این مرحله، شما یک بار کاری را که درخواست توپولوژی 2x2x2 (8 تراشه / 2 ماشین مجازی) را دارد، به کلاستری متشکل از بلوکهای 4x4x4 (64 تراشه / 16 ماشین مجازی) ارسال خواهید کرد.
حجم کار subslicing را مستقر کنید:
./06_deploy_simple_subslicing.sh
این اسکریپت kueue-jobset-simple-subslicing.yaml را اعمال میکند.
چگونه کار میکند:
- مشخصات JobSet شامل حاشیهنویسی
cloud.google.com/gke-tpu-slice-topology: 2x2x2است. - این دستور
replicas: 6وparallelism: 2(تکمیلها را ۲) پیکربندی میکند. این یعنی Kueue شش کار مستقل را زمانبندی خواهد کرد که هر کدام شامل ۲ پاد هستند. - هر پاد
google.com/tpu: "4"(1 ماشین مجازی TPU). - Kueue و کنترلکنندهی برش GKE به صورت پویا خوشهی ۳۲ گرهای را برش میدهند تا شش برش
2x2x2را اختصاص دهند.
تأیید اجرای JAX
پادها را تا زمان اجرا زیر نظر داشته باشید:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
لاگهای یکی از پادها را بررسی کنید تا مطمئن شوید JAX با موفقیت ۸ دستگاه TPU (هسته) را در زیربخش خود شناسایی کرده است:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
باید خروجی را با این مضمون ببینید: Total TPU devices (cores): 8
۹. استقرار و تأیید دسترسی TPU با Superslicing
برش فوقالعاده (Super-slicing) یک ویژگی قدرتمند GKE است که به یک بار کاری واحد اجازه میدهد تا چندین بلوک TPU فیزیکی (که اغلب به عنوان مکعب یا توپولوژیهایی مانند 4x4x4 شناخته میشوند) را در بر بگیرد. با دوختن این بلوکها به یکدیگر، میتوانید یک برش مجازی بزرگتر برای آموزش در مقیاس بزرگ یا ارائه بارهای کاری تشکیل دهید. در این مرحله، یک JobSet را مستقر خواهید کرد که درخواست توپولوژی 4x4x8 (128 تراشه / 32 ماشین مجازی) را دارد. از آنجایی که یک بلوک 4x4x4 تنها شامل 64 تراشه است، این حجم کاری از اندازه یک بلوک واحد فراتر میرود و به GKE نیاز دارد تا به صورت پویا استخرهای گره tpu7-pool-1 و tpu7-pool-2 را به هم بچسباند تا درخواست را برآورده کند.
حجم کار superslicing را مستقر کنید:
./07_deploy_simple_superslicing.sh
این اسکریپت kueue-jobset-simple-superslicing.yaml را اعمال میکند.
چگونه کار میکند:
- الگوی JobSet شامل حاشیهنویسی
cloud.google.com/gke-tpu-slice-topology: 4x4x8است. - این
parallelism: 32وcompletions: 32را پیکربندی میکند. - هر پاد
google.com/tpu: "4"را درخواست میکند. - از آنجایی که یک توپولوژی
4x4x8به هر 32 گره نیاز دارد، کنترلکننده برش به صورت پویا شبکه OCS (سوئیچینگ مدار نوری) را پیکربندی میکند تا دو استخر 16 گرهای را به یک مش ICI 32 گرهای متصل کند.
تأیید کنید که پادهای JobSet با موفقیت اجرا میشوند و JAX هر 128 دستگاه را شناسایی میکند:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
لاگهای یکی از پادها را بررسی کنید:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
باید خروجی JAX را ببینید که تعداد دستگاههای جهانی را نشان میدهد: Global device count: 128
۱۰. ارائه خدمات تفکیکشده (پیشپر کردن/رمزگشایی)
اکنون با استفاده از Prefill/Decode Disaggregation، پشته سرویس LLM سرتاسری را مستقر خواهید کرد.
در سرویسدهی استاندارد، پیشپر کردن (پردازش اعلان) و رمزگشایی (تولید توکنها) روی TPUهای یکسانی اجرا میشوند. از آنجایی که پیشپر کردن وابسته به محاسبات و رمزگشایی وابسته به پهنای باند حافظه است، آنها با هم تداخل دارند. سرویسدهی تفکیکشده آنها را روی برشهای TPU جداگانه اجرا میکند و KV Cache را از طریق شبکه منتقل میکند.
راهاندازی LLM-D و Gateway
فضاهای نام، اسرار Hugging Face و GKE Gateway را تنظیم کنید:
./08_setup_llm_d.sh
روتر LLM-D را مستقر کنید
روتری را مستقر کنید که درخواستهای کلاینت را دریافت کرده و مسیریابی بین برشهای Prefill و Decode را هماهنگ میکند:
./09_deploy_llm_d_router.sh
استقرار بارهای کاری Prefill و Decode
سرورهای مدل vLLM را روی برشهای TPU که به صورت پویا تخصیص داده شدهاند، مستقر کنید:
./10_deploy_subslicing_pd_workload.sh
این چه کاری انجام میدهد:
-
kueue-vllm-prefill-model-streamer(LWS که درخواست یک برش TPU2x2x2دارد) را مستقر میکند. -
kueue-vllm-decode-model-streamer(LWS که درخواست یک برش TPU2x2x2دارد) را مستقر میکند. - برش پیشپرسازی، وزنهای مدل Qwen 397B را بارگذاری میکند و به عنوان
kv_producerعمل میکند. - برش رمزگشایی به عنوان
kv_consumerعمل میکند. - آنها با استفاده از
TPUConnectorHMAبرای انتقال حافظههای نهان KV ارتباط برقرار میکنند.
صبر کنید تا هر دو پادِ prefill و decode اجرا شوند:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
۱۱. سرو کردن را تأیید کنید
با اجرای بارهای کاری روتر، پر کردن اولیه و رمزگشایی، اکنون میتوانید API ارائه دهنده را تأیید کنید.
اسکریپت تأیید را اجرا کنید:
./11_verify_serving.sh
چگونه کار میکند:
- این اسکریپت IP داخلی GKE Gateway را بازیابی میکند.
- این یک پاد موقت (
curl-debug-comp) را برای ارسال درخواست تکمیل بهhttp://${GATEWAY_IP}/v1/completionsراهاندازی میکند. - این یک پاد دیگر (
curl-debug-chat) را برای ارسال درخواست چت بهhttp://${GATEWAY_IP}/v1/chat/completionsراهاندازی میکند.
شما باید یک پاسخ JSON موفق از مدل Qwen ببینید:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
۱۲. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
اسکریپت teardown را اجرا کنید:
./12_teardown_cleanup.sh
کارهایی که این اسکریپت انجام میدهد:
- مجموعههای گره GKE (
tpu7-pool-1،tpu7-pool-2) را حذف میکند. - خوشه GKE (
tpu-serving-cluster) را حذف میکند. - سیاستهای منابع (
superslice-policy) را حذف میکند. - شبکههای VPC (
qwen-serving-main) را حذف میکند.
از طرف دیگر، اگر یک پروژه اختصاصی برای این آزمایشگاه کد ایجاد کردهاید، میتوانید کل پروژه را حذف کنید:
gcloud projects delete ${PROJECT_ID}
۱۳. تبریک
تبریک! شما با موفقیت GKE Dynamic Slicing را بررسی کرده و یک معماری Disaggregated LLM Serving را مستقر کردهاید.
آنچه آموختهاید
- نحوه فعال کردن GKE Slice Controller و پیکربندی Node Poolها برای Incremental Provisioning .
- نحوه استفاده از Kueue برای درخواست توپولوژیهای خاص TPU.
- چگونه Sub-slicing یک بلوک TPU بزرگ را برای بارهای کاری JAX کوچکتر و مستقل تقسیم میکند.
- چگونه Super-slicing چندین گره را به یک برش مجازی TPU بزرگتر تبدیل میکند.
- نحوهی استقرار سرویس تفکیکشدهی Prefill/Decode با استفاده از LWS، Gateway API و vLLM.