
1. Introduction
Dans cet atelier, vous allez apprendre à utiliser GKE Dynamic Slicing pour optimiser l'utilisation des ressources Cloud TPU. Le découpage dynamique est une fonctionnalité puissante qui vous permet de dissocier le provisionnement brut de TPU de la planification des charges de travail.
Plus précisément, vous allez explorer deux modèles clés :
- Sous-découpage : division d'un grand bloc TPU provisionné en tranches plus petites et isolées pour les charges de travail plus petites.
- Super-découpage : assemblage de plusieurs blocs TPU provisionnés pour former une tranche virtuelle plus grande pour les charges de travail à grande échelle.
Vous appliquerez ces modèles pour déployer une architecture Disaggregated Serving (Prefill/Decode disaggregation) haute performance pour un grand modèle de langage (Qwen 397B) à l'aide de Kueue, LeaderWorkerSet (LWS) et de l'API Gateway.
Architecture
Voici l'architecture de haut niveau de la configuration TPU Dynamic Slicing et Disaggregated Serving :
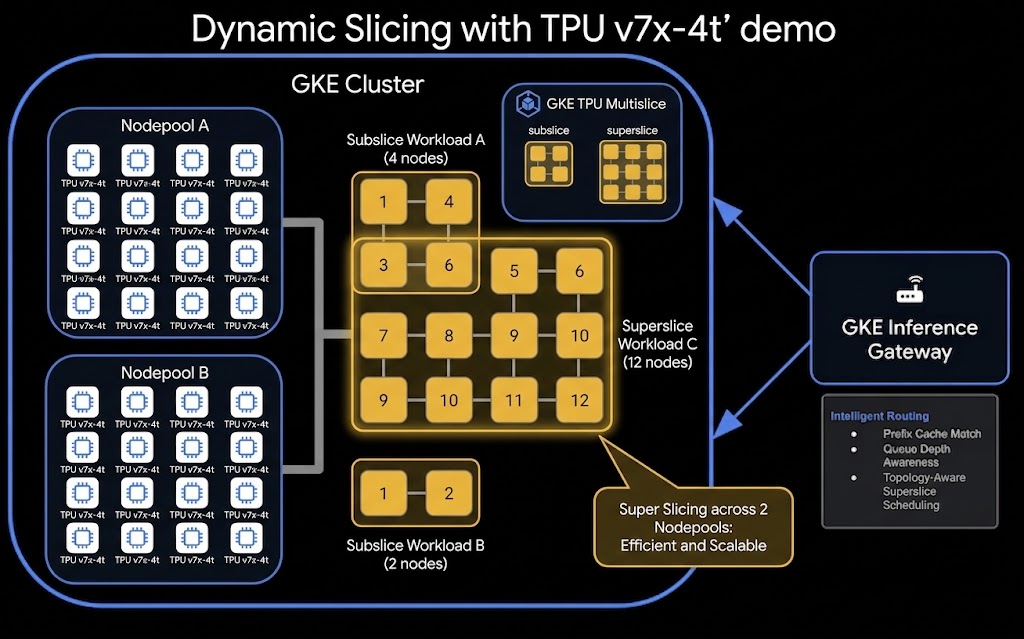
Objectifs de l'atelier
- Provisionner un cluster GKE avec GKE Slice Controller activé.
- Créer des pools de nœuds GKE TPU configurés pour le provisionnement incrémentiel.
- Déployer Kueue et LeaderWorkerSet pour gérer les charges de travail TPU.
- Exécuter une charge de travail de sous-découpage pour vérifier l'accès JAX TPU sur des tranches plus petites.
- Exécuter une charge de travail de super-découpage pour vérifier l'accès JAX TPU sur plusieurs pools de nœuds combinés.
- Déployer une configuration Disaggregated Serving dans laquelle les étapes Prefill et Decode s'exécutent sur des tranches TPU distinctes allouées de manière dynamique, coordonnées par un routeur LLM.
Ce dont vous avez besoin
- Un navigateur Web tel que Chrome.
- Un projet Google Cloud avec facturation activée.
- IMPORTANT : Accès à une réservation en mode "All Capacity" (Toute capacité) Cloud TPU7x (Ironwood).
2. Avant de commencer
Créer ou sélectionner un projet Google Cloud
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée pour un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud, qui est préchargé avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Cloner le dépôt de démonstration
Clonez le dépôt contenant les fichiers manifestes et les scripts d'assistance pour cet atelier :
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Configurer l'environnement
Avant de provisionner des ressources, vous devez configurer vos variables d'environnement. Un script d'assistance 01_setup_env.sh est fourni pour générer un fichier env.sh.
Exécutez le script de configuration :
./01_setup_env.sh
Vous serez invité à saisir plusieurs valeurs. Appuyez sur [ENTRÉE] pour accepter les valeurs par défaut, mais assurez-vous de fournir le nom de la réservation et le bloc de réservation corrects fournis par l'instructeur de votre événement :
- ID du projet GCP : ID de votre projet actuel.
- Numéro du projet GCP : numéro de votre projet.
- Nom du cluster GKE :
tpu-serving-cluster(par défaut). - Zone du pool de nœuds TPU :
us-central1-ai1a(par défaut). - Espace de noms Kubernetes :
llm-d-pd-disaggregation(par défaut). - Nom de la réservation Cloud TPU : [Saisissez le nom de la réservation fourni]
- Nom du bloc de réservation Cloud TPU :
block-0(par défaut). - Nom du bucket GCS pour les poids :
model-weights(par défaut). - Type de machine TPU :
tpu7x-standard-4t(par défaut). - Jeton Hugging Face : [Saisissez votre jeton HF si nécessaire, ou appuyez sur ENTRÉE si vous utilisez des poids préchargés]
Après avoir exécuté le script, appliquez les variables à votre session actuelle :
source env.sh
4. Activer les API et les fonctionnalités de la zone d'IA
Maintenant que votre environnement est configuré, vous devez activer les API Google Cloud requises et la fonctionnalité de visibilité de la zone d'IA. Un script d'assistance 02_enable_apis_and_features.sh est fourni.
Exécutez le script :
./02_enable_apis_and_features.sh
Ce script :
- Active les API GKE, Compute, IAM, Resource Manager, Filestore et Network Services.
- Active la fonctionnalité bêta
ai-zones-visibilitypour GKE Dynamic Slicing.
5. Provisionner le cluster GKE et les pools de nœuds TPU
Au cours de cette étape, vous allez provisionner l'infrastructure réseau sous-jacente, le cluster GKE et les pools de nœuds TPU.
Les pools de nœuds TPU seront configurés avec le provisionnement incrémentiel (à l'aide de --placement-policy=superslice-policy et --reservation-affinity=specific), qui mappe chaque pool de nœuds à un "cube" (sous-bloc) de capacité TPU brute de 16 nœuds.
Exécutez le script de provisionnement :
./03_create_cluster_and_nodes.sh
À quoi sert le script ?
- Créer un réseau VPC et des sous-réseaux : configure un réseau VPC principal avec une MTU élevée (8896) optimisée pour le trafic TPU, un sous-réseau TPU et un sous-réseau réservé aux proxys requis par GKE Gateway.
- Créer un cluster GKE : provisionne un cluster GKE Standard avec le Slice Controller activé (
--enable-slice-controller). - Créer une stratégie de charge de travail : définit une stratégie de ressource nommée
superslice-policyde typeHIGH_THROUGHPUTavec une topologie4x4x4. - Créer des pools de nœuds GKE TPU : provisionne deux pools de nœuds (
tpu7-pool-1ettpu7-pool-2), contenant chacun 16 nœuds detpu7x-standard-4t. Ils représentent deux cubes distincts de 16 nœuds.
Vérifier les nœuds
Une fois le script terminé, vérifiez que les 32 nœuds TPU sont provisionnés et enregistrés :
kubectl get nodes -l google.com/tpu=present
Vous devriez voir 32 nœuds dans la liste.
6. Installer les outils d'orchestration
Le découpage dynamique repose sur plusieurs contrôleurs Kubernetes pour coordonner les jobs et l'allocation des tranches. Vous allez installer :
- JobSet : pour gérer un groupe de jobs (nécessaire pour le super-découpage).
- Kueue : pour la mise en file d'attente, la gestion des ressources et la planification tenant compte de la topologie (TAS).
- LeaderWorkerSet (LWS) : pour gérer les déploiements TPU multinoeuds répliqués (nécessaire pour la diffusion LLM).
- GKE Slice Controller (espace utilisateur) : connecte Kueue au TPU Cluster Director pour gérer de manière dynamique les tranches physiques.
Exécutez le script d'installation :
./04_install_kueue_lws_slice_controller.sh
Vérifiez que le Slice Controller s'exécute correctement :
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Configurer les ressources Kueue
Vous devez maintenant définir les ressources Kueue qui représentent votre topologie matérielle TPU et configurer les vérifications d'admission.
Exécutez le script de déploiement :
./05_deploy_kueue_resources.sh
Principales ressources déployées :
- Topologie (
slice-topology) : définit les niveaux hiérarchiques des partitions TPU (du bloc au nom d'hôte) que Kueue doit prendre en compte lors de la planification. - ResourceFlavor (
slice-rf) : associeslice-topologyà l'accélérateurtpu7x. - AdmissionCheck (
ac) : configure Kueue pour qu'il utilise GKE Slice Controller (accelerator.gke.io/slice) afin de provisionner dynamiquement des tranches lorsqu'un job est admis. - ClusterQueue (
cq) & LocalQueue (lq) : configure les files d'attente auxquelles les charges de travail seront envoyées. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000) : définit les niveaux de priorité pour activer la préemption et la planification basée sur la priorité.
Vérifiez les ressources :
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Déployer et vérifier l'accès TPU avec le sous-découpage
Le sous-découpage vous permet d'exécuter plusieurs charges de travail plus petites dans un seul bloc TPU provisionné. Au cours de cette étape, vous allez envoyer une charge de travail qui demande une topologie 2x2x2 (8 puces / 2 VM) à un cluster composé de blocs 4x4x4 (64 puces / 16 VM).
Déployez la charge de travail de sous-découpage :
./06_deploy_simple_subslicing.sh
Ce script applique kueue-jobset-simple-subslicing.yaml.
Fonctionnement :
- La spécification JobSet inclut l'annotation
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Elle configure
replicas: 6etparallelism: 2(completions: 2). Cela signifie que Kueue planifie six jobs indépendants, chacun composé de deux pods. - Chaque pod demande
google.com/tpu: "4"(1 VM TPU). - Kueue et GKE Slice Controller découpent dynamiquement le cluster de 32 nœuds pour allouer six tranches
2x2x2.
Vérifier l'exécution de JAX
Surveillez les pods jusqu'à ce qu'ils soient en cours d'exécution :
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Consultez les journaux de l'un des pods pour vérifier que JAX a bien détecté les huit appareils TPU (cœurs) sur sa sous-tranche :
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Vous devriez voir une sortie indiquant : Total TPU devices (cores): 8
9. Déployer et vérifier l'accès TPU avec le super-découpage
Le super-découpage est une fonctionnalité GKE puissante qui permet à une seule charge de travail de s'étendre sur plusieurs blocs TPU physiques (souvent appelés cubes ou topologies comme 4x4x4). En assemblant ces blocs, vous pouvez former une tranche virtuelle plus grande pour les charges de travail d'entraînement ou de diffusion à grande échelle. Au cours de cette étape, vous allez déployer un JobSet qui demande une topologie 4x4x8 (128 puces / 32 VM). Étant donné qu'un seul bloc 4x4x4 ne contient que 64 puces, cette charge de travail dépasse la taille d'un seul bloc et nécessite que GKE assemble dynamiquement les pools de nœuds tpu7-pool-1 et tpu7-pool-2 pour répondre à la requête.
Déployez la charge de travail de super-découpage :
./07_deploy_simple_superslicing.sh
Ce script applique kueue-jobset-simple-superslicing.yaml.
Fonctionnement :
- Le modèle JobSet inclut l'annotation
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Il configure
parallelism: 32etcompletions: 32. - Chaque pod demande
google.com/tpu: "4". - Étant donné qu'une topologie
4x4x8nécessite les 32 nœuds, le Slice Controller configure dynamiquement le réseau OCS (Optical Circuit Switching) pour interconnecter les deux pools de 16 nœuds dans un seul maillage ICI de 32 nœuds.
Vérifiez que les pods JobSet s'exécutent correctement et que JAX détecte les 128 appareils :
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Consultez les journaux de l'un des pods :
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Vous devriez voir le résultat JAX indiquant le nombre total d'appareils : Global device count: 128
10. Déployer Disaggregated Serving (Prefill/Decode)
Vous allez maintenant déployer la pile de diffusion LLM de bout en bout à l'aide de Prefill/Decode Disaggregation.
Dans la diffusion standard, le préremplissage (traitement de l'invite) et le décodage (génération de jetons) s'exécutent sur les mêmes TPU. Étant donné que le préremplissage est lié au calcul et que le décodage est lié à la bande passante de la mémoire, ils sont en conflit. La diffusion désagrégée les exécute sur des tranches TPU distinctes, en transférant le cache KV sur le réseau.
Configurer LLM-D et Gateway
Configurez les espaces de noms, les secrets Hugging Face et GKE Gateway :
./08_setup_llm_d.sh
Déployer le routeur LLM-D
Déployez le routeur qui recevra les requêtes client et coordonnera le routage entre les tranches Prefill et Decode :
./09_deploy_llm_d_router.sh
Déployer les charges de travail Prefill et Decode
Déployez les serveurs de modèles vLLM sur des tranches TPU allouées de manière dynamique :
./10_deploy_subslicing_pd_workload.sh
Fonction :
- Déploie
kueue-vllm-prefill-model-streamer(LWS demandant une tranche TPU2x2x2). - Déploie
kueue-vllm-decode-model-streamer(LWS demandant une tranche TPU2x2x2). - La tranche de préremplissage charge les poids du modèle Qwen 397B et agit comme
kv_producer. - La tranche de décodage agit comme
kv_consumer. - Ils communiquent à l'aide de
TPUConnectorHMApour transférer les caches KV.
Attendez que les pods de préremplissage et de décodage soient en cours d'exécution :
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Vérifier la diffusion
Une fois les charges de travail du routeur, de préremplissage et de décodage exécutées, vous pouvez vérifier l'API de diffusion.
Exécutez le script de validation :
./11_verify_serving.sh
Fonctionnement :
- Le script récupère l'adresse IP interne de GKE Gateway.
- Il lance un pod temporaire (
curl-debug-comp) pour envoyer une requête de saisie semi-automatique àhttp://${GATEWAY_IP}/v1/completions. - Il lance un autre pod (
curl-debug-chat) pour envoyer une requête de chat àhttp://${GATEWAY_IP}/v1/chat/completions.
Vous devriez voir une réponse JSON du modèle Qwen :
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Libérer de l'espace
Pour éviter que votre compte Google Cloud ne soit facturé en permanence, supprimez les ressources créées lors de cet atelier.
Exécutez le script de suppression :
./12_teardown_cleanup.sh
À quoi sert le script ?
- Supprime les pools de nœuds GKE (
tpu7-pool-1,tpu7-pool-2). - Supprime le cluster GKE (
tpu-serving-cluster). - Supprime les stratégies de ressources (
superslice-policy). - Supprime les réseaux VPC (
qwen-serving-main).
Si vous avez créé un projet dédié pour cet atelier, vous pouvez également supprimer l'intégralité du projet :
gcloud projects delete ${PROJECT_ID}
13. Félicitations
Félicitations ! Vous avez exploré GKE Dynamic Slicing et déployé une architecture de diffusion LLM désagrégée.
Connaissances acquises
- Comment activer le GKE Slice Controller et configurer des pools de nœuds pour le provisionnement incrémentiel.
- Comment utiliser Kueue pour demander des topologies TPU spécifiques.
- Comment le sous-découpage divise un grand bloc TPU pour des charges de travail JAX plus petites et indépendantes.
- Comment le super-découpage assemble plusieurs pools de nœuds dans une seule tranche TPU virtuelle plus grande.
- Comment déployer la diffusion désagrégée Prefill/Decode à l'aide de LWS, de l'API Gateway et de vLLM.