
1. מבוא
בשיעור Codelab הזה תלמדו איך להשתמש ב-GKE Dynamic Slicing כדי לייעל את השימוש במשאבי Cloud TPU. פילוח דינמי הוא יכולת רבת עוצמה שמאפשרת לכם להפריד בין הקצאת משאבי TPU גולמיים לבין תזמון עומסי עבודה.
בפרט, נסקור שני דפוסים מרכזיים:
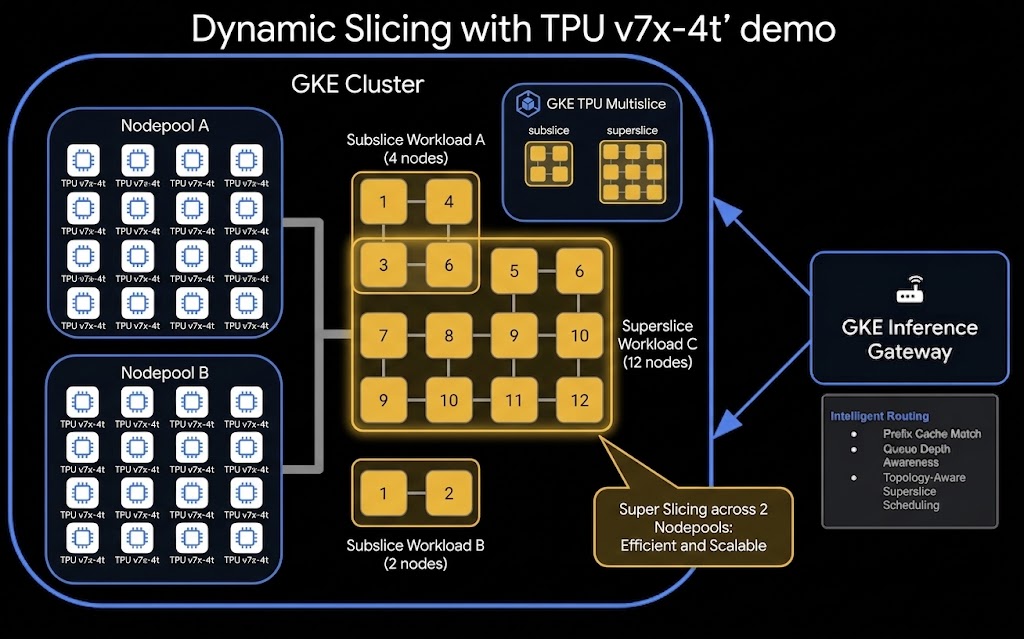
- חלוקה לתת-פרוסות: פיצול של בלוק גדול של TPU שהוקצה לפרוסות קטנות ומבודדות לעומסי עבודה קטנים יותר.
- Super-slicing: שילוב של כמה בלוקים של TPU שהוקצו יחד כדי ליצור פרוסת TPU וירטואלית גדולה יותר לעומסי עבודה גדולים.
תשתמשו בדפוסים האלה כדי לפרוס ארכיטקטורה של הצגה מפוצלת (פיצול מילוי מראש/פענוח) עם ביצועים גבוהים למודל שפה גדול (Qwen 397B) באמצעות Kueue, LeaderWorkerSet (LWS) ו-Gateway API.
ארכיטקטורה
זוהי הארכיטקטורה ברמה גבוהה של הגדרת TPU Dynamic Slicing ו-Disaggregated Serving:
הפעולות שתבצעו:
- הקצאת אשכול GKE עם הפעלת GKE Slice Controller.
- יוצרים מאגרי צמתים של GKE TPU שמוגדרים להקצאה מצטברת.
- פורסים את Kueue ואת LeaderWorkerSet כדי לנהל עומסי עבודה (workloads) של TPU.
- מריצים עומס עבודה של חלוקת משנה כדי לאמת את הגישה ל-TPU של JAX בפרוסות קטנות יותר.
- מריצים עומס עבודה של superslicing כדי לאמת את הגישה ל-TPU של JAX בכמה מאגרי צמתים משולבים.
- פריסת הגדרה של Disaggregated Serving שבה השלבים Prefill ו-Decode מופעלים על פרוסות TPU נפרדות שהוקצו באופן דינמי, בתיאום של נתב LLM.
הדרישות
- דפדפן אינטרנט כמו Chrome.
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- חשוב: גישה להזמנה של Cloud TPU7x (Ironwood) במצב 'כל הקיבולת'.
2. לפני שמתחילים
יצירה או בחירה של פרויקט ב-Google Cloud
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud וכוללת מראש את הכלים הנדרשים.
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, מאמתים את האימות:
gcloud auth list - מוודאים שהפרויקט מוגדר:
gcloud config get project - אם הפרויקט לא מוגדר כמו שציפיתם, מגדירים אותו:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
שכפול מאגר ההדגמה
משכפלים את המאגר שמכיל את המניפסטים ואת הסקריפטים המסייעים ל-Codelab הזה:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. הגדרת הסביבה
לפני הקצאת משאבים, צריך להגדיר את משתני הסביבה. יש סקריפט עזר 01_setup_env.sh ליצירת קובץ env.sh.
מריצים את סקריפט ההגדרה:
./01_setup_env.sh
תתבקשו להזין כמה ערכים. מקישים על [ENTER] כדי לאשר את ברירות המחדל, אבל חשוב לוודא שציינתם את שם ההזמנה ובלוק ההזמנה הנכונים שקיבלתם מהמדריך של האירוע:
- GCP Project ID (מזהה הפרויקט ב-GCP): מזהה הפרויקט הנוכחי.
- מספר הפרויקט ב-GCP: מספר הפרויקט.
- שם אשכול GKE:
tpu-serving-cluster(ברירת מחדל). - TPU Node Pool Zone (אזור מאגר צמתים של TPU):
us-central1-ai1a(ברירת מחדל). - מרחב שמות Kubernetes:
llm-d-pd-disaggregation(ברירת מחדל). - שם ההזמנה של Cloud TPU: [יש להזין את שם ההזמנה שסופק]
- שם בלוק ההזמנה של Cloud TPU:
block-0(ברירת מחדל). - שם קטגוריית GCS למשקלים:
model-weights(ברירת מחדל). - סוג מכונת TPU:
tpu7x-standard-4t(ברירת מחדל). - Hugging Face Token: [Enter your HF token if required, or press ENTER if using pre-loaded weights]
אחרי שמריצים את הסקריפט, מחילים את המשתנים על הסשן הנוכחי:
source env.sh
4. הפעלת ממשקי API ותכונות של AI Zone
אחרי שמגדירים את הסביבה, צריך להפעיל את ממשקי Google Cloud API הנדרשים ואת התכונה 'חשיפה של אזור AI'. יש סקריפט עזר 02_enable_apis_and_features.sh.
מריצים את הסקריפט:
./02_enable_apis_and_features.sh
הסקריפט הזה:
- הפעלת ממשקי ה-API של GKE, Compute, IAM, מנהל המשאבים, Filestore ו-Network Services.
- הפעלת התכונה
ai-zones-visibilityבתצוגה מקדימה ל-GKE Dynamic Slicing.
5. הקצאת משאבים לאשכול GKE ולמאגרי צמתים של TPU
בשלב הזה, תספקו את תשתית הרשת הבסיסית, אשכול GKE ומאגרי צמתים של TPU.
מאגרי צומתי ה-TPU יוגדרו עם הקצאת משאבים מצטברת (באמצעות --placement-policy=superslice-policy ו---reservation-affinity=specific), שממפה כל מאגר צמתים ל'קוביה' (תת-בלוק) של 16 צמתים של קיבולת TPU גולמית.
מריצים את הסקריפט להקצאת הרשאות:
./03_create_cluster_and_nodes.sh
מה הסקריפט הזה עושה:
- יצירת רשת VPC ורשתות משנה: הגדרה של רשת VPC ראשית עם MTU גדול (8896) שעבר אופטימיזציה לתנועת TPU, רשת משנה של TPU ורשת משנה של Proxy בלבד שנדרשת על ידי GKE Gateway.
- Creates GKE Cluster (יצירת אשכול GKE): הקצאת אשכול GKE רגיל עם Slice Controller (בקר הפרוסות) מופעל (
--enable-slice-controller). - Creates Workload Policy (יצירת מדיניות עומס עבודה): מגדיר מדיניות משאבים בשם
superslice-policyמסוגHIGH_THROUGHPUTעם טופולוגיה של4x4x4. - יצירת מאגרי צמתים של GKE TPU: הקצאת שני מאגרי צמתים (
tpu7-pool-1ו-tpu7-pool-2), שכל אחד מהם מכיל 16 צמתים מסוגtpu7x-standard-4t. הם מייצגים שני קוביות נפרדות של 16 צמתים.
אימות הצמתים
אחרי שהסקריפט מסתיים, מוודאים שכל 32 צמתי ה-TPU הוקצו ונרשמו:
kubectl get nodes -l google.com/tpu=present
ברשימה אמורים להופיע 32 צמתים.
6. התקנת כלי תזמור
החלוקה הדינמית מסתמכת על כמה בקרי Kubernetes כדי לתאם את העבודות ואת הקצאת החלוקה. תצטרכו להתקין:
- JobSet: לניהול קבוצת משימות (נדרש ל-superslicing).
- Kueue: לתיוג של משימות בתור, לניהול משאבים ולתזמון מודע לטופולוגיה (TAS).
- LeaderWorkerSet (LWS): לניהול פריסות משוכפלות של TPU מרובות צמתים (נדרש להפעלת LLM).
- GKE Slice Controller (מרחב משתמש): מחבר את Kueue ל-TPU Cluster Director כדי לנהל באופן דינמי את הפרוסות הפיזיות.
מריצים את סקריפט ההתקנה:
./04_install_kueue_lws_slice_controller.sh
מוודאים ש-Slice Controller פועל בצורה תקינה:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. הגדרת משאבים ב-Kueue
עכשיו צריך להגדיר את משאבי Kueue שמייצגים את טופולוגיית חומרת ה-TPU ולקבוע את בדיקות הגישה.
מריצים את סקריפט הפריסה:
./05_deploy_kueue_resources.sh
משאבים עיקריים שהופעלו:
- טופולוגיה (
slice-topology): מגדירה את הרמות ההיררכיות של מחיצות TPU (מבלוק ועד שם המארח) ש-Kueue צריך לקחת בחשבון בתזמון. - ResourceFlavor (
slice-rf): משייך אתslice-topologyלמאיץtpu7x. - AdmissionCheck (
ac): מגדיר את Kueue כך שישתמש ב-GKE Slice Controller (accelerator.gke.io/slice) כדי להקצות באופן דינמי פרוסות כשעבודה מתקבלת. - ClusterQueue (
cq) & LocalQueue (lq): הגדרת התורים שאליהם יישלחו עומסי העבודה. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): מגדיר רמות עדיפות כדי לאפשר קדימות ותזמון לפי עדיפות.
אימות המקורות:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. פריסה ואימות של גישת TPU באמצעות חלוקת משנה
חלוקה משנית מאפשרת להריץ כמה עומסי עבודה קטנים יותר בתוך בלוק TPU מוקצה אחד. בשלב הזה, תשלחו עומס עבודה שמבקש טופולוגיה של 2x2x2 (8 שבבים / 2 מכונות וירטואליות) לאשכול שמורכב מבלוקים של 4x4x4 (64 שבבים / 16 מכונות וירטואליות).
פורסים את עומס העבודה של חלוקת המשנה:
./06_deploy_simple_subslicing.sh
הסקריפט הזה מחיל את kueue-jobset-simple-subslicing.yaml.
איך זה עובד:
- המפרט של JobSet כולל את ההערה
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - היא מגדירה את
replicas: 6ואתparallelism: 2(השלמות: 2). המשמעות היא ש-Kueue יתזמן 6 משימות עצמאיות, שכל אחת מהן מורכבת מ-2 פודים. - כל פוד מבקש
google.com/tpu: "4"(מכונה וירטואלית אחת של TPU). - Kueue ו-GKE Slice Controller מחלקים באופן דינמי את האשכול בן 32 הצמתים כדי להקצות 6 פרוסות של
2x2x2.
אימות הביצוע של JAX
עוקבים אחרי הפודים עד שהם פועלים:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
בודקים את היומנים של אחד מה-pods כדי לוודא ש-JAX זיהה בהצלחה את 8 מכשירי ה-TPU (הליבות) בחלק המשנה שלו:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
הפלט אמור להיראות כך: Total TPU devices (cores): 8
9. פריסה ואימות של גישה ל-TPU באמצעות Superslicing
Super-slicing היא תכונה עוצמתית של GKE שמאפשרת לעומס עבודה יחיד להתפרס על פני כמה בלוקים פיזיים של TPU (שנקראים לעיתים קרובות קוביות או טופולוגיות כמו 4x4x4). על ידי חיבור הבלוקים האלה, אפשר ליצור פרוסה וירטואלית גדולה יותר לעומסי עבודה של אימון או של שרתים בקנה מידה גדול. בשלב הזה תפרסו JobSet שמבקש טופולוגיה של 4x4x8 (128 שבבים / 32 מכונות וירטואליות). מכיוון שכל בלוק 4x4x4 מכיל רק 64 שבבים, עומס העבודה הזה גדול יותר מבלוק אחד, ולכן GKE צריך לחבר באופן דינמי את מאגרי הצמתים tpu7-pool-1 ו-tpu7-pool-2 כדי לענות על הבקשה.
פורסים את עומס העבודה של superslicing:
./07_deploy_simple_superslicing.sh
הסקריפט הזה מחיל את kueue-jobset-simple-superslicing.yaml.
איך זה עובד:
- תבנית JobSet כוללת את ההערה
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - היא מגדירה את
parallelism: 32ואתcompletions: 32. - כל פוד מבקש
google.com/tpu: "4". - מכיוון שטופולוגיית
4x4x8דורשת את כל 32 הצמתים, בקר הפרוסות מגדיר באופן דינמי את רשת ה-OCS (Optical Circuit Switching) כדי לקשר בין שני מאגרי 16 הצמתים לרשת ICI אחת של 32 צמתים.
מוודאים שפודים של JobSet מופעלים בהצלחה ושהמערכת JAX מזהה את כל 128 המכשירים:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
בודקים את היומנים של אחד מה-pods:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
הפלט של JAX אמור להציג את מספר המכשירים הגלובלי: Global device count: 128
10. פריסת הצגה מפוצלת (מילוי מראש/פענוח)
עכשיו תפרסו את מחסנית השרתים של LLM מקצה לקצה באמצעות Prefill/Decode Disaggregation.
בשיטת ההגשה הרגילה, מילוי מראש (עיבוד ההנחיה) ופענוח (יצירת טוקנים) פועלים באותם TPU. מכיוון שמילוי מראש מוגבל על ידי יכולת החישוב ופענוח מוגבל על ידי רוחב הפס של הזיכרון, יש ביניהם התנגשות. בשיטת ההגשה המפוצלת, הם פועלים על פלחי TPU נפרדים, והעברת מטמון KV מתבצעת ברשת.
הגדרה של LLM-D ושל שער
מגדירים את מרחבי השמות, את הסודות של Hugging Face ואת GKE Gateway:
./08_setup_llm_d.sh
פריסת נתב LLM-D
פורסים את הנתב שיקבל בקשות מלקוחות ויתאם את הניתוב בין פרוסות Prefill ו-Decode:
./09_deploy_llm_d_router.sh
פריסת עומסי עבודה של מילוי מראש ופענוח
פריסת שרתי מודלים של vLLM בפרוסות TPU שהוקצו באופן דינמי:
./10_deploy_subslicing_pd_workload.sh
מה קורה:
- פריסה של
kueue-vllm-prefill-model-streamer(LWS מבקש פלח TPU של2x2x2). - פריסה של
kueue-vllm-decode-model-streamer(LWS מבקש פלח TPU של2x2x2). - הפרוסה של המילוי האוטומטי טוענת את משקלי המודל Qwen 397B ופועלת כ-
kv_producer. - הפענוח של הפרוסה פועל כ
kv_consumer. - הם מתקשרים באמצעות
TPUConnectorHMAכדי להעביר מטמוני KV.
מחכים עד ששני הפודים של מילוי מראש ופענוח יפעלו:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. אימות הצגת המודעות
אחרי שמריצים את עומסי העבודה של הנתב, המילוי מראש והפענוח, אפשר לאמת את ה-API של ההצגה.
מריצים את סקריפט האימות:
./11_verify_serving.sh
איך זה עובד:
- הסקריפט מאחזר את כתובת ה-IP הפנימית של GKE Gateway.
- הוא מפעיל באופן זמני פוד (
curl-debug-comp) כדי לשלוח בקשת השלמה אלhttp://${GATEWAY_IP}/v1/completions. - הוא מפעיל עוד פוד (
curl-debug-chat) כדי לשלוח בקשה לצ'אט אלhttp://${GATEWAY_IP}/v1/chat/completions.
אמורה להתקבל תגובת JSON מהמודל Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
מריצים את הסקריפט להסרת המשאבים:
./12_teardown_cleanup.sh
מה הסקריפט הזה עושה:
- מחיקת מאגרי צמתים של GKE (
tpu7-pool-1,tpu7-pool-2). - מחיקת אשכול GKE (
tpu-serving-cluster). - מחיקת מדיניות משאבים (
superslice-policy). - מחיקת רשתות VPC (
qwen-serving-main).
לחלופין, אם יצרתם פרויקט ייעודי בשביל ה-Codelab הזה, אתם יכולים למחוק את הפרויקט כולו:
gcloud projects delete ${PROJECT_ID}
13. מזל טוב
מעולה! הצלחתם לבחון את התכונה 'חלוקה דינמית' ב-GKE ולפרוס ארכיטקטורה של מודל שפה גדול (LLM) מפורק להצגת נתונים.
מה למדתם
- איך מפעילים את GKE Slice Controller ומגדירים מאגרי צמתים להקצאת משאבים מצטברת.
- איך משתמשים ב-Kueue כדי לבקש טופולוגיות ספציפיות של TPU.
- איך Sub-slicing מפצל בלוק גדול של TPU למשימות קטנות ועצמאיות של JAX.
- איך Super-slicing מחבר כמה מאגרי צמתים לפרוסת TPU וירטואלית אחת גדולה יותר.
- איך פורסים מילוי מראש/פענוח של הגשה מפורקת באמצעות LWS, Gateway API ו-vLLM.