
1. Pengantar
Dalam codelab ini, Anda akan mempelajari cara menggunakan Pengirisan Dinamis GKE untuk mengoptimalkan pemanfaatan resource Cloud TPU. Pengirisan dinamis adalah kemampuan canggih yang memungkinkan Anda memisahkan penyediaan TPU mentah dari penjadwalan beban kerja.
Secara khusus, Anda akan mempelajari dua pola utama:
- Sub-slicing: Membagi blok TPU besar yang disediakan menjadi slice yang lebih kecil dan terisolasi untuk workload yang lebih kecil.
- Super-slicing: Menggabungkan beberapa blok TPU yang disediakan untuk membentuk slice virtual yang lebih besar untuk workload skala besar.
Anda akan menerapkan pola ini untuk men-deploy arsitektur Disaggregated Serving (Prefill/Decode disaggregation) berperforma tinggi untuk model bahasa besar (Qwen 397B) menggunakan Kueue, LeaderWorkerSet (LWS), dan Gateway API.
Arsitektur
Berikut adalah arsitektur tingkat tinggi dari penyiapan Penayangan yang Terpisah dan Pengirisan Dinamis TPU:
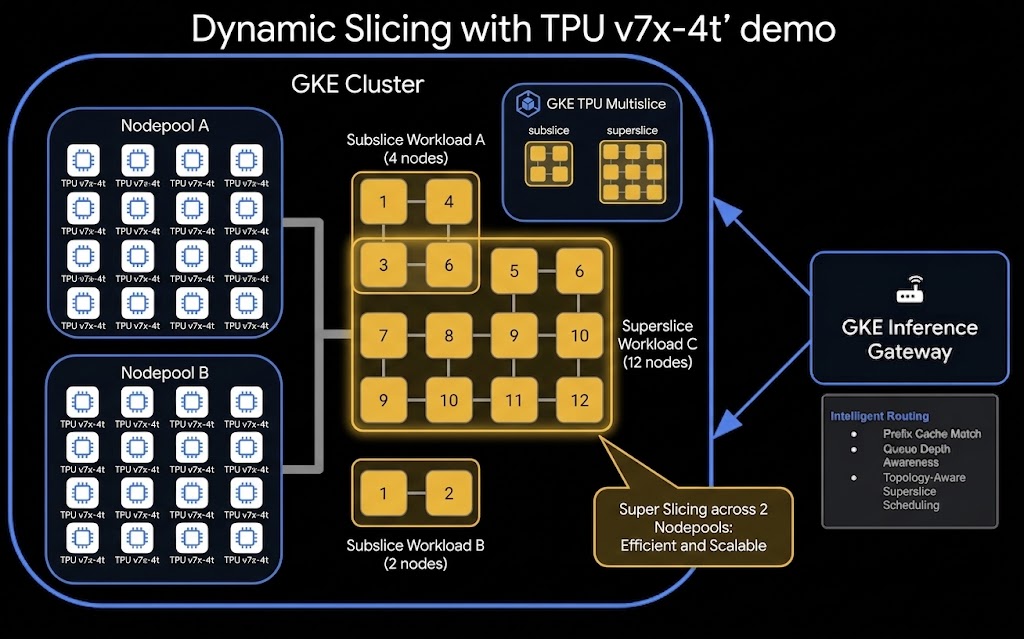
Yang akan Anda lakukan
- Sediakan cluster GKE dengan GKE Slice Controller diaktifkan.
- Buat node pool TPU GKE yang dikonfigurasi untuk penyediaan inkremental.
- Deploy Kueue dan LeaderWorkerSet untuk mengelola workload TPU.
- Jalankan beban kerja subslicing untuk memverifikasi akses JAX TPU pada slice yang lebih kecil.
- Jalankan workload superslicing untuk memverifikasi akses JAX TPU di beberapa node pool gabungan.
- Deploy penyiapan Inferensi Terpisah tempat tahap Pengisian Awal dan Dekode berjalan pada slice TPU terpisah yang dialokasikan secara dinamis, yang dikoordinasikan oleh router LLM.
Yang Anda butuhkan
- Browser web seperti Chrome.
- Project Google Cloud yang mengaktifkan penagihan.
- PENTING: Akses ke pemesanan mode Semua Kapasitas Cloud TPU7x (Ironwood).
2. Sebelum memulai
Buat atau pilih Project Google Cloud
Buat Project Google Cloud
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mulai Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan alat yang diperlukan.
- Klik Activate Cloud Shell di bagian atas konsol Google Cloud.
- Setelah terhubung ke Cloud Shell, verifikasi autentikasi Anda:
gcloud auth list - Pastikan project Anda dikonfigurasi:
gcloud config get project - Jika project Anda tidak ditetapkan seperti yang diharapkan, tetapkan project:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Meng-clone Repositori Demo
Buat clone repositori yang berisi manifes dan skrip penunjang untuk codelab ini:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Mengonfigurasi Lingkungan
Sebelum menyediakan resource, Anda perlu mengonfigurasi variabel lingkungan. Skrip helper 01_setup_env.sh disediakan untuk menghasilkan file env.sh.
Jalankan skrip penyiapan:
./01_setup_env.sh
Anda akan diminta untuk memasukkan beberapa nilai. Tekan [ENTER] untuk menerima nilai default, tetapi pastikan untuk memberikan Nama Reservasi dan Blok Reservasi yang benar yang diberikan oleh instruktur acara Anda:
- Project ID GCP: Project ID Anda saat ini.
- Nomor Project GCP: Nomor project Anda.
- Nama Cluster GKE:
tpu-serving-cluster(default). - Zona Node Pool TPU:
us-central1-ai1a(default). - Namespace Kubernetes:
llm-d-pd-disaggregation(default). - Nama Reservasi Cloud TPU: [Masukkan nama reservasi yang diberikan]
- Nama Blok Pemesanan Cloud TPU:
block-0(default). - Nama Bucket GCS untuk Bobot:
model-weights(default). - Jenis Mesin TPU:
tpu7x-standard-4t(default). - Token Hugging Face: [Masukkan token HF Anda jika diperlukan, atau tekan ENTER jika menggunakan bobot yang telah dimuat sebelumnya]
Setelah menjalankan skrip, terapkan variabel ke sesi Anda saat ini:
source env.sh
4. Mengaktifkan API dan Fitur Zona AI
Setelah lingkungan Anda dikonfigurasi, Anda perlu mengaktifkan Google Cloud API yang diperlukan dan fitur visibilitas Zona AI. Skrip helper 02_enable_apis_and_features.sh disediakan.
Jalankan skrip:
./02_enable_apis_and_features.sh
Skrip ini:
- Mengaktifkan GKE, Compute, IAM, Resource Manager, Filestore, dan Network Services API.
- Mengaktifkan fitur pratinjau
ai-zones-visibilityuntuk Pengirisan Dinamis GKE.
5. Menyediakan Cluster GKE dan Node Pool TPU
Pada langkah ini, Anda akan menyediakan infrastruktur jaringan dasar, cluster GKE, dan TPU node pool.
TPU node pool akan dikonfigurasi dengan Penyediaan Bertahap (menggunakan --placement-policy=superslice-policy dan --reservation-affinity=specific), yang memetakan setiap node pool ke "kubus" (sub-blok) kapasitas TPU mentah 16 node.
Jalankan skrip penyediaan:
./03_create_cluster_and_nodes.sh
Fungsi skrip ini:
- Membuat Jaringan & Subnet VPC: Menyiapkan jaringan VPC utama dengan MTU besar (8896) yang dioptimalkan untuk traffic TPU, subnet TPU, dan subnet khusus proxy yang diperlukan oleh GKE Gateway.
- Membuat Cluster GKE: Menyediakan cluster GKE Standar dengan Slice Controller yang diaktifkan (
--enable-slice-controller). - Membuat Kebijakan Beban Kerja: Menentukan kebijakan resource bernama
superslice-policyberjenisHIGH_THROUGHPUTdengan topologi4x4x4. - Membuat Node Pool TPU GKE: Menyediakan dua node pool (
tpu7-pool-1dantpu7-pool-2), yang masing-masing berisi 16 nodetpu7x-standard-4t. Ini mewakili dua kubus 16 node yang terpisah.
Memverifikasi Node
Setelah skrip selesai, pastikan semua 32 node TPU telah disediakan dan didaftarkan:
kubectl get nodes -l google.com/tpu=present
Anda akan melihat 32 node dalam daftar.
6. Menginstal Alat Orkestrasi
Pengirisan dinamis mengandalkan beberapa pengontrol Kubernetes untuk mengoordinasikan tugas dan alokasi irisan. Anda akan menginstal:
- JobSet: Untuk mengelola grup tugas (diperlukan untuk superslicing).
- Kueue: Untuk antrean, pengelolaan resource, dan Penjadwalan yang Mendukung Topologi (TAS).
- LeaderWorkerSet (LWS): Untuk mengelola deployment TPU multi-node yang direplikasi (diperlukan untuk penayangan LLM).
- Pengontrol Slice GKE (Ruang Pengguna): Menghubungkan Kueue dengan Cluster Director TPU untuk mengelola slice fisik secara dinamis.
Jalankan skrip penginstalan:
./04_install_kueue_lws_slice_controller.sh
Pastikan bahwa Slice Controller berhasil berjalan:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Mengonfigurasi Resource Kueue
Sekarang Anda perlu menentukan resource Kueue yang merepresentasikan topologi hardware TPU dan mengonfigurasi pemeriksaan penerimaan.
Jalankan skrip deployment:
./05_deploy_kueue_resources.sh
Resource Utama yang Di-deploy:
- Topologi (
slice-topology): Menentukan tingkat hierarki partisi TPU (dari blok hingga nama host) yang harus dipertimbangkan Kueue saat menjadwalkan. - ResourceFlavor (
slice-rf): Mengaitkanslice-topologydengan akseleratortpu7x. - AdmissionCheck (
ac): Mengonfigurasi Kueue untuk menggunakan Pengontrol Slice GKE (accelerator.gke.io/slice) guna menyediakan slice secara dinamis saat tugas diterima. - ClusterQueue (
cq) & LocalQueue (lq): Menyiapkan antrean tempat beban kerja akan dikirimkan. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): Menentukan tingkat prioritas untuk mengaktifkan penjadwalan berbasis prioritas dan pendahuluan.
Verifikasi resource:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Men-deploy dan memverifikasi Akses TPU dengan Subslicing
Dengan sub-slicing, Anda dapat menjalankan beberapa workload yang lebih kecil dalam satu blok TPU yang disediakan. Pada langkah ini, Anda akan mengirimkan workload yang meminta topologi 2x2x2 (8 chip / 2 VM) ke cluster yang dibuat dari blok 4x4x4 (64 chip / 16 VM).
Deploy workload subslicing:
./06_deploy_simple_subslicing.sh
Skrip ini menerapkan kueue-jobset-simple-subslicing.yaml.
Cara kerjanya:
- Spesifikasi JobSet mencakup anotasi
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Mengonfigurasi
replicas: 6danparallelism: 2(penyelesaian: 2). Artinya, Kueue akan menjadwalkan 6 tugas independen, yang masing-masing terdiri dari 2 pod. - Setiap pod meminta
google.com/tpu: "4"(1 TPU VM). - Kueue dan Pengontrol Slice GKE secara dinamis membagi cluster 32 node untuk mengalokasikan enam slice
2x2x2.
Memverifikasi eksekusi JAX
Pantau pod hingga berjalan:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Periksa log salah satu pod untuk memverifikasi bahwa JAX berhasil mendeteksi 8 perangkat TPU (core) pada sub-slice-nya:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Anda akan melihat output yang menunjukkan: Total TPU devices (cores): 8
9. Men-deploy dan memverifikasi Akses TPU dengan Superslicing
Super-slicing adalah fitur GKE canggih yang memungkinkan satu workload mencakup beberapa blok TPU fisik (sering disebut sebagai kubus atau topologi seperti 4x4x4). Dengan menggabungkan blok-blok ini, Anda dapat membentuk slice virtual yang lebih besar untuk workload pelatihan atau penayangan skala besar. Pada langkah ini, Anda akan men-deploy JobSet yang meminta topologi 4x4x8 (128 chip / 32 VM). Karena satu blok 4x4x4 hanya berisi 64 chip, workload ini melebihi ukuran satu blok dan mengharuskan GKE menggabungkan node pool tpu7-pool-1 dan tpu7-pool-2 secara dinamis untuk memenuhi permintaan.
Deploy workload superslicing:
./07_deploy_simple_superslicing.sh
Skrip ini menerapkan kueue-jobset-simple-superslicing.yaml.
Cara kerjanya:
- Template JobSet menyertakan anotasi
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Class ini mengonfigurasi
parallelism: 32dancompletions: 32. - Setiap pod meminta
google.com/tpu: "4". - Karena topologi
4x4x8memerlukan semua 32 node, Pengontrol Slice secara dinamis mengonfigurasi jaringan OCS (Optical Circuit Switching) untuk menghubungkan dua kumpulan 16 node menjadi mesh ICI 32 node tunggal.
Pastikan pod JobSet berhasil berjalan dan JAX mendeteksi semua 128 perangkat:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Periksa log salah satu pod:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Anda akan melihat output JAX yang menampilkan jumlah perangkat global: Global device count: 128
10. Men-deploy Penayangan yang Terpisah (Pengisian Awal/Dekode)
Sekarang Anda akan men-deploy stack penayangan LLM end-to-end menggunakan Pemisahan Pengisian Awal/Dekode.
Dalam penayangan standar, pengisian awal (pemrosesan perintah) dan dekode (pembuatan token) berjalan di TPU yang sama. Karena pengisian otomatis terikat pada komputasi dan decoding terikat pada bandwidth memori, keduanya bertentangan. Penayangan yang diuraikan menjalankannya pada slice TPU terpisah, mentransfer Cache KV melalui jaringan.
Menyiapkan LLM-D dan Gateway
Siapkan namespace, secret Hugging Face, dan GKE Gateway:
./08_setup_llm_d.sh
Men-deploy Router LLM-D
Deploy router yang akan menerima permintaan klien dan mengoordinasikan perutean antara slice Isi Otomatis dan Dekode:
./09_deploy_llm_d_router.sh
Men-deploy Beban Kerja Pengisian Otomatis dan Dekode
Deploy server model vLLM pada slice TPU yang dialokasikan secara dinamis:
./10_deploy_subslicing_pd_workload.sh
Fungsi langkah ini:
- Men-deploy
kueue-vllm-prefill-model-streamer(LWS meminta slice TPU2x2x2). - Men-deploy
kueue-vllm-decode-model-streamer(LWS meminta slice TPU2x2x2). - Slice pengisian otomatis memuat bobot model Qwen 397B dan bertindak sebagai
kv_producer. - Slice dekode bertindak sebagai
kv_consumer. - Mereka berkomunikasi menggunakan
TPUConnectorHMAuntuk mentransfer cache KV.
Tunggu hingga pod pengisian otomatis dan dekode berjalan:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Memverifikasi Penayangan
Dengan menjalankan beban kerja router, pengisian otomatis, dan decoding, Anda kini dapat memverifikasi API penayangan.
Jalankan skrip verifikasi:
./11_verify_serving.sh
Cara kerjanya:
- Skrip mengambil IP internal GKE Gateway.
- Fungsi ini meluncurkan pod sementara (
curl-debug-comp) untuk mengirim permintaan penyelesaian kehttp://${GATEWAY_IP}/v1/completions. - Aplikasi ini akan meluncurkan pod lain (
curl-debug-chat) untuk mengirim permintaan chat kehttp://${GATEWAY_IP}/v1/chat/completions.
Anda akan melihat respons JSON yang berhasil dari model Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Pembersihan
Untuk menghindari biaya berkelanjutan pada akun Google Cloud Anda, hapus resource yang dibuat selama codelab ini.
Jalankan skrip penonaktifan:
./12_teardown_cleanup.sh
Fungsi skrip ini:
- Menghapus kumpulan node GKE (
tpu7-pool-1,tpu7-pool-2). - Menghapus Cluster GKE (
tpu-serving-cluster). - Menghapus kebijakan resource (
superslice-policy). - Menghapus jaringan VPC (
qwen-serving-main).
Atau, jika Anda membuat project khusus untuk codelab ini, Anda dapat menghapus seluruh project:
gcloud projects delete ${PROJECT_ID}
13. Selamat
Selamat! Anda telah berhasil mempelajari GKE Dynamic Slicing dan men-deploy arsitektur Disaggregated LLM Serving.
Yang telah Anda pelajari
- Cara mengaktifkan Pengontrol Slice GKE dan mengonfigurasi node pool untuk Penyediaan Bertahap.
- Cara menggunakan Kueue untuk meminta topologi TPU tertentu.
- Cara Sub-slicing membagi blok TPU besar untuk workload JAX yang lebih kecil dan independen.
- Cara Super-slicing menggabungkan beberapa node pool menjadi satu slice TPU virtual yang lebih besar.
- Cara men-deploy Penayangan yang dipisah-pisahkan dengan pengisian otomatis/dekode menggunakan LWS, Gateway API, dan vLLM.