
1. Introduzione
In questo codelab imparerai a utilizzare GKE Dynamic Slicing per ottimizzare l'utilizzo delle risorse Cloud TPU. Il slicing dinamico è una funzionalità potente che ti consente di disaccoppiare il provisioning TPU non elaborato dalla pianificazione dei carichi di lavoro.
Nello specifico, esplorerai due pattern chiave:
- Sub-slicing: suddivisione di un blocco TPU di cui è stato eseguito il provisioning di grandi dimensioni in slice più piccole e isolate per carichi di lavoro più piccoli.
- Super-slicing: unione di più blocchi TPU di cui è stato eseguito il provisioning per formare una slice virtuale più grande per carichi di lavoro su larga scala.
Applicherai questi pattern per eseguire il deployment di un'architettura Disaggregated Serving (Prefill/Decode disaggregation) ad alte prestazioni per un modello linguistico di grandi dimensioni (Qwen 397B) utilizzando Kueue, LeaderWorkerSet (LWS) e Gateway API.
Architettura
Di seguito è riportata l'architettura di alto livello della configurazione di TPU Dynamic Slicing e Disaggregated Serving:
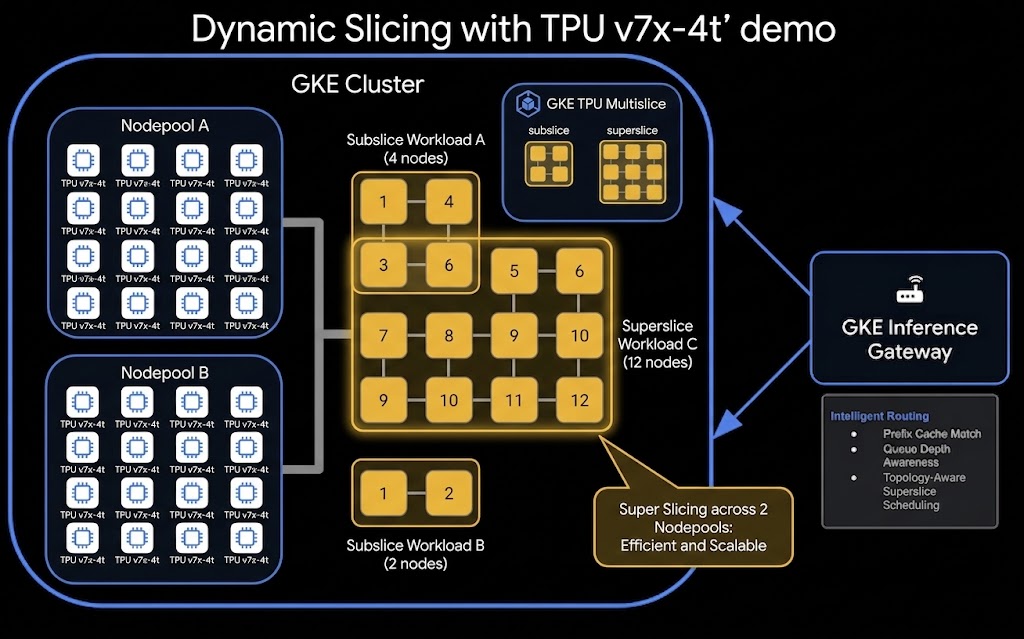
In questo lab proverai a:
- Eseguire il provisioning di un cluster GKE con GKE Slice Controller abilitato.
- Creare node pool TPU GKE configurati per il provisioning incrementale.
- Eseguire il deployment di Kueue e LeaderWorkerSet per gestire i carichi di lavoro TPU.
- Eseguire un carico di lavoro di subslicing per verificare l'accesso JAX TPU su slice più piccole.
- Eseguire un carico di lavoro di superslicing per verificare l'accesso JAX TPU su più node pool combinati.
- Eseguire il deployment di una configurazione di Disaggregated Serving in cui le fasi di prefill e decodifica vengono eseguite su slice TPU separate e allocate dinamicamente, coordinate da un router LLM.
Che cosa ti serve
- Un browser web come Chrome.
- Un progetto Google Cloud con la fatturazione abilitata.
- IMPORTANTE: accesso a una prenotazione in modalità All Capacity di Cloud TPU7x (Ironwood).
2. Prima di iniziare
Crea o seleziona un progetto Google Cloud
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene fornito con gli strumenti necessari precaricati.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta eseguita la connessione a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Clona il repository demo
Clona il repository contenente i manifest e gli script di supporto per questo codelab:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Configura ambiente
Prima di eseguire il provisioning delle risorse, devi configurare le variabili di ambiente. Viene fornito uno script di supporto 01_setup_env.sh per generare un file env.sh.
Esegui lo script di configurazione:
./01_setup_env.sh
Ti verrà richiesto di inserire diversi valori. Premi [INVIO] per accettare i valori predefiniti, ma assicurati di fornire il nome della prenotazione e il blocco di prenotazione corretti forniti dall'istruttore dell'evento:
- ID progetto Google Cloud: l'ID del progetto corrente.
- Numero progetto Google Cloud: il numero del progetto.
- Nome cluster GKE:
tpu-serving-cluster(valore predefinito). - Zona node pool TPU:
us-central1-ai1a(valore predefinito). - Spazio dei nomi Kubernetes:
llm-d-pd-disaggregation(valore predefinito). - Nome prenotazione Cloud TPU: [Inserisci il nome della prenotazione fornito]
- Nome blocco prenotazione Cloud TPU:
block-0(valore predefinito). - Nome bucket GCS per i pesi:
model-weights(valore predefinito). - Tipo di macchina TPU:
tpu7x-standard-4t(valore predefinito). - Token Hugging Face: [Inserisci il token HF, se necessario, o premi INVIO se utilizzi i pesi precaricati]
Dopo aver eseguito lo script, applica le variabili alla sessione corrente:
source env.sh
4. Abilita API e funzionalità della zona AI
Ora che l'ambiente è configurato, devi abilitare le API Google Cloud richieste e la funzionalità di visibilità della zona AI. Viene fornito uno script di supporto 02_enable_apis_and_features.sh.
Esegui lo script:
./02_enable_apis_and_features.sh
Questo script:
- Abilita le API GKE, Compute, IAM, Resource Manager, Filestore e Network Services.
- Abilita la funzionalità di anteprima
ai-zones-visibilityper GKE Dynamic Slicing.
5. Esegui il provisioning del cluster GKE e dei node pool TPU
In questo passaggio, eseguirai il provisioning dell'infrastruttura di rete sottostante, del cluster GKE e dei node pool TPU.
I node pool TPU verranno configurati con il provisioning incrementale (utilizzando --placement-policy=superslice-policy e --reservation-affinity=specific), che mappa ogni node pool a un "cubo" (sottoblocco) di capacità TPU non elaborata di 16 nodi.
Esegui lo script di provisioning:
./03_create_cluster_and_nodes.sh
Funzionalità dello script:
- Crea rete VPC e subnet: configura una rete VPC principale con un MTU di grandi dimensioni (8896) ottimizzato per il traffico TPU, una subnet TPU e una subnet solo proxy richiesta da GKE Gateway.
- Crea cluster GKE: esegue il provisioning di un cluster GKE standard con Slice Controller abilitato (
--enable-slice-controller). - Crea policy del carico di lavoro: definisce una policy delle risorse denominata
superslice-policydi tipoHIGH_THROUGHPUTcon una topologia di4x4x4. - Crea node pool TPU GKE: esegue il provisioning di due node pool (
tpu7-pool-1etpu7-pool-2), ognuno contenente 16 nodi ditpu7x-standard-4t. Questi rappresentano due cubi separati di 16 nodi.
Verifica i nodi
Al termine dello script, verifica che sia stato eseguito il provisioning e la registrazione di tutti i 32 nodi TPU:
kubectl get nodes -l google.com/tpu=present
Nell'elenco dovresti vedere 32 nodi.
6. Installa gli strumenti di orchestrazione
Il slicing dinamico si basa su diversi controller Kubernetes per coordinare i job e l'allocazione delle slice. Installerai:
- JobSet: per la gestione di gruppi di job (necessario per il superslicing).
- Kueue: per l'accodamento, la gestione delle risorse e la pianificazione sensibile alla topologia (TAS).
- LeaderWorkerSet (LWS): per la gestione dei deployment TPU multi-nodo replicati (necessario per la gestione di LLM).
- GKE Slice Controller (spazio utente): collega Kueue a TPU Cluster Director per gestire dinamicamente le slice fisiche.
Esegui lo script di installazione:
./04_install_kueue_lws_slice_controller.sh
Verifica che Slice Controller sia in esecuzione correttamente:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Configura le risorse Kueue
Ora devi definire le risorse Kueue che rappresentano la topologia hardware TPU e configurare i controlli di ammissione.
Esegui lo script di deployment:
./05_deploy_kueue_resources.sh
Risorse chiave di cui è stato eseguito il deployment:
- Topologia (
slice-topology): definisce i livelli gerarchici delle partizioni TPU (dal blocco al nome host) che Kueue deve considerare durante la pianificazione. - ResourceFlavor (
slice-rf): associaslice-topologyall'acceleratoretpu7x. - AdmissionCheck (
ac): configura Kueue in modo che utilizzi GKE Slice Controller (accelerator.gke.io/slice) per eseguire il provisioning dinamico delle slice quando viene ammesso un job. - ClusterQueue (
cq) & LocalQueue (lq): configura le code a cui verranno inviati i carichi di lavoro. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): definisce i livelli di priorità per abilitare la sottrazione e la pianificazione basata sulla priorità.
Verifica le risorse:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Esegui il deployment e verifica l'accesso TPU con il subslicing
Il subslicing ti consente di eseguire più carichi di lavoro più piccoli all'interno di un singolo blocco TPU di cui è stato eseguito il provisioning. In questo passaggio, invierai un carico di lavoro che richiede una topologia 2x2x2 (8 chip / 2 VM) a un cluster composto da blocchi 4x4x4 (64 chip / 16 VM).
Esegui il deployment del carico di lavoro di subslicing:
./06_deploy_simple_subslicing.sh
Questo script applica kueue-jobset-simple-subslicing.yaml.
Come funziona:
- La specifica JobSet include l'annotazione
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Configura
replicas: 6eparallelism: 2(completions: 2). Ciò significa che Kueue pianificherà 6 job indipendenti, ognuno composto da 2 pod. - Ogni pod richiede
google.com/tpu: "4"(1 VM TPU). - Kueue e GKE Slice Controller ritagliano dinamicamente il cluster di 32 nodi per allocare sei slice
2x2x2.
Verifica l'esecuzione di JAX
Monitora i pod finché non sono in esecuzione:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Controlla i log di uno dei pod per verificare che JAX abbia rilevato correttamente gli 8 dispositivi TPU (core) nella sua sottosezione:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Dovresti vedere un output che indica: Total TPU devices (cores): 8
9. Esegui il deployment e verifica l'accesso TPU con il superslicing
Il superslicing è una potente funzionalità GKE che consente a un singolo carico di lavoro di estendersi su più blocchi TPU fisici (spesso chiamati cubi o topologie come 4x4x4). Unendo questi blocchi, puoi formare una slice virtuale più grande per carichi di lavoro di addestramento o gestione su larga scala. In questo passaggio, eseguirai il deployment di un JobSet che richiede una topologia 4x4x8 (128 chip / 32 VM). Poiché un singolo blocco 4x4x4 contiene solo 64 chip, questo carico di lavoro supera le dimensioni di un singolo blocco e richiede a GKE di unire dinamicamente i node pool tpu7-pool-1 e tpu7-pool-2 per soddisfare la richiesta.
Esegui il deployment del carico di lavoro di superslicing:
./07_deploy_simple_superslicing.sh
Questo script applica kueue-jobset-simple-superslicing.yaml.
Come funziona:
- Il modello JobSet include l'annotazione
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Configura
parallelism: 32ecompletions: 32. - Ogni pod richiede
google.com/tpu: "4". - Poiché una topologia
4x4x8richiede tutti i 32 nodi, Slice Controller configura dinamicamente la rete OCS (Optical Circuit Switching) per interconnettere i due pool di 16 nodi in una singola mesh ICI di 32 nodi.
Verifica che i pod JobSet vengano eseguiti correttamente e che JAX rilevi tutti i 128 dispositivi:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Controlla i log di uno dei pod:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Dovresti vedere l'output JAX che mostra il conteggio globale dei dispositivi: Global device count: 128
10. Esegui il deployment di Disaggregated Serving (Prefill/Decode)
Ora eseguirai il deployment dello stack di gestione LLM end-to-end utilizzando Prefill/Decode Disaggregation.
Nella gestione standard, il prefill (elaborazione del prompt) e la decodifica (generazione di token) vengono eseguiti sulle stesse TPU. Poiché il prefill è vincolato al calcolo e la decodifica è vincolata alla larghezza di banda della memoria, si verificano conflitti. La gestione disaggregata li esegue su slice TPU separate, trasferendo la cache KV sulla rete.
Configura LLM-D e Gateway
Configura gli spazi dei nomi, i secret di Hugging Face e GKE Gateway:
./08_setup_llm_d.sh
Esegui il deployment del router LLM-D
Esegui il deployment del router che riceverà le richieste dei client e coordinerà il routing tra le slice di prefill e decodifica:
./09_deploy_llm_d_router.sh
Esegui il deployment dei carichi di lavoro di prefill e decodifica
Esegui il deployment dei server di modelli vLLM su slice TPU allocate dinamicamente:
./10_deploy_subslicing_pd_workload.sh
Funzionalità:
- Esegue il deployment di
kueue-vllm-prefill-model-streamer(LWS che richiede una slice TPU2x2x2). - Esegue il deployment di
kueue-vllm-decode-model-streamer(LWS che richiede una slice TPU2x2x2). - La slice di prefill carica i pesi del modello Qwen 397B e funge da
kv_producer. - La slice di decodifica funge da
kv_consumer. - Comunicano utilizzando
TPUConnectorHMAper trasferire le cache KV.
Attendi che i pod di prefill e decodifica siano in esecuzione:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Verifica la gestione
Con i carichi di lavoro del router, di prefill e di decodifica in esecuzione, ora puoi verificare l'API di gestione.
Esegui lo script di verifica:
./11_verify_serving.sh
Come funziona:
- Lo script recupera l'IP interno di GKE Gateway.
- Avvia un pod temporaneo (
curl-debug-comp) per inviare una richiesta di completamento ahttp://${GATEWAY_IP}/v1/completions. - Avvia un altro pod (
curl-debug-chat) per inviare una richiesta di chat ahttp://${GATEWAY_IP}/v1/chat/completions.
Dovresti vedere una risposta JSON riuscita dal modello Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Libera spazio
Per evitare addebiti continui sul tuo account Google Cloud, elimina le risorse create durante questo codelab.
Esegui lo script di eliminazione:
./12_teardown_cleanup.sh
Funzionalità dello script:
- Elimina i node pool GKE (
tpu7-pool-1,tpu7-pool-2). - Elimina il cluster GKE (
tpu-serving-cluster). - Elimina le policy delle risorse (
superslice-policy). - Elimina le reti VPC (
qwen-serving-main).
In alternativa, se hai creato un progetto dedicato per questo codelab, puoi eliminare l'intero progetto:
gcloud projects delete ${PROJECT_ID}
13. Complimenti
Complimenti! Hai esplorato correttamente GKE Dynamic Slicing e hai eseguito il deployment di un'architettura di gestione LLM disaggregata.
Che cosa hai imparato
- Come abilitare GKE Slice Controller e configurare i node pool per il provisioning incrementale.
- Come utilizzare Kueue per richiedere topologie TPU specifiche.
- Come il subslicing suddivide un blocco TPU di grandi dimensioni per carichi di lavoro JAX più piccoli e indipendenti.
- Come il superslicing unisce più node pool in una singola slice TPU virtuale più grande.
- Come eseguire il deployment della gestione disaggregata di prefill/decodifica utilizzando LWS, Gateway API e vLLM.