
1. はじめに
この Codelab では、GKE 動的スライスを使用して Cloud TPU リソースの使用率を最適化する方法について説明します。動的スライスは、未加工の TPU プロビジョニングをワークロード スケジューリングから切り離すことができる強力な機能です。
具体的には、次の 2 つの主要なパターンについて説明します。
- サブスライス: プロビジョニングされた大きな TPU ブロックを、小さなワークロード用に分離された小さなスライスに分割します。
- スーパー スライス: プロビジョニングされた複数の TPU ブロックを結合して、大規模なワークロード用のより大きな仮想スライスを形成します。
これらのパターンを適用して、Kueue、LeaderWorkerSet(LWS)、Gateway API を使用して、大規模言語モデル(Qwen 397B)用の高パフォーマンスの分離型サービング(プリフィル/デコードの分離)アーキテクチャをデプロイします。
アーキテクチャ
TPU 動的スライスと分離型サービングの設定のアーキテクチャの概要は次のとおりです。
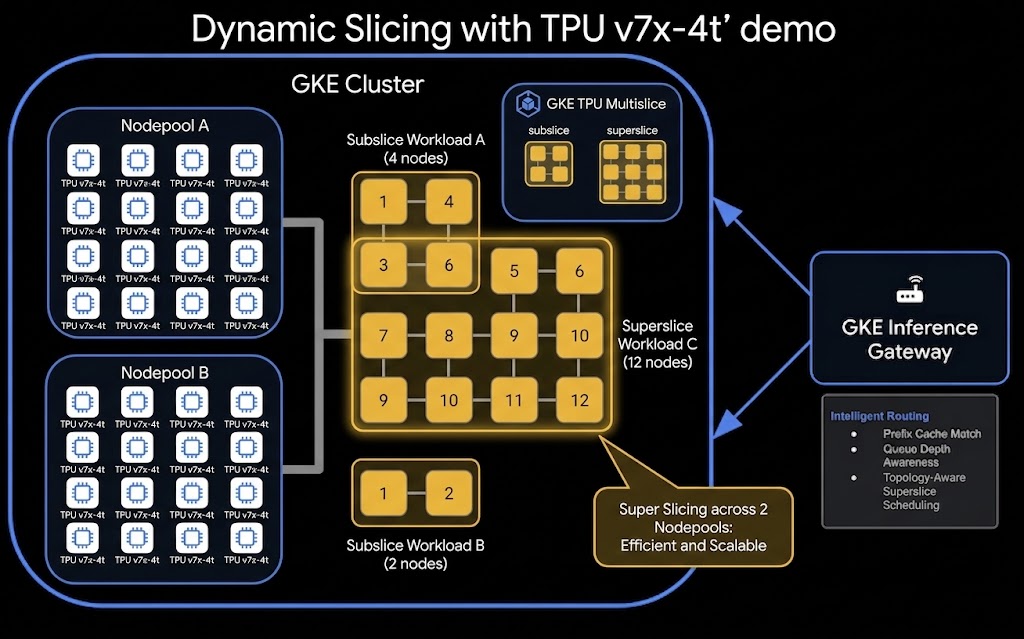
演習内容
- GKE Slice Controller が有効になっている GKE クラスタをプロビジョニングします。
- 増分プロビジョニング用に構成された GKE TPU ノードプールを作成します。
- Kueue と LeaderWorkerSet をデプロイして、TPU ワークロードを管理します。
- サブスライス ワークロードを実行して、小さいスライスで JAX TPU アクセスを確認します。
- スーパースライス ワークロードを実行して、複数の結合されたノードプールにわたる JAX TPU アクセスを確認します。
- LLM ルーターによって調整され、プレフィル ステージとデコード ステージが別々の動的に割り当てられた TPU スライスで実行される分離型サービング設定をデプロイします。
必要なもの
- ウェブブラウザ(Chrome など)。
- 課金を有効にした Google Cloud プロジェクト
- 重要: Cloud TPU7x(Ironwood)All Capacity モードの予約へのアクセス。
2. 始める前に
Google Cloud プロジェクトを作成または選択する
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
デモリポジトリのクローンを作成する
この Codelab のマニフェストとヘルパースクリプトを含むリポジトリのクローンを作成します。
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. 環境を構成する
リソースをプロビジョニングする前に、環境変数を構成する必要があります。env.sh ファイルを生成するためのヘルパー スクリプト 01_setup_env.sh が用意されています。
設定スクリプトを実行します。
./01_setup_env.sh
いくつかの値を入力するよう求められます。[ENTER] キーを押してデフォルトを受け入れますが、イベントの講師から提供された正しい予約名と予約ブロックを指定してください。
- GCP プロジェクト ID: 現在のプロジェクト ID。
- GCP プロジェクト番号: プロジェクト番号。
- GKE クラスタ名:
tpu-serving-cluster(デフォルト)。 - TPU ノードプール ゾーン:
us-central1-ai1a(デフォルト)。 - Kubernetes Namespace:
llm-d-pd-disaggregation(デフォルト)。 - Cloud TPU 予約名: [指定された予約名を入力]
- Cloud TPU 予約ブロック名:
block-0(デフォルト)。 - 重みの GCS バケット名:
model-weights(デフォルト)。 - TPU マシンタイプ:
tpu7x-standard-4t(デフォルト)。 - Hugging Face トークン: [必要に応じて HF トークンを入力するか、事前読み込み済みの重みを使用する場合は Enter キーを押します]
スクリプトを実行したら、現在のセッションに変数を適用します。
source env.sh
4. API と AI Zone の機能を有効にする
環境が構成されたので、必要な Google Cloud APIs と AI Zone の可視性機能を有効にする必要があります。ヘルパースクリプト 02_enable_apis_and_features.sh が用意されています。
スクリプトを実行します。
./02_enable_apis_and_features.sh
このスクリプトは次のようになります。
- GKE、Compute、IAM、Resource Manager、Filestore、Network Services API を有効にします。
- GKE 動的スライシングの
ai-zones-visibilityプレビュー機能を有効にします。
5. GKE クラスタと TPU ノードプールをプロビジョニングする
このステップでは、基盤となるネットワーク インフラストラクチャ、GKE クラスタ、TPU ノードプールをプロビジョニングします。
TPU ノードプールは、増分プロビジョニング(--placement-policy=superslice-policy と --reservation-affinity=specific を使用)で構成されます。これにより、各ノードプールが TPU 容量の 16 ノードの「キューブ」(サブブロック)にマッピングされます。
プロビジョニング スクリプトを実行します。
./03_create_cluster_and_nodes.sh
このスクリプトの処理内容:
- VPC ネットワークとサブネットを作成する: TPU トラフィック用に最適化された大きな MTU(8896)を持つメイン VPC ネットワーク、TPU サブネット、GKE Gateway に必要なプロキシ専用サブネットを設定します。
- GKE クラスタを作成する: Slice Controller が有効になっている Standard GKE クラスタをプロビジョニングします(
--enable-slice-controller)。 - ワークロード ポリシーを作成する: トポロジが
4x4x4のタイプHIGH_THROUGHPUTのsuperslice-policyという名前のリソース ポリシーを定義します。 - GKE TPU ノードプールを作成する: 2 つのノードプール(
tpu7-pool-1とtpu7-pool-2)をプロビジョニングします。各ノードプールには 16 個のtpu7x-standard-4tノードが含まれています。これらは、2 つの別々の 16 ノード キューブを表します。
ノードを確認する
スクリプトが完了したら、32 個の TPU ノードがすべてプロビジョニングされ、登録されていることを確認します。
kubectl get nodes -l google.com/tpu=present
リストに 32 個のノードが表示されます。
6. オーケストレーション ツールをインストールする
動的スライスは、複数の Kubernetes コントローラを使用してジョブとスライス割り当てを調整します。インストールするものは次のとおりです。
- JobSet: ジョブのグループを管理します(スーパースライシングに必要)。
- Kueue: キューイング、リソース管理、トポロジを考慮したスケジューリング(TAS)に使用します。
- LeaderWorkerSet(LWS): 複製されたマルチノード TPU デプロイを管理します(LLM サービングに必要)。
- GKE Slice Controller(ユーザー空間): Kueue を TPU Cluster Director に接続して、物理スライスを動的に管理します。
インストール スクリプトを実行します。
./04_install_kueue_lws_slice_controller.sh
Slice Controller が正常に実行されていることを確認します。
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Kueue リソースを構成する
次に、TPU ハードウェア トポロジを表す Kueue リソースを定義し、アドミッション チェックを構成する必要があります。
次のようにデプロイ スクリプトを実行します。
./05_deploy_kueue_resources.sh
デプロイされた主なリソース:
- トポロジ(
slice-topology): スケジューリング時に Kueue が考慮する必要がある TPU パーティションの階層レベル(ブロックからホスト名まで)を定義します。 - ResourceFlavor(
slice-rf):slice-topologyをtpu7xアクセラレータに関連付けます。 - AdmissionCheck(
ac): ジョブが承認されたときに、GKE Slice Controller(accelerator.gke.io/slice)を使用してスライスを動的にプロビジョニングするように Kueue を構成します。 - ClusterQueue(
cq)と LocalQueue(lq): ワークロードの送信先となるキューを設定します。 - WorkloadPriorityClass(
low-priority-1000、medium-priority-2000、high-priority-3000): 優先度レベルを定義して、プリエンプションと優先度ベースのスケジューリングを有効にします。
リソースを確認します。
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. サブスライスを使用して TPU アクセスをデプロイして検証する
サブスライスを使用すると、プロビジョニングされた単一の TPU ブロック内で複数の小さなワークロードを実行できます。このステップでは、4x4x4(64 チップ / 16 VM)ブロックで構成されたクラスタに 2x2x2 トポロジ(8 チップ / 2 VM)をリクエストするワークロードを送信します。
サブスライス ワークロードをデプロイします。
./06_deploy_simple_subslicing.sh
このスクリプトは kueue-jobset-simple-subslicing.yaml を適用します。
仕組み:
- JobSet 仕様には、アノテーション
cloud.google.com/gke-tpu-slice-topology: 2x2x2が含まれています。 replicas: 6とparallelism: 2(補完: 2)を構成します。つまり、Kueue はそれぞれ 2 つの Pod で構成される 6 つの独立したジョブをスケジュールします。- 各 Pod は
google.com/tpu: "4"(1 つの TPU VM)をリクエストします。 - Kueue と GKE Slice Controller は、32 ノードのクラスタを動的に分割して、6 つの
2x2x2スライスを割り当てます。
JAX の実行を確認する
Pod が実行されるまでモニタリングします。
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
いずれかの Pod のログを調べて、JAX がサブスライス上の 8 個の TPU デバイス(コア)を正常に検出したことを確認します。
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Total TPU devices (cores): 8 を示す出力が表示されます。
9. スーパースライシングを使用して TPU アクセスをデプロイして検証する
スーパー スライスは、単一のワークロードが複数の物理 TPU ブロック(キューブや 4x4x4 などのトポロジと呼ばれることが多い)にまたがることを可能にする強力な GKE 機能です。これらのブロックを結合することで、大規模なトレーニング ワークロードやサービング ワークロード用の大規模な仮想スライスを形成できます。このステップでは、4x4x8 トポロジ(128 個のチップ / 32 個の VM)をリクエストする JobSet をデプロイします。1 つの 4x4x4 ブロックには 64 個のチップしか含まれていないため、このワークロードは 1 つのブロックのサイズを超えています。このリクエストを満たすには、GKE が tpu7-pool-1 ノードプールと tpu7-pool-2 ノードプールを動的に結合する必要があります。
スーパースライシング ワークロードをデプロイします。
./07_deploy_simple_superslicing.sh
このスクリプトは kueue-jobset-simple-superslicing.yaml を適用します。
仕組み:
- JobSet テンプレートには、アノテーション
cloud.google.com/gke-tpu-slice-topology: 4x4x8が含まれています。 parallelism: 32とcompletions: 32を構成します。- 各 Pod が
google.com/tpu: "4"をリクエストします。 4x4x8トポロジでは 32 個のノードがすべて必要になるため、Slice Controller は OCS(光回路スイッチング)ネットワークを動的に構成して、2 つの 16 ノードプールを 1 つの 32 ノード ICI メッシュに相互接続します。
JobSet Pod が正常に実行され、JAX が 128 個のデバイスをすべて検出していることを確認します。
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
いずれかの Pod のログを確認します。
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
JAX の出力にグローバル デバイス数が表示されます。Global device count: 128
10. 分離型サービング(プレフィル/デコード)をデプロイする
次に、プリフィル/デコードの分離を使用して、エンドツーエンドの LLM サービング スタックをデプロイします。
標準サービングでは、プレフィル(プロンプトの処理)とデコード(トークンの生成)は同じ TPU で実行されます。プレフィルはコンピューティング バウンドで、デコードはメモリ帯域幅バウンドであるため、競合が発生します。分離型サービングでは、別々の TPU スライスで実行され、ネットワーク経由で KV キャッシュが転送されます。
LLM-D と Gateway を設定する
Namespace、Hugging Face Secret、GKE Gateway を設定します。
./08_setup_llm_d.sh
LLM-D ルーターをデプロイする
クライアント リクエストを受信し、Prefill スライスと Decode スライス間のルーティングを調整するルーターをデプロイします。
./09_deploy_llm_d_router.sh
プレフィルとデコードのワークロードをデプロイする
動的に割り当てられた TPU スライスに vLLM モデルサーバーをデプロイします。
./10_deploy_subslicing_pd_workload.sh
これにより行われること:
kueue-vllm-prefill-model-streamer(2x2x2TPU スライスをリクエストする LWS)をデプロイします。kueue-vllm-decode-model-streamer(2x2x2TPU スライスをリクエストする LWS)をデプロイします。- プリフィル スライスは、Qwen 397B モデルの重みを読み込み、
kv_producerとして機能します。 - デコード スライスは
kv_consumerとして機能します。 TPUConnectorHMAを使用して通信し、KV キャッシュを転送します。
プリフィル Pod とデコード Pod の両方が実行されるまで待ちます。
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. サービングを検証する
ルーター、事前入力、デコードのワークロードが実行されたら、サービング API を確認できます。
検証スクリプトを実行します。
./11_verify_serving.sh
仕組み:
- このスクリプトは、GKE Gateway の内部 IP を取得します。
- 一時 Pod(
curl-debug-comp)を起動して、http://${GATEWAY_IP}/v1/completionsに完了リクエストを送信します。 - 別の Pod(
curl-debug-chat)を起動して、http://${GATEWAY_IP}/v1/chat/completionsにチャット リクエストを送信します。
Qwen モデルから成功を示す JSON レスポンスが表示されます。
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
破棄スクリプトを実行します。
./12_teardown_cleanup.sh
このスクリプトの処理内容:
- GKE ノードプール(
tpu7-pool-1、tpu7-pool-2)を削除します。 - GKE クラスタ(
tpu-serving-cluster)を削除します。 - リソース ポリシー(
superslice-policy)を削除します。 - VPC ネットワーク(
qwen-serving-main)を削除します。
または、この Codelab 専用のプロジェクトを作成した場合は、プロジェクト全体を削除できます。
gcloud projects delete ${PROJECT_ID}
13. 完了
おめでとうございます!GKE 動的スライシングを詳しく確認し、分離型 LLM サービング アーキテクチャをデプロイしました。
学習した内容
- GKE Slice Controller を有効にして、増分プロビジョニング用にノードプールを構成する方法。
- Kueue を使用して特定の TPU トポロジをリクエストする方法。
- サブスライスが、より小さな独立した JAX ワークロード用に大規模な TPU ブロックを分割する方法。
- 複数のノードプールを 1 つの大きな仮想 TPU スライスに結合する Super-slicing の仕組み。
- LWS、Gateway API、vLLM を使用して Prefill/Decode の分散型サービングをデプロイする方法。