
1. 소개
이 Codelab에서는 GKE 동적 슬라이싱을 사용하여 Cloud TPU 리소스의 활용률을 최적화하는 방법을 알아봅니다. 동적 슬라이싱은 원시 TPU 프로비저닝을 워크로드 예약에서 분리할 수 있는 강력한 기능입니다.
구체적으로는 다음 두 가지 주요 패턴을 살펴봅니다.
- 하위 슬라이싱: 프로비저닝된 대규모 TPU 블록을 더 작은 워크로드를 위한 더 작고 격리된 슬라이스로 분할합니다.
- 슈퍼 슬라이싱: 프로비저닝된 여러 TPU 블록을 함께 스티칭하여 대규모 워크로드를 위한 더 큰 가상 슬라이스를 형성합니다.
이러한 패턴을 적용하여 Kueue, LeaderWorkerSet (LWS), Gateway API를 사용하여 대규모 언어 모델 (Qwen 397B)을 위한 고성능 분리된 서비스 (사전 입력/디코딩 분리) 아키텍처를 배포합니다.
아키텍처
다음은 TPU 동적 슬라이싱 및 분리된 제공 설정의 상위 수준 아키텍처입니다.
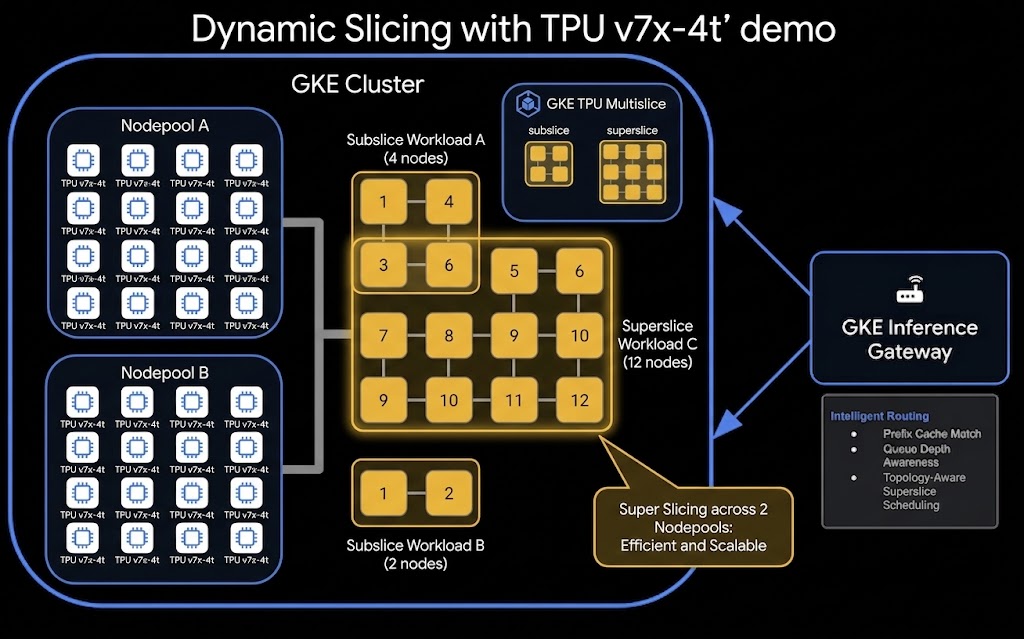
실습할 내용
- GKE 슬라이스 컨트롤러가 사용 설정된 GKE 클러스터를 프로비저닝합니다.
- 증분 프로비저닝을 위해 구성된 GKE TPU 노드 풀을 만듭니다.
- Kueue 및 LeaderWorkerSet을 배포하여 TPU 워크로드를 관리합니다.
- 슬라이스 나누기 워크로드를 실행하여 더 작은 슬라이스에서 JAX TPU 액세스를 확인합니다.
- 슈퍼슬라이싱 워크로드를 실행하여 결합된 여러 노드 풀에서 JAX TPU 액세스를 확인합니다.
- LLM 라우터로 조정되는 별도의 동적 할당 TPU 슬라이스에서 미리 채우기 및 디코딩 단계가 실행되는 분할 서빙 설정을 배포합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트.
- 중요: Cloud TPU7x (Ironwood) 모든 용량 모드 예약에 대한 액세스 권한
2. 시작하기 전에
Google Cloud 프로젝트 만들기 또는 선택
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되어 있는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
데모 저장소 클론
이 Codelab의 매니페스트와 도우미 스크립트가 포함된 저장소를 클론합니다.
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. 환경 구성
리소스를 프로비저닝하기 전에 환경 변수를 구성해야 합니다. env.sh 파일을 생성하는 도우미 스크립트 01_setup_env.sh가 제공됩니다.
설정 스크립트를 실행합니다.
./01_setup_env.sh
여러 값을 입력하라는 메시지가 표시됩니다. [ENTER]를 눌러 기본값을 수락하되, 이벤트 강사가 제공한 올바른 예약 이름과 예약 블록을 제공해야 합니다.
- GCP 프로젝트 ID: 현재 프로젝트 ID입니다.
- GCP 프로젝트 번호: 프로젝트 번호입니다.
- GKE 클러스터 이름:
tpu-serving-cluster(기본값) - TPU 노드 풀 영역:
us-central1-ai1a(기본값) - Kubernetes 네임스페이스:
llm-d-pd-disaggregation(기본값) - Cloud TPU 예약 이름: [제공된 예약 이름 입력]
- Cloud TPU 예약 블록 이름:
block-0(기본값) - 가중치용 GCS 버킷 이름:
model-weights(기본값) - TPU 머신 유형:
tpu7x-standard-4t(기본값) - Hugging Face 토큰: [필요한 경우 HF 토큰을 입력하거나 미리 로드된 가중치를 사용하는 경우 Enter 키를 누르세요.]
스크립트를 실행한 후 변수를 현재 세션에 적용합니다.
source env.sh
4. API 및 AI Zone 기능 사용 설정
이제 환경이 구성되었으므로 필요한 Google Cloud API와 AI Zone 공개 상태 기능을 사용 설정해야 합니다. 도우미 스크립트 02_enable_apis_and_features.sh이 제공됩니다.
스크립트를 실행합니다.
./02_enable_apis_and_features.sh
이 스크립트는 다음을 수행합니다.
- GKE, Compute, IAM, Resource Manager, Filestore, Network Services API를 사용 설정합니다.
- GKE 동적 슬라이싱의
ai-zones-visibility미리보기 기능을 사용 설정합니다.
5. GKE 클러스터 및 TPU 노드 풀 프로비저닝
이 단계에서는 기본 네트워크 인프라, GKE 클러스터, TPU 노드 풀을 프로비저닝합니다.
TPU 노드 풀은 증분 프로비저닝 (--placement-policy=superslice-policy 및 --reservation-affinity=specific 사용)으로 구성되며, 각 노드 풀은 원시 TPU 용량의 16노드 '큐브' (하위 블록)에 매핑됩니다.
프로비저닝 스크립트를 실행합니다.
./03_create_cluster_and_nodes.sh
이 스크립트의 기능:
- VPC 네트워크 및 서브넷 생성: TPU 트래픽에 최적화된 큰 MTU (8896), TPU 서브넷, GKE Gateway에 필요한 프록시 전용 서브넷으로 기본 VPC 네트워크를 설정합니다.
- GKE 클러스터 생성: 슬라이스 컨트롤러가 사용 설정된 표준 GKE 클러스터를 프로비저닝합니다 (
--enable-slice-controller). - 워크로드 정책 생성: 토폴로지가
4x4x4인HIGH_THROUGHPUT유형의superslice-policy이라는 리소스 정책을 정의합니다. - GKE TPU 노드 풀 생성: 각각
tpu7x-standard-4t노드 16개를 포함하는 두 개의 노드 풀 (tpu7-pool-1및tpu7-pool-2)을 프로비저닝합니다. 이는 별도의 16노드 큐브 두 개를 나타냅니다.
노드 확인
스크립트가 완료되면 32개의 TPU 노드가 모두 프로비저닝되고 등록되었는지 확인합니다.
kubectl get nodes -l google.com/tpu=present
목록에 노드 32개가 표시됩니다.
6. 조정 도구 설치
동적 슬라이싱은 여러 Kubernetes 컨트롤러를 사용하여 작업과 슬라이스 할당을 조정합니다. 다음 항목을 설치합니다.
- JobSet: 작업 그룹을 관리하는 데 사용됩니다 (슈퍼슬라이싱에 필요).
- Kueue: 대기열, 리소스 관리, 토폴로지 인식 예약 (TAS)
- LeaderWorkerSet (LWS): 복제된 멀티노드 TPU 배포를 관리합니다 (LLM 서빙에 필요).
- GKE 슬라이스 컨트롤러 (사용자 공간): Kueue를 TPU Cluster Director와 연결하여 실제 슬라이스를 동적으로 관리합니다.
설치 스크립트를 실행합니다.
./04_install_kueue_lws_slice_controller.sh
슬라이스 컨트롤러가 정상적으로 실행되고 있는지 확인합니다.
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Kueue 리소스 구성
이제 TPU 하드웨어 토폴로지를 나타내는 Kueue 리소스를 정의하고 승인 확인을 구성해야 합니다.
배포 스크립트를 실행합니다.
./05_deploy_kueue_resources.sh
배포된 주요 리소스:
- 토폴로지 (
slice-topology): Kueue가 예약할 때 고려해야 하는 TPU 파티션의 계층적 수준 (블록에서 호스트 이름까지)을 정의합니다. - ResourceFlavor (
slice-rf):slice-topology를tpu7x가속기와 연결합니다. - AdmissionCheck (
ac): 작업이 허용될 때 GKE 슬라이스 컨트롤러 (accelerator.gke.io/slice)를 사용하여 슬라이스를 동적으로 프로비저닝하도록 Kueue를 구성합니다. - ClusterQueue (
cq) 및 LocalQueue (lq): 워크로드가 제출될 대기열을 설정합니다. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): 선점 및 우선순위 기반 스케줄링을 지원하는 우선순위 수준을 정의합니다.
리소스를 확인합니다.
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. 서브슬라이싱으로 TPU 액세스 배포 및 확인
하위 슬라이싱을 사용하면 프로비저닝된 단일 TPU 블록 내에서 여러 개의 작은 워크로드를 실행할 수 있습니다. 이 단계에서는 4x4x4 (64개 칩 / 16개 VM) 블록으로 구성된 클러스터에 2x2x2 토폴로지 (8개 칩 / 2개 VM)를 요청하는 워크로드를 제출합니다.
하위 슬라이싱 워크로드를 배포합니다.
./06_deploy_simple_subslicing.sh
이 스크립트는 kueue-jobset-simple-subslicing.yaml을 적용합니다.
작동 방법:
- JobSet 사양에는
cloud.google.com/gke-tpu-slice-topology: 2x2x2주석이 포함됩니다. replicas: 6및parallelism: 2을 구성합니다 (완료: 2). 즉, Kueue는 각각 2개의 포드로 구성된 독립적인 작업 6개를 예약합니다.- 각 포드는
google.com/tpu: "4"(TPU VM 1개)을 요청합니다. - Kueue와 GKE 슬라이스 컨트롤러는 32노드 클러스터를 동적으로 분할하여
2x2x2슬라이스 6개를 할당합니다.
JAX 실행 확인
포드가 실행될 때까지 모니터링합니다.
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
포드 중 하나의 로그를 확인하여 JAX가 하위 슬라이스에서 8개의 TPU 기기 (코어)를 성공적으로 감지했는지 확인합니다.
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
다음과 같은 출력이 표시됩니다. Total TPU devices (cores): 8
9. 슈퍼슬라이싱으로 TPU 액세스 배포 및 확인
슈퍼슬라이싱은 단일 워크로드가 여러 물리적 TPU 블록 (일반적으로 큐브 또는 4x4x4와 같은 토폴로지라고 함)에 걸쳐 있을 수 있도록 하는 강력한 GKE 기능입니다. 이러한 블록을 함께 연결하면 대규모 학습 또는 서비스 워크로드를 위한 더 큰 가상 슬라이스를 형성할 수 있습니다. 이 단계에서는 4x4x8 토폴로지 (128개 칩 / 32개 VM)를 요청하는 JobSet을 배포합니다. 단일 4x4x4 블록에는 칩이 64개만 포함되므로 이 워크로드는 단일 블록의 크기를 초과하며 요청을 충족하려면 GKE가 tpu7-pool-1 및 tpu7-pool-2 노드 풀을 동적으로 연결해야 합니다.
슈퍼 슬라이싱 워크로드를 배포합니다.
./07_deploy_simple_superslicing.sh
이 스크립트는 kueue-jobset-simple-superslicing.yaml을 적용합니다.
작동 방법:
- JobSet 템플릿에는
cloud.google.com/gke-tpu-slice-topology: 4x4x8주석이 포함되어 있습니다. parallelism: 32및completions: 32를 구성합니다.- 각 포드는
google.com/tpu: "4"를 요청합니다. 4x4x8토폴로지에는 32개의 노드가 모두 필요하므로 슬라이스 컨트롤러는 OCS (광학 회로 스위칭) 네트워크를 동적으로 구성하여 두 개의 16노드 풀을 단일 32노드 ICI 메시로 상호 연결합니다.
JobSet 포드가 성공적으로 실행되고 JAX가 128개의 기기를 모두 감지하는지 확인합니다.
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
포드 중 하나의 로그를 확인합니다.
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
전역 기기 수를 보여주는 JAX 출력이 표시됩니다. Global device count: 128
10. 분할 서빙 (사전 입력/디코딩) 배포
이제 Prefill/Decode Disaggregation을 사용하여 엔드 투 엔드 LLM 제공 스택을 배포합니다.
표준 서빙에서는 미리 채우기 (프롬프트 처리)와 디코딩 (토큰 생성)이 동일한 TPU에서 실행됩니다. 미리 채우기는 컴퓨팅에 바인딩되고 디코딩은 메모리 대역폭에 바인딩되므로 충돌이 발생합니다. 분할 서빙에서는 별도의 TPU 슬라이스에서 실행되며 네트워크를 통해 KV 캐시를 전송합니다.
LLM-D 및 게이트웨이 설정
네임스페이스, Hugging Face 보안 비밀, GKE 게이트웨이를 설정합니다.
./08_setup_llm_d.sh
LLM-D 라우터 배포
클라이언트 요청을 수신하고 Prefill과 Decode 슬라이스 간의 라우팅을 조정하는 라우터를 배포합니다.
./09_deploy_llm_d_router.sh
사전 입력 및 디코딩 워크로드 배포
동적으로 할당된 TPU 슬라이스에 vLLM 모델 서버를 배포합니다.
./10_deploy_subslicing_pd_workload.sh
작업 결과:
kueue-vllm-prefill-model-streamer(2x2x2TPU 슬라이스를 요청하는 LWS)를 배포합니다.kueue-vllm-decode-model-streamer(2x2x2TPU 슬라이스를 요청하는 LWS)를 배포합니다.- 사전 입력 슬라이스는 Qwen 397B 모델 가중치를 로드하고
kv_producer역할을 합니다. - 디코딩 슬라이스는
kv_consumer역할을 합니다. TPUConnectorHMA를 사용하여 KV 캐시를 전송합니다.
미리 채우기 및 디코딩 포드가 모두 실행될 때까지 기다립니다.
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. 게재 확인
라우터, 사전 입력, 디코딩 워크로드가 실행되면 이제 서빙 API를 확인할 수 있습니다.
확인 스크립트를 실행합니다.
./11_verify_serving.sh
작동 방법:
- 스크립트가 GKE 게이트웨이의 내부 IP를 가져옵니다.
http://${GATEWAY_IP}/v1/completions에 완료 요청을 보내기 위해 임시 포드 (curl-debug-comp)를 실행합니다.http://${GATEWAY_IP}/v1/chat/completions에 채팅 요청을 보내기 위해 다른 포드 (curl-debug-chat)를 실행합니다.
Qwen 모델에서 성공적인 JSON 응답이 표시됩니다.
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. 삭제
Google Cloud 계정에 지속적으로 비용이 청구되지 않도록 하려면 이 Codelab 중에 생성된 리소스를 삭제하세요.
teardown 스크립트를 실행합니다.
./12_teardown_cleanup.sh
이 스크립트의 기능:
- GKE 노드 풀 (
tpu7-pool-1,tpu7-pool-2)을 삭제합니다. - GKE 클러스터 (
tpu-serving-cluster)를 삭제합니다. - 리소스 정책 (
superslice-policy)을 삭제합니다. - VPC 네트워크 (
qwen-serving-main)를 삭제합니다.
또는 이 Codelab 전용 프로젝트를 만든 경우 전체 프로젝트를 삭제할 수 있습니다.
gcloud projects delete ${PROJECT_ID}
13. 축하합니다
축하합니다. GKE 동적 슬라이싱을 살펴보고 분리된 LLM 제공 아키텍처를 배포했습니다.
학습한 내용
- GKE 슬라이스 컨트롤러를 사용 설정하고 증분 프로비저닝을 위해 노드 풀을 구성하는 방법
- Kueue를 사용하여 특정 TPU 토폴로지를 요청하는 방법
- 하위 슬라이싱이 더 작고 독립적인 JAX 워크로드를 위해 대규모 TPU 블록을 분할하는 방법
- 슈퍼 슬라이싱이 여러 노드 풀을 하나의 더 큰 가상 TPU 슬라이스로 연결하는 방법
- LWS, Gateway API, vLLM을 사용하여 분리된 제공을 사전 입력/디코딩하는 방법