
1. Wprowadzenie
Z tego ćwiczenia dowiesz się, jak używać dynamicznego dzielenia GKE do optymalizacji wykorzystania zasobów Cloud TPU. Dynamiczne dzielenie to zaawansowana funkcja, która umożliwia oddzielenie udostępniania surowych zasobów TPU od planowania zbiorów zadań.
Poznasz 2 kluczowe wzorce:
- Podział na mniejsze wycinki: dzielenie dużego bloku TPU na mniejsze, odizolowane wycinki na potrzeby mniejszych zadań.
- Super-slicing: łączenie ze sobą wielu udostępnionych bloków TPU w celu utworzenia większego wirtualnego wycinka na potrzeby dużych zbiorów zadań.
Zastosujesz te wzorce, aby wdrożyć architekturę rozproszonego obsługiwania (rozdzielenie wstępnego wypełniania i dekodowania) o wysokiej wydajności dla dużego modelu językowego (Qwen 397B) za pomocą Kueue, LeaderWorkerSet (LWS) i interfejsu Gateway API.
Architektura
Oto ogólna architektura konfiguracji dynamicznego dzielenia wycinków TPU i rozproszonej obsługi:
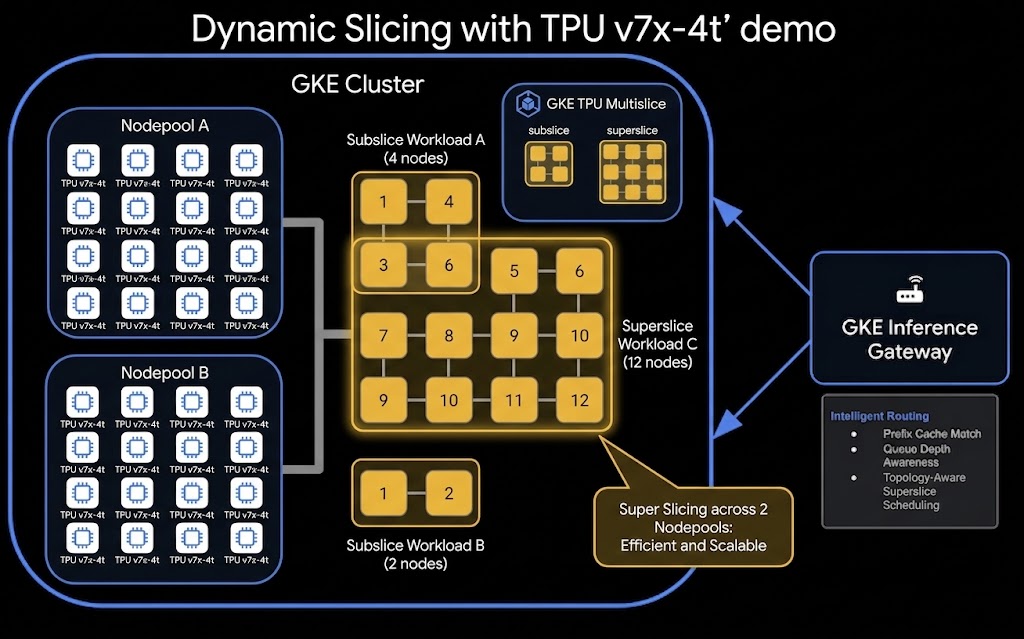
Jakie zadania wykonasz
- utworzyć klaster GKE z włączonym kontrolerem wycinków GKE;
- Utwórz pule węzłów TPU GKE skonfigurowane pod kątem przyrostowego udostępniania.
- Wdróż Kueue i LeaderWorkerSet, aby zarządzać zadaniami TPU.
- Uruchom zadanie subslicing, aby sprawdzić dostęp do JAX TPU na mniejszych wycinkach.
- Uruchom zadanie superslicing, aby sprawdzić dostęp JAX TPU w wielu połączonych pulach węzłów.
- Wdróż konfigurację rozproszonego wyświetlania, w której etapy wstępnego wypełniania i dekodowania działają na osobnych, dynamicznie przydzielanych fragmentach TPU koordynowanych przez router LLM.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- Projekt Google Cloud z włączonymi płatnościami.
- WAŻNE: dostęp do rezerwacji Cloud TPU7x (Ironwood) w trybie pełnej pojemności.
2. Zanim zaczniesz
Tworzenie lub wybieranie projektu Google Cloud
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Klonowanie repozytorium demonstracyjnego
Sklonuj repozytorium zawierające pliki manifestu i skrypty pomocnicze na potrzeby tego ćwiczenia:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Konfigurowanie środowiska
Przed udostępnieniem zasobów musisz skonfigurować zmienne środowiskowe. Aby wygenerować plik env.sh, możesz użyć skryptu pomocniczego 01_setup_env.sh.
Uruchom skrypt konfiguracji:
./01_setup_env.sh
Pojawi się prośba o podanie kilku wartości. Naciśnij [ENTER], aby zaakceptować wartości domyślne, ale podaj prawidłową nazwę rezerwacji i blok rezerwacji podane przez instruktora wydarzenia:
- Identyfikator projektu GCP: bieżący identyfikator projektu.
- Numer projektu GCP: numer projektu.
- Nazwa klastra GKE:
tpu-serving-cluster(domyślnie). - Strefa puli węzłów TPU:
us-central1-ai1a(domyślnie). - Przestrzeń nazw Kubernetes:
llm-d-pd-disaggregation(domyślnie). - Nazwa rezerwacji Cloud TPU: [Wpisz podaną nazwę rezerwacji]
- Nazwa bloku rezerwacji Cloud TPU:
block-0(domyślnie). - Nazwa zasobnika GCS dla wag:
model-weights(domyślnie). - Typ maszyny TPU:
tpu7x-standard-4t(domyślnie). - Hugging Face Token: [Wpisz token HF, jeśli jest wymagany, lub naciśnij ENTER, jeśli używasz wstępnie załadowanych wag]
Po uruchomieniu skryptu zastosuj zmienne w bieżącej sesji:
source env.sh
4. Włączanie interfejsów API i funkcji strefy AI
Po skonfigurowaniu środowiska musisz włączyć wymagane interfejsy Google Cloud API i funkcję widoczności strefy AI. Dostępny jest skrypt pomocniczy 02_enable_apis_and_features.sh.
Uruchom skrypt:
./02_enable_apis_and_features.sh
Ten skrypt:
- Włącza interfejsy GKE, Compute, IAM, Resource Manager, Filestore i Network Services API.
- Włącza funkcję w wersji testowej
ai-zones-visibilitydla dynamicznego dzielenia GKE.
5. Udostępnianie klastra GKE i pul węzłów TPU
W tym kroku udostępnisz bazową infrastrukturę sieciową, klaster GKE i pule węzłów TPU.
Pule węzłów TPU zostaną skonfigurowane za pomocą udostępniania przyrostowego (z użyciem --placement-policy=superslice-policy i --reservation-affinity=specific), które mapuje każdą pulę węzłów na 16-węzłową „kostkę” (podblok) surowej mocy obliczeniowej TPU.
Uruchom skrypt obsługi administracyjnej:
./03_create_cluster_and_nodes.sh
Działanie skryptu:
- Tworzy sieć VPC i podsieci: konfiguruje główną sieć VPC z dużym MTU (8896) zoptymalizowanym pod kątem ruchu TPU, podsieć TPU i podsieć tylko-proxy wymaganą przez GKE Gateway.
- Tworzy klaster GKE: udostępnia standardowy klaster GKE z włączonym kontrolerem wycinków (
--enable-slice-controller). - Tworzy zasadę zbioru zadań: definiuje zasadę zasobu o nazwie
superslice-policytypuHIGH_THROUGHPUTz topologią4x4x4. - Tworzy pule węzłów TPU GKE: udostępnia 2 pule węzłów (
tpu7-pool-1itpu7-pool-2), z których każda zawiera 16 węzłów typutpu7x-standard-4t. Są to 2 osobne sześciany z 16 węzłami.
Weryfikowanie węzłów
Po zakończeniu skryptu sprawdź, czy wszystkie 32 węzły TPU zostały udostępnione i zarejestrowane:
kubectl get nodes -l google.com/tpu=present
Na liście powinno być 32 węzły.
6. Instalowanie narzędzi do orkiestracji
Dynamiczne dzielenie zasobów opiera się na kilku kontrolerach Kubernetes, które koordynują zadania i przydzielanie zasobów. Musisz zainstalować:
- JobSet do zarządzania grupą zadań (potrzebny w przypadku superslicingu).
- Kueue: do kolejkowania, zarządzania zasobami i planowania uwzględniającego topologię (TAS).
- LeaderWorkerSet (LWS): do zarządzania replikowanymi wdrożeniami TPU z wieloma węzłami (potrzebne do obsługi LLM).
- Kontroler wycinków GKE (przestrzeń użytkownika): łączy Kueue z usługą TPU Cluster Director, aby dynamicznie zarządzać wycinkami fizycznymi.
Uruchom skrypt instalacyjny:
./04_install_kueue_lws_slice_controller.sh
Sprawdź, czy kontroler podziału działa prawidłowo:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Konfigurowanie zasobów Kueue
Teraz musisz zdefiniować zasoby Kueue, które reprezentują topologię sprzętu TPU, i skonfigurować sprawdzanie dopuszczenia.
Uruchom skrypt wdrażania:
./05_deploy_kueue_resources.sh
Wdrożone kluczowe zasoby:
- Topologia (
slice-topology): określa poziomy hierarchiczne partycji TPU (od bloku do nazwy hosta), które Kueue ma uwzględniać podczas planowania. - ResourceFlavor (
slice-rf): łączyslice-topologyz akceleratoremtpu7x. - AdmissionCheck (
ac): konfiguruje Kueue tak, aby używał kontrolera wycinków GKE (accelerator.gke.io/slice) do dynamicznego udostępniania wycinków po przyjęciu zadania. - ClusterQueue (
cq) i LocalQueue (lq): konfiguruje kolejki, do których będą przesyłane zadania. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): określa poziomy priorytetu, aby umożliwić wywłaszczenie i planowanie oparte na priorytetach.
Sprawdź zasoby:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Wdrażanie i weryfikowanie dostępu do TPU za pomocą podziału na mniejsze części
Podział na mniejsze części umożliwia uruchamianie wielu mniejszych zbiorów zadań w ramach jednego udostępnionego bloku TPU. W tym kroku prześlesz zbiór zadań, który wymaga topologii 2x2x2 (8 układów / 2 maszyny wirtualne), do klastra składającego się z bloków 4x4x4 (64 układy / 16 maszyn wirtualnych).
Wdróż zadanie podziału na mniejsze części:
./06_deploy_simple_subslicing.sh
Ten skrypt stosuje plik kueue-jobset-simple-subslicing.yaml.
Jak to działa:
- Specyfikacja JobSet zawiera adnotację
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Konfiguruje
replicas: 6iparallelism: 2(uzupełnienia: 2). Oznacza to, że Kueue zaplanuje 6 niezależnych zadań, z których każde będzie się składać z 2 podów. - Każdy pod wymaga
google.com/tpu: "4"(1 maszyny wirtualnej TPU). - Kueue i kontroler wycinków GKE dynamicznie dzielą 32-węzłowy klaster, aby przydzielić 6 wycinków
2x2x2.
Weryfikowanie wykonania JAX
Monitoruj pody, aż zaczną działać:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Sprawdź logi jednego z podów, aby upewnić się, że JAX wykrył 8 urządzeń TPU (rdzeni) w jego podwycinku:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Powinny się wyświetlić dane wyjściowe wskazujące: Total TPU devices (cores): 8
9. Wdrażanie i weryfikowanie dostępu do TPU za pomocą funkcji Superslicing
Super-slicing to zaawansowana funkcja GKE, która umożliwia rozciągnięcie pojedynczego zadania na wiele fizycznych bloków TPU (często nazywanych kostkami lub topologiami, np. 4x4x4). Łącząc te bloki, możesz utworzyć większy wirtualny wycinek na potrzeby trenowania na dużą skalę lub obsługi zadań. W tym kroku wdrożysz element JobSet, który zażąda topologii 4x4x8 (128 chipów / 32 maszyny wirtualne). Ponieważ pojedynczy blok 4x4x4 zawiera tylko 64 chipy, ten zbiór zadań przekracza rozmiar pojedynczego bloku i wymaga, aby GKE dynamicznie łączył pule węzłów tpu7-pool-1 i tpu7-pool-2 w celu spełnienia żądania.
Wdróż zadanie superslicing:
./07_deploy_simple_superslicing.sh
Ten skrypt stosuje plik kueue-jobset-simple-superslicing.yaml.
Jak to działa:
- Szablon JobSet zawiera adnotację
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Konfiguruje
parallelism: 32icompletions: 32. - Każde żądanie bloku reklamowego
google.com/tpu: "4". - Topologia
4x4x8wymaga wszystkich 32 węzłów, więc kontroler wycinka dynamicznie konfiguruje sieć OCS (Optical Circuit Switching), aby połączyć 2 pule po 16 węzłów w jedną sieć typu mesh ICI z 32 węzłami.
Sprawdź, czy pody JobSet działają prawidłowo i czy JAX wykrywa wszystkie 128 urządzeń:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Sprawdź logi jednego z podów:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Powinny się wyświetlić dane wyjściowe JAX z liczbą urządzeń globalnych: Global device count: 128
10. Wdrażanie rozproszonego wyświetlania (wypełnianie wstępne/dekodowanie)
Teraz wdrożysz kompleksowy stos obsługi LLM za pomocą rozdzielenia wstępnego wypełniania i dekodowania.
W przypadku standardowego wyświetlania wstępne wypełnianie (przetwarzanie promptu) i dekodowanie (generowanie tokenów) odbywają się na tych samych układach TPU. Wypełnianie wstępne jest ograniczone mocą obliczeniową, a dekodowanie – przepustowością pamięci, więc te procesy są ze sobą sprzeczne. Rozproszone wyświetlanie treści uruchamia je na oddzielnych wycinkach TPU, przesyłając pamięć podręczną klucz-wartość przez sieć.
Konfigurowanie modelu LLM-D i bramy
Skonfiguruj przestrzenie nazw, obiekty tajne Hugging Face i bramę GKE:
./08_setup_llm_d.sh
Wdrażanie routera LLM-D
Wdróż router, który będzie odbierać żądania klientów i koordynować routing między fragmentami Prefill i Decode:
./09_deploy_llm_d_router.sh
Wdrażanie zbiorów zadań Prefill i Decode
Wdróż serwery modeli vLLM na dynamicznie przydzielonych wycinkach TPU:
./10_deploy_subslicing_pd_workload.sh
Działanie:
- Wdraża
kueue-vllm-prefill-model-streamer(LWS wysyła prośbę o wycinek TPU2x2x2). - Wdraża
kueue-vllm-decode-model-streamer(LWS wysyła prośbę o wycinek TPU2x2x2). - W przypadku fragmentu wstępnego wczytywane są wagi modelu Qwen 397B, który działa jako
kv_producer. - Fragment dekodowania działa jako
kv_consumer. - Do przesyłania pamięci podręcznych KV używają komunikacji
TPUConnectorHMA.
Poczekaj, aż uruchomią się oba pody wstępnego wypełniania i dekodowania:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Weryfikowanie wyświetlania
Po uruchomieniu zadań związanych z routerem, wstępnym wypełnianiem i dekodowaniem możesz teraz zweryfikować interfejs Serving API.
Uruchom skrypt weryfikacyjny:
./11_verify_serving.sh
Jak to działa:
- Skrypt pobiera wewnętrzny adres IP bramy GKE.
- Uruchamia tymczasowy zasobnik (
curl-debug-comp), aby wysłać żądanie zakończenia dohttp://${GATEWAY_IP}/v1/completions. - Uruchamia kolejny pod (
curl-debug-chat), aby wysłać prośbę o czat dohttp://${GATEWAY_IP}/v1/chat/completions.
Powinna pojawić się odpowiedź JSON z modelem Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia.
Uruchom skrypt zamykający:
./12_teardown_cleanup.sh
Działanie skryptu:
- Usuwa pule węzłów GKE (
tpu7-pool-1,tpu7-pool-2). - Usuwa klaster GKE (
tpu-serving-cluster). - Usuwa zasady zasobów (
superslice-policy). - Usuwa sieci VPC (
qwen-serving-main).
Jeśli na potrzeby tego ćwiczenia z programowania został przez Ciebie utworzony specjalny projekt, możesz go usunąć:
gcloud projects delete ${PROJECT_ID}
13. Gratulacje
Gratulacje! Udało Ci się poznać dynamiczne dzielenie zasobów w GKE i wdrożyć architekturę rozproszonego obsługiwania dużych modeli językowych.
Czego się dowiedziałeś(-aś)
- Jak włączyć kontroler wycinków GKE i skonfigurować pule węzłów pod kątem przyrostowego udostępniania.
- Jak używać Kueue do żądania określonych topologii TPU.
- Jak dzielenie na mniejsze części dzieli duży blok TPU na mniejsze, niezależne zadania JAX.
- Jak superwycinanie łączy wiele pul węzłów w jeden większy wirtualny wycinek TPU.
- Jak wdrożyć rozdzielone udostępnianie wstępnego wypełniania/dekodowania za pomocą LWS, interfejsu Gateway API i vLLM.