
1. Introdução
Neste codelab, você vai aprender a usar o GKE Dynamic Slicing para otimizar a utilização dos recursos da Cloud TPU. O corte dinâmico é um recurso avançado que permite separar o provisionamento bruto de TPU do agendamento de carga de trabalho.
Especificamente, você vai conhecer dois padrões principais:
- Subdivisão: divisão de um grande bloco de TPU provisionado em frações menores e isoladas para cargas de trabalho menores.
- Superfatiamento: une vários blocos de TPU provisionados para formar uma fatia virtual maior para cargas de trabalho de grande escala.
Você vai aplicar esses padrões para implantar uma arquitetura de disponibilização desagregada (pré-preenchimento/desagregação de decodificação) de alta performance para um modelo de linguagem grande (Qwen 397B) usando Kueue, LeaderWorkerSet (LWS) e a API Gateway.
Arquitetura
Confira a arquitetura de alto nível da configuração de segmentação dinâmica e veiculação desagregada da TPU:
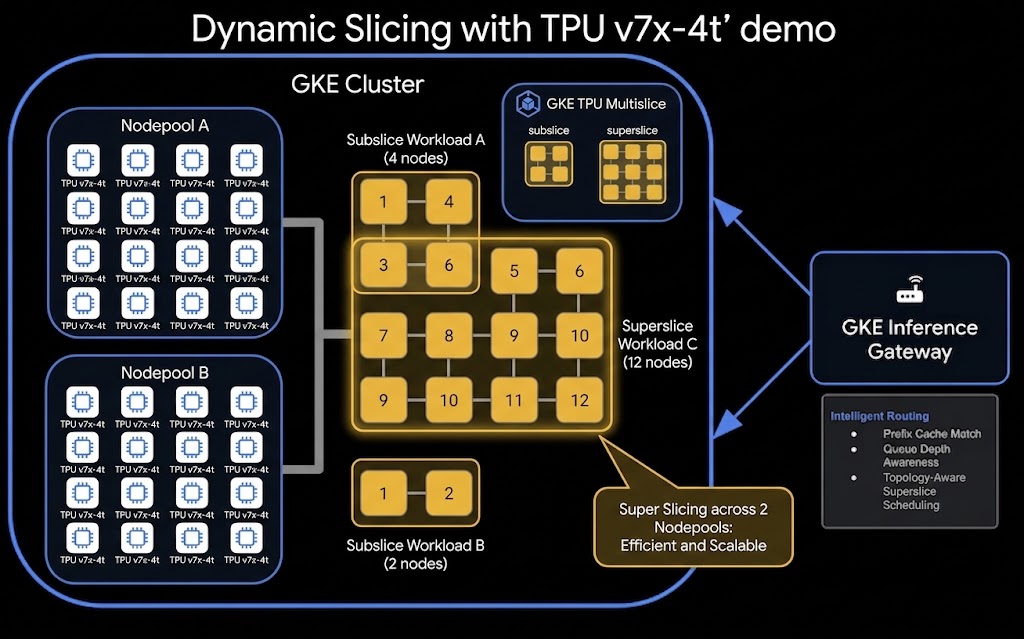
Atividades deste laboratório
- Provisione um cluster do GKE com o GKE Slice Controller ativado.
- Crie pools de nós de TPU do GKE configurados para provisionamento incremental.
- Implante o Kueue e o LeaderWorkerSet para gerenciar cargas de trabalho de TPU.
- Execute uma carga de trabalho de subdivisão para verificar o acesso da TPU do JAX em frações menores.
- Execute uma carga de trabalho de superslicing para verificar o acesso da TPU do JAX em vários pools de nós combinados.
- Implante uma configuração de Serviço desagregado em que as etapas de pré-preenchimento e decodificação são executadas em slices de TPU separados e alocados dinamicamente, coordenados por um roteador de LLM.
O que é necessário
- Um navegador da Web, como o Chrome.
- Ter um projeto do Google Cloud com o faturamento ativado.
- IMPORTANTE: acesso a uma reserva do modo "Toda a capacidade" do Cloud TPU7x (Ironwood).
2. Antes de começar
Criar ou selecionar um projeto do Google Cloud
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, faça o seguinte:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Clonar o repositório de demonstração
Clone o repositório que contém os manifestos e scripts auxiliares para este codelab:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Configurar ambiente
Antes de provisionar recursos, configure as variáveis de ambiente. Um script auxiliar 01_setup_env.sh é fornecido para gerar um arquivo env.sh.
Execute o script de configuração:
./01_setup_env.sh
Você vai receber uma solicitação para inserir vários valores. Pressione [ENTER] para aceitar os padrões, mas informe o Nome da reserva e o Bloco de reserva corretos fornecidos pelo instrutor do evento:
- ID do projeto do GCP: o ID do projeto atual.
- Número do projeto do GCP: o número do seu projeto.
- Nome do cluster do GKE:
tpu-serving-cluster(padrão). - Zona do pool de nós da TPU:
us-central1-ai1a(padrão). - Namespace do Kubernetes:
llm-d-pd-disaggregation(padrão). - Nome da reserva do Cloud TPU: [Insira o nome da reserva fornecido]
- Nome do bloco de reserva do Cloud TPU:
block-0(padrão). - Nome do bucket do GCS para pesos:
model-weights(padrão). - Tipo de máquina da TPU:
tpu7x-standard-4t(padrão). - Token do Hugging Face: [Insira seu token do HF, se necessário, ou pressione ENTER se estiver usando pesos pré-carregados]
Depois de executar o script, aplique as variáveis à sessão atual:
source env.sh
4. Ativar APIs e recursos da Zona de IA
Agora que seu ambiente está configurado, é necessário ativar as APIs do Google Cloud necessárias e o recurso de visibilidade da zona de IA. Um script auxiliar 02_enable_apis_and_features.sh é fornecido.
Execute o script:
./02_enable_apis_and_features.sh
Este script:
- Ativa as APIs GKE, Compute, IAM, Resource Manager, Filestore e Network Services.
- Ativa o recurso de visualização
ai-zones-visibilitypara o GKE Dynamic Slicing.
5. Provisionar o cluster do GKE e os pools de nós da TPU
Nesta etapa, você vai provisionar a infraestrutura de rede, o cluster do GKE e os pools de nós da TPU.
Os pools de nós de TPU serão configurados com provisionamento incremental (usando --placement-policy=superslice-policy e --reservation-affinity=specific), que mapeia cada pool de nós para um "cubo" de 16 nós (sub-bloco) de capacidade bruta de TPU.
Execute o script de provisionamento:
./03_create_cluster_and_nodes.sh
O que o script faz:
- Cria rede VPC e sub-redes: configura uma rede VPC principal com uma MTU grande (8896) otimizada para tráfego de TPU, uma sub-rede de TPU e uma sub-rede somente proxy exigida pelo GKE Gateway.
- Cria um cluster do GKE: provisiona um cluster padrão do GKE com o Controlador de fração ativado (
--enable-slice-controller). - Cria política de carga de trabalho: define uma política de recursos chamada
superslice-policydo tipoHIGH_THROUGHPUTcom uma topologia de4x4x4. - Cria pools de nós de TPU do GKE: provisiona dois pools de nós (
tpu7-pool-1etpu7-pool-2), cada um contendo 16 nós detpu7x-standard-4t. Eles representam dois cubos separados de 16 nós.
Verificar os nós
Depois que o script for concluído, verifique se todos os 32 nós de TPU foram provisionados e registrados:
kubectl get nodes -l google.com/tpu=present
A lista vai mostrar 32 nós.
6. Instalar ferramentas de orquestração
O particionamento dinâmico depende de vários controladores do Kubernetes para coordenar jobs e alocação de partições. Você vai instalar:
- JobSet: para gerenciar um grupo de jobs (necessário para superslicing).
- Kueue: para enfileiramento, gerenciamento de recursos e programação consciente da topologia (TAS, na sigla em inglês).
- LeaderWorkerSet (LWS): para gerenciar implantações de TPU multinó replicadas (necessárias para a disponibilização de LLMs).
- Controlador de fração do GKE (espaço do usuário): conecta o Kueue ao Cluster Director da TPU para gerenciar dinamicamente as frações físicas.
Execute o script de instalação:
./04_install_kueue_lws_slice_controller.sh
Verifique se o controlador de fração está sendo executado corretamente:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Configurar recursos do Kueue
Agora, defina os recursos do Kueue que representam a topologia de hardware da TPU e configure as verificações de admissão.
Execute o script de implantação:
./05_deploy_kueue_resources.sh
Principais recursos implantados:
- Topologia (
slice-topology): define os níveis hierárquicos das partições de TPU (do bloco ao nome do host) que o Kueue precisa considerar ao fazer o agendamento. - ResourceFlavor (
slice-rf): associa oslice-topologyao aceleradortpu7x. - AdmissionCheck (
ac): configura o Kueue para usar o controlador de fração do GKE (accelerator.gke.io/slice) e provisionar dinamicamente as frações quando um job é aceito. - ClusterQueue (
cq) e LocalQueue (lq): configura as filas em que as cargas de trabalho serão enviadas. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): define níveis de prioridade para ativar a substituição e o agendamento com base na prioridade.
Verifique os recursos:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Fazer o deploy e verificar o acesso à TPU com a divisão em subpartes
Com o subparticionamento, é possível executar várias cargas de trabalho menores em um único bloco de TPU provisionado. Nesta etapa, você vai enviar uma carga de trabalho que solicita uma topologia 2x2x2 (8 chips / 2 VMs) para um cluster composto por blocos 4x4x4 (64 chips / 16 VMs).
Implante a carga de trabalho de subsegmentação:
./06_deploy_simple_subslicing.sh
Esse script aplica kueue-jobset-simple-subslicing.yaml.
Como funciona:
- A especificação JobSet inclui a anotação
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Ele configura
replicas: 6eparallelism: 2(conclusões: 2). Isso significa que o Kueue vai programar seis jobs independentes, cada um consistindo em dois pods. - Cada pod solicita
google.com/tpu: "4"(uma VM de TPU). - O Kueue e o controlador de fração do GKE dividem dinamicamente o cluster de 32 nós para alocar seis frações de
2x2x2.
Verificar a execução do JAX
Monitore os pods até que eles estejam em execução:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Verifique os registros de um dos pods para confirmar se o JAX detectou os oito dispositivos TPU (núcleos) na subsegmentação:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Você vai ver uma saída indicando: Total TPU devices (cores): 8
9. Implantar e verificar o acesso à TPU com superslicing
O super-slicing é um recurso avançado do GKE que permite que uma única carga de trabalho abranja vários blocos físicos de TPU (geralmente chamados de cubos ou topologias como 4x4x4). Ao unir esses blocos, é possível formar uma fração virtual maior para treinamento em grande escala ou veiculação de cargas de trabalho. Nesta etapa, você vai implantar um JobSet que solicita uma topologia 4x4x8 (128 chips / 32 VMs). Como um único bloco 4x4x4 contém apenas 64 chips, essa carga de trabalho excede o tamanho de um único bloco e exige que o GKE combine dinamicamente os pools de nós tpu7-pool-1 e tpu7-pool-2 para atender à solicitação.
Implante a carga de trabalho de superslicing:
./07_deploy_simple_superslicing.sh
Esse script aplica kueue-jobset-simple-superslicing.yaml.
Como funciona:
- O modelo JobSet inclui a anotação
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Ele configura
parallelism: 32ecompletions: 32. - Cada pod solicita
google.com/tpu: "4". - Como uma topologia
4x4x8exige todos os 32 nós, o controlador de fração configura dinamicamente a rede OCS (comutação de circuito óptico) para interconectar os dois pools de 16 nós em uma única malha ICI de 32 nós.
Verifique se os pods do JobSet foram executados e se o JAX detectou todos os 128 dispositivos:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Verifique os registros de um dos pods:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Você vai ver a saída do JAX mostrando a contagem global de dispositivos: Global device count: 128
10. Implantar a exibição desagregada (pré-preenchimento/decodificação)
Agora você vai implantar a pilha de serviço de LLM de ponta a ponta usando a desagregação de pré-preenchimento/decodificação.
No serviço padrão, o preenchimento (processamento do comando) e a decodificação (geração de tokens) são executados nas mesmas TPUs. Como o preenchimento é vinculado à computação e a decodificação é vinculada à largura de banda da memória, eles entram em conflito. O serviço desagregado executa esses processos em slices de TPU separados, transferindo o cache KV pela rede.
Configurar LLM-D e gateway
Configure os namespaces, os secrets do Hugging Face e o gateway do GKE:
./08_setup_llm_d.sh
Implantar o roteador LLM-D
Implante o roteador que vai receber solicitações do cliente e coordenar o roteamento entre as partes de pré-preenchimento e decodificação:
./09_deploy_llm_d_router.sh
Implantar cargas de trabalho de pré-preenchimento e decodificação
Implante os servidores de modelos do vLLM em frações de TPU alocadas dinamicamente:
./10_deploy_subslicing_pd_workload.sh
O que isso faz:
- Implanta
kueue-vllm-prefill-model-streamer(LWS solicitando uma fatia de TPU2x2x2). - Implanta
kueue-vllm-decode-model-streamer(LWS solicitando uma fatia de TPU2x2x2). - A fração de pré-preenchimento carrega os pesos do modelo Qwen 397B e atua como um
kv_producer. - A fatia de decodificação funciona como o
kv_consumer. - Eles se comunicam usando
TPUConnectorHMApara transferir caches de KV.
Aguarde até que os pods de pré-preenchimento e decodificação estejam em execução:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Verificar veiculação
Com as cargas de trabalho de roteador, pré-preenchimento e decodificação em execução, agora é possível verificar a API de disponibilização.
Execute o script de verificação:
./11_verify_serving.sh
Como funciona:
- O script recupera o IP interno do gateway do GKE.
- Ele cria um pod temporário (
curl-debug-comp) para enviar uma solicitação de conclusão ahttp://${GATEWAY_IP}/v1/completions. - Ele inicia outro pod (
curl-debug-chat) para enviar uma solicitação de chat parahttp://${GATEWAY_IP}/v1/chat/completions.
Você vai receber uma resposta JSON bem-sucedida do modelo Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
Execute o script de desmontagem:
./12_teardown_cleanup.sh
O que o script faz:
- Exclui pools de nós do GKE (
tpu7-pool-1,tpu7-pool-2). - Exclui o cluster do GKE (
tpu-serving-cluster). - Exclui políticas de recursos (
superslice-policy). - Exclui redes VPC (
qwen-serving-main).
Se você criou um projeto dedicado para este codelab, exclua o projeto inteiro:
gcloud projects delete ${PROJECT_ID}
13. Parabéns
Parabéns! Você conheceu o GKE Dynamic Slicing e implantou uma arquitetura de serviço de LLM desagregado.
O que você aprendeu
- Como ativar o GKE Slice Controller e configurar pools de nós para o provisionamento incremental.
- Como usar o Kueue para solicitar topologias específicas de TPU.
- Como o subfatiamento divide um grande bloco de TPU para cargas de trabalho JAX menores e independentes.
- Como o superfatiamento une vários pools de nós em uma única fração de TPU virtual maior.
- Como implantar o Prefill/Decode disaggregated serving usando LWS, API Gateway e vLLM.