
1. Введение
В этом практическом занятии вы узнаете, как использовать динамическое разделение ресурсов TPU в GKE для оптимизации использования ресурсов Cloud. Динамическое разделение — это мощная функция, позволяющая отделить непосредственное выделение TPU от планирования рабочих нагрузок.
В частности, вы изучите две ключевые закономерности:
- Разделение на подблоки : Разделение большого выделенного блока TPU на более мелкие изолированные блоки для меньших рабочих нагрузок.
- Супер-слайсинг : объединение нескольких выделенных блоков TPU для формирования большего виртуального среза для крупномасштабных рабочих нагрузок.
Вы будете применять эти шаблоны для развертывания высокопроизводительной архитектуры дезагрегированного обслуживания (дезагрегация с предварительным заполнением/декодированием) для большой языковой модели (Qwen 397B) с использованием Kueue , LeaderWorkerSet (LWS) и Gateway API .
Архитектура
Вот высокоуровневая архитектура системы динамической нарезки и дезагрегированной подачи данных TPU:
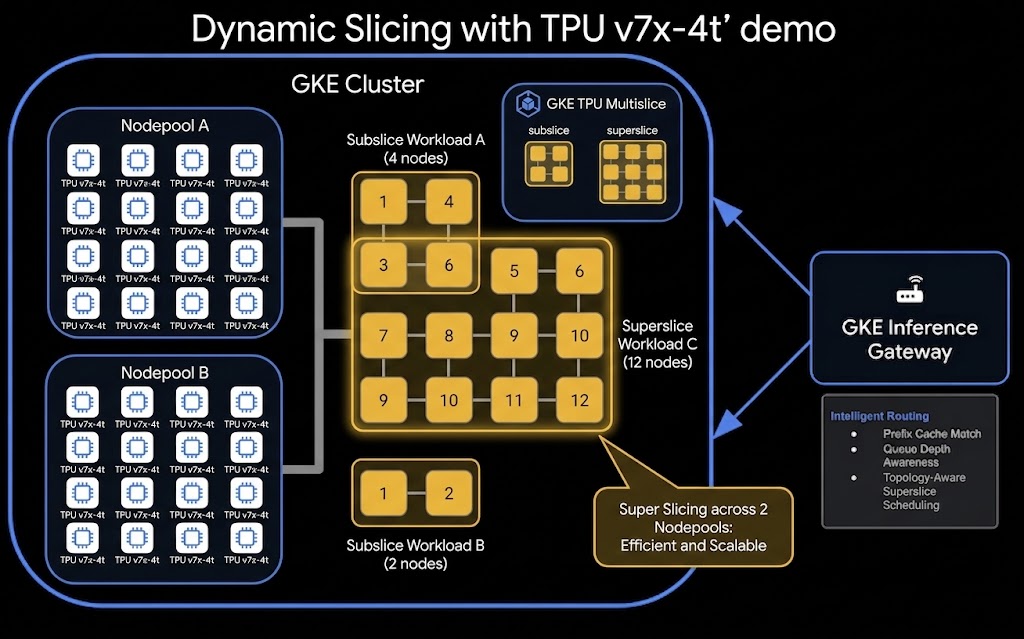
Что вы будете делать
- Разверните кластер GKE с включенным контроллером срезов GKE.
- Создайте пулы узлов GKE TPU, настроенные для инкрементального выделения ресурсов.
- Разверните Kueue и LeaderWorkerSet для управления рабочими нагрузками TPU.
- Для проверки доступа JAX TPU к меньшим фрагментам данных выполните задачу по разделению данных на подфрагменты .
- Запустите задачу суперсрезинга для проверки доступа JAX TPU к нескольким объединенным пулам узлов.
- Разверните систему дезагрегированного обслуживания , в которой этапы предварительного заполнения и декодирования выполняются на отдельных, динамически выделяемых сегментах TPU, координируемых маршрутизатором LLM.
Что вам понадобится
- Веб-браузер, например Chrome .
- Проект Google Cloud с включенной функцией выставления счетов.
- ВАЖНО : Доступ к резервированию места в режиме All Capacity для облачного сервера TPU7x (Ironwood).
2. Прежде чем начать
Создайте или выберите проект Google Cloud.
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- После подключения к Cloud Shell подтвердите свою аутентификацию:
gcloud auth list - Убедитесь, что ваш проект настроен:
gcloud config get project - Если параметры вашего проекта заданы не так, как ожидалось, настройте их следующим образом:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Клонируйте репозиторий демоверсий
Клонируйте репозиторий, содержащий манифесты и вспомогательные скрипты для этого практического занятия:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Настройка среды
Перед выделением ресурсов необходимо настроить переменные среды. Для создания файла env.sh предоставляется вспомогательный скрипт 01_setup_env.sh .
Запустите скрипт установки:
./01_setup_env.sh
Вам будет предложено ввести несколько значений. Нажмите [ENTER] , чтобы принять значения по умолчанию, но убедитесь, что вы указали правильное название бронирования и номер блока бронирования, предоставленные вашим инструктором мероприятия:
- Идентификатор проекта GCP : Ваш текущий идентификатор проекта.
- Номер проекта GCP : Номер вашего проекта.
- Имя кластера GKE :
tpu-serving-cluster(по умолчанию). - Зона пула узлов TPU :
us-central1-ai1a(по умолчанию). - Пространство имен Kubernetes :
llm-d-pd-disaggregation(по умолчанию). - Название резервирования Cloud TPU : [Введите указанное название резервирования]
- Название блока резервирования облачных TPU :
block-0(по умолчанию). - Название сегмента GCS для весов :
model-weights(по умолчанию). - Тип машины TPU :
tpu7x-standard-4t(по умолчанию). - Токен «Обнимающее лицо» : [Введите свой токен HF, если требуется, или нажмите ENTER, если используете предварительно загруженные грузы]
После запуска скрипта примените переменные к текущей сессии:
source env.sh
4. Включите API и функции AI Zone.
Теперь, когда ваша среда настроена, вам необходимо включить необходимые API Google Cloud и функцию видимости AI Zone. Предоставляется вспомогательный скрипт 02_enable_apis_and_features.sh .
Запустите скрипт:
./02_enable_apis_and_features.sh
Этот скрипт:
- Включает API-интерфейсы GKE, Compute, IAM, Resource Manager, Filestore и Network Services.
- Включает функцию предварительного просмотра
ai-zones-visibilityдля динамического нарезки GKE.
5. Создание кластера GKE и пулов узлов TPU.
На этом этапе вы выполните подготовку базовой сетевой инфраструктуры, кластера GKE и пулов узлов TPU.
Пулы узлов TPU будут настроены с использованием инкрементального выделения ресурсов (с помощью --placement-policy=superslice-policy и --reservation-affinity=specific ), который сопоставляет каждый пул узлов с 16-узловым «кубом» (подблоком) общей емкости TPU.
Запустите скрипт инициализации:
./03_create_cluster_and_nodes.sh
Что делает этот скрипт:
- Создание сети VPC и подсетей : Настраивает основную сеть VPC с большим MTU (8896), оптимизированную для трафика TPU, подсеть TPU и подсеть только для прокси, необходимую для шлюза GKE.
- Создает кластер GKE : Подготавливает стандартный кластер GKE с включенным контроллером срезов (
--enable-slice-controller). - Создает политику рабочей нагрузки : определяет политику ресурсов с именем
superslice-policyтипаHIGH_THROUGHPUTс топологией4x4x4. - Создает пулы узлов GKE TPU : выделяет два пула узлов (
tpu7-pool-1иtpu7-pool-2), каждый из которых содержит 16 узловtpu7x-standard-4t. Они представляют собой два отдельных куба по 16 узлов.
Проверьте узлы.
После завершения выполнения скрипта убедитесь, что все 32 узла TPU подготовлены и зарегистрированы:
kubectl get nodes -l google.com/tpu=present
В списке должно отображаться 32 узла.
6. Установите инструменты оркестровки.
Динамическое распределение ресурсов (Dynamic slicing) основано на использовании нескольких контроллеров Kubernetes для координации задач и распределения ресурсов. Вам потребуется установить:
- JobSet : Для управления группой заданий (необходим для суперсрезов).
- Kueue : Для организации очередей, управления ресурсами и планирования с учетом топологии сети (TAS).
- LeaderWorkerSet (LWS) : Для управления реплицированными многоузловыми развертываниями TPU (необходимы для обслуживания LLM).
- Контроллер срезов GKE (пользовательское пространство) : соединяет Kueue с директором кластера TPU для динамического управления физическими срезами.
Запустите скрипт установки:
./04_install_kueue_lws_slice_controller.sh
Убедитесь, что контроллер срезов успешно запущен:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Настройка ресурсов Kueue
Теперь вам необходимо определить ресурсы Kueue, представляющие вашу аппаратную топологию TPU, и настроить проверки доступа.
Запустите скрипт развертывания:
./05_deploy_kueue_resources.sh
Задействованные ключевые ресурсы:
- Топология (
slice-topology) : Определяет иерархические уровни разделов TPU (от блока до имени хоста), которые Kueue должен учитывать при планировании. - ResourceFlavor (
slice-rf) : Связываетslice-topologyс ускорителемtpu7x. - AdmissionCheck (
ac) : Настраивает Kueue для использования контроллера срезов GKE (accelerator.gke.io/slice) для динамического выделения срезов при принятии задания. - ClusterQueue (
cq) и LocalQueue (lq) : Настраивают очереди, в которые будут отправляться рабочие нагрузки. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000) : Определяет уровни приоритета для включения вытеснения и планирования на основе приоритетов.
Проверьте источники:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Развертывание и проверка доступа к TPU с использованием субсрезов.
Разделение на подмножества позволяет запускать несколько небольших рабочих нагрузок в рамках одного выделенного блока TPU. На этом этапе вы отправите рабочую нагрузку, запрашивающую топологию 2x2x2 (8 чипов / 2 виртуальные машины), в кластер, состоящий из блоков 4x4x4 (64 чипа / 16 виртуальных машин).
Разверните рабочую нагрузку по сегментированию:
./06_deploy_simple_subslicing.sh
Этот скрипт применяет файл kueue-jobset-simple-subslicing.yaml .
Как это работает:
- Спецификация JobSet включает аннотацию
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - В настройках задано
replicas: 6иparallelism: 2(количество завершений: 2). Это означает, что Kueue запланирует 6 независимых заданий, каждое из которых будет состоять из 2 подов. - Каждый под запрашивает
google.com/tpu: "4"(1 TPU VM). - Kueue и контроллер GKE Slice Controller динамически распределяют ресурсы в кластере из 32 узлов, выделяя шесть срезов
2x2x2.
Проверьте выполнение JAX.
Отслеживайте работу модулей до тех пор, пока они не начнут работать:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Проверьте логи одного из подов, чтобы убедиться, что JAX успешно обнаружил 8 устройств TPU (ядер) в своем подслайсе:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
В результате вы должны увидеть следующее сообщение: Total TPU devices (cores): 8
9. Развертывание и проверка доступа к TPU с использованием суперсрезов.
Функция супер-срезов (Super-slicing) — это мощная возможность GKE, позволяющая одной рабочей нагрузке охватывать несколько физических блоков TPU (часто называемых кубами или топологиями, например, 4x4x4 ). Объединяя эти блоки, можно сформировать больший виртуальный срез для крупномасштабных задач обучения или обслуживания. На этом этапе вы развернете набор заданий (JobSet), запрашивающий топологию 4x4x8 (128 чипов / 32 виртуальных машины). Поскольку один блок 4x4x4 содержит всего 64 чипа, эта рабочая нагрузка превышает размер одного блока и требует от GKE динамического объединения пулов узлов tpu7-pool-1 и tpu7-pool-2 для удовлетворения запроса.
Разверните рабочую нагрузку суперсрезов:
./07_deploy_simple_superslicing.sh
Этот скрипт применяет файл kueue-jobset-simple-superslicing.yaml .
Как это работает:
- Шаблон JobSet включает аннотацию
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Он настраивает
parallelism: 32иcompletions: 32. - Каждый pod запрашивает
google.com/tpu: "4". - Поскольку топология
4x4x8требует наличия всех 32 узлов, контроллер Slice Controller динамически настраивает сеть OCS (Optical Circuit Switching) для объединения двух пулов по 16 узлов в единую 32-узловую сеть ICI.
Убедитесь, что модули JobSet успешно запущены и что JAX обнаруживает все 128 устройств:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Проверьте логи одного из подов:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
В результате выполнения JAX должно отобразиться общее количество устройств: Global device count: 128
10. Внедрение дезагрегированного обслуживания (предварительное заполнение/декодирование)
Теперь вы развернете сквозную систему обслуживания LLM, используя дезагрегацию с предварительным заполнением/декодированием .
В стандартном режиме обслуживания предварительное заполнение (обработка запроса) и декодирование (генерация токенов) выполняются на одних и тех же TPU. Поскольку предварительное заполнение ограничено вычислительными ресурсами, а декодирование — пропускной способностью памяти, они конфликтуют. В режиме дезагрегированного обслуживания они выполняются на отдельных TPU-блоках, передавая кэш ключ-значение по сети.
Настройка LLM-D и шлюза.
Настройте пространства имен, секреты Hugging Face и шлюз GKE:
./08_setup_llm_d.sh
Развертывание маршрутизатора LLM-D
Разверните маршрутизатор, который будет принимать запросы клиентов и координировать маршрутизацию между сегментами Prefill и Decode:
./09_deploy_llm_d_router.sh
Развертывание рабочих нагрузок предварительного заполнения и декодирования
Разверните серверы модели vLLM на динамически выделяемых срезах TPU:
./10_deploy_subslicing_pd_workload.sh
Что это делает:
- Развертывает
kueue-vllm-prefill-model-streamer(LWS запрашивает фрагмент TPU2x2x2). - Развертывает
kueue-vllm-decode-model-streamer(LWS запрашивает фрагмент TPU2x2x2). - Срез предварительного заполнения загружает весовые коэффициенты модели Qwen 397B и выступает в качестве
kv_producer. - Срез декодирования выступает в роли
kv_consumer. - Они обмениваются данными, используя
TPUConnectorHMA, для передачи кэша ключ-значение.
Дождитесь, пока одновременно будут запущены модули предварительного заполнения и декодирования:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Проверьте подачу блюда.
После запуска процессов маршрутизации, предварительного заполнения и декодирования вы можете проверить работоспособность API.
Запустите скрипт проверки:
./11_verify_serving.sh
Как это работает:
- Скрипт получает внутренний IP-адрес шлюза GKE.
- Он запускает временный под (
curl-debug-comp), чтобы отправить запрос на завершение по адресуhttp://${GATEWAY_IP}/v1/completions. - Он запускает еще один под (
curl-debug-chat), чтобы отправить запрос в чат по адресуhttp://${GATEWAY_IP}/v1/chat/completions.
Вы должны увидеть успешный JSON-ответ от модели Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия.
Запустите скрипт завершения работы:
./12_teardown_cleanup.sh
Что делает этот скрипт:
- Удаляет пулы узлов GKE (
tpu7-pool-1,tpu7-pool-2). - Удаляет кластер GKE (
tpu-serving-cluster). - Удаляет политики ресурсов (
superslice-policy). - Удаляет сети VPC (
qwen-serving-main).
В качестве альтернативы, если вы создали отдельный проект для этого практического занятия, вы можете удалить весь проект целиком:
gcloud projects delete ${PROJECT_ID}
13. Поздравляем!
Поздравляем! Вы успешно изучили технологию GKE Dynamic Slicing и развернули архитектуру дезагрегированного LLM-сервера.
Что вы узнали
- Как включить контроллер GKE Slice и настроить пулы узлов для инкрементального выделения ресурсов .
- Как использовать Kueue для запроса конкретных топологий TPU.
- Как функция Sub-Slicing разделяет большой блок TPU на более мелкие, независимые рабочие нагрузки JAX.
- Как технология Super-slicing объединяет несколько пулов узлов в один большой виртуальный TPU-срез.
- Как развернуть дезагрегированное обслуживание с предварительным заполнением/декодированием с использованием LWS, Gateway API и vLLM.