
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีใช้ GKE Dynamic Slicing เพื่อเพิ่มประสิทธิภาพการใช้ทรัพยากร Cloud TPU Dynamic Slicing เป็นความสามารถอันทรงพลังที่ช่วยให้คุณแยกการจัดสรร TPU ดิบออกจากการจัดกำหนดการภาระงานได้
โดยเฉพาะอย่างยิ่ง คุณจะได้สำรวจรูปแบบสำคัญ 2 รูปแบบ ได้แก่
- Sub-slicing: การแยกบล็อก TPU ขนาดใหญ่ที่จัดสรรไว้แล้วออกเป็น Slice ที่เล็กลงและแยกกันสำหรับภาระงานที่เล็กลง
- Super-slicing: การรวมบล็อก TPU ที่จัดสรรไว้แล้วหลายๆ บล็อกเข้าด้วยกันเพื่อสร้าง Slice เสมือนขนาดใหญ่ขึ้นสำหรับภาระงานขนาดใหญ่
คุณจะใช้รูปแบบเหล่านี้เพื่อติดตั้งใช้งานสถาปัตยกรรม Disaggregated Serving (Prefill/Decode disaggregation) ประสิทธิภาพสูงสำหรับโมเดลภาษาขนาดใหญ่ (Qwen 397B) โดยใช้ Kueue, LeaderWorkerSet (LWS) และ Gateway API
สถาปัตยกรรม
นี่คือสถาปัตยกรรมระดับสูงของการตั้งค่า TPU Dynamic Slicing และ Disaggregated Serving
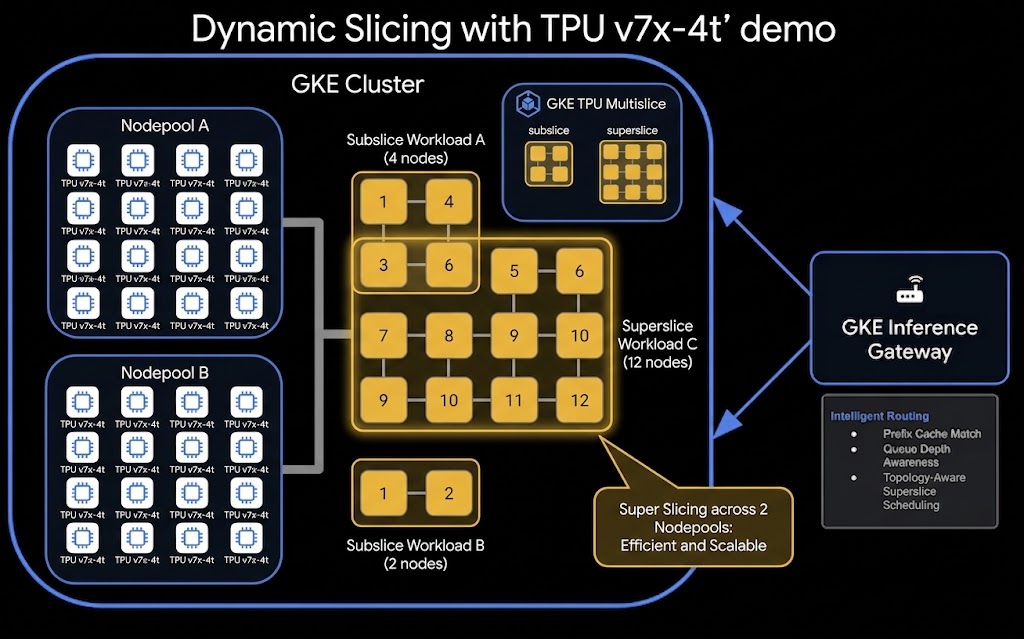
สิ่งที่คุณจะได้ทำ
- จัดสรรคลัสเตอร์ GKE ที่เปิดใช้ GKE Slice Controller
- สร้าง Node Pool ของ GKE TPU ที่กำหนดค่าสำหรับการจัดสรรแบบเพิ่ม
- ติดตั้งใช้งาน Kueue และ LeaderWorkerSet เพื่อจัดการภาระงาน TPU
- เรียกใช้ภาระงาน Sub-slicing เพื่อยืนยันการเข้าถึง JAX TPU ใน Slice ที่เล็กลง
- เรียกใช้ภาระงาน Super-slicing เพื่อยืนยันการเข้าถึง JAX TPU ใน Node Pool หลายรายการที่รวมกัน
- ติดตั้งใช้งาน Disaggregated Serving ซึ่งขั้นตอน Prefill และ Decode จะทำงานใน Slice TPU ที่จัดสรรแบบไดนามิกและแยกกัน โดยมีเราเตอร์ LLM เป็นผู้ประสานงาน
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- สำคัญ: สิทธิ์เข้าถึงการจองโหมดความจุทั้งหมดของ Cloud TPU7x (Ironwood)
2. ก่อนเริ่มต้น
สร้างหรือเลือกโปรเจ็กต์ Google Cloud
สร้างโปรเจ็กต์ Google Cloud
- ใน Google Cloud Console บนหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้ว
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งมาพร้อมกับเครื่องมือที่จำเป็น
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list - ยืนยันว่าได้กำหนดค่าโปรเจ็กต์แล้ว
gcloud config get project - หากโปรเจ็กต์ไม่ได้ตั้งค่าตามที่คาดไว้ ให้ตั้งค่าดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
โคลนที่เก็บการสาธิต
โคลนที่เก็บที่มีไฟล์ Manifest และสคริปต์ตัวช่วยสำหรับ Codelab นี้
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. กำหนดค่าสภาพแวดล้อม
คุณต้องกำหนดค่าตัวแปรสภาพแวดล้อมก่อนจัดสรรทรัพยากร เรามีสคริปต์ตัวช่วย 01_setup_env.sh ไว้ให้เพื่อสร้างไฟล์ env.sh
เรียกใช้สคริปต์การตั้งค่า
./01_setup_env.sh
ระบบจะแจ้งให้คุณป้อนค่าต่างๆ กด [ENTER] เพื่อยอมรับค่าเริ่มต้น แต่โปรดระบุชื่อการจอง และบล็อกการจอง ที่ถูกต้องซึ่งผู้สอนกิจกรรมของคุณให้ไว้
- รหัสโปรเจ็กต์ GCP: รหัสโปรเจ็กต์ปัจจุบัน
- หมายเลขโปรเจ็กต์ GCP: หมายเลขโปรเจ็กต์
- ชื่อคลัสเตอร์ GKE:
tpu-serving-cluster(ค่าเริ่มต้น) - โซน Node Pool ของ TPU:
us-central1-ai1a(ค่าเริ่มต้น) - เนมสเปซ Kubernetes:
llm-d-pd-disaggregation(ค่าเริ่มต้น) - ชื่อการจอง Cloud TPU: [ป้อนชื่อการจองที่ได้รับ]
- ชื่อบล็อกการจอง Cloud TPU:
block-0(ค่าเริ่มต้น) - ชื่อ Bucket ของ GCS สำหรับน้ำหนัก:
model-weights(ค่าเริ่มต้น) - ประเภทเครื่อง TPU:
tpu7x-standard-4t(ค่าเริ่มต้น) - โทเค็น Hugging Face: [ป้อนโทเค็น HF หากจำเป็น หรือกด ENTER หากใช้น้ำหนักที่โหลดไว้ล่วงหน้า]
หลังจากเรียกใช้สคริปต์แล้ว ให้ใช้ตัวแปรกับเซสชันปัจจุบันโดยทำดังนี้
source env.sh
4. เปิดใช้ API และฟีเจอร์ AI Zone
เมื่อกำหนดค่าสภาพแวดล้อมแล้ว คุณต้องเปิดใช้ Cloud APIs ของ Google Cloud ที่จำเป็นและฟีเจอร์การมองเห็น AI Zone เรามีสคริปต์ตัวช่วย 02_enable_apis_and_features.sh ไว้ให้
เรียกใช้สคริปต์
./02_enable_apis_and_features.sh
สคริปต์นี้จะทำสิ่งต่อไปนี้
- เปิดใช้ API ของ GKE, Compute, IAM, Resource Manager, Filestore และ Network Services
- เปิดใช้ฟีเจอร์
ai-zones-visibilityในเวอร์ชันตัวอย่างสำหรับ GKE Dynamic Slicing
5. จัดสรรคลัสเตอร์ GKE และ Node Pool ของ TPU
ในขั้นตอนนี้ คุณจะจัดสรรโครงสร้างพื้นฐานของเครือข่าย คลัสเตอร์ GKE และ Node Pool ของ TPU
Node Pool ของ TPU จะได้รับการกำหนดค่าด้วยการจัดสรรแบบเพิ่ม (โดยใช้ --placement-policy=superslice-policy และ --reservation-affinity=specific) ซึ่งจะแมป Node Pool แต่ละรายการกับ "คิวบ์" (บล็อกย่อย) ขนาด 16 โหนดของความจุ TPU ดิบ
เรียกใช้สคริปต์การจัดสรร
./03_create_cluster_and_nodes.sh
สิ่งที่สคริปต์นี้ทำ
- สร้างเครือข่าย VPC และซับเน็ต: ตั้งค่าเครือข่าย VPC หลักที่มี MTU ขนาดใหญ่ (8896) ซึ่งปรับให้เหมาะกับปริมาณการรับส่งข้อมูล TPU, ซับเน็ต TPU และซับเน็ตพร็อกซีเท่านั้นที่ GKE Gateway ต้องการ
- สร้างคลัสเตอร์ GKE: จัดสรรคลัสเตอร์ GKE มาตรฐานที่เปิดใช้ Slice Controller (
--enable-slice-controller) - สร้างนโยบายภาระงาน: กำหนดนโยบายทรัพยากรชื่อ
superslice-policyประเภทHIGH_THROUGHPUTที่มีโทโพโลยี4x4x4 - สร้าง Node Pool ของ GKE TPU: จัดสรร Node Pool 2 รายการ (
tpu7-pool-1และtpu7-pool-2) ซึ่งแต่ละรายการมีโหนดtpu7x-standard-4tจำนวน 16 โหนด ซึ่งแสดงถึงคิวบ์ 16 โหนด 2 รายการที่แยกกัน
ยืนยันโหนด
เมื่อสคริปต์ทำงานเสร็จแล้ว ให้ยืนยันว่าได้จัดสรรและลงทะเบียนโหนด TPU ทั้ง 32 โหนดแล้ว
kubectl get nodes -l google.com/tpu=present
คุณควรเห็นโหนด 32 โหนดในรายการ
6. ติดตั้งเครื่องมือการจัดการเป็นกลุ่ม
Dynamic Slicing ใช้ตัวควบคุม Kubernetes หลายรายการเพื่อประสานงานการจัดสรรงานและ Slice โดยคุณจะต้องติดตั้งเครื่องมือต่อไปนี้
- JobSet: สำหรับจัดการกลุ่มงาน (จำเป็นสำหรับ Super-slicing)
- Kueue: สำหรับการจัดคิว การจัดการทรัพยากร และการจัดกำหนดการที่คำนึงถึงโทโพโลยี (TAS)
- LeaderWorkerSet (LWS): สำหรับจัดการการติดตั้งใช้งาน TPU แบบหลายโหนดที่จำลองขึ้น (จำเป็นสำหรับการแสดงผล LLM)
- GKE Slice Controller (พื้นที่ผู้ใช้): เชื่อมต่อ Kueue กับ TPU Cluster Director เพื่อจัดการ Slice จริงแบบไดนามิก
เรียกใช้สคริปต์การติดตั้ง
./04_install_kueue_lws_slice_controller.sh
ยืนยันว่า Slice Controller ทำงานได้สำเร็จโดยทำดังนี้
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. กำหนดค่าทรัพยากร Kueue
ตอนนี้คุณต้องกำหนดทรัพยากร Kueue ที่แสดงถึงโทโพโลยีฮาร์ดแวร์ TPU และกำหนดค่าการตรวจสอบการยอมรับ
เรียกใช้สคริปต์การติดตั้งใช้งาน
./05_deploy_kueue_resources.sh
ทรัพยากรหลักที่ติดตั้งใช้งาน
- โทโพโลยี (
slice-topology): กำหนดระดับลำดับชั้นของการแบ่งพาร์ติชัน TPU (จากบล็อกลงไปจนถึงชื่อโฮสต์) ที่ Kueue ควรพิจารณาเมื่อจัดกำหนดการ - ResourceFlavor (
slice-rf): เชื่อมโยงslice-topologyกับตัวเร่งความเร็วtpu7x - AdmissionCheck (
ac): กำหนดค่า Kueue ให้ใช้ GKE Slice Controller (accelerator.gke.io/slice) เพื่อจัดสรร Slice แบบไดนามิกเมื่อมีการยอมรับงาน - ClusterQueue (
cq) & LocalQueue (lq): ตั้งค่าคิวที่จะส่งภาระงาน - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): กำหนดระดับความสำคัญเพื่อเปิดใช้การขัดจังหวะและการจัดกำหนดการตามลำดับความสำคัญ
ยืนยันทรัพยากรโดยทำดังนี้
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. ติดตั้งใช้งานและยืนยันการเข้าถึง TPU ด้วย Sub-slicing
Sub-slicing ช่วยให้คุณเรียกใช้ภาระงานขนาดเล็กหลายรายการภายในบล็อก TPU เดียวที่จัดสรรไว้แล้ว ในขั้นตอนนี้ คุณจะส่งภาระงานที่ขอโทโพโลยี 2x2x2 (8 ชิป / 2 VM) ไปยังคลัสเตอร์ที่สร้างจากบล็อก 4x4x4 (64 ชิป / 16 VM)
ติดตั้งใช้งานภาระงาน Sub-slicing โดยทำดังนี้
./06_deploy_simple_subslicing.sh
สคริปต์นี้จะใช้ kueue-jobset-simple-subslicing.yaml
วิธีการทำงาน
- ข้อมูลจำเพาะของ JobSet มีคำอธิบายประกอบ
cloud.google.com/gke-tpu-slice-topology: 2x2x2 - กำหนดค่า
replicas: 6และparallelism: 2(completions: 2) ซึ่งหมายความว่า Kueue จะจัดกำหนดการงานอิสระ 6 งาน ซึ่งแต่ละงานประกอบด้วยพ็อด 2 รายการ - แต่ละพ็อดขอ
google.com/tpu: "4"(1 TPU VM) - Kueue และ GKE Slice Controller จะแบ่งคลัสเตอร์ 32 โหนดแบบไดนามิกเพื่อจัดสรร Slice
2x2x2จำนวน 6 รายการ
ยืนยันการดำเนินการ JAX
ตรวจสอบพ็อดจนกว่าจะทำงานโดยทำดังนี้
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
ตรวจสอบบันทึกของพ็อดรายการใดรายการหนึ่งเพื่อยืนยันว่า JAX ตรวจพบอุปกรณ์ (คอร์) TPU 8 รายการใน Slice ย่อยได้สำเร็จโดยทำดังนี้
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
คุณควรเห็นเอาต์พุตที่ระบุว่า Total TPU devices (cores): 8
9. ติดตั้งใช้งานและยืนยันการเข้าถึง TPU ด้วย Super-slicing
Super-slicing เป็นฟีเจอร์ GKE อันทรงพลังที่ช่วยให้ภาระงานเดียวครอบคลุมบล็อก TPU จริงหลายบล็อก (มักเรียกว่าคิวบ์หรือโทโพโลยี เช่น 4x4x4) การรวมบล็อกเหล่านี้เข้าด้วยกันจะช่วยให้คุณสร้าง Slice TPU เสมือนขนาดใหญ่ขึ้นสำหรับการฝึกหรือการแสดงผลภาระงานขนาดใหญ่ ในขั้นตอนนี้ คุณจะติดตั้งใช้งาน JobSet ที่ขอโทโพโลยี 4x4x8 (128 ชิป / 32 VM) เนื่องจากบล็อก 4x4x4 เดียวมีชิปเพียง 64 ชิป ภาระงานนี้จึงมีขนาดใหญ่กว่าบล็อกเดียวและต้องใช้ GKE ในการรวม Node Pool tpu7-pool-1 และ tpu7-pool-2 เข้าด้วยกันแบบไดนามิกเพื่อตอบสนองคำขอ
ติดตั้งใช้งานภาระงาน Super-slicing โดยทำดังนี้
./07_deploy_simple_superslicing.sh
สคริปต์นี้จะใช้ kueue-jobset-simple-superslicing.yaml
วิธีการทำงาน
- เทมเพลต JobSet มีคำอธิบายประกอบ
cloud.google.com/gke-tpu-slice-topology: 4x4x8 - กำหนดค่า
parallelism: 32และcompletions: 32 - แต่ละพ็อดขอ
google.com/tpu: "4" - เนื่องจากโทโพโลยี
4x4x8ต้องใช้โหนดทั้งหมด 32 โหนด Slice Controller จึงกำหนดค่าเครือข่าย OCS (Optical Circuit Switching) แบบไดนามิกเพื่อเชื่อมต่อ Node Pool 2 รายการที่มี 16 โหนดเข้าด้วยกันเป็น Mesh ICI เดียวที่มี 32 โหนด
ยืนยันว่าพ็อด JobSet ทำงานได้สำเร็จและ JAX ตรวจพบอุปกรณ์ทั้งหมด 128 รายการโดยทำดังนี้
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
ตรวจสอบบันทึกของพ็อดรายการใดรายการหนึ่งโดยทำดังนี้
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
คุณควรเห็นเอาต์พุต JAX ที่แสดงจำนวนอุปกรณ์ทั่วโลก Global device count: 128
10. ติดตั้งใช้งาน Disaggregated Serving (Prefill/Decode)
ตอนนี้คุณจะติดตั้งใช้งานสแต็กการแสดงผล LLM แบบครบวงจรโดยใช้ Prefill/Decode Disaggregation
ในการแสดงผลมาตรฐาน ขั้นตอน Prefill (การประมวลผลพรอมต์) และ Decode (การสร้างโทเค็น) จะทำงานบน TPU เดียวกัน เนื่องจาก Prefill มีข้อจำกัดด้านการประมวลผล และ Decode มีข้อจำกัดด้านแบนด์วิดท์ของหน่วยความจำ จึงเกิดความขัดแย้ง Disaggregated Serving จะเรียกใช้ขั้นตอนเหล่านี้ใน Slice TPU ที่แยกกัน โดยจะโอนแคช KV ผ่านเครือข่าย
ตั้งค่า LLM-D และเกตเวย์
ตั้งค่าเนมสเปซ, Secret ของ Hugging Face และ GKE Gateway โดยทำดังนี้
./08_setup_llm_d.sh
ติดตั้งใช้งานเราเตอร์ LLM-D
ติดตั้งใช้งานเราเตอร์ที่จะรับคำขอของไคลเอ็นต์และประสานงานการกำหนดเส้นทางระหว่าง Slice Prefill และ Decode โดยทำดังนี้
./09_deploy_llm_d_router.sh
ติดตั้งใช้งานภาระงาน Prefill และ Decode
ติดตั้งใช้งานเซิร์ฟเวอร์โมเดล vLLM ใน Slice TPU ที่จัดสรรแบบไดนามิกโดยทำดังนี้
./10_deploy_subslicing_pd_workload.sh
สิ่งที่สคริปต์นี้ทำ
- ติดตั้งใช้งาน
kueue-vllm-prefill-model-streamer(LWS ที่ขอ Slice TPU2x2x2) - ติดตั้งใช้งาน
kueue-vllm-decode-model-streamer(LWS ที่ขอ Slice TPU2x2x2) - Slice Prefill จะโหลดน้ำหนักโมเดล Qwen 397B และทำหน้าที่เป็น
kv_producer - Slice Decode จะทำหน้าที่เป็น
kv_consumer - Slice ทั้ง 2 จะสื่อสารกันโดยใช้
TPUConnectorHMAเพื่อโอนแคช KV
รอจนกว่าพ็อด Prefill และ Decode จะทำงานโดยทำดังนี้
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. ยืนยันการแสดงผล
เมื่อเราเตอร์ ภาระงาน Prefill และ Decode ทำงานแล้ว คุณก็ยืนยัน Serving API ได้โดยทำดังนี้
เรียกใช้สคริปต์การยืนยันโดยทำดังนี้
./11_verify_serving.sh
วิธีการทำงาน
- สคริปต์จะดึงข้อมูล IP ภายในของ GKE Gateway
- สคริปต์จะเปิดพ็อดชั่วคราว (
curl-debug-comp) เพื่อส่งคำขอการเติมข้อความอัตโนมัติไปยังhttp://${GATEWAY_IP}/v1/completions - สคริปต์จะเปิดพ็อดอีกรายการ (
curl-debug-chat) เพื่อส่งคำขอแชทไปยังhttp://${GATEWAY_IP}/v1/chat/completions
คุณควรเห็นการตอบกลับ JSON ที่สำเร็จจากโมเดล Qwen โดยทำดังนี้
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. ล้างข้อมูล
หากต้องการหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องจากบัญชี Google Cloud ให้ลบทรัพยากรที่สร้างขึ้นระหว่าง Codelab นี้
เรียกใช้สคริปต์การล้างข้อมูลโดยทำดังนี้
./12_teardown_cleanup.sh
สิ่งที่สคริปต์นี้ทำ
- ลบ Node Pool ของ GKE (
tpu7-pool-1,tpu7-pool-2) - ลบคลัสเตอร์ GKE (
tpu-serving-cluster) - ลบนโยบายทรัพยากร (
superslice-policy) - ลบเครือข่าย VPC (
qwen-serving-main)
หรือหากคุณสร้างโปรเจ็กต์เฉพาะสำหรับ Codelab นี้ คุณสามารถลบโปรเจ็กต์ทั้งหมดได้โดยทำดังนี้
gcloud projects delete ${PROJECT_ID}
13. ขอแสดงความยินดี
ยินดีด้วย คุณได้สำรวจ GKE Dynamic Slicing และติดตั้งใช้งานสถาปัตยกรรมการแสดงผล LLM แบบ Disaggregated ได้สำเร็จแล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีเปิดใช้ GKE Slice Controller และกำหนดค่า Node Pool สำหรับการจัดสรรแบบเพิ่ม
- วิธีใช้ Kueue เพื่อขอโทโพโลยี TPU ที่เฉพาะเจาะจง
- วิธีที่ Sub-slicing แยกบล็อก TPU ขนาดใหญ่ออกเป็นภาระงาน JAX ที่เล็กลงและเป็นอิสระ
- วิธีที่ Super-slicing รวม Node Pool หลายรายการเข้าด้วยกันเป็น Slice TPU เสมือนขนาดใหญ่ขึ้นรายการเดียว
- วิธีติดตั้งใช้งาน Prefill/Decode Disaggregated Serving โดยใช้ LWS, Gateway API และ vLLM