
1. Giriş
Bu codelab'de, Cloud TPU kaynaklarının kullanımını optimize etmek için GKE Dynamic Slicing'i nasıl kullanacağınızı öğreneceksiniz. Dinamik dilimleme, ham TPU tedarikini iş yükü planlamadan ayırmanıza olanak tanıyan güçlü bir özelliktir.
Özellikle iki temel kalıbı inceleyeceksiniz:
- Alt dilimleme: Büyük bir sağlanan TPU bloğunu daha küçük iş yükleri için daha küçük ve izole dilimlere bölme.
- Süper dilimleme: Büyük ölçekli iş yükleri için daha büyük bir sanal dilim oluşturmak üzere, sağlanan birden fazla TPU bloğunu birleştirme.
Bu kalıpları, Kueue, LeaderWorkerSet (LWS) ve Gateway API'yi kullanarak büyük bir dil modeli (Qwen 397B) için yüksek performanslı bir Ayrılmış Sunum (Ön Doldurma/Ayrıştırma ayrıştırması) mimarisi dağıtmak üzere uygulayacaksınız.
Mimari
TPU Dynamic Slicing ve Disaggregated Serving kurulumunun genel mimarisi aşağıda verilmiştir:
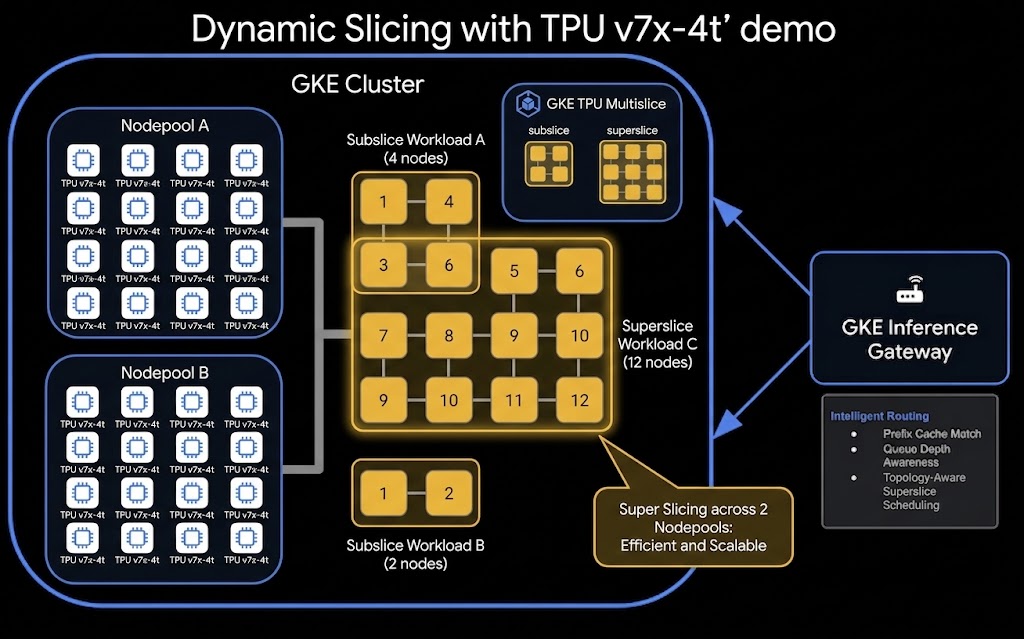
Yapacaklarınız
- GKE Slice Controller'ın etkin olduğu bir GKE kümesi sağlayın.
- Artımlı sağlama için yapılandırılmış GKE TPU düğümü havuzları oluşturun.
- TPU iş yüklerini yönetmek için Kueue ve LeaderWorkerSet'i dağıtın.
- Daha küçük dilimlerde JAX TPU erişimini doğrulamak için alt dilimleme iş yükü çalıştırın.
- Birleştirilmiş birden fazla düğüm havuzunda JAX TPU erişimini doğrulamak için superslicing iş yükü çalıştırın.
- Doldurma ve kod çözme aşamalarının, bir LLM yönlendirici tarafından koordine edilen ayrı ve dinamik olarak ayrılmış TPU dilimlerinde çalıştığı bir Ayrılmış Sunum kurulumu dağıtın.
İhtiyacınız olanlar
- Chrome gibi bir web tarayıcısı
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- ÖNEMLİ: Cloud TPU7x (Ironwood) All Capacity modu rezervasyonuna erişim.
2. Başlamadan önce
Google Cloud projesi oluşturma veya seçme
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i Başlatma
Cloud Shell, Google Cloud'da çalışan ve gerekli araçların önceden yüklendiği bir komut satırı ortamıdır.
- Google Cloud Console'un üst kısmında Activate Cloud Shell'i (Cloud Shell'i Etkinleştir) tıklayın.
- Cloud Shell'e bağlandıktan sonra kimlik doğrulamanızı onaylayın:
gcloud auth list - Projenizin yapılandırıldığını onaylayın:
gcloud config get project - Projeniz beklendiği gibi ayarlanmamışsa ayarlayın:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Demo deposunu klonlama
Bu codelab'in manifestlerini ve yardımcı komut dosyalarını içeren depoyu klonlayın:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Ortamı Yapılandırma
Kaynakları sağlamadan önce ortam değişkenlerinizi yapılandırmanız gerekir. env.sh dosyası oluşturmak için bir yardımcı komut dosyası 01_setup_env.sh sağlanır.
Kurulum komut dosyasını çalıştırın:
./01_setup_env.sh
Birkaç değer girmeniz istenir. Varsayılanları kabul etmek için [ENTER] tuşuna basın ancak etkinlik eğitmeniniz tarafından sağlanan doğru Rezervasyon Adı ve Rezervasyon Bloğu'nu girdiğinizden emin olun:
- GCP Proje Kimliği: Mevcut proje kimliğiniz.
- GCP Proje Numarası: Proje numaranız.
- GKE kümesi adı:
tpu-serving-cluster(varsayılan). - TPU düğümü havuzu bölgesi:
us-central1-ai1a(varsayılan). - Kubernetes ad alanı:
llm-d-pd-disaggregation(varsayılan). - Cloud TPU Rezervasyon Adı: [Sağlanan rezervasyon adını girin]
- Cloud TPU Rezervasyon Bloğu Adı:
block-0(varsayılan). - Ağırlıklar İçin GCS Paketi Adı:
model-weights(varsayılan). - TPU Machine Type:
tpu7x-standard-4t(varsayılan). - Hugging Face Jetonu: [Gerekirse HF jetonunuzu girin veya önceden yüklenmiş ağırlıklar kullanıyorsanız ENTER tuşuna basın]
Komut dosyasını çalıştırdıktan sonra değişkenleri mevcut oturumunuza uygulayın:
source env.sh
4. API'leri ve Yapay Zeka Bölgesi Özelliklerini Etkinleştirme
Ortamınız yapılandırıldığına göre, gerekli Google Cloud API'lerini ve AI Zone görünürlük özelliğini etkinleştirmeniz gerekir. Bir yardımcı komut dosyası 02_enable_apis_and_features.sh sağlanır.
Komut dosyasını çalıştırın:
./02_enable_apis_and_features.sh
Bu komut dosyası:
- GKE, Compute, IAM, Resource Manager, Filestore ve Network Services API'lerini etkinleştirir.
- GKE Dynamic Slicing için
ai-zones-visibilityönizleme özelliğini etkinleştirir.
5. GKE kümesi ve TPU düğüm havuzları sağlama
Bu adımda temel ağ altyapısını, GKE kümesini ve TPU düğüm havuzlarını sağlayacaksınız.
TPU düğüm havuzları, her düğüm havuzunu 16 düğümlü bir "küp"e (alt blok) eşleyen Artımlı Temel Hazırlık (--placement-policy=superslice-policy ve --reservation-affinity=specific kullanılarak) ile yapılandırılır.
Temel hazırlık komut dosyasını çalıştırın:
./03_create_cluster_and_nodes.sh
Bu komut dosyasının yaptığı işlemler:
- VPC ağı ve alt ağlar oluşturur: TPU trafiği için optimize edilmiş büyük bir MTU (8896) ile ana bir VPC ağı, bir TPU alt ağı ve GKE ağ geçidi için gerekli olan yalnızca proxy alt ağı oluşturur.
- GKE kümesi oluşturur: Dilim denetleyicisi etkin olarak bir Standart GKE kümesi sağlar (
--enable-slice-controller). - İş Yükü Politikası Oluşturur:
4x4x4topolojisine sahip,HIGH_THROUGHPUTtüründesuperslice-policyadlı bir kaynak politikası tanımlar. - GKE TPU düğüm havuzları oluşturur: Her biri 16 düğüm içeren iki düğüm havuzu (
tpu7-pool-1vetpu7-pool-2) sağlar. Bunlar, 16 düğümlü iki ayrı küpü temsil eder.tpu7x-standard-4t
Düğümleri doğrulama
Komut dosyası tamamlandıktan sonra 32 TPU düğümünün tamamının temel hazırlığının yapıldığını ve kaydedildiğini doğrulayın:
kubectl get nodes -l google.com/tpu=present
Listede 32 düğüm görmelisiniz.
6. Orkestrasyon Araçlarını Yükleme
Dinamik dilimleme, işleri ve dilim ayırmayı koordine etmek için çeşitli Kubernetes denetleyicilerine dayanır. Şunları yükleyeceksiniz:
- JobSet: İş gruplarını yönetmek için kullanılır (süper dilimleme için gereklidir).
- Kueue: Sıraya alma, kaynak yönetimi ve topolojiye duyarlı planlama (TAS) için kullanılır.
- LeaderWorkerSet (LWS): Çoğaltılmış çok düğümlü TPU dağıtımlarını yönetmek için (LLM hizmeti için gereklidir).
- GKE Slice Controller (Kullanıcı Alanı): Kueue'yi TPU Cluster Director'a bağlayarak fiziksel dilimleri dinamik olarak yönetir.
Yükleme komut dosyasını çalıştırın:
./04_install_kueue_lws_slice_controller.sh
Dilim denetleyicisinin başarıyla çalıştığını doğrulayın:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Kueue kaynaklarını yapılandırma
Şimdi TPU donanım topolojinizi temsil eden Kueue kaynaklarını tanımlamanız ve kabul kontrollerini yapılandırmanız gerekiyor.
Dağıtım komut dosyasını çalıştırın:
./05_deploy_kueue_resources.sh
Dağıtılan Önemli Kaynaklar:
- Topoloji (
slice-topology): Kueue'nun planlama yaparken dikkate alması gereken TPU bölümlerinin hiyerarşik düzeylerini (bloktan ana makine adına kadar) tanımlar. - ResourceFlavor (
slice-rf):slice-topologyiletpu7xhızlandırıcıyı ilişkilendirir. - AdmissionCheck (
ac): Bir iş kabul edildiğinde dilimleri dinamik olarak sağlamak için Kueue'yi GKE Dilim Denetleyicisi'ni (accelerator.gke.io/slice) kullanacak şekilde yapılandırır. - ClusterQueue (
cq) ve LocalQueue (lq): İş yüklerinin gönderileceği kuyrukları ayarlar. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): Öncelikli olarak planlamayı ve öncelik tabanlı planlamayı etkinleştirmek için öncelik düzeylerini tanımlar.
Kaynakları doğrulayın:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Alt dilimleme ile TPU erişimini dağıtma ve doğrulama
Alt dilimleme, tek bir sağlanan TPU bloğunda birden fazla küçük iş yükü çalıştırmanıza olanak tanır. Bu adımda, 2x2x2 topolojisi (8 çip / 2 sanal makine) isteyen bir iş yükünü 4x4x4 (64 çip / 16 sanal makine) bloklarından oluşan bir kümeye göndereceksiniz.
Alt dilimleme iş yükünü dağıtın:
./06_deploy_simple_subslicing.sh
Bu komut dosyası, kueue-jobset-simple-subslicing.yaml dosyasını uygular.
İşleyiş şekli:
- JobSet spesifikasyonu,
cloud.google.com/gke-tpu-slice-topology: 2x2x2ek açıklamasını içerir. replicas: 6veparallelism: 2(tamamlanma sayısı: 2) yapılandırılır. Bu, Kueue'nun her biri 2 poddan oluşan 6 bağımsız iş planlayacağı anlamına gelir.- Her kapsül
google.com/tpu: "4"(1 TPU VM) ister. - Kueue ve GKE Slice Controller, altı
2x2x2dilimi ayırmak için 32 düğümlü kümeyi dinamik olarak böler.
JAX yürütmesini doğrulama
Pod'lar çalışana kadar izleyin:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
JAX'in alt diliminde 8 TPU cihazının (çekirdek) başarıyla algılandığını doğrulamak için kapsüllerden birinin günlüklerini kontrol edin:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Aşağıdaki çıkışı görmeniz gerekir: Total TPU devices (cores): 8
9. TPU erişimini süper dilimleme ile dağıtma ve doğrulama
Süper dilimleme, tek bir iş yükünün birden fazla fiziksel TPU bloğunu (genellikle küpler veya 4x4x4 gibi topolojiler olarak adlandırılır) kapsamasına olanak tanıyan güçlü bir GKE özelliğidir. Bu blokları birleştirerek büyük ölçekli eğitim veya sunma iş yükleri için daha büyük bir sanal dilim oluşturabilirsiniz. Bu adımda, 4x4x8 topolojisi (128 çip / 32 VM) isteyen bir JobSet dağıtacaksınız. Tek bir 4x4x4 blok yalnızca 64 çip içerdiğinden bu iş yükü tek bir bloğun boyutunu aşıyor ve isteği karşılamak için GKE'nin tpu7-pool-1 ve tpu7-pool-2 düğüm havuzlarını dinamik olarak birleştirmesini gerektiriyor.
Superslicing iş yükünü dağıtın:
./07_deploy_simple_superslicing.sh
Bu komut dosyası, kueue-jobset-simple-superslicing.yaml dosyasını uygular.
İşleyiş şekli:
- JobSet şablonu,
cloud.google.com/gke-tpu-slice-topology: 4x4x8ek açıklamasını içerir. parallelism: 32vecompletions: 32yapılandırılır.- Her kapsül
google.com/tpu: "4"isteğinde bulunur. 4x4x8topolojisi için 32 düğümün tamamı gerektiğinden Slice Controller, iki 16 düğümlü havuzu tek bir 32 düğümlü ICI ağına bağlamak için OCS (Optik Devre Anahtarlama) ağını dinamik olarak yapılandırır.
JobSet kapsüllerinin başarıyla çalıştığını ve JAX'in 128 cihazın tamamını algıladığını doğrulayın:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Kapsüllerden birinin günlüklerini kontrol edin:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Genel cihaz sayısını gösteren JAX çıkışını görmeniz gerekir: Global device count: 128
10. Ayrılmış yayınlama (önceden doldurma/kod çözme) dağıtma
Şimdi Prefill/Decode Disaggregation kullanarak uçtan uca LLM yayınlama yığınını dağıtacaksınız.
Standart yayınlamada, önceden doldurma (istem işleme) ve kod çözme (jeton oluşturma) aynı TPU'larda çalışır. Önceden doldurma işlemi hesaplama açısından sınırlı, kod çözme işlemi ise bellek bant genişliği açısından sınırlı olduğundan bu iki işlem çakışır. Ayrıştırılmış sunum, bunları ayrı TPU dilimlerinde çalıştırır ve KV önbelleğini ağ üzerinden aktarır.
LLM-D ve Ağ Geçidi'ni kurma
Ad alanlarını, Hugging Face sırlarını ve GKE ağ geçidini ayarlayın:
./08_setup_llm_d.sh
LLM-D Router'ı dağıtma
İstemci isteklerini alacak ve Prefill ile Decode dilimleri arasındaki yönlendirmeyi koordine edecek yönlendiriciyi dağıtın:
./09_deploy_llm_d_router.sh
Ön Doldurma ve Kod Çözme İş Yüklerini Dağıtma
vLLM model sunucularını dinamik olarak ayrılmış TPU dilimlerine dağıtın:
./10_deploy_subslicing_pd_workload.sh
Bu özellik ne işe yarar?
kueue-vllm-prefill-model-streamerdağıtımları (LWS,2x2x2TPU dilimi istiyor).kueue-vllm-decode-model-streamerdağıtımları (LWS,2x2x2TPU dilimi istiyor).- Ön doldurma dilimi, Qwen 397B model ağırlıklarını yükler ve
kv_producerolarak işlev görür. - Kod çözme dilimi,
kv_consumergörevi görür. - KV önbelleklerini aktarmak için
TPUConnectorHMAkullanarak iletişim kurarlar.
Hem önceden doldurma hem de kod çözme pod'ları çalışana kadar bekleyin:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Yayınlamayı doğrulama
Yönlendirici, önceden doldurma ve kod çözme iş yükleri çalışırken artık sunma API'sini doğrulayabilirsiniz.
Doğrulama komut dosyasını çalıştırın:
./11_verify_serving.sh
İşleyiş şekli:
- Komut dosyası, GKE ağ geçidinin dahili IP'sini alır.
http://${GATEWAY_IP}/v1/completions'ye tamamlama isteği göndermek için geçici bir pod (curl-debug-comp) oluşturur.http://${GATEWAY_IP}/v1/chat/completions'ye sohbet isteği göndermek için başka bir pod (curl-debug-chat) oluşturur.
Qwen modelinden başarılı bir JSON yanıtı görmelisiniz:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Temizleme
Google Cloud hesabınızın sürekli olarak ücretlendirilmesini önlemek için bu codelab sırasında oluşturulan kaynakları silin.
Kaldırma komut dosyasını çalıştırın:
./12_teardown_cleanup.sh
Bu komut dosyasının yaptığı işlemler:
- GKE düğüm havuzlarını siler (
tpu7-pool-1,tpu7-pool-2). - GKE kümesini siler (
tpu-serving-cluster). - Kaynak politikalarını (
superslice-policy) siler. - VPC ağlarını (
qwen-serving-main) siler.
Alternatif olarak, bu codelab için özel bir proje oluşturduysanız projenin tamamını silebilirsiniz:
gcloud projects delete ${PROJECT_ID}
13. Tebrikler
Tebrikler! GKE Dinamik Dilimleme'yi başarıyla incelediniz ve ayrıştırılmış bir LLM sunma mimarisi dağıttınız.
Öğrendikleriniz
- GKE Slice Controller'ı etkinleştirme ve artımlı hazırlama için düğüm havuzlarını yapılandırma
- Belirli TPU topolojileri istemek için Kueue'yu kullanma
- Alt dilimleme, daha küçük ve bağımsız JAX iş yükleri için büyük bir TPU bloğunu nasıl böler?
- Super-slicing, birden fazla düğüm havuzunu tek bir büyük sanal TPU diliminde birleştirir.
- LWS, Gateway API ve vLLM kullanarak ayrıştırılmış sunum için önceden doldurma/kod çözme özelliğini dağıtma