
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách sử dụng tính năng Phân chia động GKE để tối ưu hoá việc sử dụng tài nguyên Cloud TPU. Phân đoạn động là một khả năng mạnh mẽ cho phép bạn tách việc cung cấp TPU thô khỏi việc lập lịch tải.
Cụ thể, bạn sẽ khám phá 2 mẫu khoá:
- Phân chia thành các phần nhỏ: Chia một khối TPU được cấp phép lớn thành các phần nhỏ hơn, riêng biệt cho các khối lượng công việc nhỏ hơn.
- Phân chia siêu dữ liệu: Ghép nhiều khối TPU được cấp phép lại với nhau để tạo thành một phân chia ảo lớn hơn cho các khối lượng công việc quy mô lớn.
Bạn sẽ áp dụng các mẫu này để triển khai cấu trúc Phân phát tách biệt (Phân tách trước/Giải mã) có hiệu suất cao cho một mô hình ngôn ngữ lớn (Qwen 397B) bằng cách sử dụng Kueue, LeaderWorkerSet (LWS) và Gateway API.
Kiến trúc
Sau đây là kiến trúc cấp cao của chế độ thiết lập Phân chia động TPU và Phân tách dịch vụ:
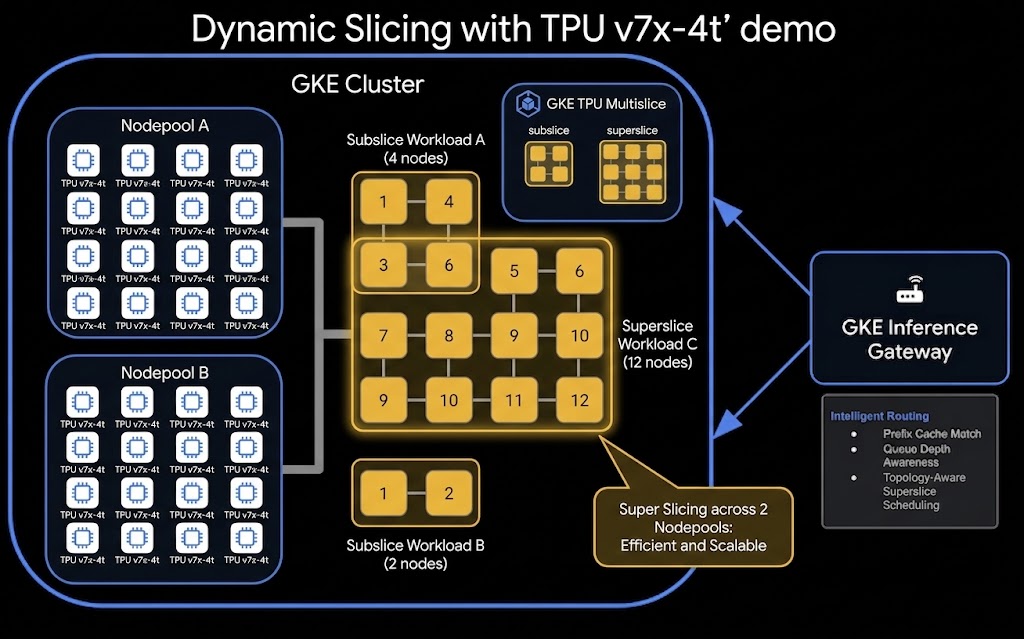
Bạn sẽ thực hiện
- Cung cấp một cụm GKE có bật GKE Slice Controller.
- Tạo nhóm nút TPU GKE được định cấu hình để cung cấp gia tăng.
- Triển khai Kueue và LeaderWorkerSet để quản lý khối lượng công việc TPU.
- Chạy một khối lượng công việc subslicing để xác minh quyền truy cập vào JAX TPU trên các lát nhỏ hơn.
- Chạy một khối lượng công việc superslicing để xác minh quyền truy cập vào JAX TPU trên nhiều nhóm nút kết hợp.
- Triển khai chế độ thiết lập Phân phát tách biệt, trong đó các giai đoạn Điền sẵn và Giải mã chạy trên các lát TPU riêng biệt, được phân bổ linh hoạt và được điều phối bởi một bộ định tuyến LLM.
Bạn cần có
- Một trình duyệt web như Chrome.
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
- QUAN TRỌNG: Quyền truy cập vào chế độ đặt trước Cloud TPU7x (Ironwood) All Capacity.
2. Trước khi bắt đầu
Tạo hoặc chọn một dự án trên Google Cloud
Tạo một dự án trên Google Cloud
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên đám mây. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
Khởi động Cloud Shell
Cloud Shell là một môi trường dòng lệnh chạy trong Google Cloud và được tải sẵn các công cụ cần thiết.
- Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.
- Sau khi kết nối với Cloud Shell, hãy xác minh thông tin xác thực của bạn:
gcloud auth list - Xác nhận rằng dự án của bạn đã được định cấu hình:
gcloud config get project - Nếu dự án của bạn không được thiết lập như mong đợi, hãy thiết lập dự án:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Sao chép kho lưu trữ hoạt động minh hoạ
Sao chép kho lưu trữ chứa các tệp kê khai và tập lệnh trợ giúp cho lớp học lập trình này:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. Định cấu hình môi trường
Trước khi cung cấp tài nguyên, bạn cần định cấu hình các biến môi trường. Một tập lệnh trợ giúp 01_setup_env.sh được cung cấp để tạo tệp env.sh.
Chạy tập lệnh thiết lập:
./01_setup_env.sh
Bạn sẽ được nhắc nhập một số giá trị. Nhấn [ENTER] để chấp nhận các giá trị mặc định, nhưng nhớ cung cấp Tên đặt trước và Khối đặt trước chính xác do người hướng dẫn sự kiện cung cấp:
- Mã dự án GCP: Mã dự án hiện tại của bạn.
- Số dự án trên Google Cloud Platform: Số dự án của bạn.
- Tên cụm GKE:
tpu-serving-cluster(mặc định). - TPU Node Pool Zone:
us-central1-ai1a(mặc định). - Không gian tên Kubernetes:
llm-d-pd-disaggregation(mặc định). - Tên đặt trước Cloud TPU: [Nhập tên đặt trước được cung cấp]
- Tên khối đặt trước Cloud TPU:
block-0(mặc định). - Tên bộ chứa GCS cho trọng số:
model-weights(mặc định). - Loại máy TPU:
tpu7x-standard-4t(mặc định). - Mã thông báo Hugging Face: [Nhập mã thông báo HF nếu cần hoặc nhấn ENTER nếu dùng các trọng số được tải sẵn]
Sau khi chạy tập lệnh, hãy áp dụng các biến cho phiên hiện tại:
source env.sh
4. Bật API và các tính năng của Vùng AI
Giờ đây, khi môi trường của bạn đã được định cấu hình, bạn cần bật các API cần thiết của Google Cloud và tính năng hiển thị Vùng AI. Một tập lệnh trợ giúp 02_enable_apis_and_features.sh sẽ được cung cấp.
Chạy tập lệnh:
./02_enable_apis_and_features.sh
Đoạn mã này:
- Cho phép các API GKE, Compute, IAM, Resource Manager, Filestore và Network Services.
- Bật tính năng xem trước
ai-zones-visibilitycho tính năng Phân chia động của GKE.
5. Cung cấp Cụm GKE và Nhóm nút TPU
Trong bước này, bạn sẽ cung cấp cơ sở hạ tầng mạng cơ bản, cụm GKE và nhóm nút TPU.
Các bộ nút TPU sẽ được định cấu hình bằng tính năng Cung cấp gia tăng (sử dụng --placement-policy=superslice-policy và --reservation-affinity=specific), tính năng này liên kết mỗi bộ nút với một "khối" (tiểu khối) gồm 16 nút có dung lượng TPU thô.
Chạy tập lệnh cấp phép:
./03_create_cluster_and_nodes.sh
Tập lệnh này làm những việc sau:
- Tạo mạng và mạng con VPC: Thiết lập một mạng VPC chính có MTU lớn (8896) được tối ưu hoá cho lưu lượng truy cập TPU, một mạng con TPU và một mạng con chỉ dành cho proxy do Cổng GKE yêu cầu.
- Tạo cụm GKE: Cung cấp một cụm GKE tiêu chuẩn có bật Slice Controller (
--enable-slice-controller). - Tạo Chính sách về khối lượng công việc: Xác định một chính sách tài nguyên có tên là
superslice-policythuộc loạiHIGH_THROUGHPUTvới một cấu trúc liên kết là4x4x4. - Tạo Nhóm nút TPU GKE: Cung cấp 2 nhóm nút (
tpu7-pool-1vàtpu7-pool-2), mỗi nhóm chứa 16 núttpu7x-standard-4t. Đây là hai khối 16 nút riêng biệt.
Xác minh các nút
Sau khi tập lệnh hoàn tất, hãy xác minh rằng tất cả 32 nút TPU đều được cung cấp và đăng ký:
kubectl get nodes -l google.com/tpu=present
Bạn sẽ thấy 32 nút trong danh sách.
6. Cài đặt công cụ điều phối
Tính năng phân chia linh hoạt dựa vào một số bộ điều khiển Kubernetes để điều phối các công việc và việc phân bổ phân đoạn. Bạn sẽ cài đặt:
- JobSet: Để quản lý nhóm các công việc (cần thiết cho tính năng chia siêu dữ liệu).
- Kueue: Để xếp hàng, quản lý tài nguyên và Lập lịch dựa trên cấu trúc liên kết (TAS).
- LeaderWorkerSet (LWS): Để quản lý các hoạt động triển khai TPU nhiều nút được sao chép (cần thiết cho việc phân phát mô hình ngôn ngữ lớn).
- GKE Slice Controller (Không gian người dùng): Kết nối Kueue với TPU Cluster Director để quản lý các phần vật lý một cách linh hoạt.
Chạy tập lệnh cài đặt:
./04_install_kueue_lws_slice_controller.sh
Xác minh rằng Slice Controller đang chạy thành công:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. Định cấu hình tài nguyên Kueue
Bây giờ, bạn cần xác định các tài nguyên Kueue đại diện cho cấu trúc liên kết phần cứng TPU và định cấu hình các bước kiểm tra chấp nhận.
Chạy tập lệnh triển khai:
./05_deploy_kueue_resources.sh
Các tài nguyên chính đã triển khai:
- Cấu trúc liên kết (
slice-topology): Xác định các cấp bậc của phân vùng TPU (từ khối xuống tên máy chủ) mà Kueue nên xem xét khi lập lịch. - ResourceFlavor (
slice-rf): Liên kếtslice-topologyvới trình tăng tốctpu7x. - AdmissionCheck (
ac): Định cấu hình Kueue để sử dụng GKE Slice Controller (accelerator.gke.io/slice) nhằm cung cấp các phần một cách linh hoạt khi một công việc được chấp nhận. - ClusterQueue (
cq) và LocalQueue (lq): Thiết lập các hàng đợi mà khối lượng công việc sẽ được gửi đến. - WorkloadPriorityClass (
low-priority-1000,medium-priority-2000,high-priority-3000): Xác định các cấp độ ưu tiên để cho phép ưu tiên và lập lịch dựa trên mức độ ưu tiên.
Xác minh các tài nguyên:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. Triển khai và xác minh quyền truy cập vào TPU bằng tính năng phân chia
Phân chia phụ cho phép bạn chạy nhiều khối lượng công việc nhỏ hơn trong một khối TPU được cấp phép duy nhất. Trong bước này, bạn sẽ gửi một tải công việc yêu cầu một cấu trúc liên kết 2x2x2 (8 chip / 2 VM) đến một cụm được tạo thành từ các khối 4x4x4 (64 chip / 16 VM).
Triển khai khối lượng công việc phân chia nhỏ:
./06_deploy_simple_subslicing.sh
Tập lệnh này áp dụng kueue-jobset-simple-subslicing.yaml.
Cách hoạt động:
- Thông số kỹ thuật JobSet bao gồm chú thích
cloud.google.com/gke-tpu-slice-topology: 2x2x2. - Thao tác này định cấu hình
replicas: 6vàparallelism: 2(hoàn thành: 2). Điều này có nghĩa là Kueue sẽ lên lịch cho 6 công việc độc lập, mỗi công việc bao gồm 2 nhóm. - Mỗi nhóm yêu cầu
google.com/tpu: "4"(1 VM TPU). - Kueue và GKE Slice Controller sẽ phân chia linh hoạt cụm 32 nút để phân bổ 6 lát
2x2x2.
Xác minh quá trình thực thi JAX
Theo dõi các pod cho đến khi chúng chạy:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
Kiểm tra nhật ký của một trong các nhóm để xác minh rằng JAX đã phát hiện thành công 8 thiết bị TPU (lõi) trên phân đoạn phụ của nhóm:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
Bạn sẽ thấy kết quả cho biết: Total TPU devices (cores): 8
9. Triển khai và xác minh quyền truy cập vào TPU bằng tính năng phân chia siêu dữ liệu
Super-slicing là một tính năng mạnh mẽ của GKE, cho phép một tải trọng duy nhất trải rộng trên nhiều khối TPU vật lý (thường được gọi là khối lập phương hoặc cấu trúc liên kết như 4x4x4). Bằng cách ghép các khối này lại với nhau, bạn có thể tạo thành một lát ảo lớn hơn cho các tải trọng huấn luyện hoặc phân phát quy mô lớn. Trong bước này, bạn sẽ triển khai một JobSet yêu cầu cấu trúc liên kết 4x4x8 (128 chip / 32 VM). Vì một khối 4x4x4 duy nhất chỉ chứa 64 chip, nên tải trọng này vượt quá kích thước của một khối duy nhất và yêu cầu GKE ghép các nhóm nút tpu7-pool-1 và tpu7-pool-2 lại với nhau một cách linh hoạt để đáp ứng yêu cầu.
Triển khai khối lượng công việc phân chia siêu dữ liệu:
./07_deploy_simple_superslicing.sh
Tập lệnh này áp dụng kueue-jobset-simple-superslicing.yaml.
Cách hoạt động:
- Mẫu JobSet bao gồm chú thích
cloud.google.com/gke-tpu-slice-topology: 4x4x8. - Thư viện này định cấu hình
parallelism: 32vàcompletions: 32. - Mỗi nhóm yêu cầu
google.com/tpu: "4". - Vì cấu trúc liên kết
4x4x8yêu cầu tất cả 32 nút, nên Bộ điều khiển phân đoạn sẽ định cấu hình động mạng OCS (Chuyển mạch quang) để kết nối hai nhóm 16 nút với nhau thành một mạng lưới ICI gồm 32 nút.
Xác minh rằng các nhóm JobSet chạy thành công và JAX phát hiện tất cả 128 thiết bị:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
Kiểm tra nhật ký của một trong các nhóm:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
Bạn sẽ thấy đầu ra JAX cho biết số lượng thiết bị trên toàn cầu: Global device count: 128
10. Triển khai tính năng phân phát tách biệt (Điền sẵn/Giải mã)
Giờ đây, bạn sẽ triển khai ngăn xếp phân phát LLM từ đầu đến cuối bằng cách sử dụng Phân tách giải mã/điền sẵn.
Trong quá trình phân phát tiêu chuẩn, bước điền sẵn (xử lý câu lệnh) và giải mã (tạo mã thông báo) chạy trên cùng một TPU. Vì tính năng điền sẵn bị giới hạn về khả năng tính toán và tính năng giải mã bị giới hạn về băng thông bộ nhớ, nên chúng xung đột với nhau. Tính năng phân phát tách biệt sẽ chạy các mô hình này trên các lát TPU riêng biệt, chuyển Bộ nhớ đệm KV qua mạng.
Thiết lập LLM-D và Cổng
Thiết lập không gian tên, khoá bí mật của Hugging Face và Cổng GKE:
./08_setup_llm_d.sh
Triển khai Bộ định tuyến LLM-D
Triển khai bộ định tuyến sẽ nhận các yêu cầu của ứng dụng và điều phối việc định tuyến giữa các lát Prefill và Decode:
./09_deploy_llm_d_router.sh
Triển khai khối lượng công việc điền sẵn và giải mã
Triển khai các máy chủ mô hình vLLM trên các lát TPU được phân bổ động:
./10_deploy_subslicing_pd_workload.sh
Chức năng:
- Triển khai
kueue-vllm-prefill-model-streamer(LWS yêu cầu một lát2x2x2TPU). - Triển khai
kueue-vllm-decode-model-streamer(LWS yêu cầu một lát2x2x2TPU). - Lát tiền xử lý tải trọng số mô hình Qwen 397B và đóng vai trò là
kv_producer. - Lát cắt giải mã đóng vai trò là
kv_consumer. - Chúng giao tiếp bằng cách sử dụng
TPUConnectorHMAđể chuyển bộ nhớ đệm KV.
Chờ cho đến khi cả hai nhóm tiền xử lý và giải mã đang chạy:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. Xác minh việc phân phát
Khi các tải công việc của bộ định tuyến, quá trình điền sẵn và giải mã đang chạy, giờ đây, bạn có thể xác minh API phân phát.
Chạy tập lệnh xác minh:
./11_verify_serving.sh
Cách hoạt động:
- Tập lệnh này truy xuất IP nội bộ của Cổng GKE.
- Thao tác này sẽ tạo một nhóm tạm thời (
curl-debug-comp) để gửi yêu cầu hoàn tất đếnhttp://${GATEWAY_IP}/v1/completions. - Thao tác này sẽ tạo một nhóm khác (
curl-debug-chat) để gửi yêu cầu trò chuyện đếnhttp://${GATEWAY_IP}/v1/chat/completions.
Bạn sẽ thấy một phản hồi JSON thành công từ mô hình Qwen:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. Dọn dẹp
Để tránh các khoản phí phát sinh cho tài khoản Google Cloud của bạn, hãy xoá các tài nguyên đã tạo trong lớp học lập trình này.
Chạy tập lệnh huỷ:
./12_teardown_cleanup.sh
Tập lệnh này làm những việc sau:
- Xoá nhóm nút GKE (
tpu7-pool-1,tpu7-pool-2). - Xoá Cụm GKE (
tpu-serving-cluster). - Xoá các chính sách tài nguyên (
superslice-policy). - Xoá mạng VPC (
qwen-serving-main).
Ngoài ra, nếu đã tạo một dự án riêng cho lớp học lập trình này, bạn có thể xoá toàn bộ dự án:
gcloud projects delete ${PROJECT_ID}
13. Xin chúc mừng
Xin chúc mừng! Bạn đã khám phá thành công tính năng Phân chia động của GKE và triển khai một cấu trúc Phân phát LLM tách biệt.
Kiến thức bạn học được
- Cách bật GKE Slice Controller và định cấu hình nhóm nút cho Incremental Provisioning (Cung cấp gia tăng).
- Cách sử dụng Kueue để yêu cầu các cấu trúc liên kết TPU cụ thể.
- Cách Phân chia phụ chia một khối TPU lớn thành các khối lượng công việc JAX nhỏ hơn, độc lập.
- Cách Super-slicing ghép nhiều nhóm nút thành một lát TPU ảo lớn hơn.
- Cách triển khai Phân phát tách biệt Prefill/Decode bằng LWS, Gateway API và vLLM.