
1. 簡介
在本程式碼研究室中,您將瞭解如何使用 GKE 動態切片,盡量充分運用 Cloud TPU 資源。動態切片是一項強大功能,可讓您將原始 TPU 佈建作業與工作負載排程作業分離。
具體來說,您將瞭解兩種主要模式:
- 子配量:將大型佈建的 TPU 區塊分割成較小的獨立配量,以處理較小的工作負載。
- 超級配量:將多個已佈建的 TPU 區塊縫合在一起,形成較大的虛擬配量,用於大規模工作負載。
您將套用這些模式,使用 Kueue、LeaderWorkerSet (LWS) 和 Gateway API,為大型語言模型 (Qwen 397B) 部署高效能的分離式服務 (預先填入/解碼分離) 架構。
架構
以下是 TPU 動態切片和分離式服務設定的高層級架構:
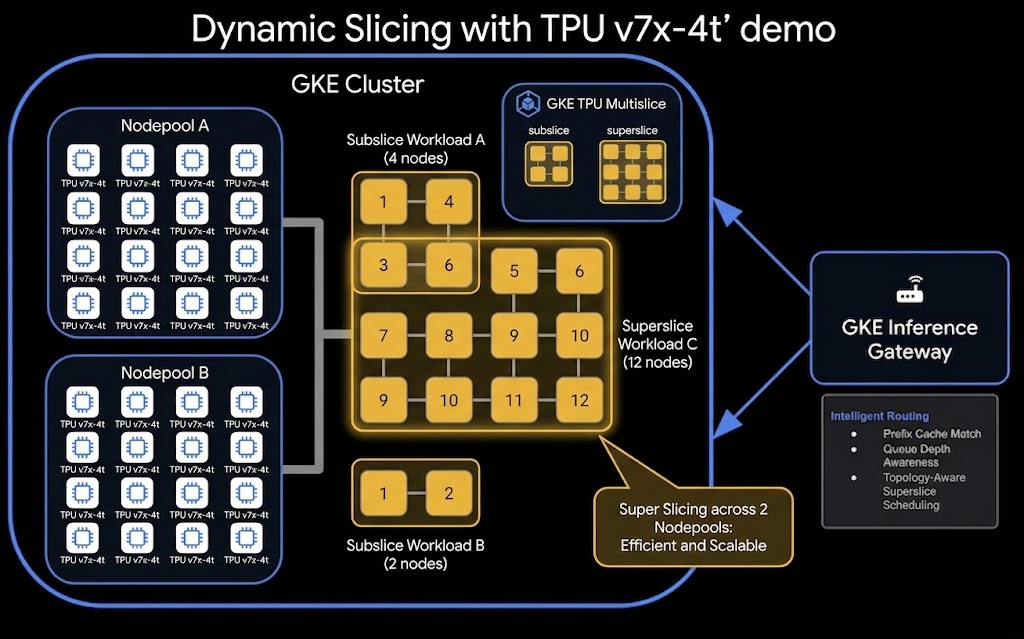
學習內容
- 佈建啟用 GKE Slice Controller 的 GKE 叢集。
- 建立設定為增量佈建的 GKE TPU 節點集區。
- 部署 Kueue 和 LeaderWorkerSet,管理 TPU 工作負載。
- 執行子切片工作負載,在較小的切片上驗證 JAX TPU 存取權。
- 執行超級配量工作負載,驗證多個合併節點集區的 JAX TPU 存取權。
- 部署「分散式提供程序」設定,讓「預先填充」和「解碼」階段在 LLM 路由器協調下,於動態分配的 TPU 節點上分別執行。
軟硬體需求
- 網路瀏覽器,例如 Chrome。
- 已啟用計費功能的 Google Cloud 專案。
- 重要事項:存取 Cloud TPU7x (Ironwood) All Capacity 模式預訂。
2. 事前準備
建立或選取 Google Cloud 專案
建立 Google Cloud 專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
啟動 Cloud Shell
Cloud Shell 是在 Google Cloud 中運作的指令列環境,已預先載入必要工具。
- 按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。
- 連至 Cloud Shell 後,請驗證您的驗證:
gcloud auth list - 確認專案已設定完成:
gcloud config get project - 如果專案未如預期設定,請設定專案:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
複製示範存放區
複製包含本程式碼研究室資訊清單和輔助指令碼的存放區:
git clone --depth 1 --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set ai-ml/dynamic-slicing
cd ai-ml/dynamic-slicing
3. 設定環境
佈建資源前,請先設定環境變數。我們提供輔助指令碼 01_setup_env.sh,可產生 env.sh 檔案。
執行設定指令碼:
./01_setup_env.sh
系統會提示您輸入多個值。按下 [ENTER] 鍵接受預設值,但請務必提供活動講師提供的正確預訂名稱和預訂區塊:
- GCP 專案 ID:目前的專案 ID。
- GCP 專案編號:您的專案編號。
- GKE 叢集名稱:
tpu-serving-cluster(預設)。 - TPU 節點集區區域:
us-central1-ai1a(預設)。 - Kubernetes 命名空間:
llm-d-pd-disaggregation(預設)。 - Cloud TPU 預訂名稱:[輸入提供的預訂名稱]
- Cloud TPU 預訂區塊名稱:
block-0(預設)。 - 權重的 GCS bucket 名稱:
model-weights(預設)。 - TPU 機器類型:
tpu7x-standard-4t(預設)。 - Hugging Face 權杖:[視需要輸入 HF 權杖,或在使用預先載入的權重時按下 ENTER 鍵]
執行指令碼後,將變數套用至目前的工作階段:
source env.sh
4. 啟用 API 和 AI 專區功能
環境設定完成後,請啟用必要的 Google Cloud API 和 AI 專區瀏覽權限功能。系統提供輔助指令碼 02_enable_apis_and_features.sh。
執行指令碼:
./02_enable_apis_and_features.sh
這個指令碼:
- 啟用 GKE、Compute、IAM、Resource Manager、Filestore 和 Network Services API。
- 啟用 GKE Dynamic Slicing 的
ai-zones-visibility預先發布功能。
5. 佈建 GKE 叢集和 TPU 節點集區
在這個步驟中,您將佈建底層網路基礎架構、GKE 叢集和 TPU 節點集區。
TPU 節點集區會使用增量佈建 (使用 --placement-policy=superslice-policy 和 --reservation-affinity=specific) 進行設定,將每個節點集區對應至原始 TPU 容量的 16 節點「立方體」(子區塊)。
執行佈建指令碼:
./03_create_cluster_and_nodes.sh
這段指令碼的作用:
- 建立虛擬私有雲網路和子網路:設定主要虛擬私有雲網路,並使用針對 TPU 流量最佳化的大型 MTU (8896)、TPU 子網路,以及 GKE Gateway 要求的僅限 Proxy 子網路。
- 建立 GKE 叢集:佈建已啟用 Slice Controller 的 Standard GKE 叢集 (
--enable-slice-controller)。 - 建立工作負載政策:定義名為 的資源政策,類型為 ,拓撲為 。
superslice-policyHIGH_THROUGHPUT4x4x4 - 建立 GKE TPU 節點集區:佈建兩個節點集區 (
tpu7-pool-1和tpu7-pool-2),每個集區都包含 16 個tpu7x-standard-4t節點。這代表兩個獨立的 16 節點立方體。
驗證節點
指令碼執行完畢後,請確認已佈建並註冊所有 32 個 TPU 節點:
kubectl get nodes -l google.com/tpu=present
清單中應會顯示 32 個節點。
6. 安裝自動化調度管理工具
動態切片功能會透過多個 Kubernetes 控制器協調工作和切片分配作業。您將安裝:
- JobSet:用於管理工作群組 (超級切片功能需要此項目)。
- Kueue:用於佇列、資源管理和拓撲感知排程 (TAS)。
- LeaderWorkerSet (LWS):用於管理複製的多節點 TPU 部署作業 (LLM 服務需要此項目)。
- GKE Slice Controller (使用者空間):將 Kueue 連線至 TPU Cluster Director,動態管理實體 Slice。
執行安裝指令碼:
./04_install_kueue_lws_slice_controller.sh
確認 Slice 控制器是否順利執行:
kubectl rollout status deployment/slice-controller-controller-manager -n slice-controller-system
7. 設定 Kueue 資源
現在,您需要定義代表 TPU 硬體拓撲的 Kueue 資源,並設定准入檢查。
執行部署指令碼:
./05_deploy_kueue_resources.sh
部署的重要資源:
- 拓撲 (
slice-topology):定義 Kueue 應在排程時考量的 TPU 分區階層式層級 (從區塊到主機名稱)。 - ResourceFlavor (
slice-rf):將slice-topology與tpu7x加速器建立關聯。 - AdmissionCheck (
ac):設定 Kueue 使用 GKE 配量控制器 (accelerator.gke.io/slice),在工作獲准時動態佈建配量。 - ClusterQueue (
cq) 和 LocalQueue (lq):設定要將工作負載提交至的佇列。 - WorkloadPriorityClass (
low-priority-1000、medium-priority-2000、high-priority-3000):定義優先順序層級,以啟用搶占和優先順序排程。
驗證資源:
kubectl get topology slice-topology
kubectl get resourceflavor slice-rf
kubectl get admissioncheck ac
kubectl get clusterqueue cq
kubectl get localqueue lq -n ${NAMESPACE}
8. 使用子切片部署及驗證 TPU 存取權
子配量可讓您在單一佈建的 TPU 區塊中執行多個較小的工作負載。在這個步驟中,您會將要求 2x2x2 拓撲 (8 個晶片 / 2 個 VM) 的工作負載提交至由 4x4x4 (64 個晶片 / 16 個 VM) 區塊組成的叢集。
部署子切片工作負載:
./06_deploy_simple_subslicing.sh
這個指令碼會套用 kueue-jobset-simple-subslicing.yaml。
運作方式:
- JobSet 規格包含
cloud.google.com/gke-tpu-slice-topology: 2x2x2註解。 - 這會設定
replicas: 6和parallelism: 2(完成:2)。也就是說,Kueue 會排定 6 項獨立工作,每項工作包含 2 個 Pod。 - 每個 Pod 都會要求
google.com/tpu: "4"(1 個 TPU VM)。 - Kueue 和 GKE Slice 控制器會動態分割 32 節點叢集,分配六個
2x2x2切片。
驗證 JAX 執行作業
監控 Pod,直到 Pod 執行為止:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing
檢查其中一個 pod 的記錄,確認 JAX 已成功偵測到子配量上的 8 個 TPU 裝置 (核心):
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-subslicing -o name | head -n 1) -n ${NAMESPACE}
輸出內容應會顯示:Total TPU devices (cores): 8
9. 使用 Superslicing 部署及驗證 TPU 存取權
超級配量是強大的 GKE 功能,可讓單一工作負載跨越多個實體 TPU 區塊 (通常稱為立方體或拓撲,例如 4x4x4)。將這些區塊縫合在一起,即可形成較大的虛擬配量,用於大規模訓練或服務工作負載。在這個步驟中,您將部署 JobSet,要求 4x4x8 拓撲 (128 個晶片 / 32 部 VM)。由於單一 4x4x4 區塊只包含 64 個晶片,這個工作負載會超出單一區塊的大小,因此需要 GKE 動態縫合 tpu7-pool-1 和 tpu7-pool-2 節點集區,以滿足要求。
部署超切片工作負載:
./07_deploy_simple_superslicing.sh
這個指令碼會套用 kueue-jobset-simple-superslicing.yaml。
運作方式:
- JobSet 範本包含註解
cloud.google.com/gke-tpu-slice-topology: 4x4x8。 - 設定
parallelism: 32和completions: 32。 - 每個 Pod 都會要求
google.com/tpu: "4"。 - 由於
4x4x8拓撲需要所有 32 個節點,Slice 控制器會動態設定 OCS (光學電路交換) 網路,將兩個 16 節點集區互連至單一 32 節點 ICI 網格。
確認 JobSet Pod 順利執行,且 JAX 偵測到所有 128 個裝置:
kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing
檢查其中一個 pod 的記錄:
kubectl logs $(kubectl get pods -n ${NAMESPACE} -l jobset.sigs.k8s.io/jobset-name=kueue-jobset-simple-superslicing -o name | head -n 1) -n ${NAMESPACE}
您應該會看到 JAX 輸出內容,顯示全域裝置數量:Global device count: 128
10. 部署分散式提供 (預先填入/解碼)
現在,您要使用預填/解碼分離功能,部署端對端 LLM 服務堆疊。
在標準服務中,預先填入 (處理提示) 和解碼 (產生權杖) 會在相同的 TPU 上執行。由於預先填入作業受運算限制,解碼作業受記憶體頻寬限制,因此兩者會發生衝突。分離式服務會在不同的 TPU 切片上執行這些模型,並透過網路傳輸 KV 快取。
設定 LLM-D 和閘道
設定命名空間、Hugging Face 密鑰和 GKE Gateway:
./08_setup_llm_d.sh
部署 LLM-D 路由器
部署路由器,接收用戶端要求並協調 Prefill 和 Decode 切片之間的路由:
./09_deploy_llm_d_router.sh
部署預填和解碼工作負載
在動態分配的 TPU 節點上部署 vLLM 模型伺服器:
./10_deploy_subslicing_pd_workload.sh
這段指令的作用:
- 部署
kueue-vllm-prefill-model-streamer(LWS 要求2x2x2TPU 配量)。 - 部署
kueue-vllm-decode-model-streamer(LWS 要求2x2x2TPU 配量)。 - 預填切片會載入 Qwen 397B 模型權重,並做為
kv_producer。 - 解碼切片會做為
kv_consumer。 - 這些節點會使用
TPUConnectorHMA傳輸 KV 快取。
等待預填和解碼 Pod 執行:
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=prefill
kubectl get pods -n ${NAMESPACE} -l llm-d.ai/role=decode
11. 驗證放送狀態
執行路由器、預先填入和解碼工作負載後,您現在可以驗證服務 API。
執行驗證指令碼:
./11_verify_serving.sh
運作方式:
- 指令碼會擷取 GKE Gateway 的內部 IP。
- 這會啟動臨時 Pod (
curl-debug-comp),將完成要求傳送至http://${GATEWAY_IP}/v1/completions。 - 系統會啟動另一個 Pod (
curl-debug-chat),將即時通訊要求傳送至http://${GATEWAY_IP}/v1/chat/completions。
您應該會看到 Qwen 模型傳回的 JSON 回應,顯示執行成功:
{
"choices": [
{
"text": "... [Model Response] ..."
}
]
}
12. 清理
如要避免系統持續向您的 Google Cloud 帳戶收取費用,請刪除本程式碼研究室建立的資源。
執行拆解指令碼:
./12_teardown_cleanup.sh
這段指令碼的作用:
- 刪除 GKE 節點集區 (
tpu7-pool-1、tpu7-pool-2)。 - 刪除 GKE 叢集 (
tpu-serving-cluster)。 - 刪除資源政策 (
superslice-policy)。 - 刪除虛擬私有雲網路 (
qwen-serving-main)。
或者,如果您為這個程式碼研究室建立了專屬專案,可以刪除整個專案:
gcloud projects delete ${PROJECT_ID}
13. 恭喜
恭喜!您已成功探索 GKE Dynamic Slicing,並部署分散式 LLM 服務架構。
目前所學內容
- 如何啟用 GKE Slice Controller,以及如何為增量佈建設定節點集區。
- 如何使用 Kueue 要求特定 TPU 拓撲。
- 瞭解如何透過子配量分割大型 TPU 區塊,以處理較小的獨立 JAX 工作負載。
- 超級配量如何將多個節點集區縫合為單一較大的虛擬 TPU 配量。
- 如何使用 LWS、Gateway API 和 vLLM 部署預填/解碼分離式服務。