
1. Einführung
Letzte Aktualisierung: 04.03.2026
Die Vektorsuche oder Vektordatenbank ist zu einer grundlegenden Technologie für moderne KI-Systeme geworden. Durch die Darstellung von Daten als hochdimensionale Einbettungen, die die semantische Bedeutung erfassen, wird alles von der semantischen Suche, die die Nutzerabsicht versteht, über Empfehlungsmaschinen, die relevante Inhalte präsentieren, bis hin zu Retrieval-Augmented Generation (RAG) und KI-Agents, die LLM-Antworten auf realen, aktuellen Informationen basieren, ermöglicht. Große Technologieunternehmen wie Google nutzen diese Technologie in großem Umfang, um täglich Milliarden von Suchanfragen, Empfehlungen und Fundierungen zu verarbeiten.
Die Entwicklung einer produktionsreifen Vektorsuche ist jedoch nach wie vor eine Herausforderung. Google hat vor Kurzem Vertex AI Vector Search 2.0 veröffentlicht, um das zu ändern. Dieser vollständig verwaltete Dienst wurde entwickelt, um die Design- und Betriebs-Komplexität zu beseitigen, die Teams verlangsamt.

Warum die Vektorsuche schwieriger ist, als sie aussieht
Das Konzept ist einfach. Die Implementierung? An dieser Stelle wird es kompliziert.
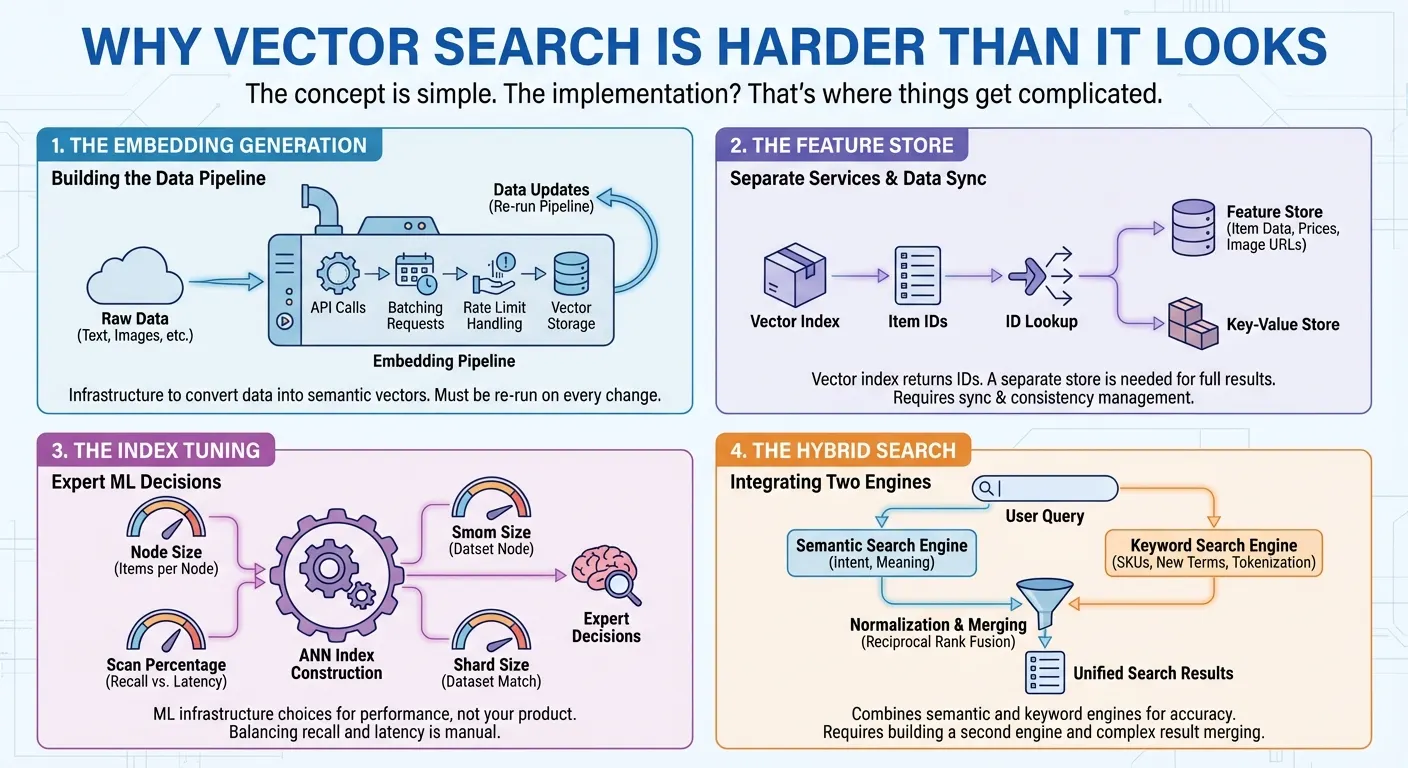
Die Generierung von Einbettungen. Für die Vektorsuche müssen Ihre Daten in numerische Darstellungen (Einbettungen) umgewandelt werden, die die semantische Bedeutung erfassen. Das bedeutet, dass Sie eine Embedding-API aufrufen, Ihre Anfragen in Batches verarbeiten, Ratenlimits berücksichtigen und die Vektoren speichern müssen. Jedes Mal, wenn sich Ihre Daten ändern, führen Sie die Pipeline noch einmal aus. Sie müssen die Infrastruktur aufbauen, bevor Sie überhaupt mit der Suche beginnen können.
Feature Store Viele Vektorsuchprodukte bieten nur einen Vektorindex, der für jede Suche eine Liste von Artikel-IDs zurückgibt. Damit Nutzern vollständige Suchergebnisse präsentiert werden können, benötigen Sie einen separaten Feature Store oder Key-Value-Store, um die tatsächlichen Artikeldaten (Namen, Preise, Kategorien, Bild-URLs in Millisekunden) abzurufen, indem Sie diese IDs übergeben. In vielen Fällen müssen Sie auch komplexe Filter für Artikelattribute wie Preis, Kategorie oder Verfügbarkeit implementieren. Das bedeutet, dass zwei verschiedene Dienste erstellt und gewartet werden müssen: einer für die Vektorsuche und einer für das Abrufen und Filtern von Daten. Für jedes Update und jede Anfrage muss auf beide Systeme zugegriffen und synchronisiert werden.
Die Indexabstimmung. Wenn Sie ANN-Indizes (Approximate Nearest Neighbor) mit Millionen von Elementen erstellen möchten, müssen Sie fundierte Entscheidungen treffen, um die beste Leistung zu erzielen: Wie viele Elemente sollten in jedem Indexknoten enthalten sein? Welcher Prozentsatz des Index sollte pro Abfrage gescannt werden, um ein Gleichgewicht zwischen Recall und Latenz zu schaffen? Welche Shard-Größe passt zu Ihrem Dataset? Das sind Entscheidungen zur ML-Infrastruktur, die nichts mit Ihrem eigentlichen Produkt zu tun haben.
Die Hybridsuche Die semantische Suche ist ideal, um die Absicht zu verstehen. So werden beispielsweise „Badeshorts“ gefunden, wenn Nutzer nach „Herrenoutfit für den Strand“ suchen. Bei Produktcodes wie „SKU-12345“, die keine semantische Bedeutung haben, schlägt die Funktion jedoch fehl. Auch bei neu geprägten Begriffen oder Markennamen, die dem Einbettungsmodell noch nicht bekannt sind, gibt es Probleme. Die Stichwortsuche kann diese Fälle abdecken, berücksichtigt aber keinen semantischen Kontext. Nutzer benötigen beides. Deshalb ist die Hybridsuche so wichtig geworden. Die Entwicklung ist jedoch alles andere als trivial. Sie benötigen zusätzlich zu Ihrer Vektorsuchmaschine eine Volltextsuchmaschine mit Tokenisierung, invertierten Indexen oder dünnbesetzten Einbettungen. Anschließend müssen Sie parallele Abfragen für beide Engines ausführen, die unterschiedlichen Bewertungssysteme normalisieren und die Ergebnisse mit Techniken wie Reciprocal Rank Fusion zusammenführen.
So löst Vector Search 2.0 diese Probleme
Vector Search 2.0 in Google Cloud bietet für jede dieser Herausforderungen eine Lösung:

In diesem Workshop erstellen wir eine vollständig verwaltete Hybridsuche mit 10.000 Modeprodukten aus dem TheLook-E-Commerce-Dataset.
Was ist die Vektorsuche 2.0?
Vector Search 2.0 ist die vollständig verwaltete, selbstoptimierende Vektordatenbank von Google Cloud, die auf dem ScaNN-Algorithmus (Scalable Nearest Neighbors) von Google basiert. Diese Technologie wird auch für die Google Suche, YouTube und Google Play verwendet.
Hauptunterschiede
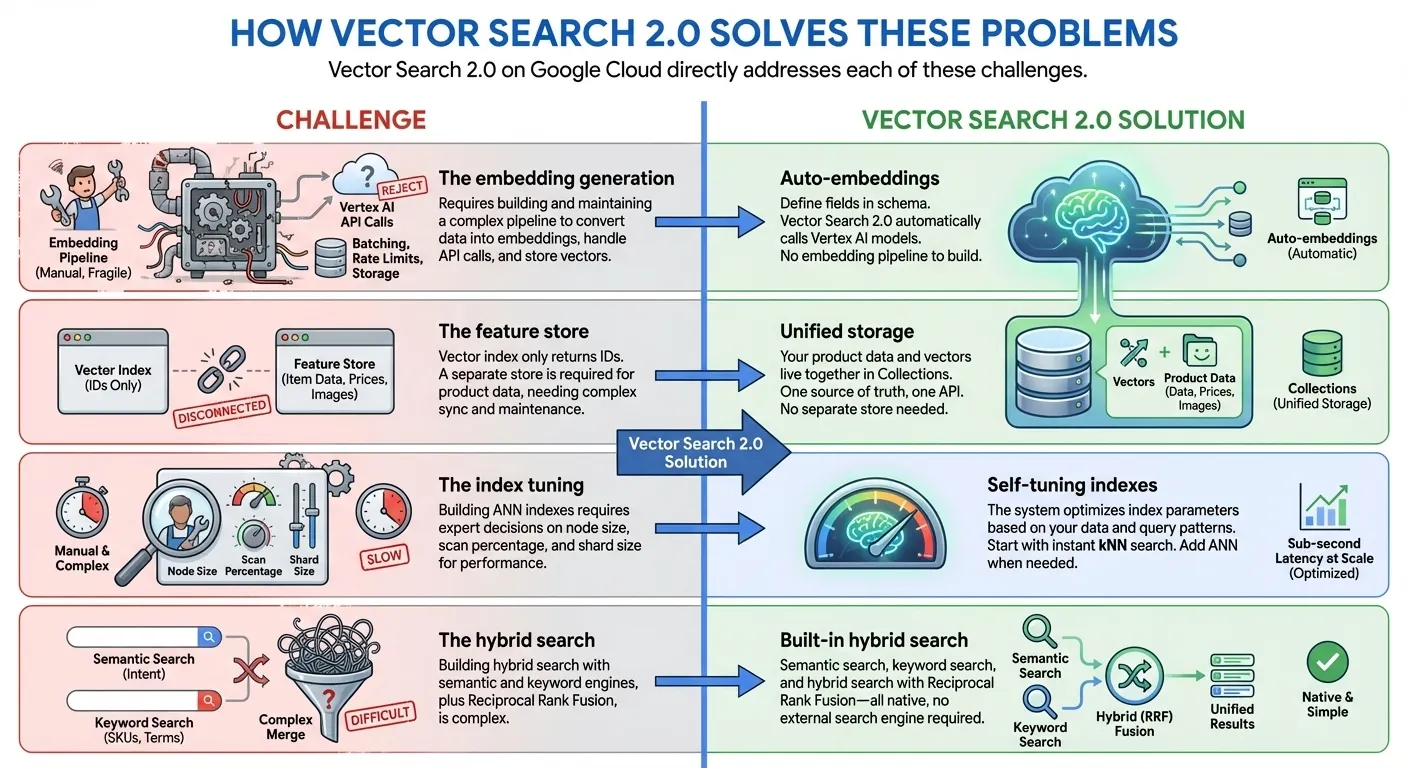
- Zero Indexing to Billion-Scale Index: Sie können sofort mit der Entwicklung beginnen, ohne dass eine Indexierung erforderlich ist. Verwenden Sie dazu kNN (k-Nearest Neighbors) und skalieren Sie dann mit Google-Scale-ANN-Indizes (Approximate Nearest Neighbor) für die Produktion auf Milliarden von Vektoren mit Millisekunden-Latenz – alles mit derselben API und demselben Dataset.
- Einheitlicher Datenspeicher: Sie können sowohl Vektoreinbettungen als auch von Nutzern bereitgestellte Daten zusammen speichern. Es ist keine separate Datenbank oder kein separater Feature Store erforderlich.
- Auto-Embeddings: Semantische Einbettungen automatisch mit Vertex AI-Einbettungsmodellen generieren
- Integrierte Volltextsuche: Bietet eine integrierte Volltextsuche, ohne dass Sie selbst dünnbesetzte Einbettungen generieren müssen. Sie können auch Ihre eigenen dünnbesetzten Einbettungen (z.B. BM25, SPLADE) mit der Vektorsuche für eine benutzerdefinierte Volltextsuche verwenden.
- Hybridsuche: Kombinieren Sie semantische und stichwort-/tokenbasierte Suche in einer einzigen Anfrage mit intelligentem RRF-Ranking.
- Automatische Optimierung: Automatisch optimierte Leistung ohne manuelle Konfiguration
- Für Unternehmen geeignet: Integrierte Skalierbarkeit, Sicherheit und Compliance
Kernarchitektur
Vector Search 2.0 besteht aus drei Hauptkomponenten:
- Sammlungen: Container mit Schema-Erzwingung für Ihre Daten
- Datenobjekte: Einzelne Elemente mit Daten und Vektoreinbettungen
- Indizes: Mit kNN können Sie sofort nach den nächsten Nachbarn in Ihren Daten suchen. Verwenden Sie für die Suche nach dem nächsten Nachbarn mit niedriger Latenz einen ANN-Index.
- Schnell starten: kNN kann sofort ohne Einrichtungszeit verwendet werden – ideal für die Entwicklung und kleine Datasets.
- Für die Produktion skalieren: Verwenden Sie ANN-Indizes für die Suche im Milliardenbereich mit Latenzen im Subsekundenbereich, die auf dem ScaNN-Algorithmus basieren.
Sehen wir uns die einzelnen Konzepte anhand von praktischen Beispielen an.
2. TheLook Fashion Search entwickeln
Stellen Sie sich vor, ein Kunde landet auf Ihrer E-Commerce-Website und gibt „etwas Süßes für einen Strandurlaub“ ein. Bei der herkömmlichen Suche mit Suchbegriffen erhalten sie keine Ergebnisse, da kein Produkt in Ihrem Katalog genau diese Wörter enthält. Frustriert gehen sie.
Stellen Sie sich nun eine andere Situation vor. Dieselbe Anfrage liefert Sommerkleider, Strandkleider und Shorts – Produkte, die genau dem entsprechen, was der Kunde gesucht hat, obwohl keines der Produkte das Wort „Strand“ im Titel enthält. Das ist die Erfahrung, die die Vektorsuche ermöglicht.
Um zu demonstrieren, wie Vector Search 2.0 dies ermöglicht, erstellen wir ein Produkt-Suchsystem mit TheLook,einem realistischen E-Commerce-Dataset mit 30.000 Modeartikeln in 26 Kategorien. Jedes Produkt hat Attribute, die Sie in jedem echten Katalog finden:

Die Herausforderungen bei der Suche, die wir lösen werden
Echte Kunden suchen nicht so, wie Datenbanken es erwarten. Sie suchen so, wie sie denken:

Vector Search 2.0 löst alle vier Herausforderungen mit einer einheitlichen Architektur.
Datenarchitektur für die Vektorsuche 2.0
Bevor wir uns mit dem Code befassen, sehen wir uns an, wie Ihre Daten in Vector Search 2.0 organisiert werden. Die Architektur basiert auf drei Schlüsselkonzepten: Sammlungen, Datenobjekte und Indexe.
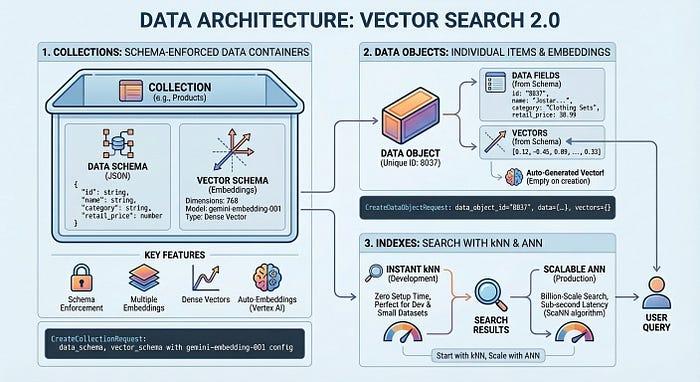
In einer Sammlung wird Ihre Datenstruktur definiert – die Felder, die Sie speichern möchten, und die Felder, die eingebettet werden sollen. Datenobjekte sind die tatsächlichen Elemente (Produkte, Dokumente, Bilder), die in einer Sammlung gespeichert sind. Jedes hat seine eigenen Daten und automatisch generierte oder Ihre eigenen Vektoren. Ein Index optimiert Abfragen im großen Maßstab und ermöglicht eine Latenz von Millisekunden bei Milliarden von Elementen. Sie können ohne Index mit der Entwicklung beginnen und dann einen hinzufügen, wenn Sie Produktionsleistung benötigen.
TheLook Search erstellen: Schritt für Schritt
Jetzt erstellen wir ein funktionierendes System für die Produktsuche. Wir laden 10.000 Modeartikel von TheLook, aktivieren automatische Einbettungen und führen semantische, Keyword- und hybride Suchanfragen aus – alles in etwa 50 Codezeilen.
Notebook öffnen: Einführung in die Vektorsuche 2.0 in Vertex AI
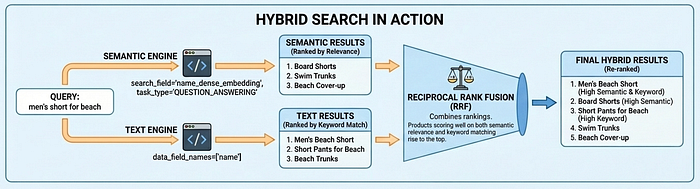
Hybridsuche in der Praxis
Die Vektorsuche 2.0 unterstützt drei Suchmodi: semantische Suche (Intention wird über Einbettungen verstanden), Textsuche (Abgleich von Suchbegriffen) und Hybridsuche (Kombination beider). Die Hybridsuche liefert für die meisten Anwendungsfälle die besten Ergebnisse. Bei der semantischen Suche werden „Badeshorts“ gefunden, wenn Nutzer nach „Herrenoutfit für den Strand“ suchen. Bei der Textsuche werden hingegen genaue Übereinstimmungen wie Produktcodes nicht übersehen.
Warum sind Einbettungen für Aufgabentypen wichtig?
Beachten Sie die Parameter „task_type“ im obigen Code: RETRIEVAL_DOCUMENT beim Indexieren von Produkten und QUESTION_ANSWERING bei der Suche. Das ist nicht willkürlich, sondern eine wichtige Technik zur Verbesserung der Suchqualität, da das Einbettungsmodell wie ein Empfehlungsmodell funktioniert.
Die meisten Anwendungsfälle für die Vektorsuche basieren auf einem einfachen Ähnlichkeitsabgleich. Damit lässt sich jedoch oft keine Suchqualität auf Produktionsniveau erzielen, da Fragen und Antworten im Einbettungsraum nicht von Natur aus ähnlich sind. „Was ist gut für einen Strandurlaub?“ und „Badeshorts“ haben unterschiedliche Semantik, sollten aber übereinstimmen. Einbettungen für Aufgabentypen lösen dieses Problem, indem sie das Einbettungsmodell für asymmetrische Beziehungen optimieren: Dokumente werden anders eingebettet als Anfragen. So entsteht ein Einbettungsbereich, in dem relevante Übereinstimmungen gruppiert werden. Dadurch wird die Möglichkeit der Empfehlung hinzugefügt, relevante Elemente basierend auf der Nutzerabsicht zu finden.
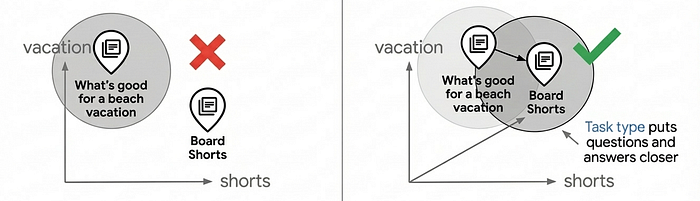
Mit aufgabenspezifischen Einbettungen lässt sich die Suchqualität im Vergleich zu generischen Einbettungen um 30–40% verbessern. Eine ausführliche Beschreibung der Funktionsweise finden Sie im Notebook für Einbettungen für Aufgabentypen.
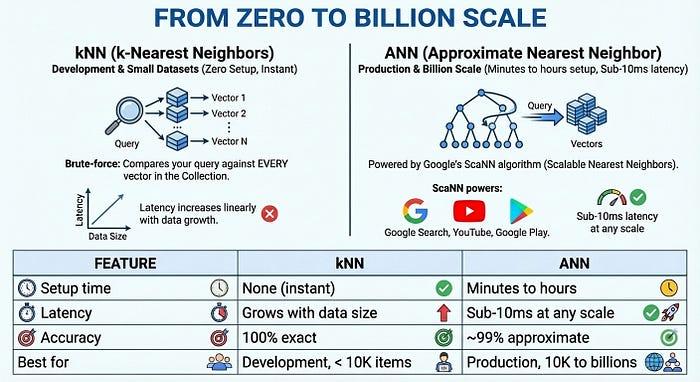
Von null auf Milliarden skalieren
Für die Produktion im großen Maßstab bietet die Vektorsuche 2.0 ANN-Indizes (Approximate Nearest Neighbor), die auf dem ScaNN-Algorithmus (Scalable Nearest Neighbors) von Google basieren – derselben Technologie, die auch für die Google Suche, YouTube und Google Play verwendet wird. ANN tauscht eine geringe Menge an Genauigkeit (~99%) gegen massive Geschwindigkeitssteigerungen ein: Latenz von unter 10 ms, selbst bei Milliarden von Vektoren.
Das Gesamtbild
In nur fünf Schritten, wobei die Schritte 1 bis 4 nur etwa fünf Minuten dauern, haben wir ein produktionsreifes Produkt-Suchsystem erstellt:
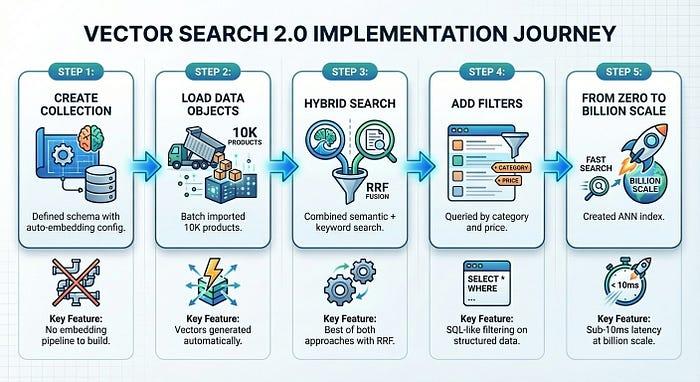
Mit Vector Search 2.0 wird die Infrastrukturkomplexität beseitigt, die die Einführung der Vektorsuche normalerweise verlangsamt. Sie konzentrieren sich auf Ihr Produkt. Die Plattform übernimmt das Einbetten, Indexieren und Skalieren.
3. Glückwunsch
Sie haben Ihre erste Anwendung mit Vector Search 2.0 erfolgreich erstellt.