
1. Introducción
Última actualización: 2026-03-04
La búsqueda vectorial, o base de datos de vectores, se convirtió en una tecnología fundamental para los sistemas de IA modernos. Al representar los datos como embeddings de alta dimensión que capturan el significado semántico, potencia todo, desde la búsqueda semántica que comprende la intención del usuario hasta los motores de recomendación que muestran contenido pertinente, la generación mejorada por recuperación (RAG) y los agentes de IA que fundamentan las respuestas de los LLM en información real y actualizada. Las principales empresas de tecnología, como Google, dependen de esta tecnología a gran escala para procesar miles de millones de búsquedas, recomendaciones y fundamentaciones a diario.
Sin embargo, crear una búsqueda de vectores lista para producción sigue siendo un desafío. Recientemente, Google lanzó Vertex AI Vector Search 2.0 para cambiar eso, un servicio completamente administrado diseñado para eliminar la complejidad operativa y de diseño que ralentiza a los equipos.

Why Vector Search Is Harder Than It Looks (Por qué la búsqueda de vectores es más difícil de lo que parece)
El concepto es simple. ¿La implementación? Ahí es donde las cosas se complican.
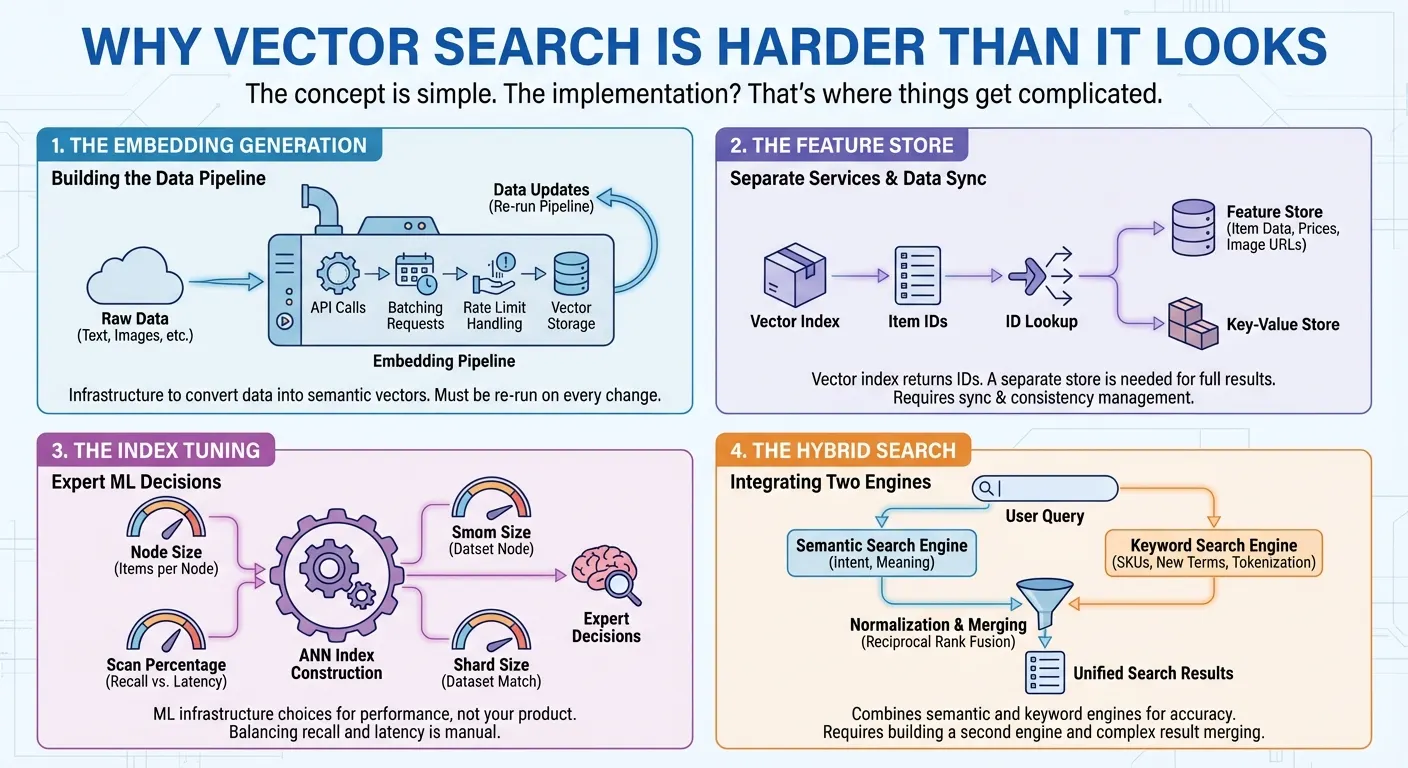
Es la generación de embeddings. La búsqueda de vectores requiere que conviertas tus datos en representaciones numéricas (embeddings) que capturen el significado semántico. Esto significa que debes llamar a una API de embeddings, procesar tus solicitudes por lotes, controlar los límites de frecuencia y almacenar los vectores. Cada vez que cambian tus datos, vuelves a ejecutar la canalización. Es la infraestructura que debes construir antes de poder comenzar a buscar.
El almacén de atributos. Muchos productos de búsqueda de vectores solo proporcionan un índice de vectores que devuelve una lista de IDs de elementos para cada búsqueda. Para mostrar resultados de búsqueda completos a los usuarios, necesitas un almacén de atributos o un almacén de clave-valor independientes para recuperar los datos reales de los elementos (nombres, precios, categorías, URLs de imágenes en milisegundos) pasando esos IDs. En muchos casos, también debes implementar un filtrado complejo en las características de los elementos, como el precio, la categoría o la disponibilidad. Esto significa crear y mantener dos servicios diferentes: uno para la búsqueda vectorial y otro para la recuperación y el filtrado de datos. Cada actualización y consulta requiere acceder a ambos sistemas y sincronizarlos.
Es el ajuste del índice. Para crear índices de vecino más cercano aproximado (ANN) con millones de elementos, debes tomar decisiones expertas para obtener el mejor rendimiento: ¿Cuántos elementos debe contener cada nodo del índice? ¿Qué porcentaje del índice se debe analizar por búsqueda para equilibrar la recuperación y la latencia? ¿Qué tamaño de fragmento coincide con tu conjunto de datos? Estas son decisiones de infraestructura de AA que no tienen nada que ver con tu producto real.
La búsqueda híbrida. La búsqueda semántica se destaca por comprender la intención, ya que encuentra "Bermudas" cuando los usuarios buscan "ropa de hombre para la playa". Sin embargo, falla en códigos de producto como "SKU-12345" que no tienen significado semántico y tiene dificultades con términos recién acuñados o nombres de marcas que el modelo de embedding nunca ha visto. La búsqueda por palabra clave maneja estos casos, pero no tiene en cuenta el contexto semántico. Los usuarios necesitan ambas, por lo que la búsqueda híbrida se ha vuelto esencial. Sin embargo, su creación no es trivial. Necesitas un motor de búsqueda de texto completo con tokenización, índices invertidos o embeddings dispersas, además de tu motor de búsqueda de vectores. Luego, debes ejecutar consultas paralelas en ambos motores, normalizar sus diferentes sistemas de puntuación y combinar los resultados con técnicas como la fusión de clasificación recíproca.
Cómo Vector Search 2.0 resuelve estos problemas
La versión 2.0 de la Búsqueda de vectores en Google Cloud aborda directamente cada uno de estos desafíos:

En este taller, crearemos una búsqueda híbrida completamente administrada con 10,000 productos de moda del conjunto de datos de comercio electrónico TheLook.
¿Qué es Vector Search 2.0?
Vector Search 2.0 es la base de datos de vectores autoadaptable y completamente administrada de Google Cloud, creada con el algoritmo ScaNN (Scalable Nearest Neighbors) de Google, la misma tecnología que impulsa la Búsqueda de Google, YouTube y Google Play.
Factores de diferenciación clave
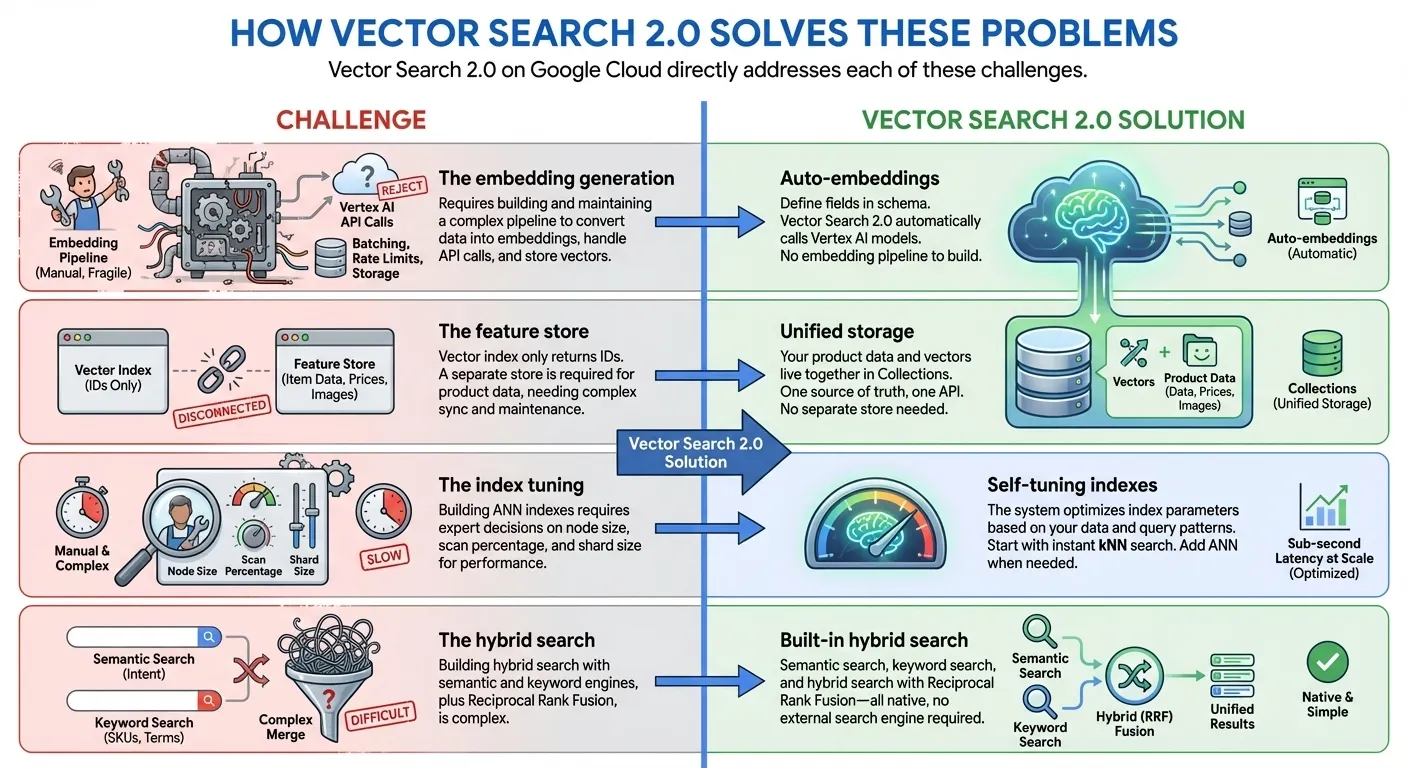
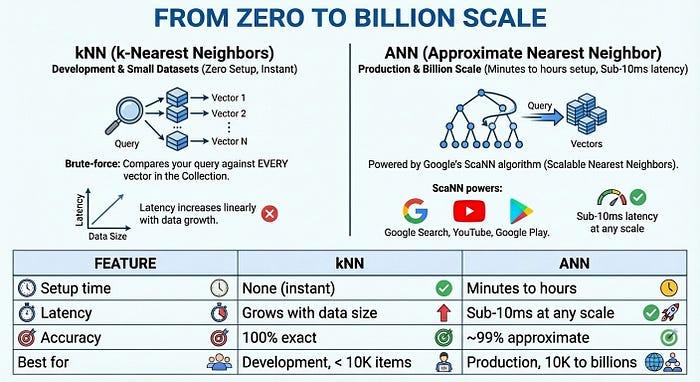
- Indexación desde cero hasta miles de millones de índices: Comienza a desarrollar de inmediato sin tiempo de indexación con kNN (k-vecinos más cercanos) y, luego, escala a miles de millones de vectores con latencia de milisegundos con índices de ANN (vecino más cercano aproximado) a escala de Google para la producción, todo con la misma API y el mismo conjunto de datos.
- Almacenamiento de datos unificado: Almacena juntos los embeddings de vectores y los datos proporcionados por el usuario (no se necesita una base de datos ni un almacén de funciones independientes).
- Incorporaciones automáticas: Genera automáticamente incorporaciones semánticas con modelos de incorporación de Vertex AI
- Búsqueda de texto completo integrada: Proporciona una búsqueda de texto completo integrada sin necesidad de generar embeddings dispersos por tu cuenta. También puedes usar tus propios embeddings dispersos (p.ej., BM25, SPLADE) con la Búsqueda vectorial para realizar una búsqueda en el texto completo personalizada.
- Búsqueda híbrida: Combina la búsqueda semántica y la búsqueda basada en palabras clave o tokens en una sola consulta con una clasificación RRR inteligente.
- Self-Tuning: Rendimiento optimizado automáticamente sin configuración manual
- Preparado para empresas: Escalabilidad, seguridad y cumplimiento integrados
Arquitectura principal
La Búsqueda vectorial 2.0 tiene tres componentes principales:
- Colecciones: Contenedores con esquema aplicado para tus datos
- Objetos de datos: Son elementos individuales con datos y embeddings de vectores.
- Índices: Realiza búsquedas instantáneas de vecinos más cercanos en tus datos con kNN. Para la búsqueda de vecinos más cercanos con baja latencia, usa un índice de ANN.
- Comienza rápido: Usa kNN de inmediato sin tiempo de configuración, ideal para el desarrollo y los conjuntos de datos pequeños
- Escala a producción: Usa índices de ANN para realizar búsquedas a gran escala con latencia inferior a un segundo gracias al algoritmo ScaNN.
Exploremos cada concepto con ejemplos prácticos.
2. Cómo crear la Búsqueda de moda de TheLook
Imagina que un cliente llega a tu sitio de comercio electrónico y escribe "algo lindo para unas vacaciones en la playa". Con la búsqueda tradicional por palabras clave, no obtienen ningún resultado, ya que ningún producto de tu catálogo contiene esas palabras exactas. Frustrados, se van.
Ahora imagina una experiencia diferente. La misma búsqueda devuelve vestidos de verano, prendas para cubrirse después de nadar y shorts holgados, productos que coinciden perfectamente con lo que el cliente tenía en mente, aunque ninguno contenga la palabra "playa" en sus títulos. Esa es la experiencia que permite la búsqueda de vectores.
Para demostrar cómo Vector Search 2.0 hace esto posible, crearemos un sistema de búsqueda de productos con TheLook, un conjunto de datos de comercio electrónico realista con 30,000 artículos de moda en 26 categorías. Cada producto tiene atributos que encontrarías en cualquier catálogo real:

Los desafíos de la Búsqueda que resolveremos
Los clientes reales no realizan búsquedas de la forma en que lo esperan las bases de datos. Buscan de la misma manera en que piensan:

La Búsqueda de vectores 2.0 resuelve los cuatro desafíos con una arquitectura unificada.
Arquitectura de datos de Vector Search 2.0
Antes de profundizar en el código, comprendamos cómo organiza tus datos la Búsqueda de vectores 2.0. La arquitectura se centra en tres conceptos clave: colecciones, objetos de datos e índices.
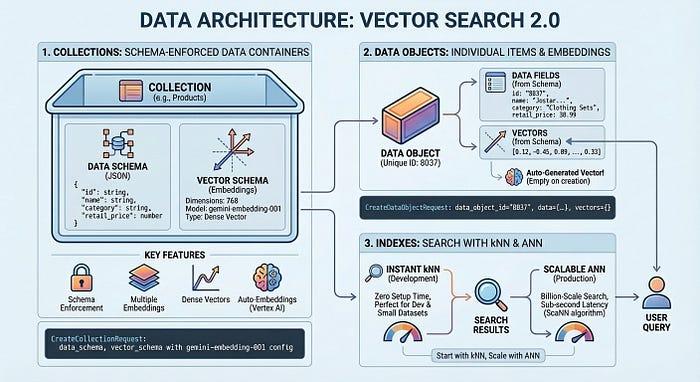
Una colección define la estructura de tus datos, es decir, los campos que deseas almacenar y los que deben incorporarse. Los objetos de datos son los elementos reales (productos, documentos, imágenes) almacenados en una colección, cada uno con sus datos y vectores generados automáticamente o tus propios vectores. Un índice optimiza las consultas a gran escala, lo que permite una latencia de milisegundos en miles de millones de elementos. Puedes comenzar sin un índice para el desarrollo sin tiempo de configuración y, luego, agregar uno cuando necesites rendimiento de producción.
Cómo compilar la búsqueda de TheLook: paso a paso
Ahora, creemos un sistema de búsqueda de productos que funcione. Cargaremos 10,000 artículos de moda de TheLook, habilitaremos las incorporaciones automáticas y ejecutaremos búsquedas semánticas, de palabras clave e híbridas, todo en aproximadamente 50 líneas de código.
Notebook abierto: Introducción a Vertex AI Vector Search 2.0
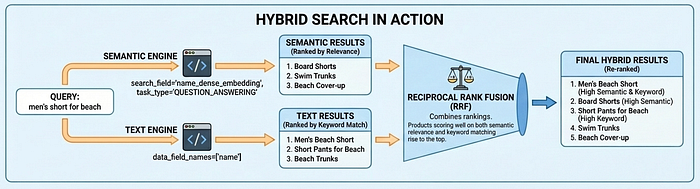
Búsqueda híbrida en acción
La versión 2.0 de Vector Search admite tres modos de búsqueda: búsqueda semántica (comprende la intención a través de embeddings), búsqueda de texto (concordancia de palabras clave) y búsqueda híbrida (combina ambos). La búsqueda híbrida ofrece los mejores resultados para la mayoría de los casos de uso: la búsqueda semántica encuentra "pantalones cortos de playa" cuando los usuarios buscan "ropa de hombre para la playa", mientras que la búsqueda de texto garantiza que no se pierdan coincidencias exactas, como los códigos de productos.
Por qué son importantes los embeddings de tipo de tarea
Observa los parámetros task_type en el código anterior: RETRIEVAL_DOCUMENT cuando se indexan productos y QUESTION_ANSWERING cuando se realiza una búsqueda. Esto no es arbitrario, sino que es una técnica clave para mejorar la calidad de la búsqueda, ya que permite que el modelo de embedding funcione como un modelo de recomendación.
La mayoría de los casos de uso de la búsqueda de vectores se basan en la coincidencia de similitud simple, pero, a menudo, no logran proporcionar una calidad de búsqueda a nivel de producción porque las preguntas y las respuestas no son inherentemente similares en el espacio de incorporación. "¿Qué es bueno para unas vacaciones en la playa?" y "Bermudas" tienen semánticas diferentes, pero deberían coincidir. Los embeddings de tipo de tarea resuelven este problema optimizando el modelo de embedding para las relaciones asimétricas: los documentos se incorporan de manera diferente a las búsquedas, lo que crea un espacio de embedding en el que las coincidencias pertinentes se agrupan, lo que agrega la capacidad de recomendación, es decir, encontrar elementos pertinentes según la intención del usuario.

El uso de embeddings específicos para la tarea puede mejorar la calidad de la búsqueda entre un 30% y un 40% en comparación con los embeddings genéricos. Para obtener información detallada sobre cómo funciona, consulta el notebook de Task Type Embedding.
De cero a miles de millones de usuarios
Para la producción a gran escala, la Búsqueda de Vectores 2.0 ofrece índices de ANN (vecino más cercano aproximado) potenciados por el algoritmo ScaNN (vecinos más cercanos escalables) de Google, la misma tecnología que impulsa la Búsqueda de Google, YouTube y Google Play. El ANN intercambia una pequeña cantidad de exactitud (~99%) por grandes ganancias de velocidad: latencia inferior a 10 ms incluso con miles de millones de vectores.
The Complete Picture
En solo cinco pasos (los pasos del 1 al 4 tardan solo unos 5 minutos), creamos un sistema de búsqueda de productos listo para la producción:
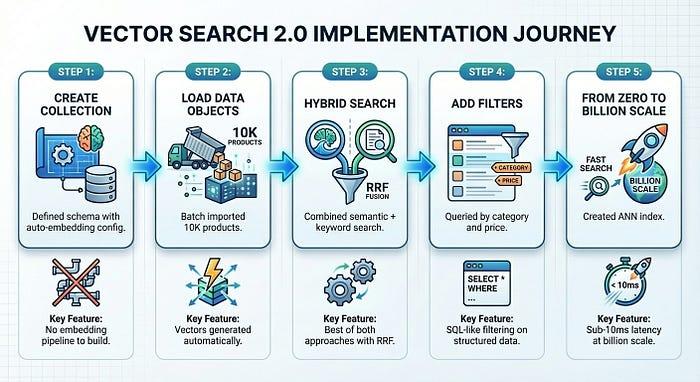
Vector Search 2.0 elimina la complejidad de la infraestructura que suele ralentizar la adopción de la búsqueda de vectores. Te enfocas en tu producto, y la plataforma se encarga de las incorporaciones, la indexación y el escalamiento.
3. Felicitaciones
¡Felicitaciones! Compilaste con éxito tu primera aplicación con la versión 2.0 de Vector Search.