
1. Introduction
Dernière mise à jour : 04/03/2026
La recherche vectorielle, ou base de données vectorielle, est devenue une technologie fondamentale pour les systèmes d'IA modernes. En représentant les données sous forme d'embeddings de grande dimension qui capturent la signification sémantique, elle alimente tout, de la recherche sémantique qui comprend l'intention de l'utilisateur aux moteurs de recommandation qui font apparaître du contenu pertinent, en passant par la génération augmentée par récupération (RAG) et les agents d'IA qui ancrent les réponses LLM dans des informations réelles et à jour. Les principales entreprises technologiques, y compris Google, s'appuient sur cette technologie à grande échelle pour traiter des milliards de recherches, de recommandations et d'ancrages chaque jour.
Toutefois, la création d'une recherche vectorielle prête pour la production reste difficile. Google a récemment lancé Vertex AI Vector Search 2.0 pour y remédier. Il s'agit d'un service entièrement géré conçu pour éliminer la complexité de conception et opérationnelle qui ralentit les équipes.

Pourquoi la recherche vectorielle est plus complexe qu'il n'y paraît
Le concept est simple. L'implémentation ? C'est là que les choses se compliquent.
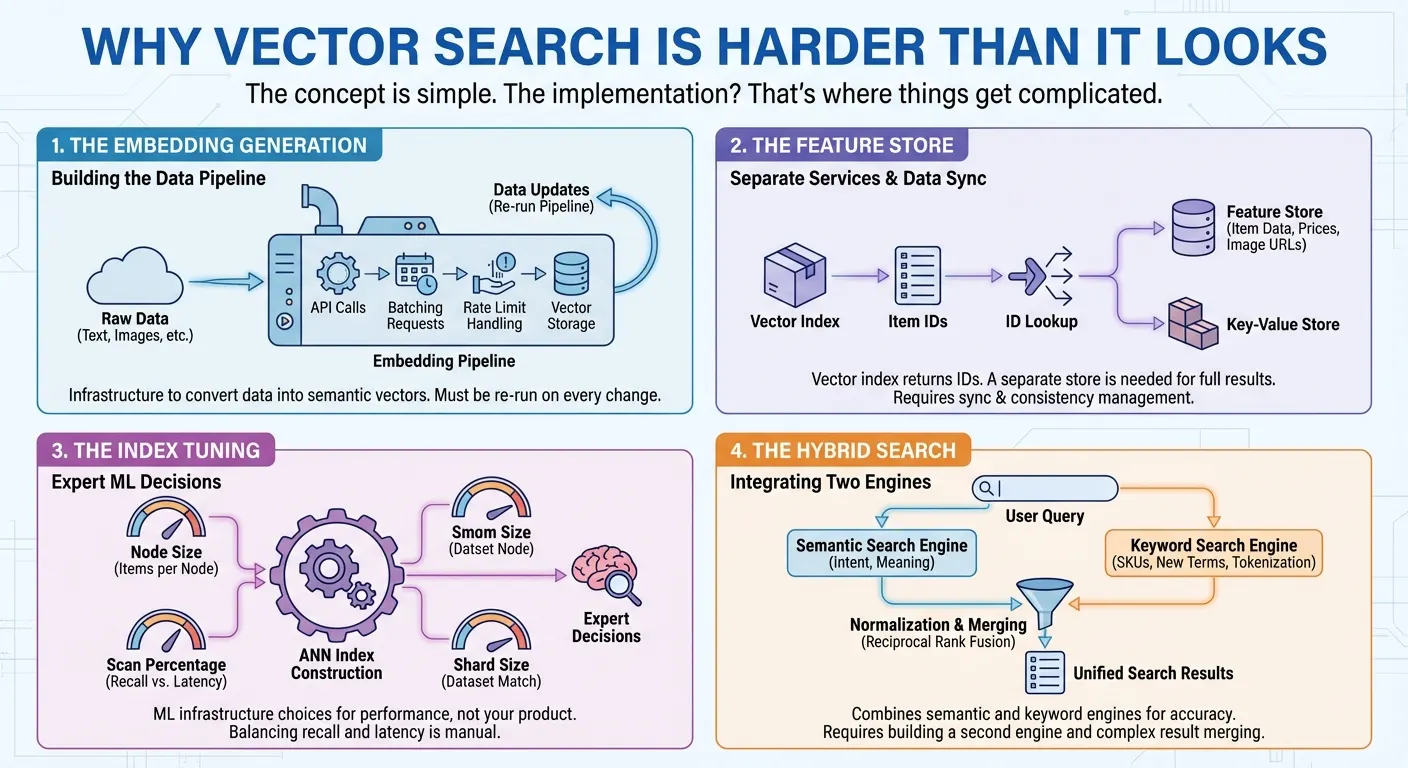
Génération d'embeddings. La recherche vectorielle nécessite de convertir vos données en représentations numériques (embeddings) qui capturent la signification sémantique. Cela signifie que vous devez appeler une API d'embedding, regrouper vos requêtes par lots, gérer les limites de débit et stocker les vecteurs. Chaque fois que vos données changent, vous réexécutez le pipeline. Il s'agit d'une infrastructure que vous devez créer avant même de pouvoir commencer à effectuer des recherches.
Le magasin de caractéristiques De nombreux produits de recherche vectorielle ne fournissent qu'un index vectoriel qui renvoie une liste d'ID d'éléments pour chaque recherche. Pour afficher des résultats de recherche complets aux utilisateurs, vous avez besoin d'un feature store ou d'un key-value store distinct pour récupérer les données réelles des articles (noms, prix, catégories, URL des images en millisecondes) en transmettant ces ID. Dans de nombreux cas, vous devez également implémenter un filtrage complexe sur les caractéristiques des articles, telles que le prix, la catégorie ou la disponibilité. Cela signifie que vous devez créer et gérer deux services différents : un pour la recherche vectorielle et un pour la récupération et le filtrage des données. Chaque mise à jour et requête nécessite d'accéder aux deux systèmes et de les synchroniser.
Réglage de l'index. Pour créer des index de plus proches voisins approximatifs (ANN) avec des millions d'éléments, vous devez prendre des décisions d'expert pour obtenir les meilleures performances : combien d'éléments chaque nœud d'index doit-il contenir ? Quel pourcentage de l'index doit être analysé par requête pour équilibrer le rappel et la latence ? Quelle taille de segment correspond à votre ensemble de données ? Il s'agit de décisions concernant l'infrastructure de ML qui n'ont rien à voir avec votre produit.
La recherche hybride La recherche sémantique excelle dans la compréhension de l'intention : elle trouve"short de bain " lorsque les utilisateurs recherchent "tenue homme pour la plage". En revanche, il échoue avec les codes produit comme "SKU-12345" qui n'ont aucune signification sémantique, et a du mal avec les termes ou noms de marque nouvellement inventés que le modèle d'embedding n'a jamais vus. La recherche par mot clé gère ces cas, mais ne tient pas compte du contexte sémantique. Les utilisateurs ont besoin des deux, c'est pourquoi la recherche hybride est devenue essentielle. Cependant, sa création est loin d'être triviale. Vous avez besoin d'un moteur de recherche en texte intégral avec tokenisation, index inversés ou embeddings creux, en plus de votre moteur de recherche vectoriel. Vous devez ensuite exécuter des requêtes parallèles sur les deux moteurs, normaliser leurs différents systèmes de notation et fusionner les résultats à l'aide de techniques telles que la fusion de classement réciproque.
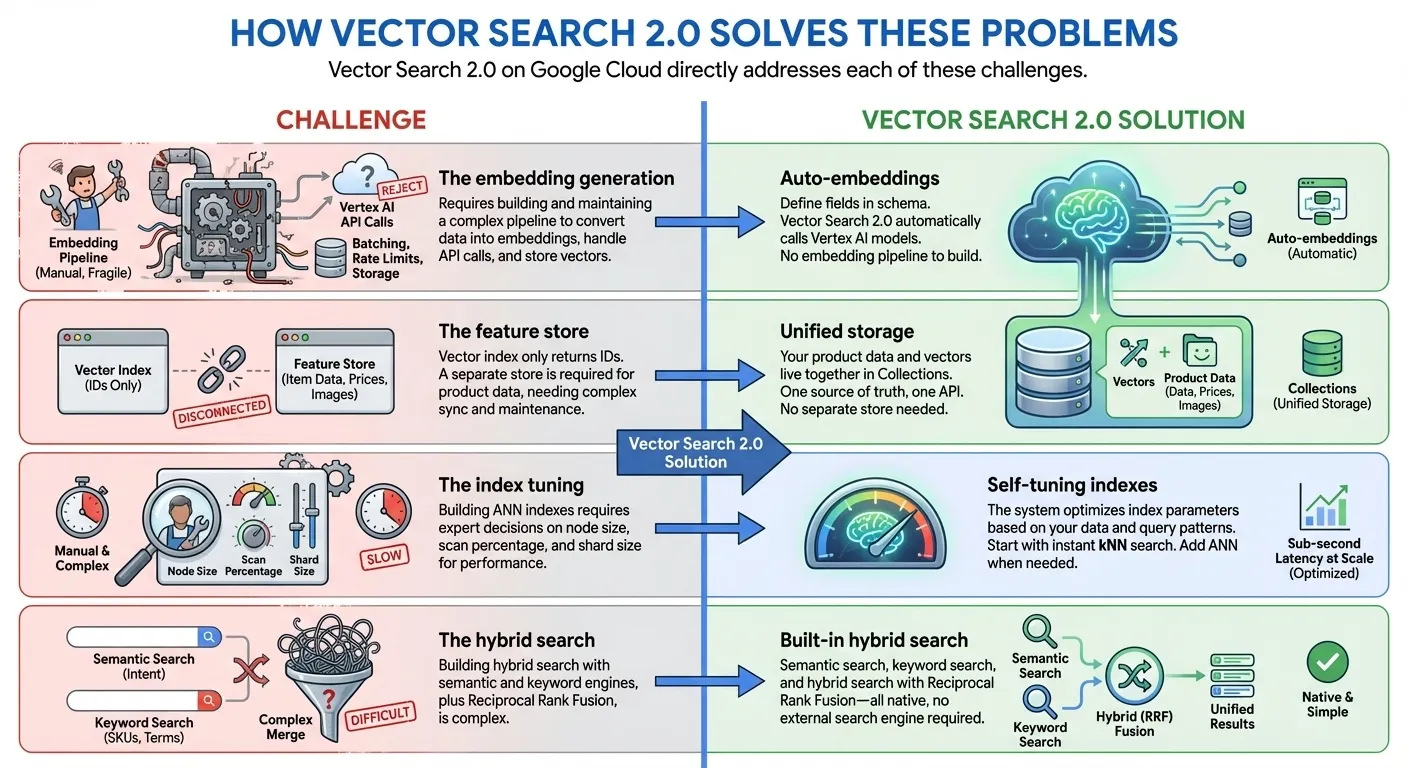
Comment Vector Search 2.0 résout ces problèmes
Vector Search 2.0 sur Google Cloud répond directement à chacun de ces défis :

Dans cet atelier, nous allons créer une recherche hybride entièrement gérée à l'aide de 10 000 produits de mode issus de l'ensemble de données d'e-commerce TheLook.
Qu'est-ce que Vector Search 2.0 ?
Vector Search 2.0 est une base de données vectorielle entièrement gérée et auto-réglable de Google Cloud, basée sur l'algorithme ScaNN (Scalable Nearest Neighbors) de Google, la même technologie que celle utilisée par la recherche Google, YouTube et Google Play.
Facteurs clés de différenciation
- Indexation nulle à l'indexation à l'échelle du milliard : commencez à développer immédiatement sans temps d'indexation à l'aide de kNN (k-plus proches voisins), puis passez à des milliards de vecteurs avec une latence en millisecondes grâce aux index ANN (plus proches voisins approximatifs) à l'échelle de Google pour la production. Le tout avec la même API et le même ensemble de données.
- Stockage de données unifié : stockez ensemble les embeddings vectoriels et les données fournies par les utilisateurs (aucune base de données ni aucun feature store distincts ne sont nécessaires).
- Auto-Embeddings : générez automatiquement des embeddings sémantiques à l'aide des modèles d'embedding Vertex AI.
- Recherche en texte intégral intégrée : fournit une recherche en texte intégral intégrée sans avoir à générer vous-même des embeddings creux. Vous pouvez également choisir d'utiliser vos propres embeddings creux (par exemple, BM25 ou SPLADE) avec Vector Search pour une recherche en texte intégral personnalisée.
- Recherche hybride : combinez la recherche sémantique et la recherche par mot clé/jeton dans une seule requête avec un classement RRF intelligent.
- Réglage automatique : performances optimisées automatiquement sans configuration manuelle
- Adapté aux entreprises : évolutivité, sécurité et conformité intégrées
Architecture de base
La recherche vectorielle 2.0 comporte trois composants principaux :
- Collections : conteneurs pour vos données avec application du schéma
- Objets de données : éléments individuels avec des données et des embeddings vectoriels
- Index : effectuez une recherche instantanée des voisins les plus proches dans vos données avec kNN. Pour une recherche des voisins les plus proches à faible latence, utilisez un index ANN.
- Démarrage rapide : utilisez k-NN immédiatement, sans aucun temps de configuration. C'est idéal pour le développement et les petits ensembles de données.
- Mise à l'échelle pour la production : utilisez des index ANN pour la recherche à l'échelle du milliard avec une latence inférieure à la seconde grâce à l'algorithme ScaNN.
Explorons chaque concept avec des exemples pratiques.
2. Créer la recherche de mode TheLook
Imaginez qu'un client arrive sur votre site d'e-commerce et saisit "quelque chose de mignon pour des vacances à la plage". Avec la recherche traditionnelle par mots clés, ils n'obtiennent aucun résultat, car aucun produit de votre catalogue ne contient ces mots exacts. Frustrés, ils s'en vont.
Imaginez maintenant une autre expérience. La même requête renvoie des robes d'été, des maillots de bain et des shorts amples, soit des produits qui correspondent parfaitement à ce que le client avait en tête, même si aucun d'eux ne contient le mot "plage" dans son titre. C'est l'expérience que permet la recherche vectorielle.
Pour vous montrer comment Vector Search 2.0 permet d'y parvenir, nous allons créer un système de recherche de produits à l'aide de TheLook, un ensemble de données d'e-commerce réaliste qui contient 30 000 articles de mode répartis dans 26 catégories. Chaque produit possède des attributs que vous trouverez dans n'importe quel catalogue réel :

Les défis de recherche que nous allons relever
Les vrais clients ne recherchent pas les informations de la manière dont les bases de données s'y attendent. Ils effectuent des recherches comme ils pensent :

La recherche vectorielle 2.0 résout ces quatre problèmes grâce à une architecture unifiée.
Architecture des données de Vector Search 2.0
Avant de nous intéresser au code, comprenons comment la recherche vectorielle 2.0 organise vos données. L'architecture repose sur trois concepts clés : les collections, les objets de données et les index.
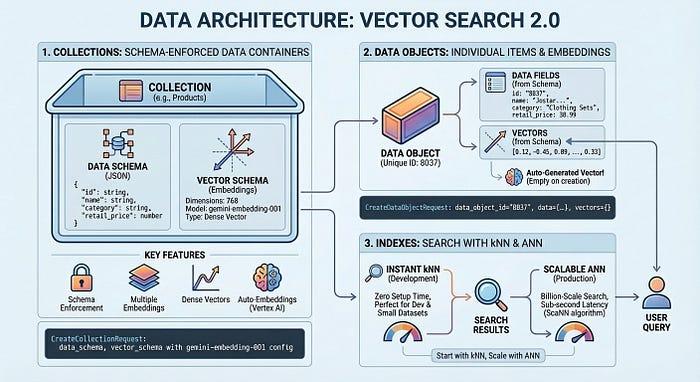
Une collection définit la structure de vos données : les champs que vous souhaitez stocker et ceux qui doivent être intégrés. Les objets de données sont les éléments (produits, documents, images) stockés dans une collection, chacun avec ses données et ses vecteurs générés automatiquement ou vos propres vecteurs. Un index optimise les requêtes à grande échelle, ce qui permet d'obtenir une latence en millisecondes pour des milliards d'éléments. Vous pouvez commencer sans index pour le développement, sans aucun temps de configuration, puis en ajouter un lorsque vous avez besoin de performances de production.
Créer la recherche TheLook : procédure détaillée
Nous allons maintenant créer un système de recherche de produits fonctionnel. Nous allons charger 10 000 articles de mode depuis TheLook, activer les embeddings automatiques et exécuter des recherches sémantiques, par mot clé et hybrides, le tout en une cinquantaine de lignes de code.
Ouvrir le notebook : Présentation de Vertex AI Vector Search 2.0
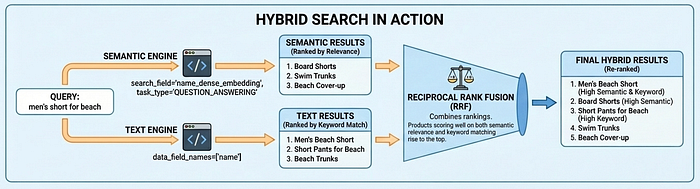
La recherche hybride en action
Vector Search 2.0 est compatible avec trois modes de recherche : la recherche sémantique (comprend l'intention grâce aux embeddings), la recherche textuelle (correspondance de mots clés) et la recherche hybride (qui combine les deux). La recherche hybride offre les meilleurs résultats pour la plupart des cas d'utilisation. La recherche sémantique trouve "short de bain" lorsque les utilisateurs recherchent "tenue homme pour la plage", tandis que la recherche textuelle garantit que les correspondances exactes, comme les codes produit, ne sont pas manquées.
Pourquoi les embeddings de type de tâche sont-ils importants ?
Notez les paramètres task_type dans le code ci-dessus : RETRIEVAL_DOCUMENT lors de l'indexation des produits et QUESTION_ANSWERING lors de la recherche. Ce n'est pas arbitraire : il s'agit d'une technique clé pour améliorer la qualité de la recherche en permettant au modèle d'embedding de fonctionner comme un modèle de recommandation.
La plupart des cas d'utilisation de la recherche vectorielle reposent sur une simple mise en correspondance de similarité, mais cela ne permet souvent pas d'obtenir une qualité de recherche de niveau production, car les questions et les réponses ne sont pas intrinsèquement similaires dans l'espace d'intégration. Les requêtes "Quoi emporter pour des vacances à la plage ?" et "Short de bain" ont des sémantiques différentes, mais elles devraient correspondre. Les embeddings de type de tâche résolvent ce problème en optimisant le modèle d'embedding pour les relations asymétriques : les documents sont intégrés différemment des requêtes, ce qui crée un espace d'embedding où les correspondances pertinentes sont regroupées. Cela permet de recommander des éléments et de trouver des éléments pertinents en fonction de l'intention de l'utilisateur.
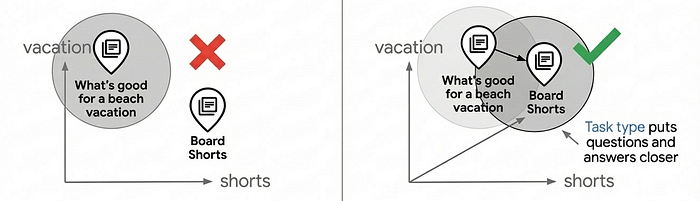
L'utilisation d'embeddings spécifiques à une tâche peut améliorer la qualité de la recherche de 30 à 40 % par rapport aux embeddings génériques. Pour en savoir plus sur son fonctionnement, consultez le notebook Task Type Embedding.
De zéro à un milliard d'utilisateurs
Pour la production à grande échelle, la recherche vectorielle 2.0 propose des index ANN (Approximate Nearest Neighbor) optimisés par l'algorithme ScaNN (Scalable Nearest Neighbors) de Google, la même technologie que celle utilisée par la recherche Google, YouTube et Google Play. ANN échange une petite quantité de précision (~99 %) contre des gains de vitesse considérables : une latence inférieure à 10 ms, même avec des milliards de vecteurs.
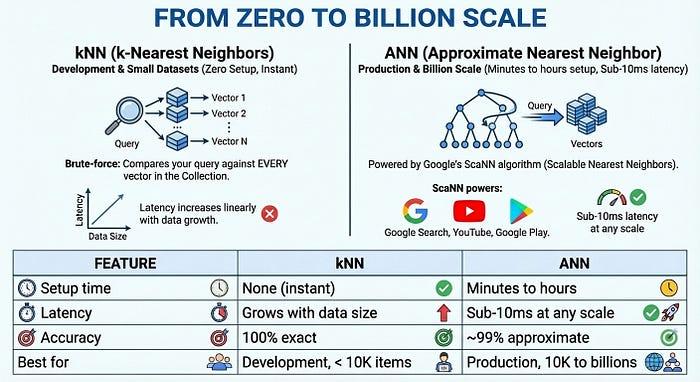
The Complete Picture
En seulement cinq étapes (les quatre premières ne prenant qu'environ cinq minutes), nous avons créé un système de recherche de produits prêt pour la production :
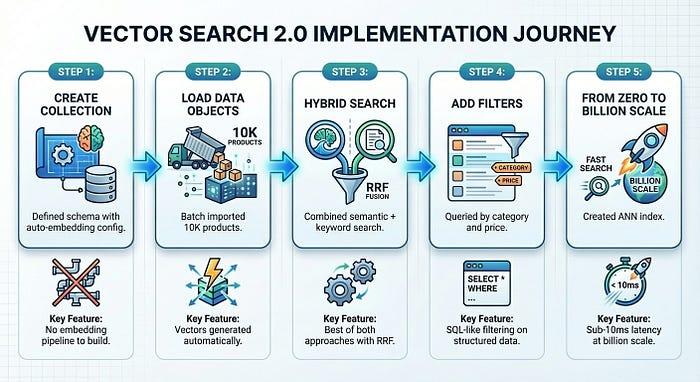
Vector Search 2.0 élimine la complexité de l'infrastructure qui ralentit généralement l'adoption de la recherche vectorielle. Vous vous concentrez sur votre produit, et la plate-forme gère les embeddings, l'indexation et la mise à l'échelle.
3. Félicitations
Félicitations, vous venez de créer votre première application avec la recherche vectorielle 2.0 !