
1. מבוא
עדכון אחרון: 2026-03-04
חיפוש וקטורי, או מסד נתונים וקטורי, הפך לטכנולוגיה בסיסית למערכות AI מודרניות. הטכנולוגיה הזו מייצגת נתונים כהטמעות רב-ממדיות שמבטאות משמעות סמנטית, והיא משמשת לכל מיני משימות, החל מחיפוש סמנטי שמבין את כוונת המשתמש, דרך מנועי המלצות שמציגים תוכן רלוונטי, ועד ליצירה משולבת-אחזור (RAG) וסוכני AI שמבססים את התשובות של מודלים גדולים של שפה (LLM) על מידע אמיתי ועדכני. חברות טכנולוגיה גדולות, כולל Google, מסתמכות על הטכנולוגיה הזו בקנה מידה עצום כדי לעבד מיליארדי חיפושים, המלצות ועיגונים מדי יום.
עם זאת, בניית חיפוש וקטורי שמוכן לייצור עדיין מאתגרת. לאחרונה Google השיקה את Vertex AI Vector Search 2.0 כדי לשנות את המצב – שירות מנוהל באופן מלא שנועד לבטל את המורכבות התכנונית והתפעולית שמעכבת את הצוותים.

Why Vector Search Is Harder Than It Looks
הקונספט פשוט. ההטמעה? כאן הדברים מתחילים להיות מורכבים.
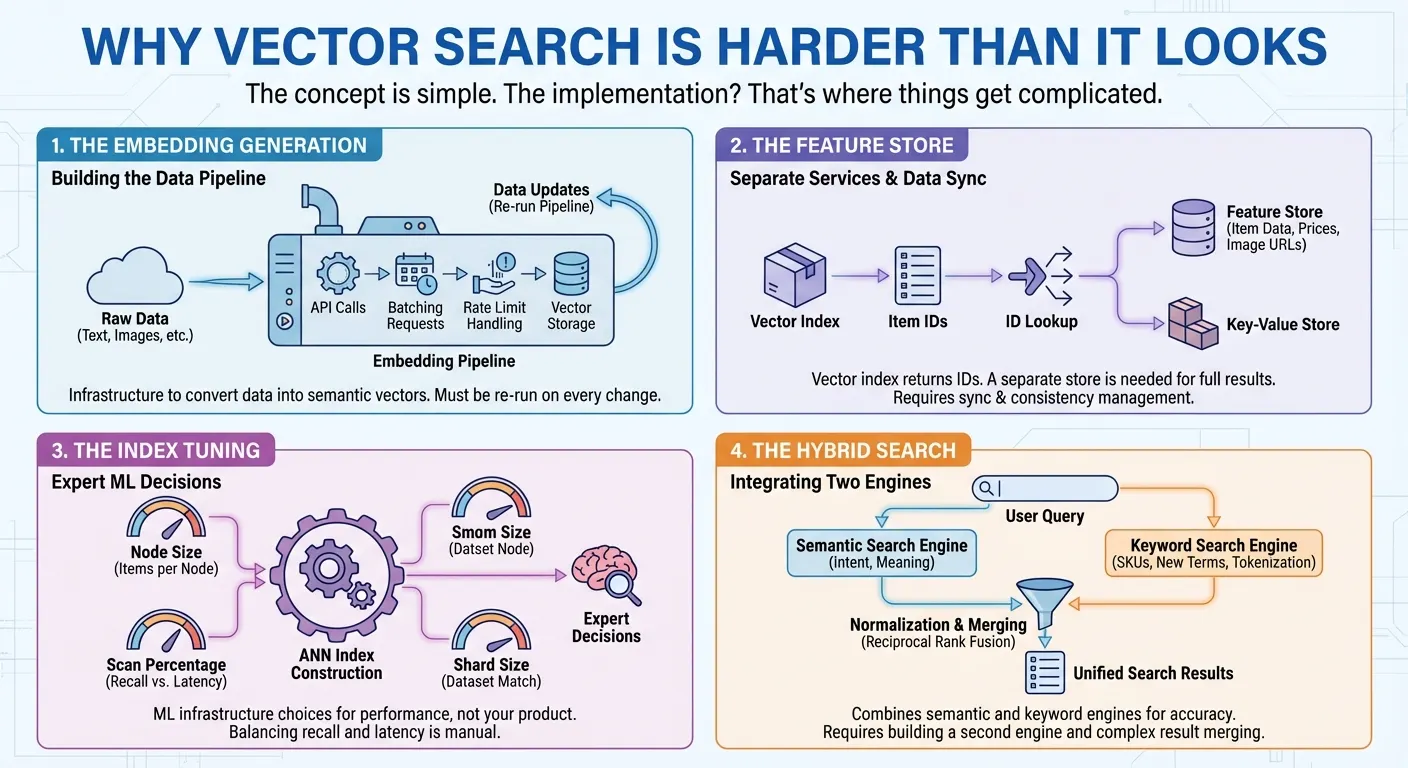
יצירת ההטמעה. כדי להשתמש בחיפוש וקטורי, צריך להמיר את הנתונים לייצוגים מספריים (הטמעות) שמשקפים משמעות סמנטית. כלומר, צריך לקרוא ל-API להטמעת וקטורים, לשלוח את הבקשות באצווה, לטפל במגבלות קצב ולשמור את הווקטורים. בכל פעם שהנתונים משתנים, מריצים מחדש את צינור הנתונים. זוהי תשתית שצריך לבנות לפני שאפשר להתחיל לחפש.
מאגר התכונות. הרבה מוצרים של חיפוש וקטורי מספקים רק אינדקס וקטורי שמחזיר רשימה של מזהי פריטים לכל חיפוש. כדי להציג למשתמשים תוצאות חיפוש מלאות, צריך מאגר תכונות או מאגר של זוגות מפתח/ערך נפרדים כדי לאחזר את נתוני הפריטים בפועל – שמות, מחירים, קטגוריות, כתובות URL של תמונות במילישניות – על ידי העברת המזהים האלה. במקרים רבים, צריך גם להטמיע סינון מורכב של תכונות הפריט, כמו מחיר, קטגוריה או זמינות. כלומר, צריך ליצור ולתחזק שני שירותים שונים: אחד לחיפוש וקטורי ואחד לאחזור ולסינון נתונים. כל עדכון וכל שאילתה מחייבים גישה לשתי המערכות וסנכרון שלהן.
התאמה של האינדקס. כדי ליצור אינדקסים של שכנים קרובים משוערים (ANN) עם מיליוני פריטים, צריך לקבל החלטות מומחים כדי להשיג את הביצועים הטובים ביותר: כמה פריטים צריך להכיל כל צומת באינדקס? כדי לאזן בין היזכרות לבין זמן האחזור, מהו אחוז האינדקס שצריך לסרוק לכל שאילתה? מהו גודל השארד שמתאים למערך הנתונים שלכם? אלה החלטות לגבי תשתית ML שלא קשורות למוצר עצמו.
החיפוש ההיברידי. חיפוש סמנטי מצטיין בהבנת הכוונה – הוא מוצא מכנסי גלישה כשמשתמשים מחפשים "בגדים לגברים לים". אבל הוא נכשל בקודי מוצרים כמו 'SKU-12345' שאין להם משמעות סמנטית, ומתקשה עם מונחים חדשים או שמות מותגים שהמודל לא נתקל בהם אף פעם. חיפוש מילות מפתח מטפל במקרים האלה, אבל לא מביא בחשבון את ההקשר הסמנטי. המשתמשים צריכים את שניהם, ולכן חיפוש היברידי הפך לחיוני. אבל בנייתו היא לא עניין פשוט. אתם צריכים מנוע חיפוש של טקסט מלא עם טוקניזציה, אינדקסים הפוכים או הטמעות דלילות – בנוסף למנוע החיפוש הווקטורי. לאחר מכן צריך להריץ שאילתות מקבילות בשני המנועים, לנרמל את מערכות הניקוד השונות שלהם ולמזג את התוצאות באמצעות טכניקות כמו Reciprocal Rank Fusion.
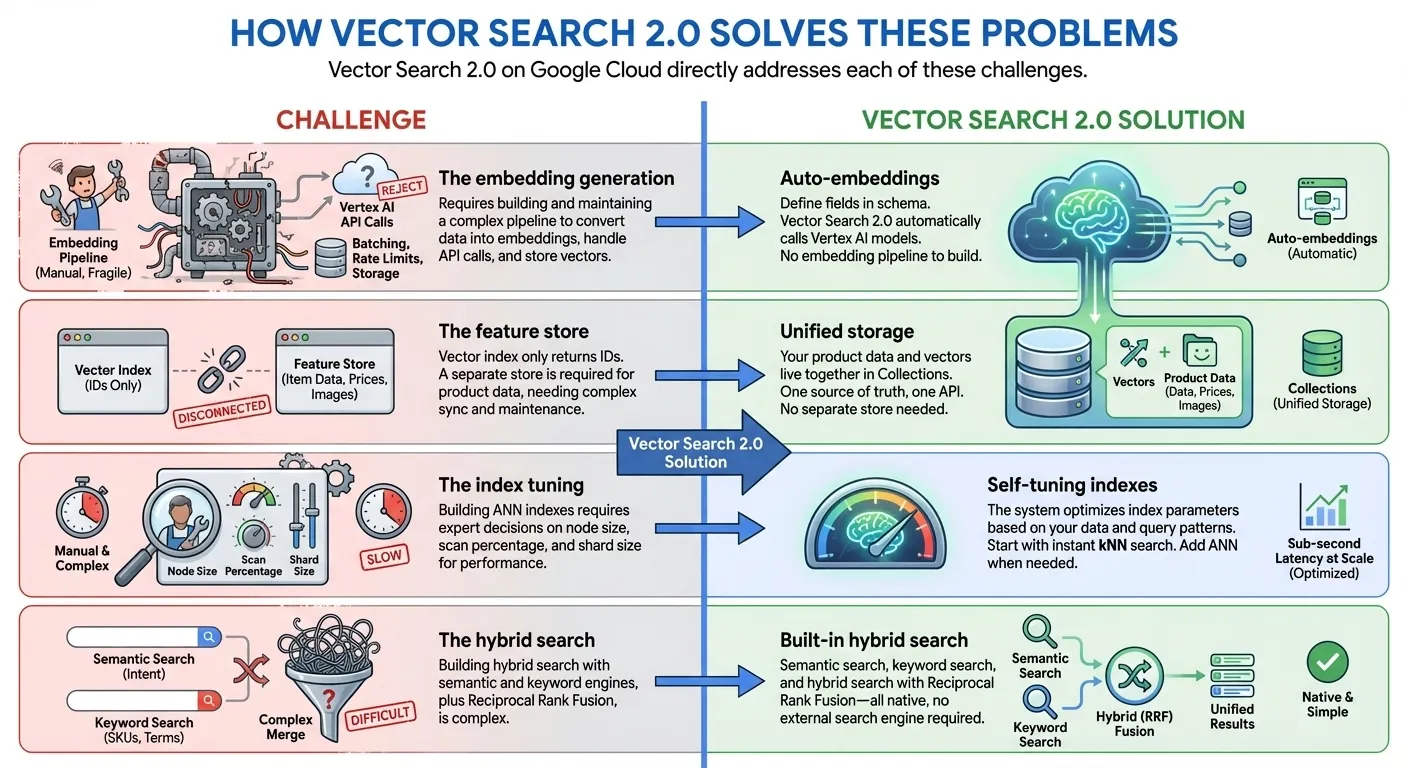
איך Vector Search 2.0 פותר את הבעיות האלה
התכונה 'חיפוש וקטורי 2.0' ב-Google Cloud נותנת מענה ישיר לכל אחד מהאתגרים האלה:

בסדנה הזו ניצור חיפוש היברידי בניהול מלא באמצעות 10,000 מוצרי אופנה ממערך הנתונים של TheLook למסחר אלקטרוני.
מהו Vector Search 2.0?
Vector Search 2.0 הוא מסד נתונים וקטורי מנוהל לחלוטין של Google Cloud, עם כוונון עצמי, שמבוסס על אלגוריתם ScaNN (Scalable Nearest Neighbors) של Google – אותה טכנולוגיה שמפעילה את חיפוש Google, YouTube ו-Google Play.
יתרונות מרכזיים
- אינדקס מאפס לאינדקס של מיליארדים: אפשר להתחיל לפתח באופן מיידי עם זמן אינדקס של אפס באמצעות kNN (k-Nearest Neighbors), ואז להרחיב למיליארדי וקטורים עם חביון של אלפיות השנייה באמצעות אינדקסים של ANN (Approximate Nearest Neighbor) בקנה מידה של Google לייצור – והכול עם אותו API ואותו מערך נתונים.
- אחסון נתונים מאוחד: אחסון של הטמעות וקטוריות ונתונים שהמשתמשים סיפקו יחד (אין צורך במסד נתונים נפרד או במאגר תכונות)
- Auto-Embeddings: יצירה אוטומטית של הטמעות סמנטיות באמצעות מודלים להטמעה של Vertex AI
- חיפוש טקסט מלא מובנה: מספק חיפוש טקסט מלא מובנה בלי שתצטרכו ליצור הטמעות דלילות בעצמכם. אפשר גם להשתמש בהטמעות דלילות משלכם (למשל, BM25, SPLADE) עם חיפוש וקטורי כדי לבצע חיפוש מותאם אישית של טקסט מלא.
- חיפוש היברידי: שילוב של חיפוש סמנטי וחיפוש שמבוסס על מילות מפתח או על טוקנים בשאילתה אחת, עם דירוג חכם של RRF
- התאמה אוטומטית: ביצועים שעברו אופטימיזציה אוטומטית ללא הגדרה ידנית
- מתאים לארגונים: יכולות מובנות של התאמה לגודל, אבטחה ועמידה בדרישות
ארכיטקטורת ליבה
הגרסה Vector Search 2.0 כוללת שלושה רכיבים עיקריים:
- אוספים: מאגרי נתונים שמוגדרת להם סכימה
- אובייקטים של נתונים: פריטים בודדים עם נתונים והטמעות וקטוריות
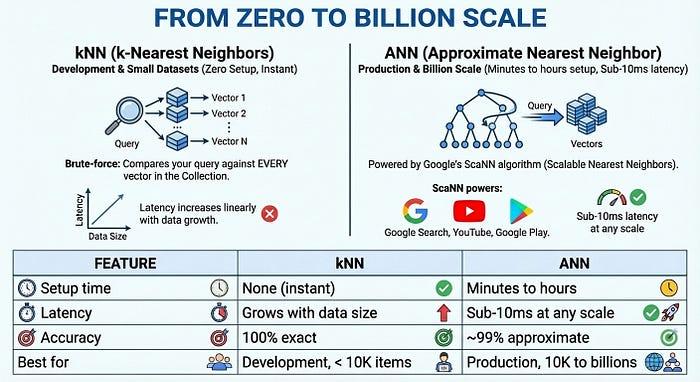
- אינדקסים: חיפוש מיידי של השכן הקרוב ביותר בנתונים באמצעות kNN. כדי לבצע חיפוש של שכנים קרובים עם זמן אחזור נמוך, צריך להשתמש באינדקס ANN.
- מתחילים במהירות: אפשר להשתמש ב-kNN באופן מיידי ללא זמן הגדרה – מושלם לפיתוח ולקבוצות נתונים קטנות
- התאמה לשימוש בסביבת ייצור: שימוש באינדקסים של ANN לחיפוש בהיקף של מיליארדים עם זמן אחזור של פחות משנייה, באמצעות אלגוריתם ScaNN
נבחן כל מושג באמצעות דוגמאות מעשיות.
2. יצירת חיפוש אופנה ב-TheLook
נניח שלקוח נכנס לאתר המסחר האלקטרוני שלכם ומקליד "משהו חמוד לחופשה בים". בחיפוש מילות מפתח רגיל, הם לא מקבלים תוצאות – אף מוצר בקטלוג לא מכיל את המילים האלה בדיוק. הם מתייאשים ועוזבים.
עכשיו דמיינו חוויה אחרת. אותה שאילתה מחזירה שמלות קיץ, בגדי חוף ומכנסיים קצרים רחבים – מוצרים שתואמים בדיוק למה שהלקוח רצה, למרות שאף אחד מהם לא מכיל את המילה "חוף" בשם שלו. זו החוויה שחיפוש וקטורי מאפשר.
כדי להדגים איך Vector Search 2.0 מאפשר זאת, נבנה מערכת לחיפוש מוצרים באמצעות TheLook, מערך נתונים ריאליסטי של מסחר אלקטרוני עם 30,000 פריטי אופנה ב-26 קטגוריות. לכל מוצר יש מאפיינים שאפשר למצוא בכל קטלוג אמיתי:

האתגרים בחיפוש שנפתור
לקוחות אמיתיים לא מחפשים כמו שמסדי נתונים מצפים. הם מחפשים כמו שהם חושבים:

Vector Search 2.0 פותר את כל ארבעת האתגרים באמצעות ארכיטקטורה מאוחדת.
ארכיטקטורת הנתונים של Vector Search 2.0
לפני שמתחילים לכתוב קוד, חשוב להבין איך Vector Search 2.0 מארגן את הנתונים. הארכיטקטורה מתבססת על שלושה מושגי מפתח: אוספים, אובייקטים של נתונים ואינדקסים.
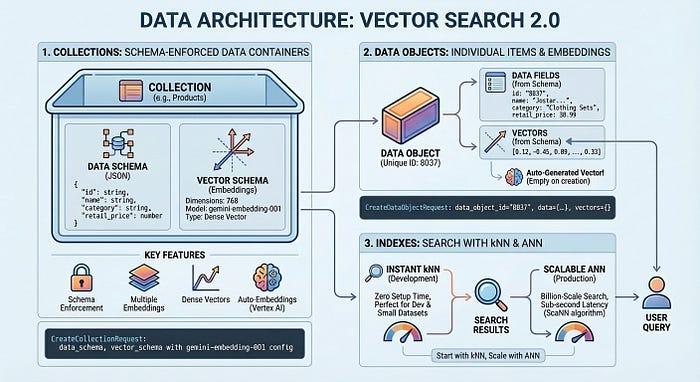
אוסף מגדיר את מבנה הנתונים – השדות שרוצים לאחסן ואילו שדות צריכים להיות מוטמעים. אובייקטים של נתונים הם הפריטים בפועל (מוצרים, מסמכים, תמונות) שמאוחסנים באוסף, כל אחד עם הנתונים שלו ועם וקטורים שנוצרו אוטומטית או וקטורים משלכם. אינדקס מבצע אופטימיזציה של שאילתות בהיקף נרחב, ומאפשר זמן אחזור של אלפיות שנייה במיליארדי פריטים. אתם יכולים להתחיל לפתח בלי אינדקס כדי לחסוך זמן הגדרה, ואז להוסיף אינדקס כשאתם צריכים ביצועים ברמת הייצור.
יצירת חיפוש ב-TheLook: מדריך מפורט
עכשיו נבנה מערכת חיפוש מוצרים שעובדת. נטען 10,000 פריטי אופנה מ-TheLook, נפעיל הטמעה אוטומטית ונריץ חיפושים סמנטיים, חיפושים לפי מילות מפתח וחיפושים היברידיים – והכול בכ-50 שורות קוד.
פתיחת מסמך notebook: Introduction to Vertex AI Vector Search 2.0
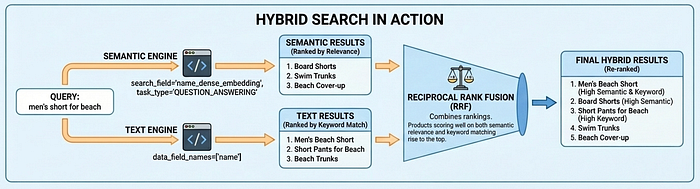
חיפוש היברידי בפעולה
Vector Search 2.0 תומך בשלושה מצבי חיפוש: חיפוש סמנטי (הבנת כוונת המשתמש באמצעות הטמעות), חיפוש טקסט (התאמה למילות מפתח) וחיפוש היברידי (שילוב של שניהם). חיפוש היברידי מספק את התוצאות הטובות ביותר לרוב תרחישי השימוש – חיפוש סמנטי מוצא את התוצאה 'מכנסי גלישה' כשמשתמשים מחפשים 'ביגוד לגברים לחוף הים', בעוד שחיפוש טקסט מבטיח שלא יפספסו התאמות מדויקות כמו קודי מוצרים.
למה חשוב להטמיע סוגי משימות
שימו לב לפרמטרים של task_type בקוד שלמעלה: RETRIEVAL_DOCUMENT כשמבצעים אינדוקס של מוצרים, ו-QUESTION_ANSWERING כשמבצעים חיפוש. השיטה הזו לא שרירותית – היא טכניקה חשובה לשיפור איכות החיפוש, כי היא מאפשרת למודל ההטמעה לפעול כמו מודל המלצות.
רוב תרחישי השימוש בחיפוש וקטורי מסתמכים על התאמה פשוטה של דמיון, אבל לרוב הם לא מספקים איכות חיפוש ברמה של ייצור, כי השאלות והתשובות לא דומות באופן מובנה במרחב ההטמעה. לשאילתות 'מה מתאים לחופשה בים?' ו'מכנסי גלישה' יש משמעויות שונות, אבל הן צריכות להתאים. הטכנולוגיה הזו פותרת את הבעיה הזו על ידי אופטימיזציה של מודל ההטמעה ליחסים אסימטריים: הטמעת המסמכים שונה מהטמעת השאילתות, וכך נוצר מרחב הטמעה שבו התאמות רלוונטיות מקובצות יחד – מה שמאפשר להוסיף המלצות ולמצוא פריטים רלוונטיים על סמך כוונת המשתמש.
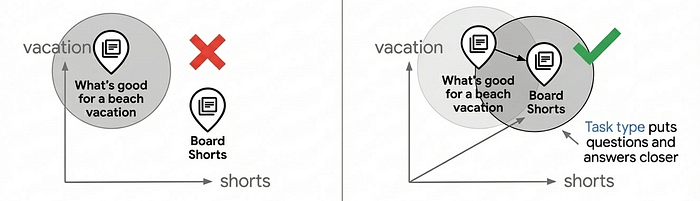
שימוש בהטמעות ספציפיות למשימות יכול לשפר את איכות החיפוש ב-30% עד 40% בהשוואה להטמעות כלליות. למידע מעמיק על אופן הפעולה של התכונה הזו, אפשר לעיין במחברת Task Type Embedding.
מ-0 לקנה מידה של מיליארדים
לייצור בקנה מידה גדול, Vector Search 2.0 מציע אינדקסים של ANN (Approximate Nearest Neighbor) שמבוססים על אלגוריתם ScaNN (Scalable Nearest Neighbors) של Google – אותה טכנולוגיה שמופעלת בחיפוש Google, ב-YouTube וב-Google Play. רשת ANN מוותרת על כמות קטנה מאוד של דיוק (~99%) לטובת שיפורים משמעותיים במהירות: זמן אחזור של פחות מ-10 אלפיות השנייה, גם עם מיליארדי וקטורים.
התמונה המלאה
ב-5 שלבים בלבד – כששלבים 1 עד 4 נמשכים כ-5 דקות בלבד – בנינו מערכת לחיפוש מוצרים שמוכנה להפקה:
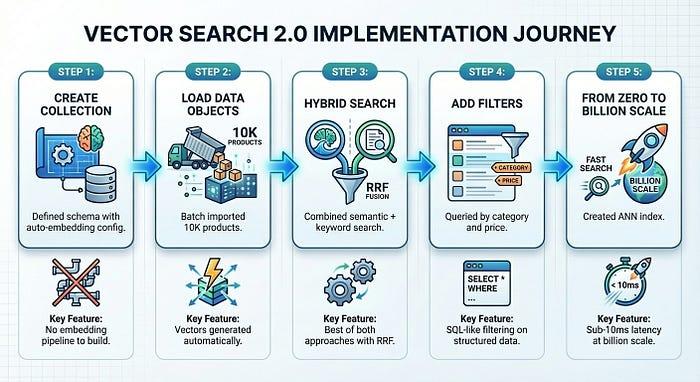
הכלי Vector Search 2.0 מבטל את המורכבות של התשתית שבדרך כלל מאטה את האימוץ של חיפוש וקטורי. אתם מתמקדים במוצר, והפלטפורמה מטפלת בהטמעות, ביצירת אינדקסים ובשינוי קנה מידה.
3. מזל טוב
מזל טוב, יצרת בהצלחה את האפליקציה הראשונה שלך באמצעות Vector Search 2.0!