
1. परिचय
पिछले अपडेट की तारीख: 04-03-2026
वेक्टर सर्च या वेक्टर डेटाबेस, आधुनिक एआई सिस्टम के लिए एक बुनियादी टेक्नोलॉजी बन गई है. यह डेटा को सेमैंटिक मीनिंग कैप्चर करने वाले हाई-डाइमेंशनल एम्बेडिंग के तौर पर दिखाता है. इससे सेमैंटिक सर्च से लेकर, काम का कॉन्टेंट दिखाने वाले सुझाव इंजन, रिट्रीवल ऑगमेंटेड जनरेशन (आरएजी), और एआई एजेंट तक, सभी को बेहतर बनाने में मदद मिलती है. ये एलएलएम के जवाबों को असल और अप-टू-डेट जानकारी के आधार पर तैयार करते हैं. Google जैसी बड़ी टेक्नोलॉजी कंपनियां, इस टेक्नोलॉजी का इस्तेमाल बड़े पैमाने पर करती हैं. इससे हर दिन अरबों खोजों, सुझावों, और भरोसेमंद स्रोतों से जानकारी लेने की प्रोसेस को पूरा किया जाता है.
हालांकि, प्रोडक्शन के लिए तैयार वेक्टर सर्च को बनाना अब भी एक चुनौती है. Google ने हाल ही में Vertex AI Vector Search 2.0 लॉन्च किया है. यह पूरी तरह से मैनेज की जाने वाली सेवा है. इसे डिज़ाइन और ऑपरेशन से जुड़ी उन मुश्किलों को दूर करने के लिए बनाया गया है जिनकी वजह से टीमें धीमे काम करती हैं.

Why Vector Search Is Harder Than It Looks
यह कॉन्सेप्ट आसान है. लागू करना है? यहां चीज़ें मुश्किल हो जाती हैं.
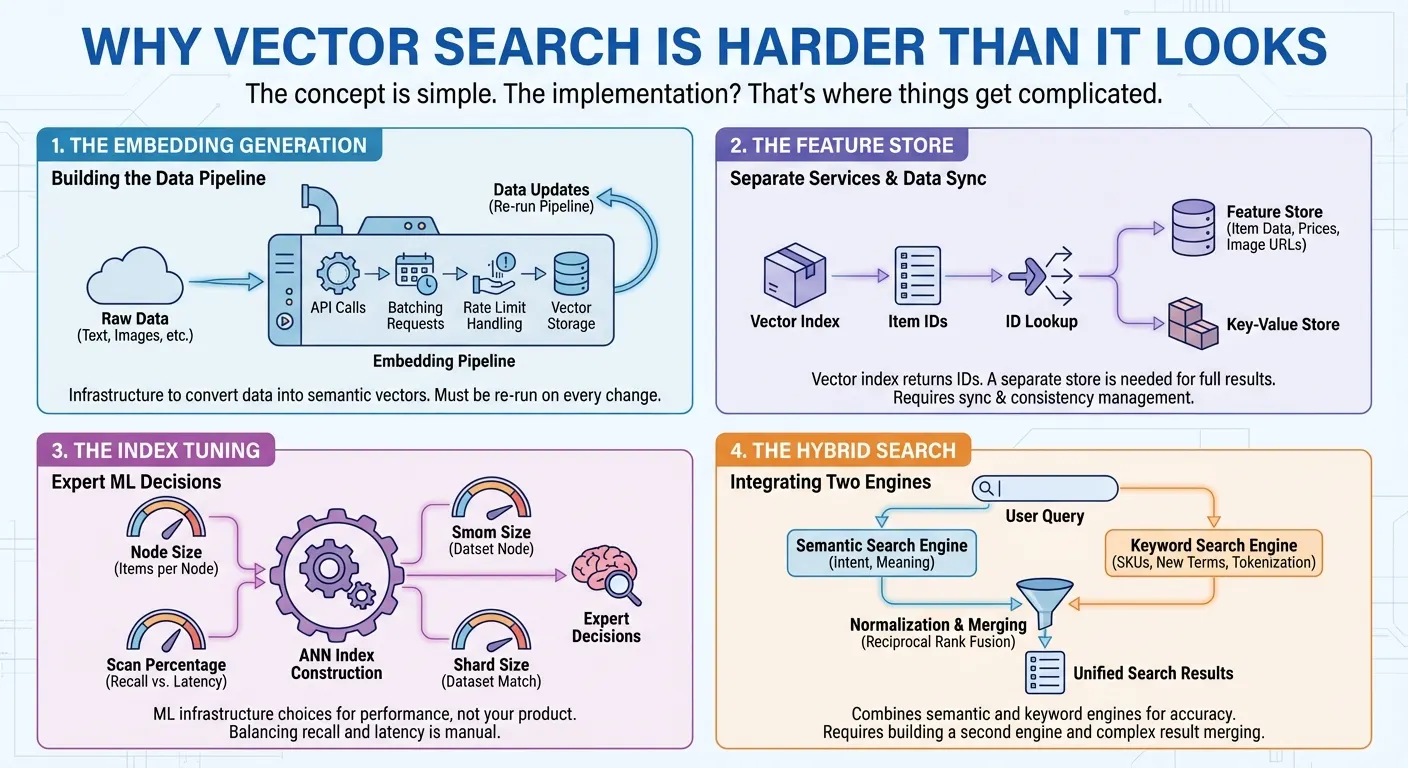
एम्बेडिंग जनरेट करने की प्रोसेस. वेक्टर सर्च के लिए, अपने डेटा को संख्यात्मक प्रज़ेंटेशन (एम्बेडिंग) में बदलना ज़रूरी है. इससे सिमैंटिक अर्थ को कैप्चर किया जा सकता है. इसका मतलब है कि आपको Embedding API को कॉल करना होगा, अपने अनुरोधों को बैच में भेजना होगा, दर की सीमाओं को मैनेज करना होगा, और वेक्टर सेव करने होंगे. जब भी आपके डेटा में बदलाव होता है, तब पाइपलाइन को फिर से चलाया जाता है. यह एक ऐसा इन्फ़्रास्ट्रक्चर है जिसे आपको खोज शुरू करने से पहले बनाना होगा.
सुविधाओं का स्टोर. वेक्टर सर्च की सुविधा देने वाले कई प्रॉडक्ट, सिर्फ़ एक वेक्टर इंडेक्स उपलब्ध कराते हैं. यह इंडेक्स, हर खोज के लिए आइटम आईडी की सूची दिखाता है. लोगों को खोज के पूरे नतीजे दिखाने के लिए, आपको अलग फ़ीचर स्टोर या कुंजी-वैल्यू स्टोर की ज़रूरत होती है. इससे आईडी पास करके, आइटम का असल डेटा (नाम, कीमतें, कैटगरी, मिलीसेकंड में इमेज के यूआरएल) वापस पाया जा सकता है. कई मामलों में, आपको आइटम की सुविधाओं पर मुश्किल फ़िल्टरिंग भी लागू करनी होती है. जैसे, कीमत, कैटगरी या उपलब्धता. इसका मतलब है कि आपको दो अलग-अलग सेवाएं बनानी और मैनेज करनी होंगी: एक वेक्टर सर्च के लिए और दूसरी डेटा को वापस पाने और फ़िल्टर करने के लिए. हर अपडेट और क्वेरी के लिए, दोनों सिस्टम को ऐक्सेस करना और सिंक करना ज़रूरी है.
इंडेक्स ट्यूनिंग. लाखों आइटम के साथ ऐप्रोक्सिमेट नियरेस्ट नेबर (एएनएन) इंडेक्स बनाने के लिए, आपको सबसे अच्छी परफ़ॉर्मेंस पाने के लिए एक्सपर्ट फ़ैसले लेने होंगे: हर इंडेक्स नोड में कितने आइटम होने चाहिए? हर क्वेरी के लिए इंडेक्स के कितने प्रतिशत हिस्से को स्कैन किया जाना चाहिए, ताकि रिकॉल और लेटेन्सी के बीच संतुलन बना रहे? आपके डेटासेट के हिसाब से, शार्ड का कौनसा साइज़ सही है? ये एमएल इंफ़्रास्ट्रक्चर से जुड़े फ़ैसले हैं. इनका आपके प्रॉडक्ट से कोई लेना-देना नहीं है.
हाइब्रिड सर्च. सिमेंटिक सर्च, इंटेंट को समझने में बेहतर होती है. जैसे, जब लोग "पुरुषों के लिए बीच पर पहनने वाले कपड़े" खोजते हैं, तो उन्हें "बोर्ड शॉर्ट्स" मिलते हैं. हालांकि, यह "SKU-12345" जैसे प्रॉडक्ट कोड के लिए काम नहीं करता, क्योंकि इनका कोई मतलब नहीं होता. साथ ही, यह ऐसे नए शब्दों या ब्रैंड के नामों को समझने में भी मुश्किलों का सामना करता है जिनके बारे में एम्बेडिंग मॉडल को पहले से जानकारी नहीं होती. कीवर्ड की मदद से खोज करने पर, इन मामलों को हैंडल किया जाता है. हालांकि, इसमें सिमैंटिक कॉन्टेक्स्ट नहीं मिलता. लोगों को दोनों की ज़रूरत होती है. इसलिए, हाइब्रिड सर्च ज़रूरी हो गई है. हालांकि, इसे बनाना आसान नहीं है. आपको अपने वेक्टर सर्च इंजन के साथ-साथ, टोकनाइज़ेशन, उल्टे इंडेक्स या स्पार्स एम्बेडिंग वाला फ़ुल-टेक्स्ट सर्च इंजन भी चाहिए. इसके बाद, आपको दोनों इंजन पर एक साथ क्वेरी चलाने, उनकी अलग-अलग स्कोरिंग सिस्टम को सामान्य करने, और Reciprocal Rank Fusion जैसी तकनीकों का इस्तेमाल करके नतीजों को मर्ज करने की ज़रूरत होती है.
Vector Search 2.0 इन समस्याओं को कैसे हल करता है
Google Cloud पर उपलब्ध Vector Search 2.0, इन सभी चुनौतियों को सीधे तौर पर हल करता है:

इस वर्कशॉप में, हम TheLook ई-कॉमर्स डेटासेट से लिए गए 10,000 फ़ैशन प्रॉडक्ट का इस्तेमाल करके, पूरी तरह से मैनेज की जाने वाली हाइब्रिड खोज बनाएंगे.
Vector Search 2.0 क्या है?
Vector Search 2.0, Google Cloud का पूरी तरह से मैनेज किया जाने वाला, अपने-आप ट्यून होने वाला वेक्टर डेटाबेस है. इसे Google के ScaNN (स्केलेबल नियरेस्ट नेबर्स) एल्गोरिदम पर बनाया गया है. यह वही टेक्नोलॉजी है जो Google Search, YouTube, और Google Play को बेहतर बनाती है.
मुख्य अंतर
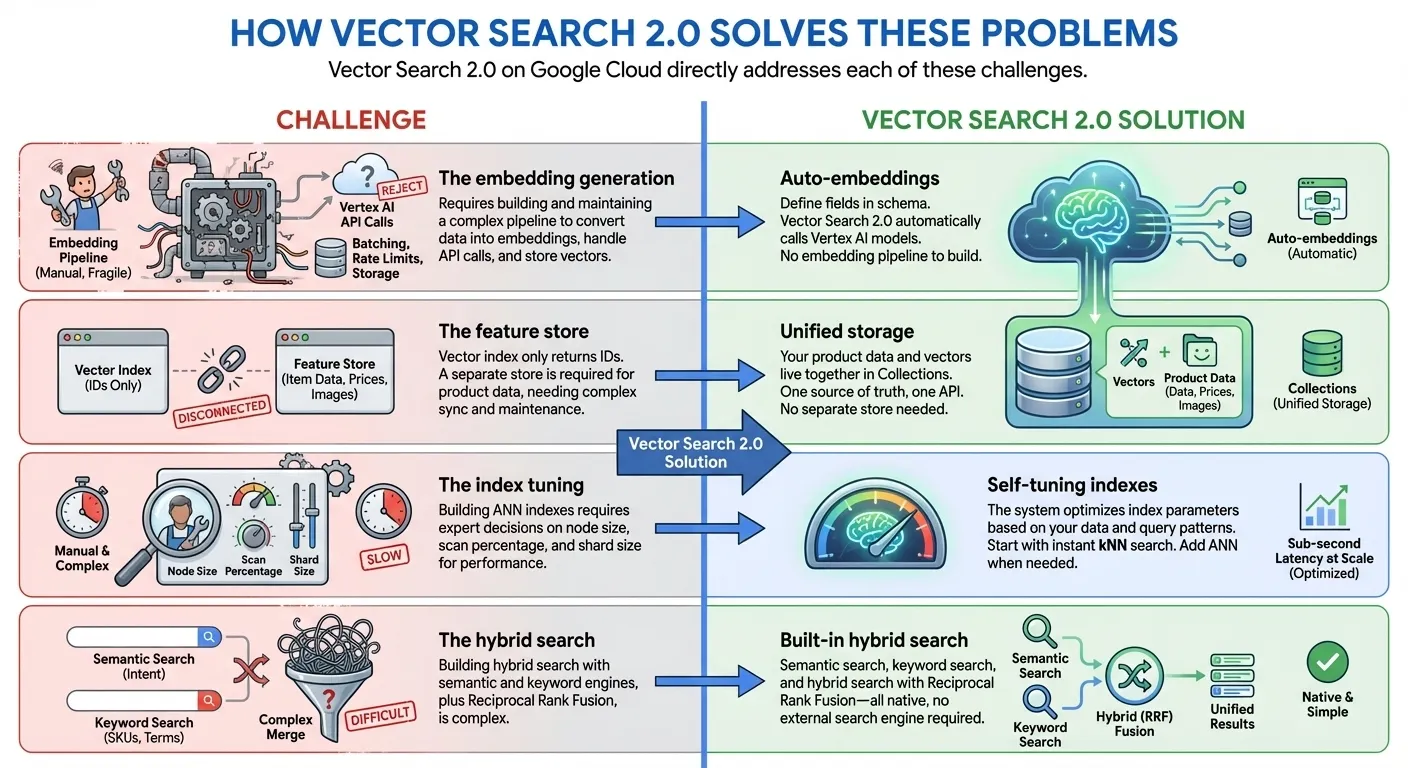
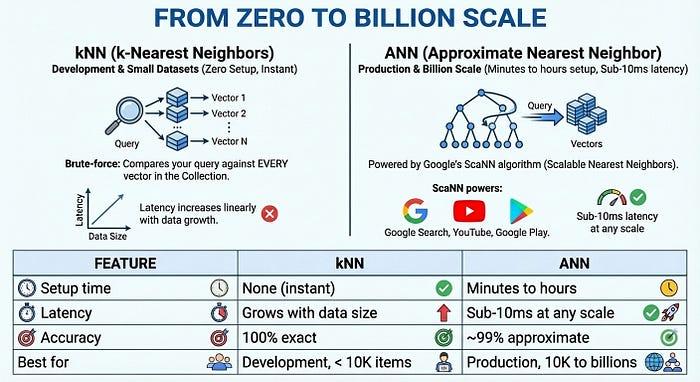
- ज़ीरो इंडेक्सिंग से लेकर अरबों इंडेक्स तक: kNN (k-Nearest Neighbors) का इस्तेमाल करके, इंडेक्सिंग में लगने वाले समय को कम करें और तुरंत डेवलपमेंट शुरू करें. इसके बाद, प्रोडक्शन के लिए Google के ANN (Approximate Nearest Neighbor) इंडेक्स का इस्तेमाल करके, मिलीसेकंड की लेटेन्सी के साथ अरबों वेक्टर तक स्केल करें. यह सब एक ही एपीआई और एक ही डेटासेट के साथ किया जा सकता है
- यूनिफ़ाइड डेटा स्टोरेज: वेक्टर एम्बेडिंग और उपयोगकर्ता से मिले डेटा, दोनों को एक साथ सेव करें. इसके लिए, अलग डेटाबेस या फ़ीचर स्टोर की ज़रूरत नहीं होती
- ऑटो-एम्बेडिंग: Vertex AI एम्बेडिंग मॉडल का इस्तेमाल करके, सिमैंटिक एम्बेडिंग अपने-आप जनरेट करें
- पहले से मौजूद फ़ुल टेक्स्ट सर्च की सुविधा: यह सुविधा, आपको खुद से स्पार्स एम्बेडिंग जनरेट करने की ज़रूरत के बिना, पहले से मौजूद फ़ुल-टेक्स्ट सर्च की सुविधा देती है. आपके पास वेक्टर सर्च के साथ अपने स्पार्स एम्बेडिंग (जैसे, BM25, SPLADE) का इस्तेमाल करने का विकल्प भी होता है. इससे आपको अपनी पसंद के मुताबिक फ़ुल-टेक्स्ट सर्च करने में मदद मिलती है.
- हाइब्रिड सर्च: इसमें एक ही क्वेरी में सिमैंटिक और कीवर्ड/टोकन-आधारित सर्च को, इंटेलिजेंट आरआरएफ़ रैंकिंग के साथ जोड़ा जाता है
- सेल्फ़-ट्यूनिंग: मैन्युअल कॉन्फ़िगरेशन के बिना, परफ़ॉर्मेंस अपने-आप ऑप्टिमाइज़ हो जाती है
- एंटरप्राइज़ के लिए तैयार: इसमें पहले से ही स्केलेबिलिटी, सुरक्षा, और अनुपालन की सुविधाएं मौजूद हैं
कोर आर्किटेक्चर
वेक्टर सर्च 2.0 में तीन मुख्य कॉम्पोनेंट होते हैं:
- कलेक्शन: ये आपके डेटा के लिए, स्कीमा लागू किए गए कंटेनर होते हैं
- डेटा ऑब्जेक्ट: डेटा और वेक्टर एम्बेडिंग वाले अलग-अलग आइटम
- इंडेक्स: kNN की मदद से, अपने डेटा में सबसे मिलते-जुलते डेटा को तुरंत खोजें. कम इंतज़ार के समय में सबसे नज़दीकी पड़ोसी को खोजने के लिए, एएनएन इंडेक्स का इस्तेमाल करें.
- तुरंत शुरू करें: kNN का इस्तेमाल तुरंत शुरू करें. इसके लिए, आपको कोई सेटअप नहीं करना होगा. यह डेवलपमेंट और छोटे डेटासेट के लिए सबसे सही है
- प्रोडक्शन के लिए स्केल करें: ScaNN एल्गोरिदम की मदद से, एक सेकंड से भी कम समय में अरबों आइटम में खोज करने के लिए, एएनएन इंडेक्स का इस्तेमाल करें
आइए, हर कॉन्सेप्ट को उदाहरणों के साथ समझते हैं!
2. TheLook की फ़ैशन सर्च सुविधा बनाना
मान लें कि कोई खरीदार आपकी ई-कॉमर्स साइट पर आता है और "समुद्र तट पर छुट्टियां बिताने के लिए कोई प्यारा सा सामान" टाइप करता है. कीवर्ड के हिसाब से खोज करने पर, उन्हें कोई नतीजा नहीं मिलता. ऐसा इसलिए, क्योंकि आपके कैटलॉग में मौजूद किसी भी प्रॉडक्ट में वे सटीक शब्द शामिल नहीं हैं. इससे परेशान होकर, वे साइट छोड़ देते हैं.
अब एक अलग अनुभव के बारे में सोचें. इसी क्वेरी के लिए, सनड्रेस, स्विमवियर कवर-अप, और फ़्लोई शॉर्ट्स दिखाए गए हैं. ये ऐसे प्रॉडक्ट हैं जो खरीदार की पसंद से पूरी तरह मेल खाते हैं. हालांकि, इनमें से किसी भी प्रॉडक्ट के टाइटल में "बीच" शब्द शामिल नहीं है. वेक्टर सर्च की मदद से, ऐसा ही अनुभव मिलता है.
हम TheLook का इस्तेमाल करके, प्रॉडक्ट खोजने वाला एक सिस्टम बनाएंगे. यह एक ऐसा ई-कॉमर्स डेटासेट है जिसमें 26 कैटगरी के 30, 000 फ़ैशन आइटम शामिल हैं. इससे यह पता चलेगा कि Vector Search 2.0 की मदद से,ऐसा कैसे किया जा सकता है. हर प्रॉडक्ट में ऐसे एट्रिब्यूट होते हैं जो आपको किसी भी असली कैटलॉग में मिल सकते हैं:

खोज से जुड़ी समस्याएं और उन्हें हल करने के तरीके
असली ग्राहक, डेटाबेस के हिसाब से खोज नहीं करते. वे अपनी सोच के हिसाब से खोज करते हैं:

Vector Search 2.0, एक ही आर्किटेक्चर का इस्तेमाल करके इन चारों समस्याओं को हल करता है.
वेक्टर सर्च 2.0 का डेटा आर्किटेक्चर
कोड के बारे में जानने से पहले, आइए समझते हैं कि Vector Search 2.0 आपके डेटा को कैसे व्यवस्थित करता है. आर्किटेक्चर में तीन मुख्य कॉन्सेप्ट पर फ़ोकस किया जाता है: कलेक्शन, डेटा ऑब्जेक्ट, और इंडेक्स.
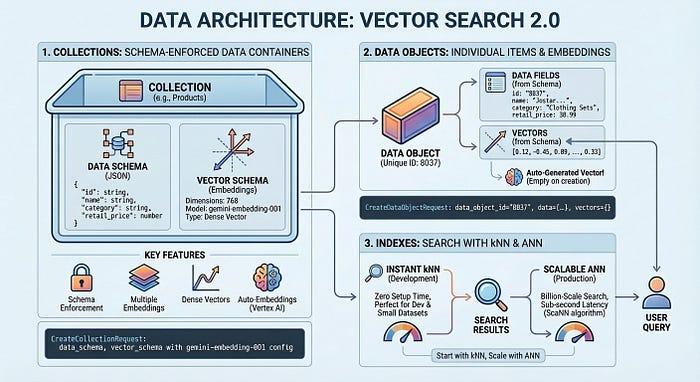
कलेक्शन से आपके डेटा स्ट्रक्चर के बारे में पता चलता है. जैसे, आपको कौनसे फ़ील्ड सेव करने हैं और कौनसे फ़ील्ड एम्बेड किए जाने चाहिए. डेटा ऑब्जेक्ट, कलेक्शन में सेव किए गए आइटम (प्रॉडक्ट, दस्तावेज़, इमेज) होते हैं. हर ऑब्जेक्ट में उसका डेटा और अपने-आप जनरेट होने वाले वेक्टर या आपके वेक्टर होते हैं. इंडेक्स, क्वेरी को बड़े पैमाने पर ऑप्टिमाइज़ करता है. इससे अरबों आइटम के लिए, मिलीसेकंड में नतीजे मिलते हैं. बिना इंडेक्स के डेवलपमेंट शुरू किया जा सकता है. इसमें सेटअप करने में कोई समय नहीं लगता. इसके बाद, जब आपको प्रोडक्शन परफ़ॉर्मेंस की ज़रूरत हो, तब इंडेक्स जोड़ा जा सकता है.
TheLook Search को बनाना: चरण दर चरण
अब हम काम करने वाला प्रॉडक्ट खोज सिस्टम बनाते हैं. हम TheLook से 10,000 फ़ैशन आइटम लोड करेंगे, अपने-आप एम्बेड होने की सुविधा चालू करेंगे, और सिमैंटिक, कीवर्ड, और हाइब्रिड खोजें चलाएंगे. यह सब करीब 50 लाइनों के कोड में होगा.
नोटबुक खोलें: Vertex AI Vector Search 2.0 के बारे में जानकारी
हाइब्रिड सर्च की सुविधा
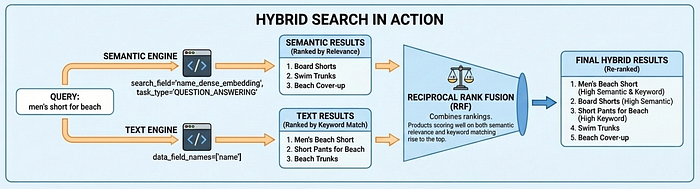
Vector Search 2.0 में खोज के तीन मोड उपलब्ध हैं: सिमैंटिक सर्च (एम्बेडिंग के ज़रिए इंटेंट को समझता है), टेक्स्ट सर्च (कीवर्ड मैचिंग), और हाइब्रिड सर्च (दोनों को जोड़ता है). हाइब्रिड सर्च, ज़्यादातर इस्तेमाल के मामलों में सबसे अच्छे नतीजे देती है. जैसे, सिमैंटिक सर्च की मदद से, जब लोग "पुरुषों के लिए बीच पर पहनने वाले कपड़े" खोजते हैं, तब उन्हें "बोर्ड शॉर्ट्स" मिलते हैं. वहीं, टेक्स्ट सर्च की मदद से यह पक्का किया जाता है कि प्रॉडक्ट कोड जैसे सटीक मैच न छूटें.
टास्क टाइप एम्बेडिंग क्यों ज़रूरी है
ऊपर दिए गए कोड में task_type पैरामीटर देखें: प्रॉडक्ट इंडेक्स करते समय RETRIEVAL_DOCUMENT और खोज करते समय QUESTION_ANSWERING. यह मनमाने तरीके से नहीं किया जाता. यह खोज के नतीजों की क्वालिटी को बेहतर बनाने की एक अहम तकनीक है. इससे एम्बेडिंग मॉडल, सुझाव देने वाले मॉडल की तरह काम कर पाता है.
वेक्टर सर्च के ज़्यादातर इस्तेमाल के उदाहरण, समानता से मैच करने की आसान तकनीक पर निर्भर करते हैं. हालांकि, इससे अक्सर प्रोडक्शन-लेवल की सर्च क्वालिटी नहीं मिलती. इसकी वजह यह है कि एम्बेडिंग स्पेस में सवाल और जवाब एक जैसे नहीं होते. "समुद्र किनारे की छुट्टियों के लिए क्या अच्छा है?" और "बोर्ड शॉर्ट्स" के सिमैंटिक अलग-अलग हैं. हालांकि, इन्हें मैच करना चाहिए. टास्क टाइप एम्बेडिंग इस समस्या को हल करती हैं. इसके लिए, वे असिमेट्रिक रिलेशनशिप के लिए एम्बेडिंग मॉडल को ऑप्टिमाइज़ करती हैं: दस्तावेज़ों को क्वेरी से अलग तरीके से एम्बेड किया जाता है. इससे एक ऐसा एम्बेडिंग स्पेस बनता है जहां काम के मैच एक साथ क्लस्टर होते हैं. इससे, सुझाव देने की सुविधा मिलती है. साथ ही, उपयोगकर्ता के मकसद के आधार पर काम के आइटम ढूंढे जा सकते हैं.
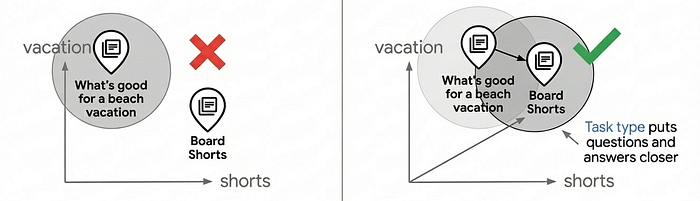
टास्क के हिसाब से एम्बेडिंग का इस्तेमाल करने से, सामान्य एम्बेडिंग की तुलना में खोज की क्वालिटी में 30 से 40% तक सुधार हो सकता है. यह सुविधा कैसे काम करती है, इसके बारे में ज़्यादा जानने के लिए टास्क टाइप एम्बेडिंग नोटबुक देखें.
From Zero to Billion Scale
बड़े पैमाने पर प्रोडक्शन के लिए, Vector Search 2.0, एएनएन (ऐप्रोक्सिमेट नियरेस्ट नेबर) इंडेक्स उपलब्ध कराता है. ये इंडेक्स, Google के ScaNN (स्केलेबल नियरेस्ट नेबर्स) एल्गोरिदम पर आधारित होते हैं. यह वही टेक्नोलॉजी है जो Google Search, YouTube, और Google Play में इस्तेमाल की जाती है. ANN, सटीक नतीजे देने के मामले में थोड़ा पीछे है (~99%). हालांकि, यह बहुत तेज़ी से काम करता है. इसमें अरबों वेक्टर होने पर भी, इंतज़ार का समय 10 मिलीसेकंड से कम होता है.
पूरी जानकारी
हमने सिर्फ़ पांच चरणों में, प्रॉडक्ट खोजने का ऐसा सिस्टम बनाया जिसे तुरंत इस्तेमाल किया जा सकता है. पहले से चौथे चरण तक, हमें सिर्फ़ पांच मिनट लगे:
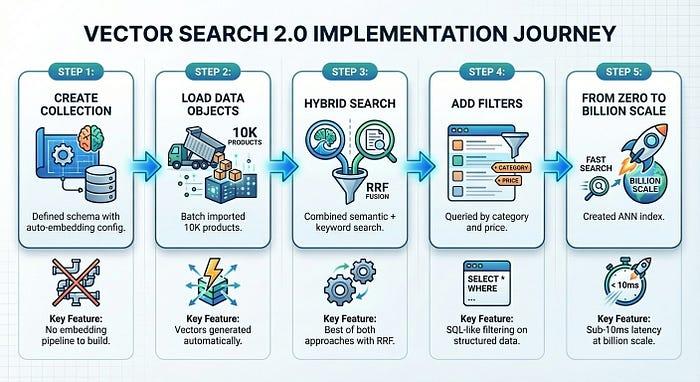
Vector Search 2.0, इन्फ़्रास्ट्रक्चर की जटिलता को कम करता है. आम तौर पर, इसकी वजह से वेक्टर सर्च को अपनाने में समय लगता है. आपका फ़ोकस अपने प्रॉडक्ट पर होता है. प्लैटफ़ॉर्म, एम्बेड करने, इंडेक्स करने, और स्केल करने की प्रोसेस को मैनेज करता है.
3. बधाई हो
बधाई हो, आपने Vector Search 2.0 की मदद से अपना पहला ऐप्लिकेशन बना लिया है!