
1. はじめに
最終更新日: 2026 年 3 月 4 日
ベクトル検索(ベクトル データベース)は、最新の AI システムの基盤となるテクノロジーになっています。意味的意味を捉えた高次元のエンベディングとしてデータを表現することで、ユーザーの意図を理解するセマンティック検索から、関連性の高いコンテンツを表示するレコメンデーション エンジン、LLM の回答を最新の実際の情報に基づいてグラウンディングする検索拡張生成(RAG)や AI エージェントまで、あらゆるものを強化します。Google を含む大手テクノロジー企業は、このテクノロジーを大規模に活用して、毎日数十億件の検索、おすすめ、グラウンディングを処理しています。
しかし、本番環境に対応したベクトル検索の構築は依然として困難です。Google は最近、Vertex AI Vector Search 2.0 をリリースしました。これは、チームのスピードを低下させる設計と運用の複雑さを解消するように設計されたフルマネージド サービスです。

ベクトル検索が難しい理由
コンセプトはシンプルです。実装は?ここからが複雑な部分です。
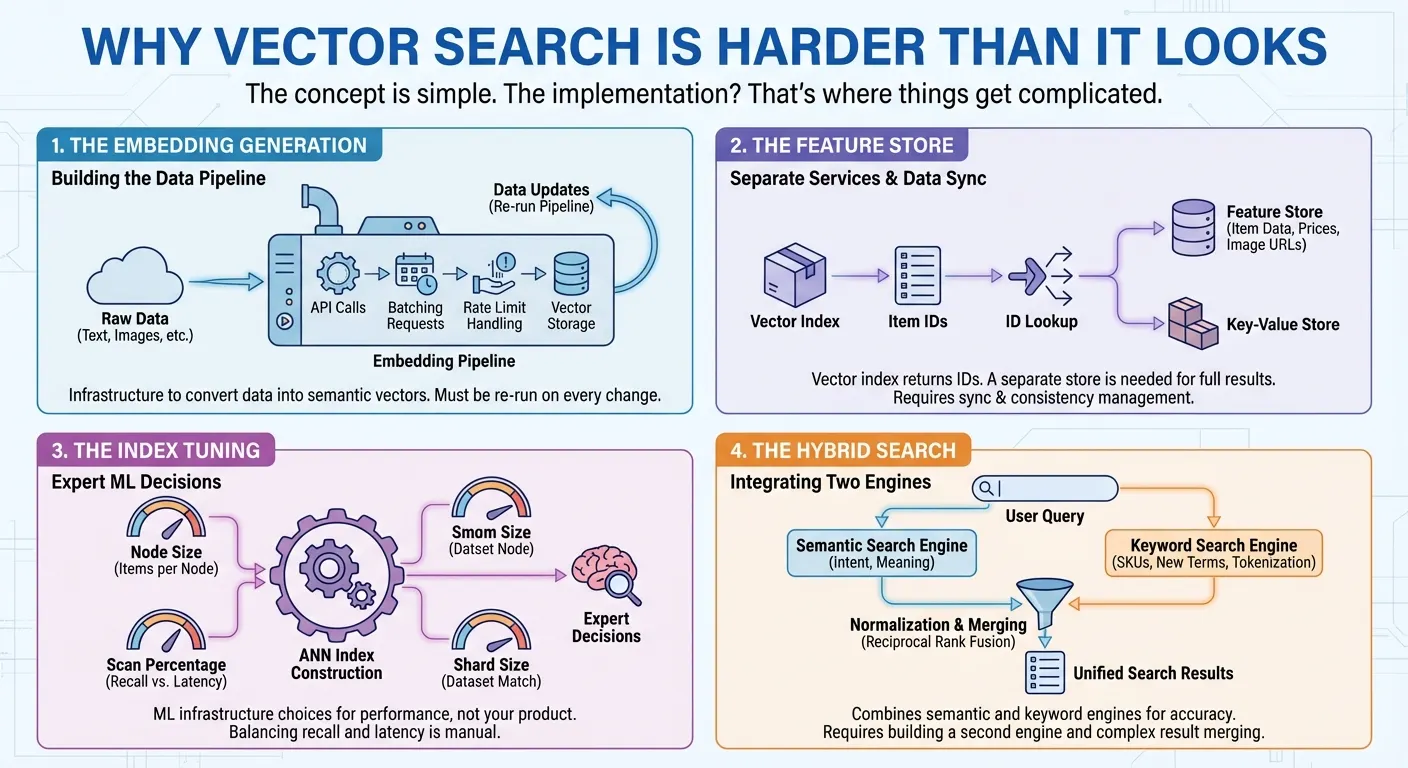
エンベディングの生成。ベクトル検索では、意味論的な意味を捉える数値表現(エンベディング)にデータを変換する必要があります。つまり、エンベディング API を呼び出し、リクエストをバッチ処理し、レート制限を処理して、ベクトルを保存する必要があります。データが変更されるたびに、パイプラインを再実行します。検索を開始する前に構築する必要があるインフラストラクチャです。
Feature Store。多くのベクトル検索プロダクトでは、各検索のアイテム ID のリストを返すベクトル インデックスのみが提供されています。完全な検索結果をユーザーに提供するには、これらの ID を渡して実際のアイテムデータ(名前、価格、カテゴリ、画像 URL など)をミリ秒単位で取得するための、別の特徴ストアまたはキー値ストアが必要です。多くの場合、価格、カテゴリ、在庫状況などのアイテムの特徴に対して複雑なフィルタリングを実装する必要もあります。つまり、ベクトル検索用のサービスとデータ取得とフィルタリング用のサービスの 2 つを構築して維持する必要があります。すべての更新とクエリで、両方のシステムにアクセスして同期する必要があります。
インデックスのチューニング。数百万のアイテムを含む近似最近傍(ANN)インデックスを構築するには、最適なパフォーマンスを得るために専門的な判断を行う必要があります。各インデックス ノードに保持するアイテムの数はどのくらいにするかなどです。再現率とレイテンシのバランスを取るために、クエリごとにインデックスの何パーセントをスキャンする必要がありますか?どのシャードサイズがデータセットに一致しますか?これらは、実際のプロダクトとは関係のない ML インフラストラクチャの決定です。
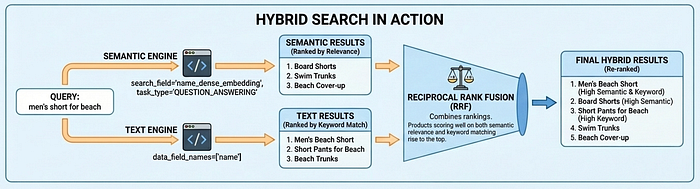
ハイブリッド検索。セマンティック検索は、ユーザーが「ビーチ用の男性用服装」と検索したときに「ボードショーツ」を見つけるなど、意図を理解することに優れています。ただし、セマンティックな意味のない「SKU-12345」のような商品コードでは失敗し、エンベディング モデルが一度も見たことのない新造語やブランド名では苦戦します。キーワード検索はこれらのケースを処理しますが、セマンティック コンテキストを見逃します。ユーザーは両方を必要としています。そのため、ハイブリッド検索が不可欠になっています。ただし、構築は簡単ではありません。ベクトル検索エンジンに加えて、トークン化、転置インデックス、スパース エンベディングを備えた全文検索エンジンが必要です。次に、両方のエンジンで並列クエリを実行し、異なるスコアリング システムを正規化して、Reciprocal Rank Fusion などの手法で結果を統合する必要があります。
ベクトル検索 2.0 でこれらの問題を解決する方法
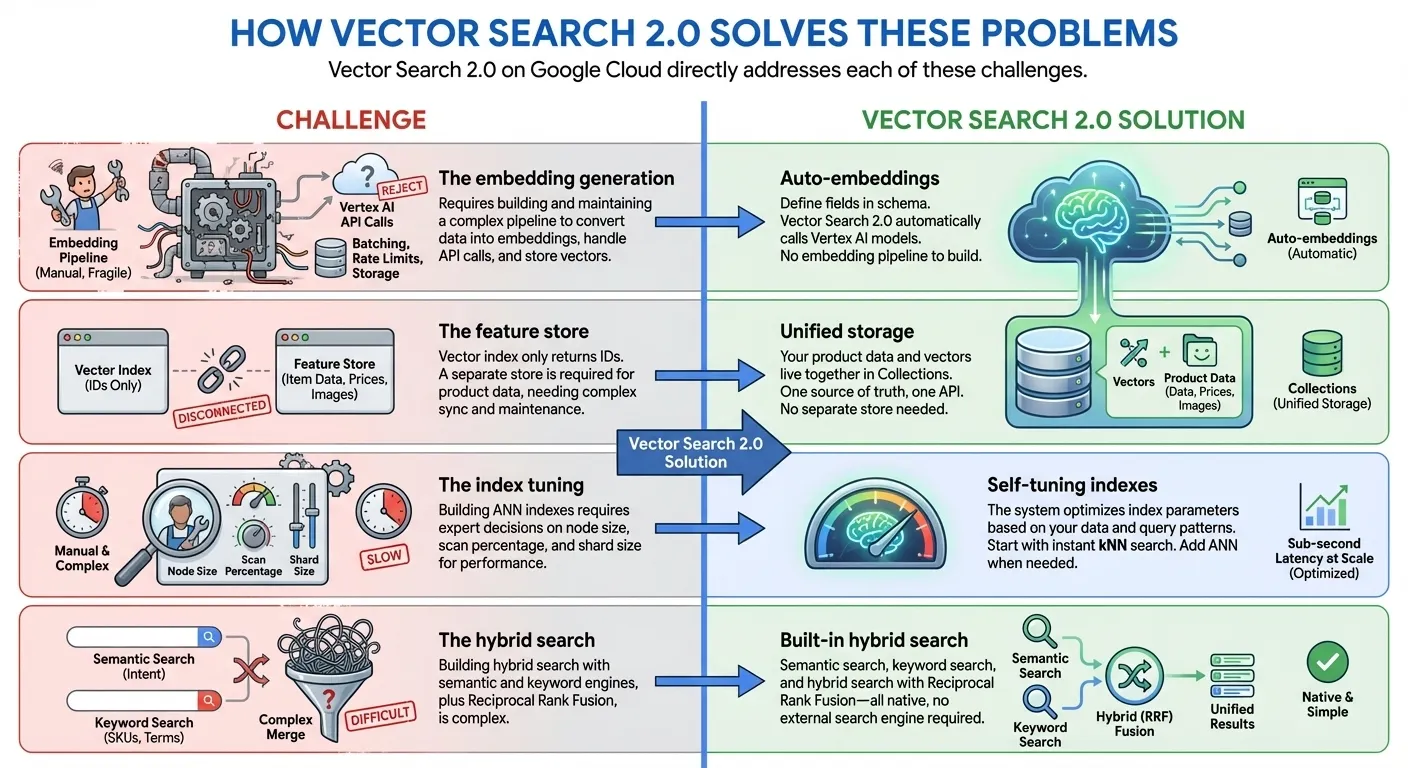
Google Cloud の Vector Search 2.0 は、これらの課題に直接対応します。

このワークショップでは、TheLook e コマース データセットの 10,000 個のファッション商品を使用して、フルマネージド ハイブリッド検索を構築します。
ベクトル検索 2.0 とは
ベクトル検索 2.0 は、Google の ScaNN(スケーラブルな最近傍)アルゴリズムに基づいて構築された、Google Cloud のフルマネージドのセルフチューニング ベクトル データベースです。これは、Google 検索、YouTube、Google Play で使用されているのと同じテクノロジーです。
主な差別化要因
- ゼロ インデックスから数十億規模のインデックス: kNN(k 近傍)を使用してインデックス作成時間をゼロにしてすぐに開発を開始し、Google 規模の ANN(近似最近傍)インデックスを使用して、同じ API と同じデータセットで、ミリ秒単位のレイテンシで数十億のベクトルにスケーリングします。
- 統合データ ストレージ: ベクトル エンベディングとユーザー提供データを一緒に保存します(個別のデータベースや特徴ストアは不要です)。
- 自動エンベディング: Vertex AI エンベディング モデルを使用してセマンティック エンベディングを自動的に生成します。
- 組み込みの全文検索: スパース エンベディングを自分で生成する必要がない、組み込みの全文検索を提供します。ベクトル検索で独自のスパース エンベディング(BM25、SPLADE など)を使用して、カスタマイズされた全文検索を行うこともできます。
- ハイブリッド検索: インテリジェントな RRF ランキングを使用して、セマンティック検索とキーワード/トークンベース検索を 1 つのクエリに統合します。
- セルフチューニング: 手動構成なしでパフォーマンスを自動最適化
- エンタープライズ対応: スケーラビリティ、セキュリティ、コンプライアンスが組み込まれています
コア アーキテクチャ
ベクトル検索 2.0 には、次の 3 つの主要コンポーネントがあります。
- コレクション: スキーマが適用されたデータ コンテナ
- データ オブジェクト: データとベクトル エンベディングを含む個々のアイテム
- インデックス: kNN を使用してデータを瞬時に最近傍検索します。低レイテンシの最近傍検索には ANN インデックスを使用します。
- すぐに開始: 設定時間なしで kNN をすぐに使用できます。開発や小規模なデータセットに最適です。
- 本番環境にスケーリングする: ScaNN アルゴリズムを活用した、10 億規模の検索に ANN インデックスを使用し、レイテンシを 1 秒未満に抑える
各コンセプトを実践的な例で見ていきましょう。
2. TheLook ファッション検索の構築
たとえば、お客様が e コマース サイトにアクセスして「ビーチ バケーションにぴったりの可愛いもの」と入力したとします。従来のキーワード検索では、カタログ内のどの商品にもこれらの単語が完全に一致していないため、検索結果はゼロになります。不満を感じたユーザーは離脱します。
別のエクスペリエンスを想像してみましょう。同じクエリで、ビーチという単語がタイトルに含まれていないにもかかわらず、お客様が思い描いていたものにぴったりの商品(サマードレス、水着のカバーアップ、ゆったりとしたショートパンツ)が返されます。ベクトル検索によって実現されるエクスペリエンスです。
Vector Search 2.0 でこれがどのように実現されるかを示すために、26 のカテゴリにわたる 30,000 点のファッション アイテムを含む現実的な e コマース データセットである TheLook を使用して、商品検索システムを構築します。各商品には、実際のカタログにある属性があります。

解決する検索の課題
実際のユーザーは、データベースが想定するような検索を行いません。ユーザーは、次のような思考で検索します。

ベクトル検索 2.0 は、統合アーキテクチャでこれら 4 つの課題をすべて解決します。
Vector Search 2.0 のデータ アーキテクチャ
コードに入る前に、Vector Search 2.0 でデータがどのように整理されるかについて説明します。このアーキテクチャは、コレクション、データ オブジェクト、インデックスという 3 つの重要なコンセプトを中心に構成されています。
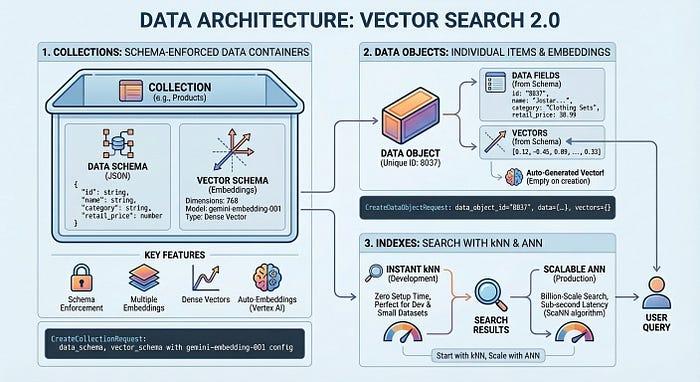
コレクションは、保存するフィールドと埋め込むフィールドなど、データ構造を定義します。データ オブジェクトは、コレクションに保存されている実際のアイテム(商品、ドキュメント、画像)です。それぞれにデータと自動生成されたベクトルまたは独自のベクトルが含まれています。インデックスはクエリを大規模に最適化し、数十億のアイテムに対してミリ秒単位のレイテンシを実現します。セットアップ時間なしで開発用のインデックスなしで開始し、本番環境のパフォーマンスが必要になったらインデックスを追加できます。
TheLook Search の構築: 手順
では、実際に動作する商品検索システムを構築してみましょう。TheLook から 10,000 個のファッション アイテムを読み込み、自動エンベディングを有効にして、セマンティック検索、キーワード検索、ハイブリッド検索を実行します。これらすべてを約 50 行のコードで実現します。
ノートブックを開く: Vertex AI Vector Search 2.0 の概要
ハイブリッド検索の活用
ベクトル検索 2.0 は、セマンティック検索(エンベディングを介して意図を理解)、テキスト検索(キーワード マッチング)、ハイブリッド検索(両方を組み合わせる)の 3 つの検索モードをサポートしています。ハイブリッド検索は、ほとんどのユースケースで最適な結果を提供します。たとえば、ユーザーが「ビーチ用のメンズ服」を検索すると、セマンティック検索で「ボードショーツ」が見つかり、テキスト検索では商品コードなどの完全一致が見つかります。
タスクタイプ エンベディングが重要な理由
上記のコードの task_type パラメータに注目してください。商品のインデックス登録時には RETRIEVAL_DOCUMENT、検索時には QUESTION_ANSWERING が指定されています。これは任意ではありません。エンベディング モデルをレコメンデーション モデルのように動作させることで、検索の品質を向上させるための重要な手法です。
ほとんどのベクトル検索のユースケースは単純な類似性マッチングに依存していますが、質問と回答がエンベディング空間で本質的に類似していないため、本番環境レベルの検索品質を提供できないことがよくあります。「ビーチでの休暇に最適なものは何ですか?」と「ボードショーツ」はセマンティクスが異なりますが、一致させる必要があります。タスクタイプのエンベディングは、非対称の関係に対してエンベディング モデルを最適化することで、この問題を解決します。ドキュメントはクエリとは異なる方法でエンベディングされ、関連する一致がクラスタリングされるエンベディング空間が作成されます。これにより、ユーザーの意図に基づいて関連するアイテムを見つける推奨機能が追加されます。
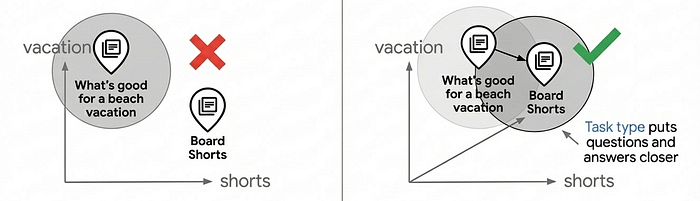
タスク固有のエンベディングを使用すると、汎用エンベディングと比較して検索品質を 30 ~ 40% 向上させることができます。この仕組みの詳細については、タスクタイプのエンベディング ノートブックをご覧ください。
ゼロから 10 億規模へ
大規模な本番環境向けに、ベクトル検索 2.0 は、Google の ScaNN(スケーラブルな最近傍)アルゴリズムを活用した ANN(近似最近傍)インデックスを提供します。これは、Google 検索、YouTube、Google Play の基盤となっているのと同じテクノロジーです。ANN は、わずかな精度(約 99%)と引き換えに、大幅な速度向上を実現します。数十億のベクトルでも 10 ミリ秒未満のレイテンシを実現します。
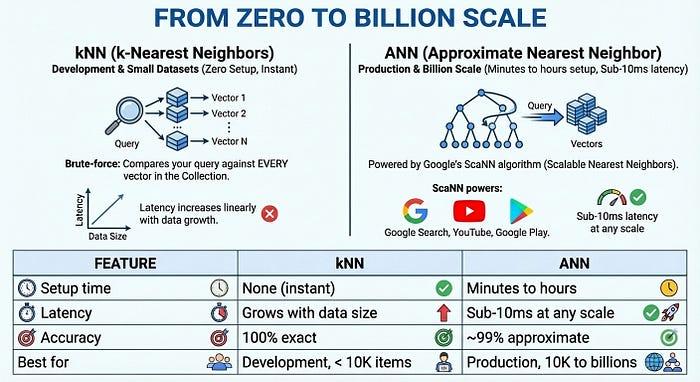
全体像
5 つのステップ(ステップ 1 ~ 4 は約 5 分で完了)で、本番環境で使用できる商品検索システムを構築しました。
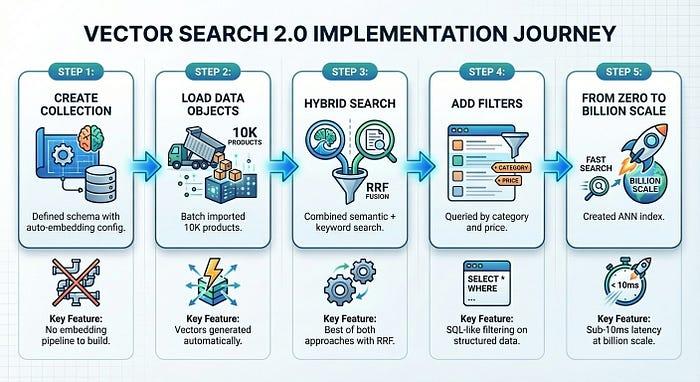
Vector Search 2.0 は、通常ベクトル検索の導入を遅らせるインフラストラクチャの複雑さを解消します。ユーザーはプロダクトに集中し、エンベディング、インデックス登録、スケーリングはプラットフォームが処理します。
3. 完了
おつかれさまです。これで、Vector Search 2.0 を使用する最初のアプリケーションを構築できました。