
1. Introdução
Última atualização:04/03/2026
A pesquisa vetorial, ou banco de dados vetorial, se tornou uma tecnologia fundamental para os sistemas modernos de IA. Ao representar dados como embeddings de alta dimensão que capturam o significado semântico, ela alimenta tudo, desde a pesquisa semântica que entende a intenção do usuário até os mecanismos de recomendação que mostram conteúdo relevante, a geração aumentada por recuperação (RAG) e os agentes de IA que fundamentam as respostas do LLM em informações reais e atualizadas. As principais empresas de tecnologia, incluindo o Google, usam essa tecnologia em grande escala para processar bilhões de pesquisas, recomendações e embasamentos diariamente.
No entanto, criar uma pesquisa vetorial pronta para produção ainda é um desafio. O Google lançou recentemente a Vertex AI Vector Search 2.0 para mudar isso. É um serviço totalmente gerenciado projetado para eliminar a complexidade operacional e de design que atrasa as equipes.

Por que a pesquisa vetorial é mais difícil do que parece
O conceito é simples. A implementação? É aí que as coisas ficam complicadas.
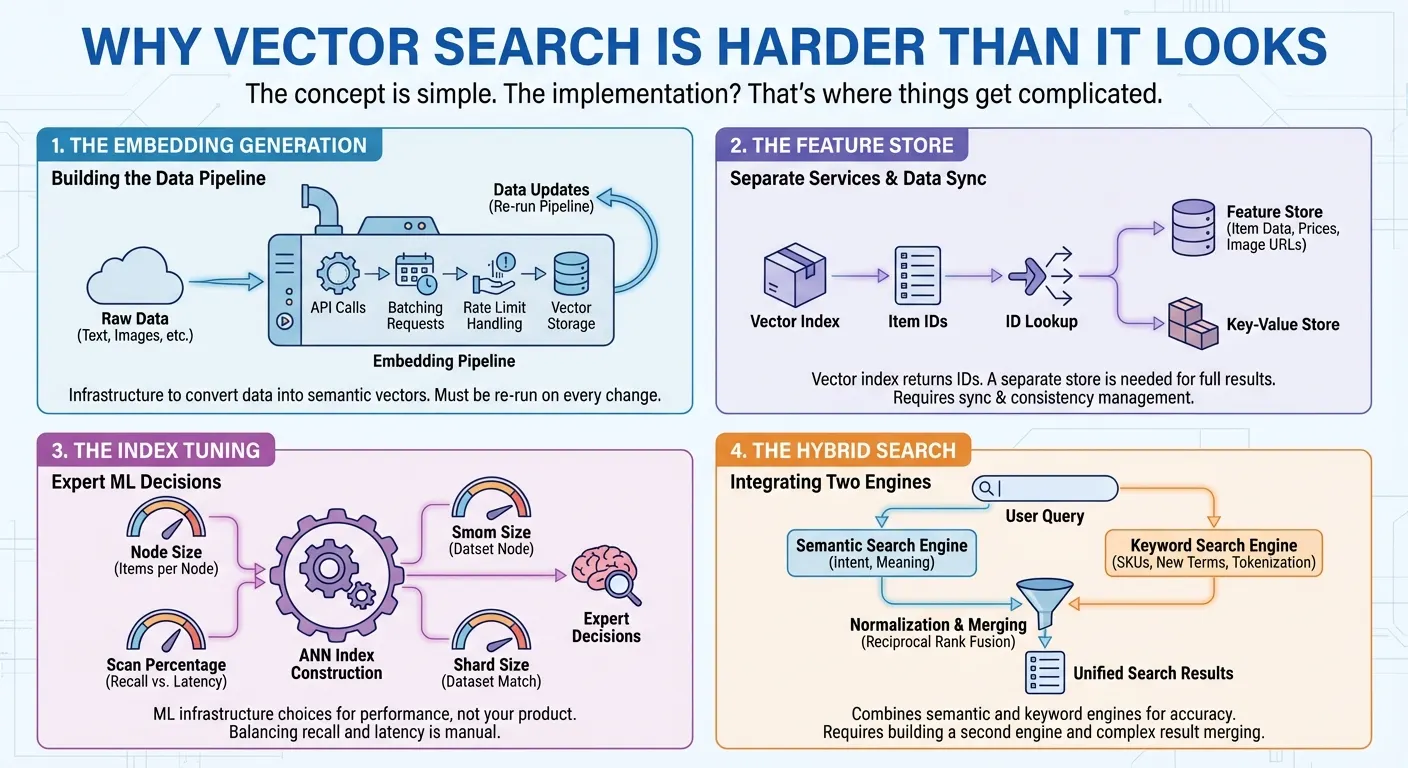
A geração de embeddings. A pesquisa de vetor exige a conversão dos dados em representações numéricas (embeddings) que capturam o significado semântico. Isso significa que você precisa chamar uma API de embedding, agrupar suas solicitações, processar limites de taxa e armazenar os vetores. Sempre que os dados mudam, você executa o pipeline novamente. É uma infraestrutura que você precisa criar antes mesmo de começar a pesquisar.
A Feature Store. Muitos produtos de pesquisa vetorial oferecem apenas um índice vetorial que retorna uma lista de IDs de itens para cada pesquisa. Para veicular resultados de pesquisa completos aos usuários, você precisa de um repositório de recursos ou um repositório de chave-valor separado para recuperar os dados reais do item (nomes, preços, categorias, URLs de imagens em milissegundos) transmitindo esses IDs. Em muitos casos, também é necessário implementar filtros complexos em recursos de itens, como preço, categoria ou disponibilidade. Isso significa criar e manter dois serviços diferentes: um para pesquisa vetorial e outro para recuperação e filtragem de dados. Toda atualização e consulta exige o acesso e a sincronização dos dois sistemas.
O ajuste do índice. Para criar índices de vizinho mais próximo aproximado (ANN) com milhões de itens, é necessário tomar decisões de especialista para ter a melhor performance: quantos itens cada nó de índice deve conter? Qual porcentagem do índice deve ser verificada por consulta para equilibrar o recall e a latência? Qual tamanho de fragmento corresponde ao seu conjunto de dados? Essas são decisões de infraestrutura de ML que não têm nada a ver com seu produto real.
A pesquisa híbrida. A pesquisa semântica é excelente para entender a intenção, encontrando "Board Shorts" quando os usuários pesquisam "roupa masculina para praia". No entanto, ele falha em códigos de produtos como "SKU-12345", que não têm significado semântico, e tem dificuldades com termos recém-criados ou nomes de marcas que o modelo de embedding nunca viu. A pesquisa por palavra-chave lida com esses casos, mas não considera o contexto semântico. Os usuários precisam dos dois, e é por isso que a pesquisa híbrida se tornou essencial. No entanto, a criação é bem complexa. Você precisa de um mecanismo de pesquisa de texto completo com tokenização, índices invertidos ou embeddings esparsos, além do seu mecanismo de pesquisa vetorial. Em seguida, execute consultas paralelas nos dois mecanismos, normalize os diferentes sistemas de pontuação e mescle os resultados com técnicas como a fusão de classificação recíproca.
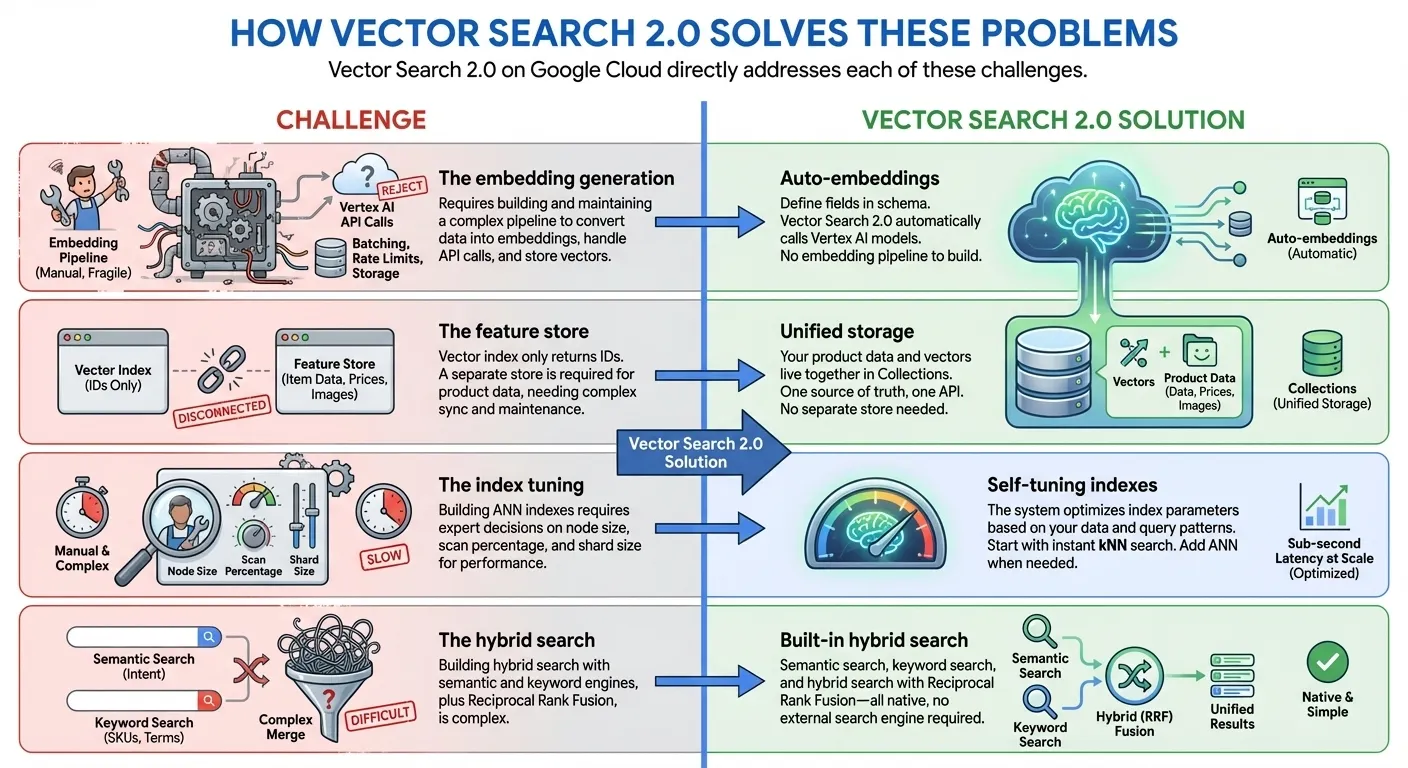
Como a Pesquisa de vetores 2.0 resolve esses problemas
A pesquisa vetorial 2.0 no Google Cloud aborda diretamente cada um desses desafios:

Neste workshop, vamos criar uma pesquisa híbrida totalmente gerenciada usando 10.000 produtos de moda do conjunto de dados de e-commerce TheLook.
O que é a Pesquisa vetorial 2.0?
A Pesquisa de vetor 2.0 é um banco de dados de vetor totalmente gerenciado e com ajuste automático do Google Cloud, criado com base no algoritmo ScaNN (Vizinhos mais próximos escalonáveis) do Google, a mesma tecnologia que alimenta a Pesquisa Google, o YouTube e o Google Play.
Principais diferenciais
- Indexação de zero a bilhões: comece a desenvolver imediatamente com tempo de indexação zero usando kNN (k-vizinhos mais próximos) e dimensione para bilhões de vetores com latência de milissegundos com índices ANN (vizinho mais próximo aproximado) em escala do Google para produção. Tudo isso com a mesma API e o mesmo conjunto de dados.
- Armazenamento unificado de dados: armazene embeddings vetoriais e dados fornecidos pelo usuário juntos. Não é necessário um banco de dados ou repositório de recursos separado.
- Embeddings automáticos: gere embeddings semânticos automaticamente usando modelos de embedding da Vertex AI.
- Pesquisa de texto completo integrada: oferece uma pesquisa de texto completo integrada sem precisar gerar embeddings esparsos por conta própria. Você também pode usar seus próprios embeddings esparsos (por exemplo, BM25, SPLADE) com a pesquisa vetorial para uma pesquisa de texto completo personalizada.
- Pesquisa híbrida: combine a pesquisa semântica e por palavra-chave/token em uma única consulta com a classificação inteligente RRF.
- Ajuste automático: desempenho otimizado automaticamente sem configuração manual
- Pronto para empresas: escalonabilidade, segurança e compliance integrados
Arquitetura principal
A pesquisa vetorial 2.0 tem três componentes principais:
- Coleções: contêineres com aplicação de esquema para seus dados
- Objetos de dados: itens individuais com dados e embeddings de vetores.
- Índices: Pesquisa instantânea de vizinhos mais próximos dos seus dados com kNN. Para pesquisa de vizinho mais próximo de baixa latência, use um índice ANN.
- Comece rápido: use o kNN imediatamente sem tempo de configuração, perfeito para desenvolvimento e conjuntos de dados pequenos.
- Escalonamento para produção: use índices ANN para pesquisa em escala de bilhões com latência inferior a um segundo usando o algoritmo ScaNN.
Vamos analisar cada conceito com exemplos práticos.
2. Como criar a pesquisa de moda do TheLook
Imagine que um cliente acessa seu site de e-commerce e digita "algo fofo para férias na praia". Com a pesquisa tradicional por palavra-chave, eles não recebem nenhum resultado porque nenhum produto no seu catálogo contém essas palavras exatas. Frustradas, elas vão embora.
Agora imagine uma experiência diferente. A mesma consulta retorna vestidos de verão, saídas de praia e shorts soltos, produtos que correspondem perfeitamente ao que o cliente tinha em mente, mesmo que nenhum deles contenha a palavra "praia" nos títulos. Essa é a experiência que a pesquisa vetorial oferece.
Para demonstrar como a pesquisa vetorial 2.0 torna isso possível, vamos criar um sistema de pesquisa de produtos usando o TheLook, um conjunto de dados de e-commerce realista com 30 mil itens de moda em 26 categorias. Cada produto tem atributos que você encontraria em qualquer catálogo real:

Os desafios de pesquisa que vamos resolver
Os clientes reais não pesquisam da maneira que os bancos de dados esperam. Elas pesquisam da maneira como pensam:

A Pesquisa vetorial 2.0 resolve todos os quatro desafios com uma arquitetura unificada.
Arquitetura de dados da Pesquisa vetorial 2.0
Antes de começar a programar, vamos entender como a pesquisa de vetor 2.0 organiza seus dados. A arquitetura se concentra em três conceitos principais: coleções, objetos de dados e índices.
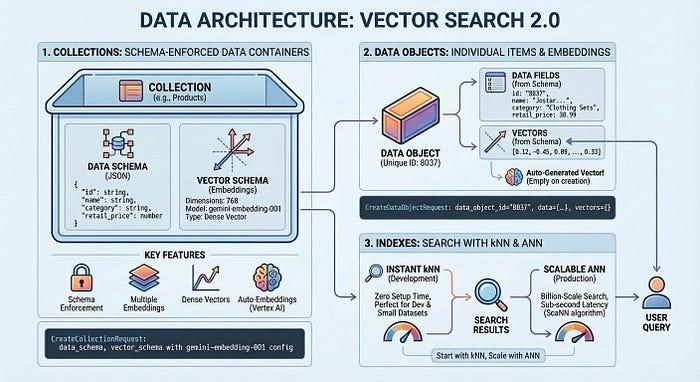
Uma coleção define sua estrutura de dados: os campos que você quer armazenar e quais devem ser incorporados. Os objetos de dados são os itens reais (produtos, documentos, imagens) armazenados em uma coleção, cada um com seus dados e vetores gerados automaticamente ou seus próprios vetores. Um índice otimiza consultas em grande escala, permitindo latência de milissegundos em bilhões de itens. Você pode começar sem um índice para desenvolvimento com tempo de configuração zero e adicionar um quando precisar de desempenho de produção.
Como criar a pesquisa do TheLook: passo a passo
Agora vamos criar um sistema de pesquisa de produtos funcional. Vamos carregar 10.000 itens de moda da TheLook, ativar os encodings automáticos e executar pesquisas semânticas, de palavras-chave e híbridas. Tudo isso em cerca de 50 linhas de código.
Abra o notebook: Introdução à pesquisa de vetor da Vertex AI 2.0
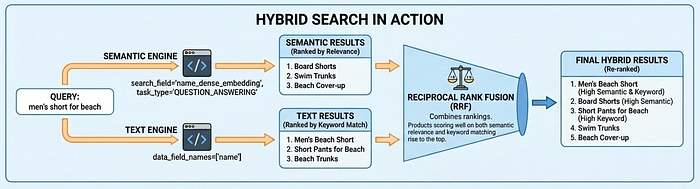
Pesquisa híbrida em ação
A pesquisa vetorial 2.0 oferece suporte a três modos de pesquisa: semântica (entende a intenção por embeddings), de texto (correspondência de palavras-chave) e híbrida (combina os dois). A pesquisa híbrida oferece os melhores resultados para a maioria dos casos de uso. A pesquisa semântica encontra "Board Shorts" quando os usuários pesquisam "roupa masculina para praia", enquanto a pesquisa de texto garante que correspondências exatas, como códigos de produtos, não sejam perdidas.
Por que as incorporações de tipo de tarefa são importantes
Observe os parâmetros "task_type" no código acima: "RETRIEVAL_DOCUMENT" ao indexar produtos e "QUESTION_ANSWERING" ao pesquisar. Isso não é arbitrário. É uma técnica fundamental para melhorar a qualidade da pesquisa, permitindo que o modelo de embedding funcione como um modelo de recomendação.
A maioria dos casos de uso de pesquisa vetorial depende de uma correspondência de similaridade simples, mas isso geralmente não oferece uma qualidade de pesquisa de nível de produção porque as perguntas e respostas não são inerentemente semelhantes no espaço de embedding. "O que é bom para férias na praia?" e "Board Shorts" têm semânticas diferentes, mas precisam corresponder. Os embeddings de tipo de tarefa resolvem isso otimizando o modelo de embedding para relações assimétricas: os documentos são incorporados de maneira diferente das consultas, criando um espaço de embedding em que as correspondências relevantes se agrupam, adicionando a capacidade de recomendação, encontrando itens relevantes com base na intenção do usuário.
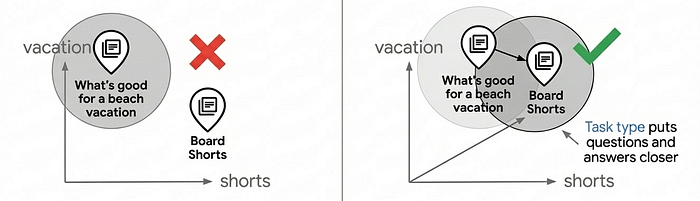
O uso de embeddings específicos para tarefas pode melhorar a qualidade da pesquisa em 30 a 40% em comparação com embeddings genéricos. Para saber mais sobre como isso funciona, consulte o notebook de incorporação de tipo de tarefa.
Do zero à escala de bilhões
Para produção em grande escala, a Pesquisa de vetor 2.0 oferece índices ANN (vizinho mais próximo aproximado) com tecnologia do algoritmo ScaNN (vizinhos mais próximos escalonáveis) do Google, a mesma tecnologia da Pesquisa Google, do YouTube e do Google Play. A ANN troca uma pequena quantidade de precisão (~99%) por ganhos de velocidade enormes: latência inferior a 10 ms, mesmo com bilhões de vetores.
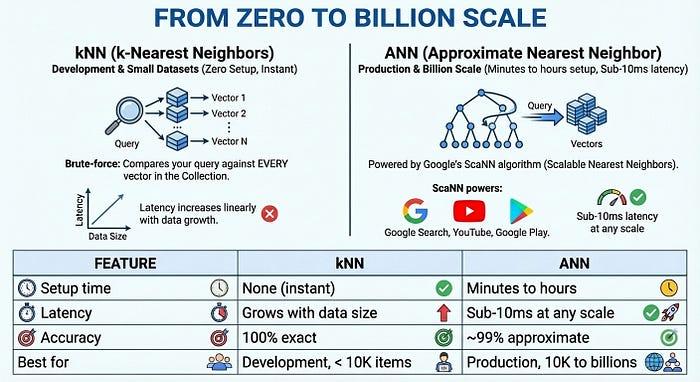
The Complete Picture (em inglês)
Em apenas cinco etapas, sendo que as etapas de 1 a 4 levam apenas 5 minutos, criamos um sistema de pesquisa de produtos pronto para produção:
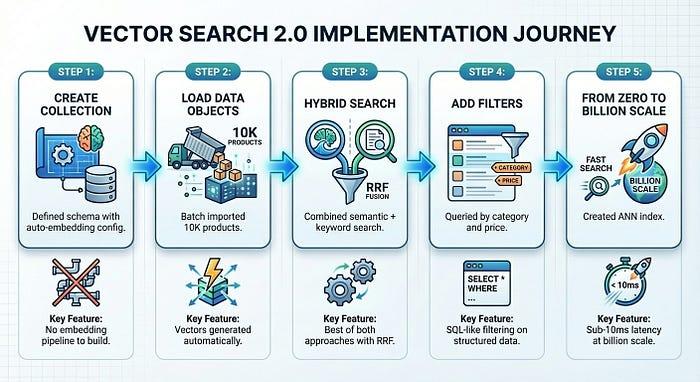
A pesquisa vetorial 2.0 elimina a complexidade da infraestrutura que normalmente retarda a adoção da pesquisa vetorial. Você se concentra no produto, e a plataforma cuida de incorporações, indexação e escalonamento.
3. Parabéns
Parabéns! Você criou seu primeiro aplicativo com a pesquisa vetorial 2.0.