
1. บทนำ
อัปเดตล่าสุด: 04-03-2026
การค้นหาเวกเตอร์หรือฐานข้อมูลเวกเตอร์กลายเป็นเทคโนโลยีพื้นฐานสำหรับระบบ AI สมัยใหม่ การแสดงข้อมูลเป็น Embedding แบบหลายมิติที่บันทึกความหมายเชิงความหมายจะขับเคลื่อนทุกอย่างตั้งแต่การค้นหาเชิงความหมายที่เข้าใจเจตนาของผู้ใช้ ไปจนถึงเครื่องมือแนะนำที่แสดงเนื้อหาที่เกี่ยวข้อง รวมถึงการสร้างแบบดึงข้อมูล (RAG) และเอเจนต์ AI ที่ยึดโยงคำตอบของ LLM กับข้อมูลจริงที่เป็นปัจจุบัน บริษัทเทคโนโลยีรายใหญ่ๆ รวมถึง Google ต่างก็ใช้เทคโนโลยีนี้ในวงกว้างเพื่อประมวลผลการค้นหา คำแนะนำ และการอ้างอิงหลายพันล้านรายการในแต่ละวัน
แต่การสร้างการค้นหาเวกเตอร์ที่พร้อมใช้งานจริงยังคงเป็นเรื่องที่ท้าทาย เมื่อเร็วๆ นี้ Google ได้เปิดตัว Vertex AI Vector Search 2.0 เพื่อเปลี่ยนแปลงสิ่งดังกล่าว ซึ่งเป็นบริการที่มีการจัดการเต็มรูปแบบที่ออกแบบมาเพื่อขจัดความซับซ้อนในการออกแบบและการปฏิบัติงานที่ทำให้ทีมทำงานช้าลง

เหตุใดการค้นหาเวกเตอร์จึงยากกว่าที่คิด
แนวคิดนี้เรียบง่าย การติดตั้งใช้งาน ซึ่งตรงนี้เองที่ทำให้เรื่องราวซับซ้อนขึ้น
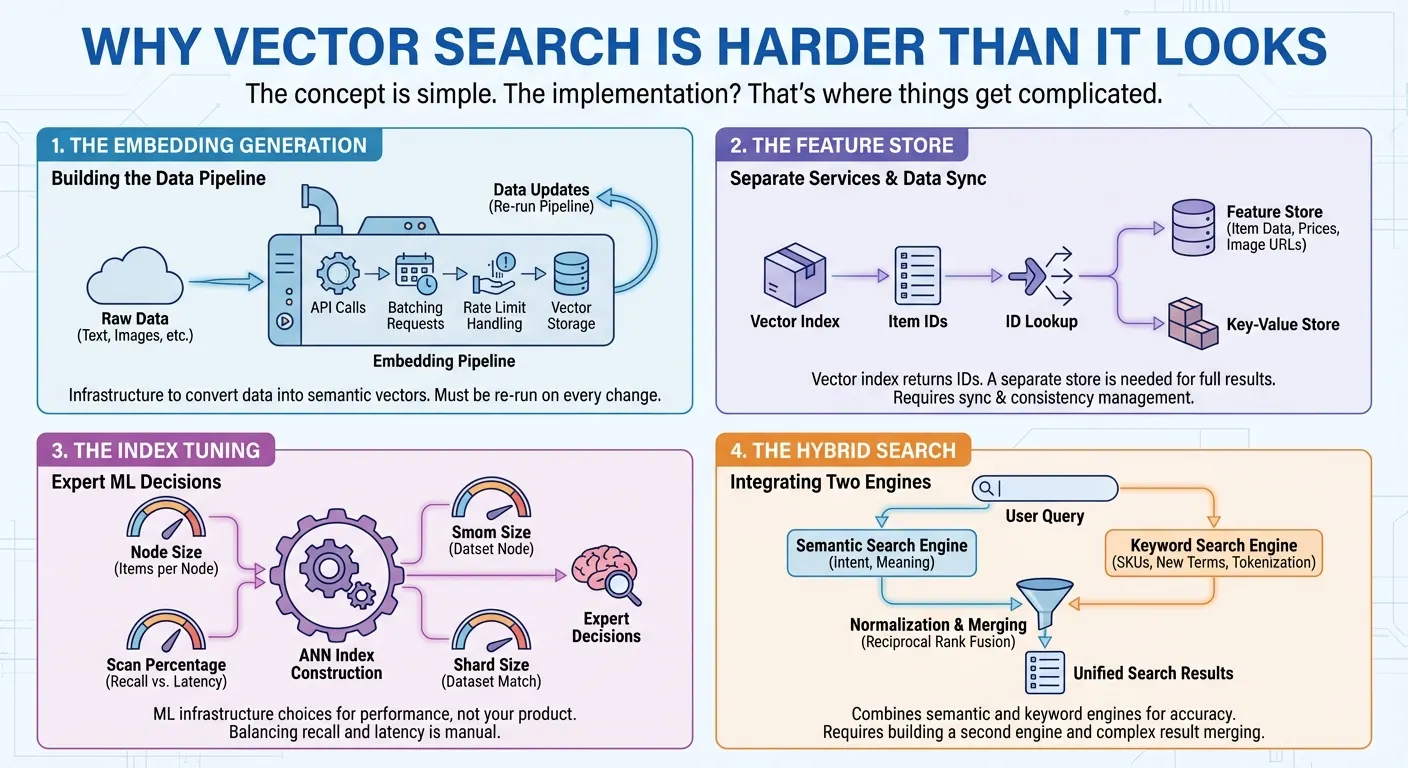
การสร้างการฝัง การค้นหาเวกเตอร์ต้องแปลงข้อมูลเป็นตัวแทนเชิงตัวเลข (การฝัง) ที่จับความหมายเชิงความหมาย ซึ่งหมายความว่าคุณต้องเรียกใช้ Embedding API จัดกลุ่มคำขอ จัดการขีดจำกัดอัตรา และจัดเก็บเวกเตอร์ ทุกครั้งที่ข้อมูลมีการเปลี่ยนแปลง คุณจะต้องเรียกใช้ไปป์ไลน์อีกครั้ง ซึ่งเป็นโครงสร้างพื้นฐานที่คุณต้องสร้างก่อนจึงจะเริ่มค้นหาได้
ร้านค้าฟีเจอร์ ผลิตภัณฑ์ Vector Search หลายรายการมีเฉพาะดัชนีเวกเตอร์ที่แสดงผลรายการรหัสสินค้าสำหรับการค้นหาแต่ละครั้ง หากต้องการแสดงผลการค้นหาทั้งหมดต่อผู้ใช้ คุณต้องมีที่เก็บฟีเจอร์หรือที่เก็บคีย์-ค่าแยกต่างหากเพื่อดึงข้อมูลรายการจริง เช่น ชื่อ ราคา หมวดหมู่ และ URL ของรูปภาพในหน่วยมิลลิวินาที โดยการส่งรหัสเหล่านั้น ในหลายกรณี คุณยังต้องใช้การกรองที่ซับซ้อนกับฟีเจอร์ของสินค้า เช่น ราคา หมวดหมู่ หรือความพร้อมจำหน่ายสินค้าด้วย ซึ่งหมายถึงการสร้างและบำรุงรักษาบริการ 2 อย่างที่แตกต่างกัน ได้แก่ บริการค้นหาเวกเตอร์ และบริการดึงข้อมูลและการกรอง การอัปเดตและคำค้นหาทุกรายการต้องมีการเข้าถึงและซิงค์ทั้ง 2 ระบบ
การปรับดัชนี หากต้องการสร้างดัชนีเพื่อนบ้านที่ใกล้ที่สุดโดยประมาณ (ANN) ที่มีสินค้าหลายล้านรายการ คุณต้องตัดสินใจอย่างผู้เชี่ยวชาญเพื่อให้ได้ประสิทธิภาพที่ดีที่สุด เช่น โหนดดัชนีแต่ละโหนดควรมีสินค้ากี่รายการ ควรสแกนดัชนีเป็นกี่เปอร์เซ็นต์ต่อการค้นหาเพื่อรักษาสมดุลระหว่างการเรียกคืนกับเวลาในการตอบสนอง ขนาด Shard ใดที่ตรงกับชุดข้อมูลของคุณ การตัดสินใจเกี่ยวกับโครงสร้างพื้นฐานของ ML เหล่านี้ไม่เกี่ยวข้องกับผลิตภัณฑ์จริงของคุณ
การค้นหาแบบผสม การค้นหาเชิงความหมายมีความโดดเด่นในด้านการทำความเข้าใจเจตนา ซึ่งก็คือการค้นหา "กางเกงขาสั้น" เมื่อผู้ใช้ค้นหา "ชุดผู้ชายสำหรับชายหาด" แต่จะทำงานไม่สำเร็จกับรหัสผลิตภัณฑ์ เช่น "SKU-12345" ที่ไม่มีความหมายเชิงความหมาย และทำงานได้ไม่ดีกับคำที่เพิ่งสร้างขึ้นใหม่หรือชื่อแบรนด์ที่โมเดลการฝังไม่เคยเห็น การค้นหาคีย์เวิร์ดจะจัดการกรณีเหล่านี้ได้ แต่พลาดบริบทเชิงความหมาย ผู้ใช้ต้องการทั้ง 2 อย่าง จึงทำให้การค้นหาแบบไฮบริดกลายเป็นสิ่งจำเป็น แต่การสร้างนั้นไม่ใช่เรื่องง่าย คุณต้องมีเครื่องมือค้นหาแบบข้อความแบบเต็มที่มีการสร้างโทเค็น ดัชนีผกผัน หรือการฝังแบบกระจัดกระจาย นอกเหนือจากเครื่องมือค้นหาเวกเตอร์ จากนั้นคุณต้องเรียกใช้การค้นหาแบบขนานในทั้ง 2 เครื่องมือ ปรับระบบการให้คะแนนที่แตกต่างกันให้เป็นมาตรฐาน และผสานผลลัพธ์ด้วยเทคนิคต่างๆ เช่น Reciprocal Rank Fusion
Vector Search 2.0 แก้ปัญหาเหล่านี้ได้อย่างไร
Vector Search 2.0 ใน Google Cloud ช่วยแก้ปัญหาแต่ละอย่างเหล่านี้ได้โดยตรง

ในเวิร์กช็อปนี้ เราจะสร้างการค้นหาแบบไฮบริดที่มีการจัดการเต็มรูปแบบโดยใช้ผลิตภัณฑ์แฟชั่น 10,000 รายการจากชุดข้อมูลอีคอมเมิร์ซ TheLook
การค้นหาเวกเตอร์ 2.0 คืออะไร
Vector Search 2.0 คือฐานข้อมูลเวกเตอร์ที่จัดการด้วยตนเองและมีการจัดการโดยสมบูรณ์ของ Google Cloud ซึ่งสร้างขึ้นจากอัลกอริทึม ScaNN (Scalable Nearest Neighbors) ของ Google ซึ่งเป็นเทคโนโลยีเดียวกันกับที่ขับเคลื่อน Google Search, YouTube และ Google Play
จุดสร้างความแตกต่างที่สำคัญ
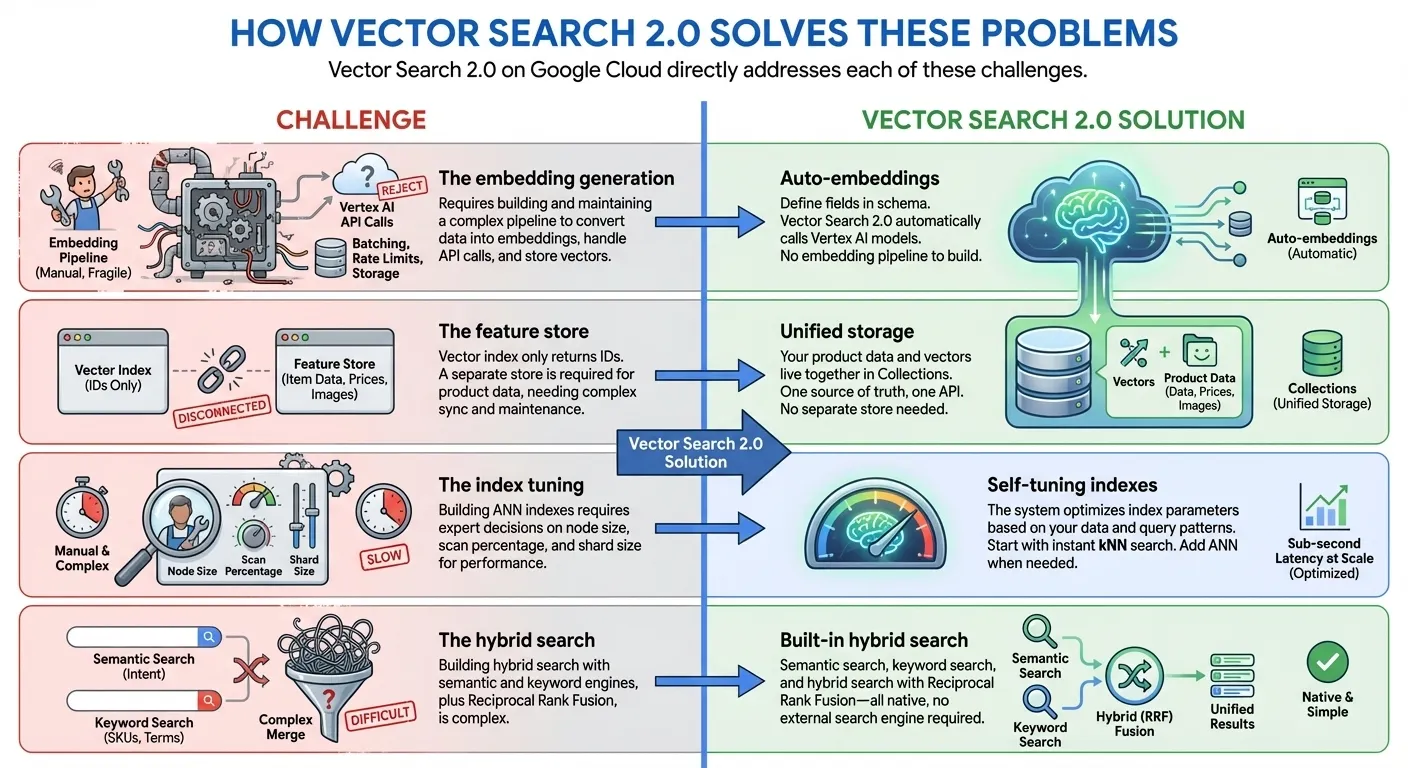
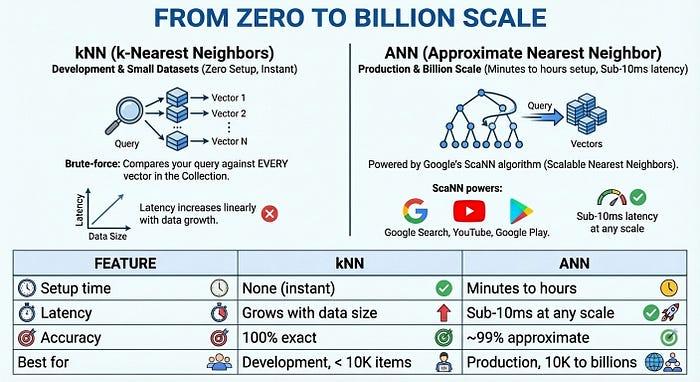
- การจัดทำดัชนีตั้งแต่ 0 ไปจนถึงระดับพันล้าน: เริ่มพัฒนาได้ทันทีโดยไม่ต้องรอเวลาจัดทำดัชนีด้วย kNN (k-Nearest Neighbors) จากนั้นขยายขนาดเป็นเวกเตอร์หลายพันล้านรายการโดยมีเวลาในการตอบสนองเป็นมิลลิวินาทีด้วยดัชนี ANN (Approximate Nearest Neighbor) ระดับ Google สำหรับการใช้งานจริง ทั้งหมดนี้ใช้ API และชุดข้อมูลเดียวกัน
- ที่เก็บข้อมูลแบบรวม: จัดเก็บทั้งการฝังเวกเตอร์และข้อมูลที่ได้จากผู้ใช้ไว้ด้วยกัน (ไม่จำเป็นต้องมีฐานข้อมูลหรือที่เก็บฟีเจอร์แยกต่างหาก)
- การฝังอัตโนมัติ: สร้างการฝังเชิงความหมายโดยอัตโนมัติโดยใช้โมเดลการฝังของ Vertex AI
- การค้นหาข้อความแบบเต็มในตัว: มีการค้นหาข้อความแบบเต็มในตัวโดยไม่ต้องสร้างการฝังแบบกระจัดกระจายด้วยตนเอง นอกจากนี้ คุณยังเลือกใช้การฝังแบบกระจัดกระจายของคุณเอง (เช่น BM25, SPLADE) กับการค้นหาแบบเวกเตอร์เพื่อการค้นหาแบบเต็มข้อความที่กำหนดเองได้ด้วย
- การค้นหาแบบไฮบริด: รวมการค้นหาตามความหมายและการค้นหาตามคีย์เวิร์ด/โทเค็นไว้ในการค้นหาเดียวด้วยการจัดอันดับ RRF อัจฉริยะ
- การปรับแต่งด้วยตนเอง: ประสิทธิภาพที่เพิ่มประสิทธิภาพอัตโนมัติโดยไม่ต้องกำหนดค่าด้วยตนเอง
- พร้อมใช้งานในระดับองค์กร: ความสามารถในการปรับขนาด การรักษาความปลอดภัย และการปฏิบัติตามข้อกำหนดที่มีให้ในตัว
สถาปัตยกรรมหลัก
Vector Search 2.0 มีองค์ประกอบหลัก 3 ส่วน ได้แก่
- คอลเล็กชัน: คอนเทนเนอร์ที่บังคับใช้สคีมาสำหรับข้อมูล
- ออบเจ็กต์ข้อมูล: รายการแต่ละรายการที่มีข้อมูลและการฝังเวกเตอร์
- ดัชนี: ค้นหาเพื่อนบ้านที่ใกล้ที่สุดในข้อมูลของคุณทันทีด้วย kNN สำหรับการค้นหาเพื่อนบ้านที่ใกล้ที่สุดที่มีเวลาในการตอบสนองต่ำ ให้ใช้ดัชนี ANN
- เริ่มต้นอย่างรวดเร็ว: ใช้ kNN ได้ทันทีโดยไม่ต้องตั้งค่า ซึ่งเหมาะอย่างยิ่งสำหรับการพัฒนาและชุดข้อมูลขนาดเล็ก
- ปรับขนาดเพื่อการใช้งานจริง: ใช้ดัชนี ANN สำหรับการค้นหาขนาดหลายพันล้านรายการที่มีเวลาในการตอบสนองต่ำกว่า 1 วินาทีซึ่งขับเคลื่อนโดยอัลกอริทึม ScaNN
มาดูแนวคิดแต่ละอย่างพร้อมตัวอย่างการใช้งานจริงกัน
2. การสร้างการค้นหาแฟชั่นของ TheLook
ลองนึกภาพว่าลูกค้าเข้าสู่เว็บไซต์อีคอมเมิร์ซของคุณและพิมพ์ว่า "ชุดน่ารักๆ สำหรับทริปเที่ยวชายหาด" การค้นหาคีย์เวิร์ดแบบเดิมจะไม่มีผลการค้นหาเลย เนื่องจากไม่มีผลิตภัณฑ์ในแคตตาล็อกที่มีคำเหล่านั้นตรงกันทุกประการ และรู้สึกหงุดหงิดจนออกจากเว็บไซต์
ทีนี้ลองนึกถึงประสบการณ์การใช้งานที่แตกต่างออกไป คำค้นหาเดียวกันจะแสดงชุดเดรสชายหาด ชุดว่ายน้ำ และกางเกงขาสั้นแบบพลิ้ว ซึ่งเป็นผลิตภัณฑ์ที่ตรงกับสิ่งที่ลูกค้าต้องการอย่างสมบูรณ์แบบ แม้ว่าจะไม่มีคำว่า "ชายหาด" ในชื่อก็ตาม นั่นคือประสบการณ์ที่การค้นหาเวกเตอร์ช่วยให้ทำได้
เพื่อแสดงให้เห็นว่า Vector Search 2.0 ช่วยให้สิ่งนี้เป็นไปได้อย่างไร เราจะสร้างระบบค้นหาสินค้าโดยใช้ TheLook ซึ่งเป็นชุดข้อมูลอีคอมเมิร์ซที่สมจริงซึ่งมีสินค้าแฟชั่น 30,000 รายการใน 26 หมวดหมู่ ผลิตภัณฑ์แต่ละรายการมีแอตทริบิวต์ที่คุณจะเห็นในแคตตาล็อกจริง

ความท้าทายด้านการค้นหาที่เราจะแก้ไข
ลูกค้าจริงไม่ได้ค้นหาในแบบที่ฐานข้อมูลคาดหวัง โดยผู้ใช้จะค้นหาตามที่คิด ดังนี้

Vector Search 2.0 แก้ปัญหาทั้ง 4 ประการด้วยสถาปัตยกรรมแบบรวม
สถาปัตยกรรมข้อมูลการค้นหาเวกเตอร์ 2.0
ก่อนที่จะเจาะลึกเรื่องโค้ด เรามาทำความเข้าใจวิธีที่ Vector Search 2.0 จัดระเบียบข้อมูลกันก่อน สถาปัตยกรรมนี้มีแนวคิดหลัก 3 ประการ ได้แก่ คอลเล็กชัน ออบเจ็กต์ข้อมูล และดัชนี
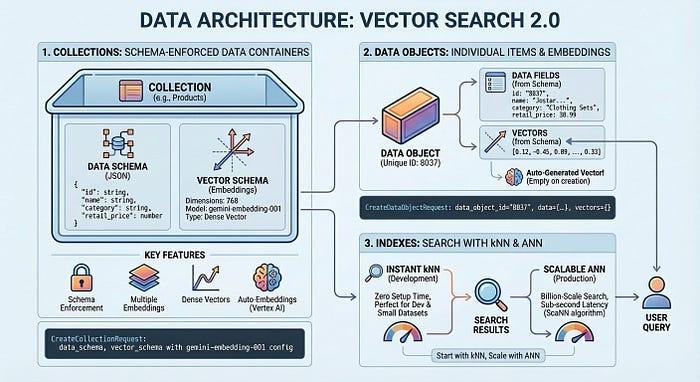
คอลเล็กชันจะกำหนดโครงสร้างข้อมูลของคุณ ซึ่งก็คือฟิลด์ที่ต้องการจัดเก็บและฟิลด์ที่ควรฝัง ออบเจ็กต์ข้อมูลคือรายการจริง (ผลิตภัณฑ์ เอกสาร รูปภาพ) ที่จัดเก็บไว้ในคอลเล็กชัน โดยแต่ละรายการจะมีข้อมูลและเวกเตอร์ที่สร้างขึ้นโดยอัตโนมัติหรือเวกเตอร์ของคุณเอง ดัชนีจะเพิ่มประสิทธิภาพการค้นหาในวงกว้าง ทำให้เกิดเวลาในการตอบสนองระดับมิลลิวินาทีในรายการหลายพันล้านรายการ คุณสามารถเริ่มต้นได้โดยไม่ต้องมีดัชนีสำหรับการพัฒนาโดยไม่ต้องเสียเวลาในการตั้งค่า จากนั้นจึงเพิ่มดัชนีเมื่อต้องการประสิทธิภาพการทำงานจริง
การสร้างการค้นหาด้วย TheLook: ทีละขั้นตอน
ตอนนี้มาสร้างระบบค้นหาผลิตภัณฑ์ที่ใช้งานได้กัน เราจะโหลดสินค้าแฟชั่น 10,000 รายการจาก TheLook เปิดใช้การฝังอัตโนมัติ และเรียกใช้การค้นหาเชิงความหมาย คีย์เวิร์ด และแบบผสม ทั้งหมดนี้ใช้โค้ดประมาณ 50 บรรทัด
เปิด Notebook: Introduction to Vertex AI Vector Search 2.0
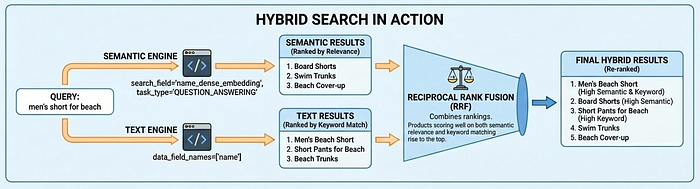
การค้นหาแบบผสมผสานในการใช้งานจริง
Vector Search 2.0 รองรับโหมดการค้นหา 3 โหมด ได้แก่ การค้นหาเชิงความหมาย (เข้าใจความตั้งใจผ่านการฝัง) การค้นหาข้อความ (การทำงานของคีย์เวิร์ด) และการค้นหาแบบไฮบริด (รวมทั้ง 2 อย่าง) การค้นหาแบบไฮบริดให้ผลลัพธ์ที่ดีที่สุดสำหรับกรณีการใช้งานส่วนใหญ่ โดยการค้นหาเชิงความหมายจะค้นหา "กางเกงขาสั้น" เมื่อผู้ใช้ค้นหา "ชุดผู้ชายสำหรับชายหาด" ขณะที่การค้นหาข้อความจะช่วยให้มั่นใจได้ว่าจะไม่พลาดผลการค้นหาที่ตรงกันทุกประการ เช่น รหัสผลิตภัณฑ์
เหตุใดการฝังประเภทงานจึงมีความสำคัญ
โปรดสังเกตพารามิเตอร์ task_type ในโค้ดด้านบน ซึ่งคือ RETRIEVAL_DOCUMENT เมื่อจัดทำดัชนีผลิตภัณฑ์ และ QUESTION_ANSWERING เมื่อค้นหา การดำเนินการนี้ไม่ได้เกิดขึ้นโดยพลการ แต่เป็นเทคนิคสำคัญในการปรับปรุงคุณภาพการค้นหาด้วยการทำให้โมเดลการฝังทำงานเหมือนโมเดลคำแนะนำ
กรณีการใช้งานการค้นหาเวกเตอร์ส่วนใหญ่จะอาศัยการจับคู่ความคล้ายคลึงอย่างง่าย แต่การจับคู่ดังกล่าวมักให้คุณภาพการค้นหาระดับการผลิตไม่ได้ เนื่องจากคำถามและคำตอบไม่ได้มีความคล้ายคลึงกันโดยธรรมชาติในพื้นที่การฝัง "What's good for a beach vacation?" และ "Board Shorts" มีความหมายที่แตกต่างกัน แต่ควรตรงกัน การฝังประเภทงานช่วยแก้ปัญหานี้ด้วยการเพิ่มประสิทธิภาพโมเดลการฝังสำหรับความสัมพันธ์ที่ไม่สมมาตร โดยฝังเอกสารแตกต่างจากคำค้นหา ซึ่งจะสร้างพื้นที่การฝังที่รายการที่เกี่ยวข้องจะรวมกันเป็นกลุ่ม ซึ่งจะเพิ่มความสามารถในการแนะนำและค้นหารายการที่เกี่ยวข้องตามความตั้งใจของผู้ใช้
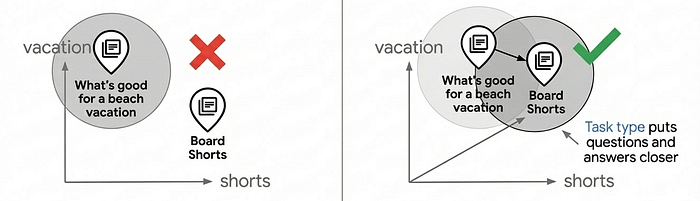
การใช้การฝังเฉพาะงานจะช่วยปรับปรุงคุณภาพการค้นหาได้ 30-40% เมื่อเทียบกับการฝังทั่วไป ดูรายละเอียดเกี่ยวกับวิธีการทำงานนี้ได้ที่สมุดบันทึกการฝังประเภทงาน
จากศูนย์สู่ระดับพันล้าน
สำหรับการใช้งานจริงในวงกว้าง Vector Search 2.0 มีดัชนี ANN (Approximate Nearest Neighbor) ที่ขับเคลื่อนโดยอัลกอริทึม ScaNN (Scalable Nearest Neighbors) ของ Google ซึ่งเป็นเทคโนโลยีเดียวกันที่อยู่เบื้องหลัง Google Search, YouTube และ Google Play ANN แลกเปลี่ยนความแม่นยำเพียงเล็กน้อย (~99%) กับความเร็วที่เพิ่มขึ้นอย่างมาก โดยมีเวลาในการตอบสนองต่ำกว่า 10 มิลลิวินาทีแม้จะมีเวกเตอร์หลายพันล้านรายการ
ภาพรวม
เราสร้างระบบค้นหาผลิตภัณฑ์ที่พร้อมใช้งานจริงได้ใน 5 ขั้นตอน โดยขั้นตอนที่ 1-4 ใช้เวลาเพียงประมาณ 5 นาที
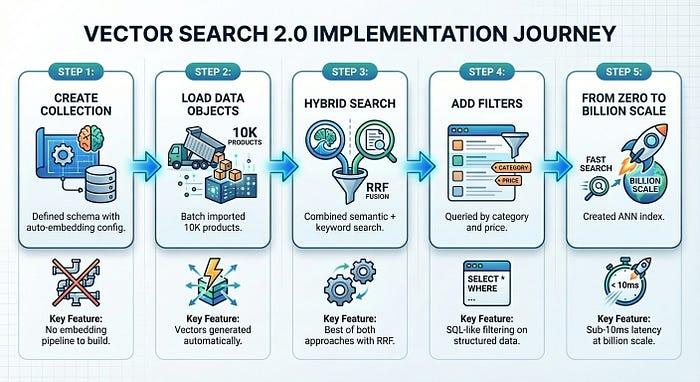
Vector Search 2.0 ช่วยลดความซับซ้อนของโครงสร้างพื้นฐานซึ่งมักจะทำให้การนำ Vector Search มาใช้ช้าลง คุณมุ่งเน้นที่ผลิตภัณฑ์ ส่วนแพลตฟอร์มจะจัดการการฝัง การจัดทำดัชนี และการปรับขนาด
3. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างแอปพลิเคชันแรกด้วยการค้นหาเวกเตอร์ 2.0 ได้สำเร็จแล้ว