
1. 簡介
上次更新時間:2026 年 3 月 4 日
向量搜尋或向量資料庫已成為現代 AI 系統的基礎技術。將資料表示為擷取語意的高維度嵌入,可支援各種功能,包括瞭解使用者意圖的語意搜尋、顯示相關內容的推薦引擎、檢索增強生成 (RAG) 和 AI 代理程式,以及以真實且最新的資訊為基礎生成 LLM 回覆。包括 Google 在內的主要科技公司,每天都會大規模運用這項技術,處理數十億筆搜尋、建議和基礎資料。
不過,建構可用於正式環境的向量搜尋仍是一大挑戰。為解決這個問題,Google 最近發布了 Vertex AI Vector Search 2.0,這項全代管服務可消除設計和運作上的複雜性,讓團隊不再受到阻礙。

向量搜尋比想像中更困難
概念很簡單,實作方式?這時情況就會變得複雜。
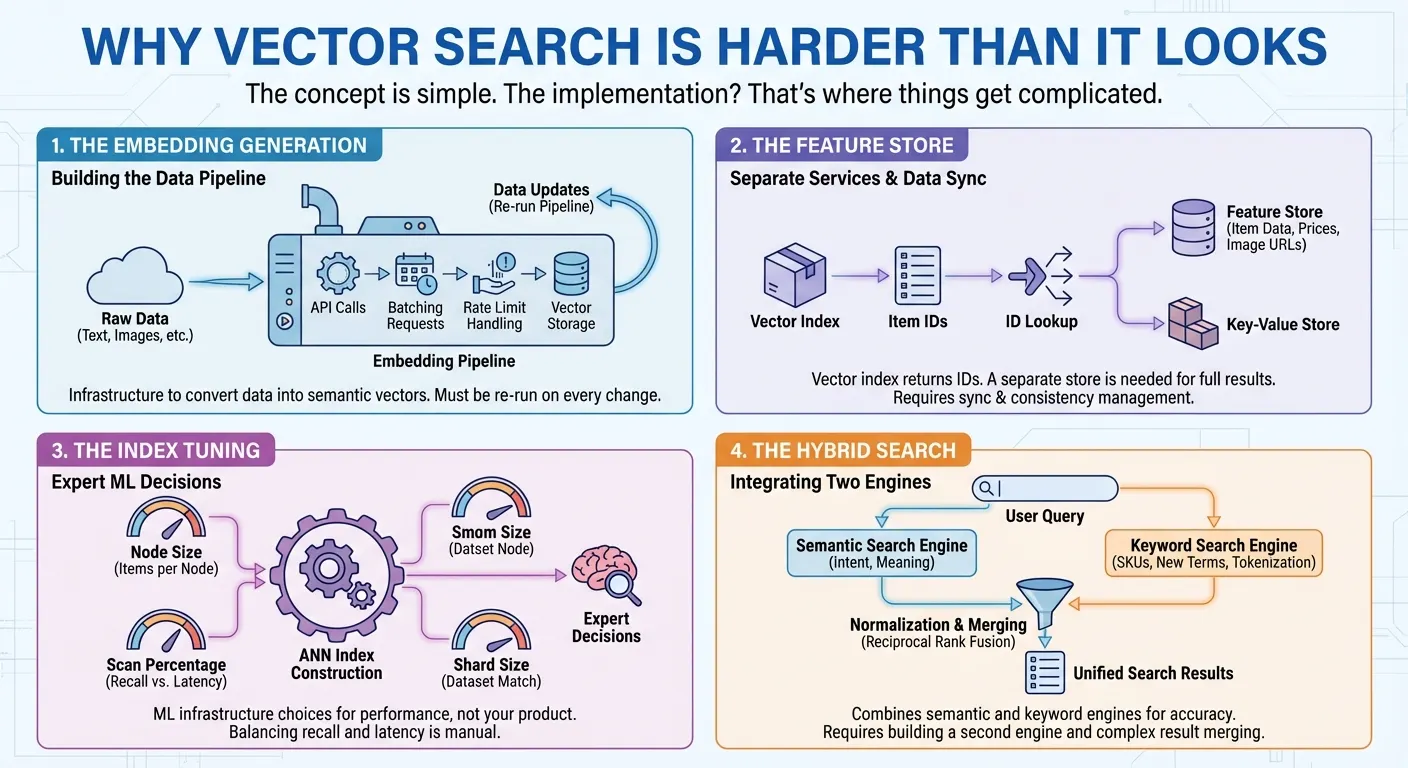
生成嵌入。向量搜尋需要將資料轉換為數值表示法 (嵌入),藉此掌握語意。也就是說,您需要呼叫 Embedding API、批次處理要求、處理速率限制,以及儲存向量。每次資料變更時,您都會重新執行管道。您必須先建構基礎架構,才能開始搜尋。
特徵儲存庫。許多向量搜尋產品只提供向量索引,可針對每次搜尋傳回項目 ID 清單。如要向使用者提供完整的搜尋結果,您需要使用個別的特徵商店或鍵值商店,傳遞這些 ID 來擷取實際的商品資料 (名稱、價格、類別、圖片網址,以毫秒為單位)。在許多情況下,你還需要對項目特徵 (例如價格、類別或供應情形) 實作複雜的篩選條件。也就是說,您需要建構及維護兩項不同的服務:一項用於向量搜尋,另一項用於資料擷取和篩選。每次更新和查詢都需要存取及同步處理這兩個系統。
索引調整。如要使用數百萬個項目建構近似最近鄰 (ANN) 索引,您需要做出專家決策,才能獲得最佳效能:每個索引節點應保留多少項目?每次查詢應掃描多少百分比的索引,才能在召回率和延遲之間取得平衡?哪個分片大小符合您的資料集?這些機器學習基礎架構決策與實際產品無關。
混合型搜尋。語意搜尋擅長瞭解意圖,例如使用者搜尋「適合海灘的男裝」時,系統會找出「海灘褲」。但如果產品代碼沒有語意,例如「SKU-12345」,系統就會無法辨識,如果嵌入模型從未見過新創字詞或品牌名稱,也會難以辨識。關鍵字搜尋可以處理這些情況,但會遺漏語意脈絡。使用者需要這兩者,因此混合型搜尋已成為不可或缺的功能。但建構這類應用程式並不容易。除了向量搜尋引擎,您還需要具備權杖化、反向索引或稀疏嵌入的全文搜尋引擎。然後您必須在兩個引擎上執行平行查詢、將不同的評分系統標準化,並使用倒數排名融合等技術合併結果。
Vector Search 2.0 如何解決這些問題
Google Cloud 的 Vector Search 2.0 可直接解決上述各項挑戰:

在本研討會中,我們將使用 TheLook 電子商務資料集中的 10,000 項時尚產品,建構全代管的混合型搜尋功能。
什麼是 Vector Search 2.0?
向量搜尋 2.0 是 Google Cloud 的全代管、自動調整向量資料庫,採用 Google 的 ScaNN (可擴充的最近鄰) 演算法,這項技術也用於 Google 搜尋、YouTube 和 Google Play。
主要競爭優勢
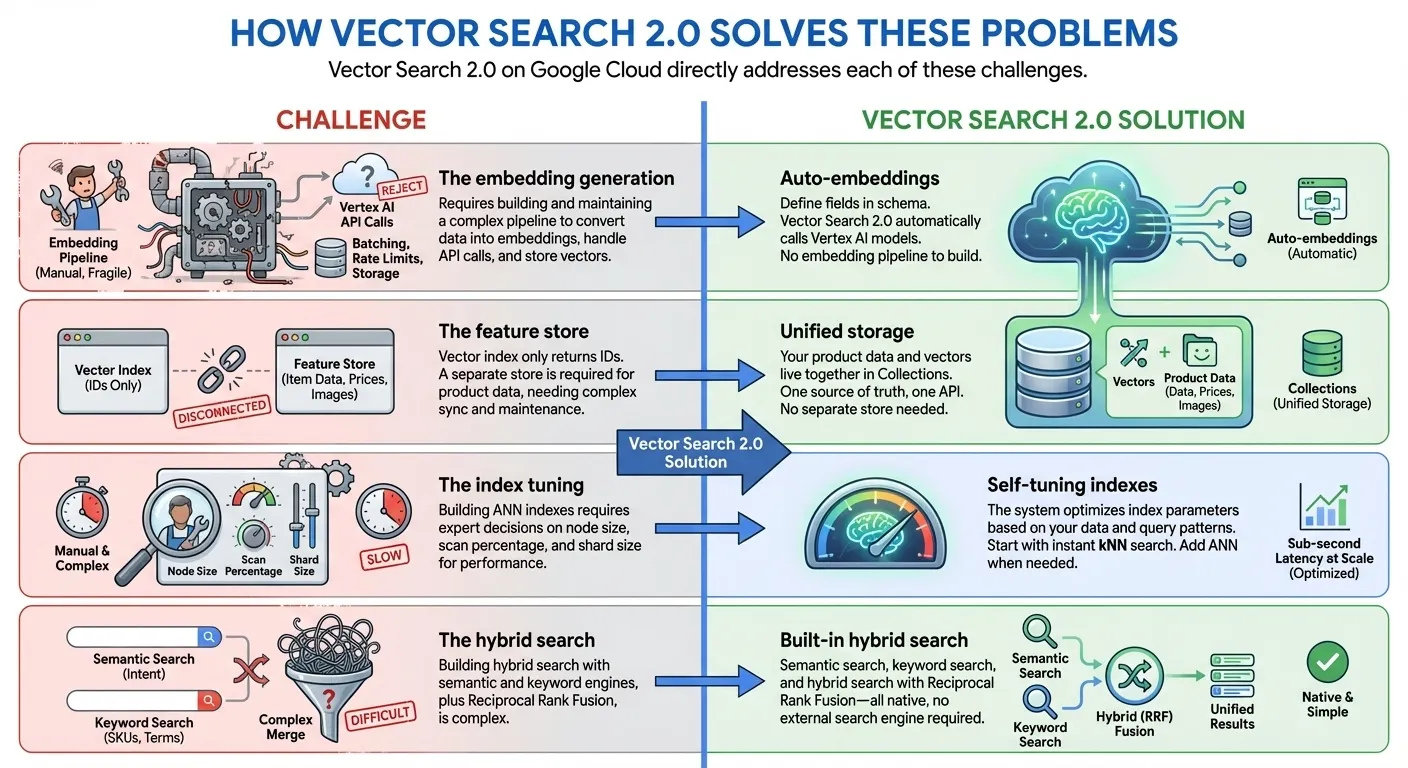
- 從零索引到十億規模的索引:使用 kNN (k 近鄰) 立即開始開發,索引時間為零,然後使用 Google 規模的 ANN (近似近鄰) 索引,將向量擴展到數十億個,延遲時間為毫秒級,用於正式環境 - 全都使用相同的 API 和資料集
- 統一資料儲存:同時儲存向量嵌入和使用者提供的資料 (不需另外使用資料庫或特徵儲存區)
- 自動嵌入:使用 Vertex AI 嵌入模型自動生成語意嵌入
- 內建全文搜尋:提供內建全文搜尋功能,不必自行生成稀疏嵌入。您也可以選擇搭配向量搜尋功能使用自己的稀疏嵌入 (例如 BM25、SPLADE),進行自訂的全文搜尋。
- 混合型搜尋:在單一查詢中結合語意和關鍵字/權杖搜尋,並使用智慧型 RRF 排名
- 自動調整:自動最佳化效能,不需手動設定
- 企業適用:內建擴充性、安全性和法規遵循功能
核心架構
Vector Search 2.0 包含三個主要元件:
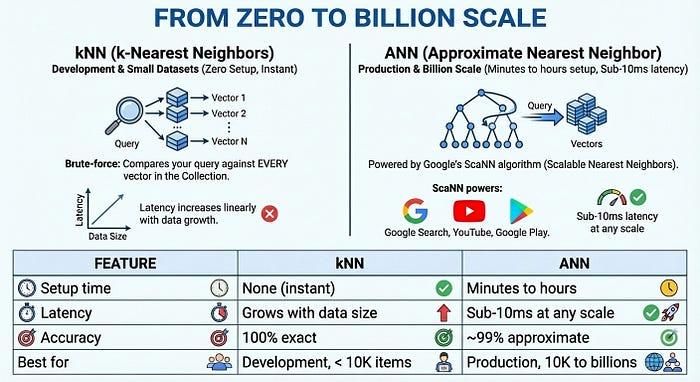
- 快速上手:立即使用 kNN,無需設定,非常適合開發和小型資料集
- 大規模投入生產:使用 ANN 索引,透過 ScaNN 演算法支援數十億筆資料的搜尋,延遲時間不到 1 秒
讓我們透過實作範例,深入瞭解每個概念!
2. 建構 TheLook 時尚搜尋功能
假設有位顧客造訪你的電子商務網站,並輸入「適合海灘度假的可愛單品」。如果使用傳統關鍵字搜尋,他們會得到零結果,因為目錄中沒有任何產品包含這些確切字詞。他們感到沮喪,於是離開。
現在想像一下不同的體驗。同樣的查詢會傳回連身裙、泳衣外罩和飄逸短褲,這些產品完全符合顧客的期望,即使名稱中沒有「海灘」一詞也一樣。這就是向量搜尋帶來的體驗。
為示範 Vector Search 2.0 如何實現這項功能,我們將使用 TheLook 建構產品搜尋系統。這是一個真實的電子商務資料集,包含 26 個類別的 30,000 件時尚商品。每項產品都有屬性,就像實體目錄一樣:

我們將解決的搜尋挑戰
實際顧客的搜尋方式與資料庫預期的不同。他們會以思考方式搜尋:

Vector Search 2.0 採用統一架構,可解決上述所有四項挑戰。
Vector Search 2.0 資料架構
開始撰寫程式碼前,請先瞭解 Vector Search 2.0 如何整理資料。這項架構以三個重要概念為中心:集合、資料物件和索引。
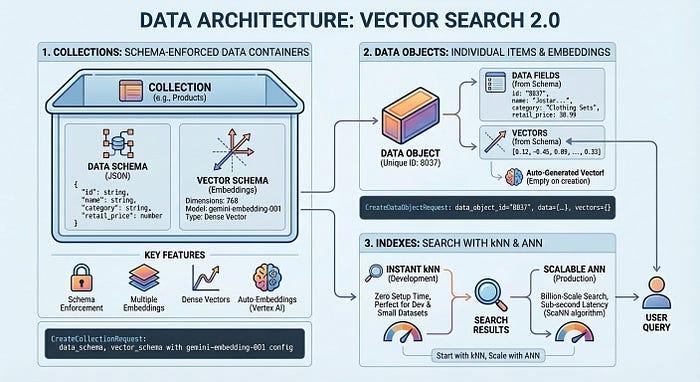
集合會定義資料結構,也就是您要儲存的欄位,以及應嵌入的欄位。資料物件是儲存在集合中的實際項目 (產品、文件、圖片),每個項目都有自己的資料和自動產生的向量,或您自己的向量。索引可大規模最佳化查詢,在數十億個項目中實現毫秒級延遲。您可以在開發時不使用索引,完全不需要設定,然後在需要生產效能時新增索引。
建構 TheLook 搜尋功能:逐步說明
現在來建構可用的產品搜尋系統。我們將從 TheLook 載入 10,000 項時尚商品、啟用自動嵌入,並執行語意、關鍵字和混合搜尋,所有作業都只需約 50 行程式碼。
開啟筆記本:Introduction to Vertex AI Vector Search 2.0
混合型搜尋的實際應用
Vector Search 2.0 支援三種搜尋模式:語意搜尋 (透過嵌入瞭解意圖)、文字搜尋 (關鍵字比對) 和混合型搜尋 (結合兩者)。混合搜尋功能可為大多數用途提供最佳結果,例如使用者搜尋「海灘男裝」時,語意搜尋功能會找出「海灘短褲」,而文字搜尋功能則可確保不會遺漏產品代碼等完全相符的結果。
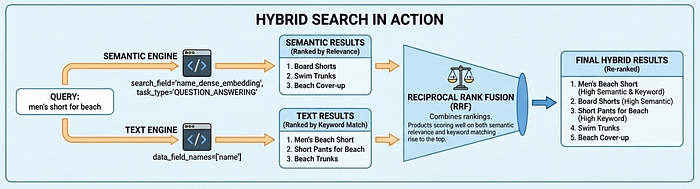
工作類型嵌入的重要性
請注意上述程式碼中的 task_type 參數:建立產品索引時為 RETRIEVAL_DOCUMENT,搜尋時為 QUESTION_ANSWERING。這並非隨機做法,而是讓嵌入模型像建議模型一樣運作,藉此提升搜尋品質的重要技術。
大多數向量搜尋應用情境都依賴簡單的相似度比對,但由於問題和答案在嵌入空間中本質上並不相似,因此這類比對通常無法提供生產等級的搜尋品質。「適合海灘度假的服裝」和「海灘短褲」的語意不同,但應視為相符。工作類型嵌入可解決這個問題,做法是針對非對稱關係最佳化嵌入模型:文件和查詢的嵌入方式不同,因此建立的嵌入空間會將相關項目聚集在一起,進而新增推薦功能,根據使用者意圖尋找相關項目。
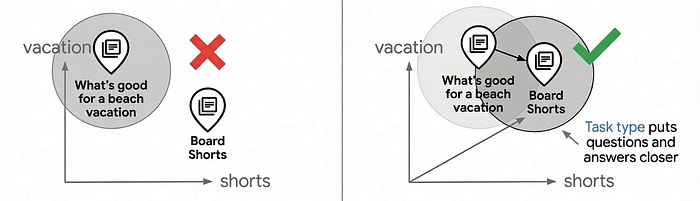
與一般嵌入相比,使用特定工作嵌入可提升 30% 至 40% 的搜尋品質。如要深入瞭解相關運作方式,請參閱 Task Type Embedding 筆記本。
從零到十億規模
如要大規模進行生產,Vector Search 2.0 提供 ANN (近似最鄰近項目) 索引,採用 Google 的 ScaNN (可擴充最鄰近項目) 演算法,這項技術也用於 Google 搜尋、YouTube 和 Google Play。ANN 會犧牲極少量的準確率 (約 99%),換取大幅提升的速度,即使有數十億個向量,延遲時間仍低於 10 毫秒。
完整圖像
我們只花了五個步驟 (步驟 1 到 4 大約只花了 5 分鐘),就建構出可供正式上線的產品搜尋系統:
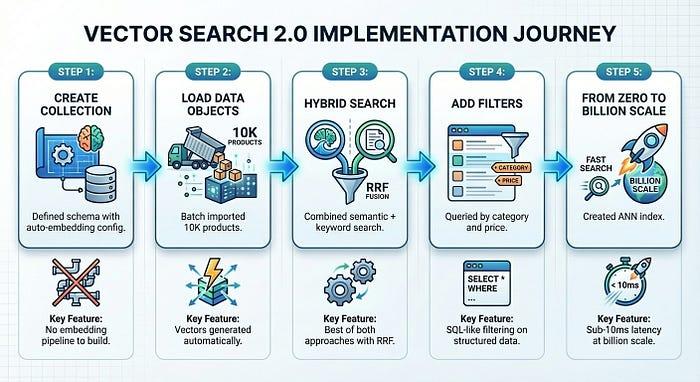
向量搜尋 2.0 可消除基礎架構的複雜性,通常這類複雜性會減緩向量搜尋的採用速度。你專注於產品,平台則負責嵌入、建立索引和擴展。
3. 恭喜
恭喜,您已成功使用 Vector Search 2.0 建構第一個應用程式!