
1. 简介
上次更新日期:2026-03-04
向量搜索(或向量数据库)已成为现代 AI 系统的基础技术。通过将数据表示为可捕捉语义的高维嵌入,它可为各种应用提供支持,从可理解用户意图的语义搜索,到可显示相关内容的推荐引擎,再到可基于实时最新信息生成 LLM 回答的检索增强生成 (RAG) 和 AI 代理。包括 Google 在内的主要科技公司大规模依赖这项技术,每天处理数十亿次搜索、推荐和 grounding。
不过,构建可用于生产用途的向量搜索仍然是一项具有挑战性的任务。Google 最近发布了 Vertex AI Vector Search 2.0,旨在改变这一现状。这项全托管式服务旨在消除会拖慢团队速度的设计和运营复杂性。

为什么向量搜索比看起来更难
这个概念很简单。实现?这正是问题变得复杂的地方。
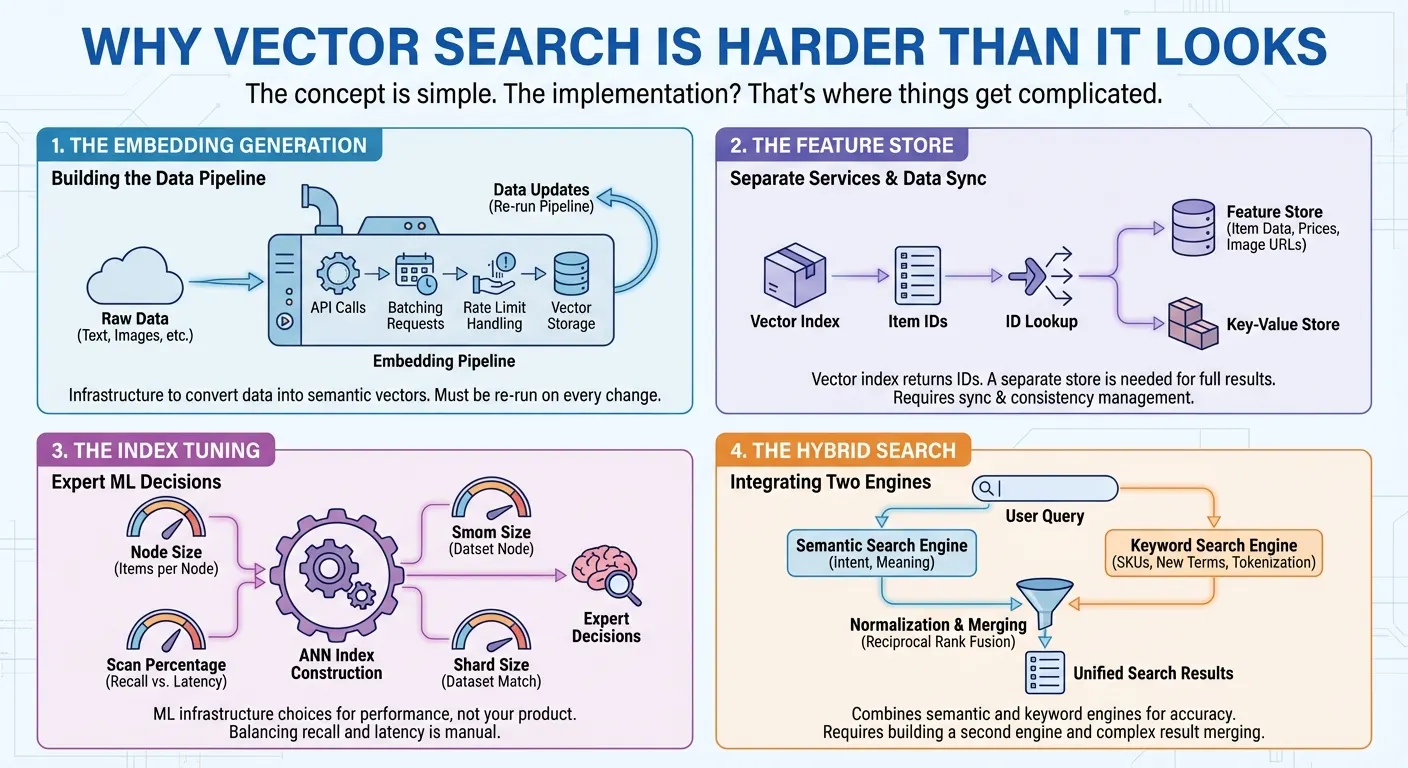
嵌入生成。向量搜索需要将数据转换为可捕捉语义含义的数值表示法(嵌入)。这意味着您需要调用嵌入 API、批量处理请求、处理速率限制并存储向量。每次数据发生变化时,您都需要重新运行流水线。这是您在开始搜索之前必须构建的基础设施。
特征存储区。许多向量搜索产品仅提供向量索引,该索引会针对每次搜索返回商品 ID 列表。为了向用户提供完整的搜索结果,您需要一个单独的特征存储区或键值对存储区,通过传递这些 ID 来检索实际的商品数据(名称、价格、类别、图片网址,以毫秒为单位)。在许多情况下,您还需要对价格、类别或供应情况等商品特征实现复杂的过滤。这意味着需要构建和维护两项不同的服务:一项用于向量搜索,另一项用于数据检索和过滤。每次更新和查询都需要访问并同步这两个系统。
索引调优。如需构建包含数百万个商品的近似最邻近 (ANN) 索引,您需要做出专家级决策,才能获得最佳性能:每个索引节点应包含多少个商品?每次查询应扫描索引的百分比,以平衡召回率和延迟时间?哪个分片大小与您的数据集相匹配?这些是与您的实际产品无关的机器学习基础设施决策。
混合搜索。语义搜索擅长理解意图,例如,当用户搜索“男士海滩服装”时,语义搜索会找到“沙滩裤”。但对于“SKU-12345”等没有语义的产品代码,它会失败,并且对于嵌入模型从未见过的新造词或品牌名称,它也会遇到困难。关键字搜索可以处理这些情况,但会忽略语义上下文。用户需要这两种搜索方式,因此混合搜索变得至关重要。不过,构建它绝非易事。除了向量搜索引擎之外,您还需要一个具有分词、倒排索引或稀疏嵌入的全文搜索引擎。然后,您必须在两个引擎上运行并行查询,对它们不同的评分系统进行归一化处理,并使用倒数排序融合等技术合并结果。
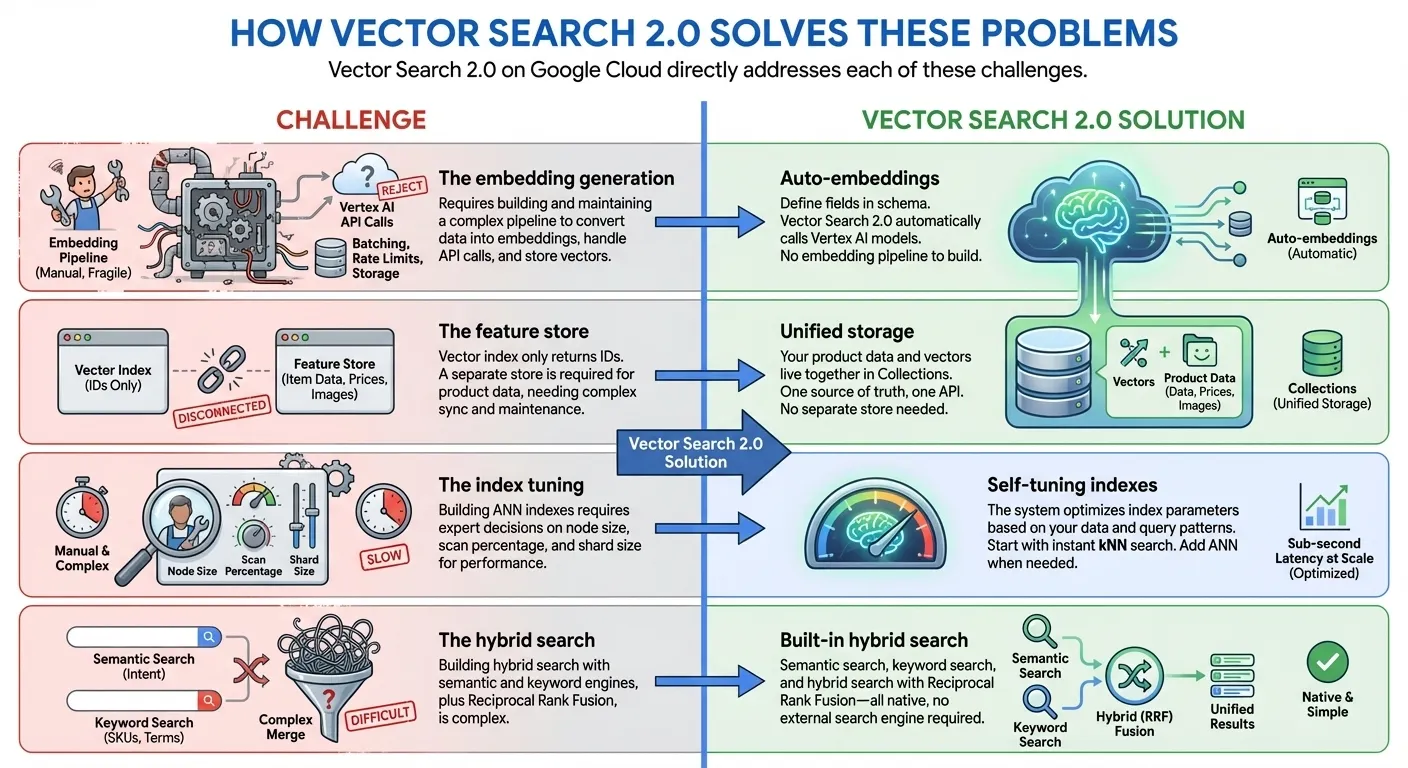
Vector Search 2.0 如何解决这些问题
Google Cloud 上的 Vector Search 2.0 直接解决了上述各项挑战:

在此研讨会中,我们将使用 TheLook 电子商务数据集中的 10,000 件时尚产品构建一个全托管式混合搜索。
什么是 Vector Search 2.0?
Vector Search 2.0 是 Google Cloud 的全托管式自调优向量数据库,基于 Google 的 ScaNN(可伸缩最近邻)算法构建而成,该算法也是 Google 搜索、YouTube 和 Google Play 的底层技术。
主要差异化因素
- 从零索引到十亿级索引:使用 kNN(k-最近邻)立即开始开发,然后使用 Google 规模的 ANN(近似最近邻)索引扩展到数十亿个向量,延迟时间为毫秒级,用于生产 - 所有这些都使用相同的 API 和相同的数据集
- 统一数据存储:同时存储向量嵌入和用户提供的数据(无需单独的数据库或特征存储区)
- 自动嵌入:使用 Vertex AI 嵌入模型自动生成语义嵌入
- 内置全文搜索:提供内置全文搜索,无需自行生成稀疏嵌入。您还可以选择将自己的稀疏嵌入(例如 BM25、SPLADE)与 Vector Search 搭配使用,以实现自定义的全文搜索。
- 混合搜索:通过智能 RRF 排名,在单个查询中结合使用语义搜索和基于关键字/词元的搜索
- 自动调优:自动优化性能,无需手动配置
- 可满足企业需求:内置可伸缩性、安全性和合规性
核心架构
Vector Search 2.0 包含三个主要组件:
- 快速开始:立即使用 kNN,无需设置时间 - 非常适合开发和小数据集
- 扩展到生产环境:使用 ANN 索引进行数十亿规模的搜索,延迟时间不到一秒,由 ScaNN 算法提供支持
让我们通过实际操作示例来探索每个概念!
2. 构建 TheLook 时尚搜索
假设客户访问了您的电子商务网站,并输入了“适合海滩度假的可爱物品”。如果使用传统的关键字搜索,他们会得到零结果,因为您的商品目录中没有任何商品包含这些确切的字词。他们感到沮丧,于是离开了。
现在,想象一下不同的体验。同一搜索查询返回了夏日连衣裙、泳装遮盖物和飘逸短裤,这些商品完全符合客户的预期,即使它们的商品名中都没有“海滩”一词。这就是向量搜索带来的体验。
为了演示 Vector Search 2.0 如何实现这一点,我们将使用 TheLook 构建一个产品搜索系统。这是一个真实的电子商务数据集,包含 26 个类别的 30,000 件时尚商品。每件商品都具有您在任何真实目录中都能找到的属性:

我们将解决的搜索挑战
真实客户的搜索方式与数据库的预期不同。他们会按照自己的思维方式进行搜索:

Vector Search 2.0 采用统一的架构,可解决所有这四项挑战。
Vector Search 2.0 数据架构
在深入研究代码之前,我们先来了解一下 Vector Search 2.0 如何整理数据。该架构围绕三个关键概念展开:集合、数据对象和索引。

集合用于定义数据结构,即您要存储的字段以及应嵌入的字段。数据对象是存储在集合中的实际项(产品、文档、图片),每个数据对象都包含其数据和自动生成的向量或您自己的向量。索引可大规模优化查询,从而在数十亿个项中实现毫秒级延迟。您可以先在开发阶段不使用索引,这样无需设置,然后等到需要生产性能时再添加索引。
构建 TheLook Search:分步说明
现在,我们来构建一个可用的商品搜索系统。我们将从 TheLook 加载 10,000 件时尚商品,启用自动嵌入,并运行语义搜索、关键字搜索和混合搜索,所有这些操作只需大约 50 行代码。
打开笔记本:Vertex AI Vector Search 2.0 简介
混合搜索的实际应用
Vector Search 2.0 支持三种搜索模式:语义搜索(通过嵌入理解意图)、文本搜索(关键字匹配)和混合搜索(结合使用前两种模式)。在大多数使用情形下,混合搜索都能提供最佳结果。例如,当用户搜索“适合海滩的男士服装”时,语义搜索会找到“沙滩裤”;而文本搜索则可确保不会遗漏产品代码等完全匹配的结果。
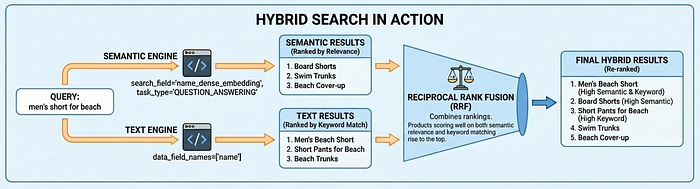
任务类型嵌入的重要性
请注意上述代码中的 task_type 参数:在为商品编制索引时为 RETRIEVAL_DOCUMENT,在搜索时为 QUESTION_ANSWERING。这并非随意设置,而是一项关键技术,可让嵌入模型像推荐模型一样运作,从而提高搜索质量。
大多数向量搜索用例都依赖于简单的相似度匹配,但由于问题和答案在嵌入空间中并不具有内在的相似性,因此这种方法往往无法提供生产级搜索质量。“适合海滩度假的服装有哪些?”和“板裤”的语义不同,但它们应该匹配。任务类型嵌入通过针对非对称关系优化嵌入模型来解决此问题:文档的嵌入方式与查询的嵌入方式不同,从而创建一个相关匹配项聚集在一起的嵌入空间,并添加了推荐功能,可根据用户意图查找相关项。
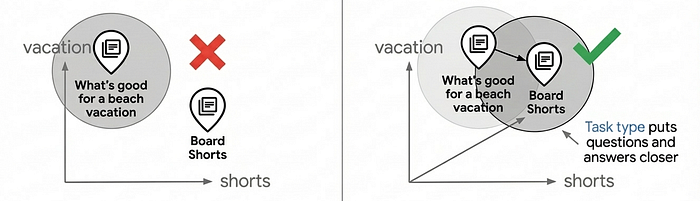
与通用嵌入相比,使用特定于任务的嵌入可将搜索质量提高 30% 至 40%。如需深入研究其工作原理,请参阅任务类型嵌入笔记本。
从零到十亿规模
对于大规模生产环境,Vector Search 2.0 提供由 Google 的 ScaNN(可伸缩最近邻)算法提供支持的 ANN(近似最近邻)索引,该算法与 Google 搜索、YouTube 和 Google Play 背后的技术相同。ANN 会牺牲少量准确率(约 99%),以换取巨大的速度提升:即使有数十亿个向量,延迟时间也低于 10 毫秒。
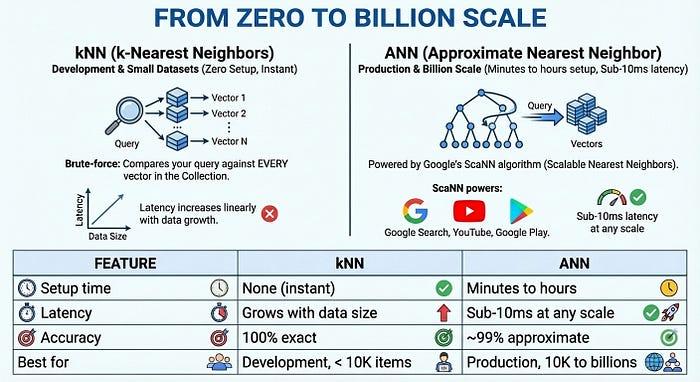
全貌
只需 5 个步骤(其中第 1 步到第 4 步只需大约 5 分钟),我们就构建了一个可用于生产用途的商品搜索系统:
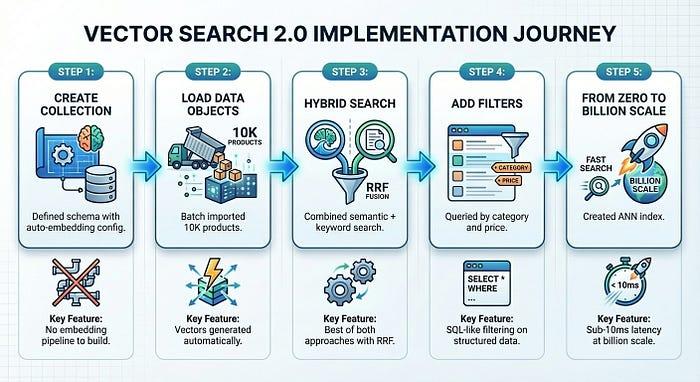
Vector Search 2.0 消除了通常会减缓向量搜索采用速度的基础设施复杂性。您只需专注于产品,平台会处理嵌入、编入索引和扩缩。
3. 恭喜
恭喜,您已成功使用 Vector Search 2.0 构建了第一个应用!