
1. Übersicht
In diesem Lab verwenden Sie die Funktion für das gemeinsame Hosting von Modellen in Vertex AI, um mehrere Modelle auf derselben VM für Onlinevorhersagen zu hosten.
Lerninhalte
Die folgenden Themen werden behandelt:
DeploymentResourcePoolerstellen- Modelle in einer
DeploymentResourcePoolbereitstellen
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 2$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produkt von Google Cloud verwendet. Vertex AI vereint die ML-Angebote von Google Cloud in einer nahtlosen Entwicklungsumgebung. Bisher musste auf mit AutoML trainierte und benutzerdefinierte Modelle über verschiedene Dienste zugegriffen werden. Das neue Angebot kombiniert diese und weitere, neue Produkte zu einer einzigen API. Sie können auch vorhandene Projekte zu Vertex AI migrieren. Wenn Sie Feedback haben, lesen Sie bitte die Supportseite.
Vertex AI umfasst viele verschiedene Produkte zur Unterstützung von End-to-End-ML-Workflows. In diesem Lab konzentrieren wir uns auf die unten hervorgehobenen Produkte: Vorhersagen und Workbench.

3. Übersicht über Anwendungsfälle
Wenn Sie Modelle im Vertex AI Prediction-Dienst bereitstellen, wird jedes Modell standardmäßig auf einer eigenen VM bereitgestellt. Um das Hosting kostengünstiger zu gestalten, können Sie mehrere Modelle auf derselben VM hosten. Dadurch werden Speicher- und Rechenressourcen besser genutzt. Die Anzahl der Modelle, die Sie auf derselben VM bereitstellen, hängt von den Modellgrößen und Trafficmustern ab. Diese Funktion ist jedoch besonders nützlich für Szenarien, in denen Sie viele bereitgestellte Modelle mit geringem Traffic haben.
Mit Unterstützung des Co-Hostings-Modells wird das Konzept des Ressourcenpools für die Bereitstellung eingeführt, in dem Modelle gruppiert werden, die Ressourcen innerhalb einer VM gemeinsam nutzen. Modelle können eine VM gemeinsam nutzen, wenn sie einen Endpunkt gemeinsam nutzen oder wenn sie auf verschiedenen Endpunkten bereitgestellt werden. Derzeit müssen Modelle im selben Ressourcenpool dasselbe Container-Image haben, einschließlich der Framework-Version der vordefinierten Vertex Prediction-Container. Außerdem werden in dieser Version nur vordefinierte Vertex Prediction-Container mit dem Tensorflow-Modell-Framework unterstützt. Andere Modell-Frameworks und benutzerdefinierte Container werden noch nicht unterstützt.

4. Umgebung einrichten
Für dieses Codelab benötigen Sie ein Google Cloud Platform-Projekt mit aktivierter Abrechnung. Folgen Sie dieser Anleitung, um ein Projekt zu erstellen.
Schritt 1: Compute Engine API aktivieren
Rufen Sie Compute Engine auf und wählen Sie Aktivieren aus, falls die API noch nicht aktiviert ist.
Schritt 2: Vertex AI API aktivieren
Rufen Sie den Vertex AI-Bereich Ihrer Cloud Console auf und klicken Sie auf Vertex AI API aktivieren.
Schritt 3: Vertex AI Workbench-Instanz erstellen
Klicken Sie in der Cloud Console im Bereich „Vertex AI“ auf „Workbench“:
Aktivieren Sie die Notebooks API, falls sie noch nicht aktiviert ist.
Klicken Sie nach der Aktivierung auf VERWALTETE NOTEBOOKS:

Wählen Sie dann NEUES NOTEBOOK aus.

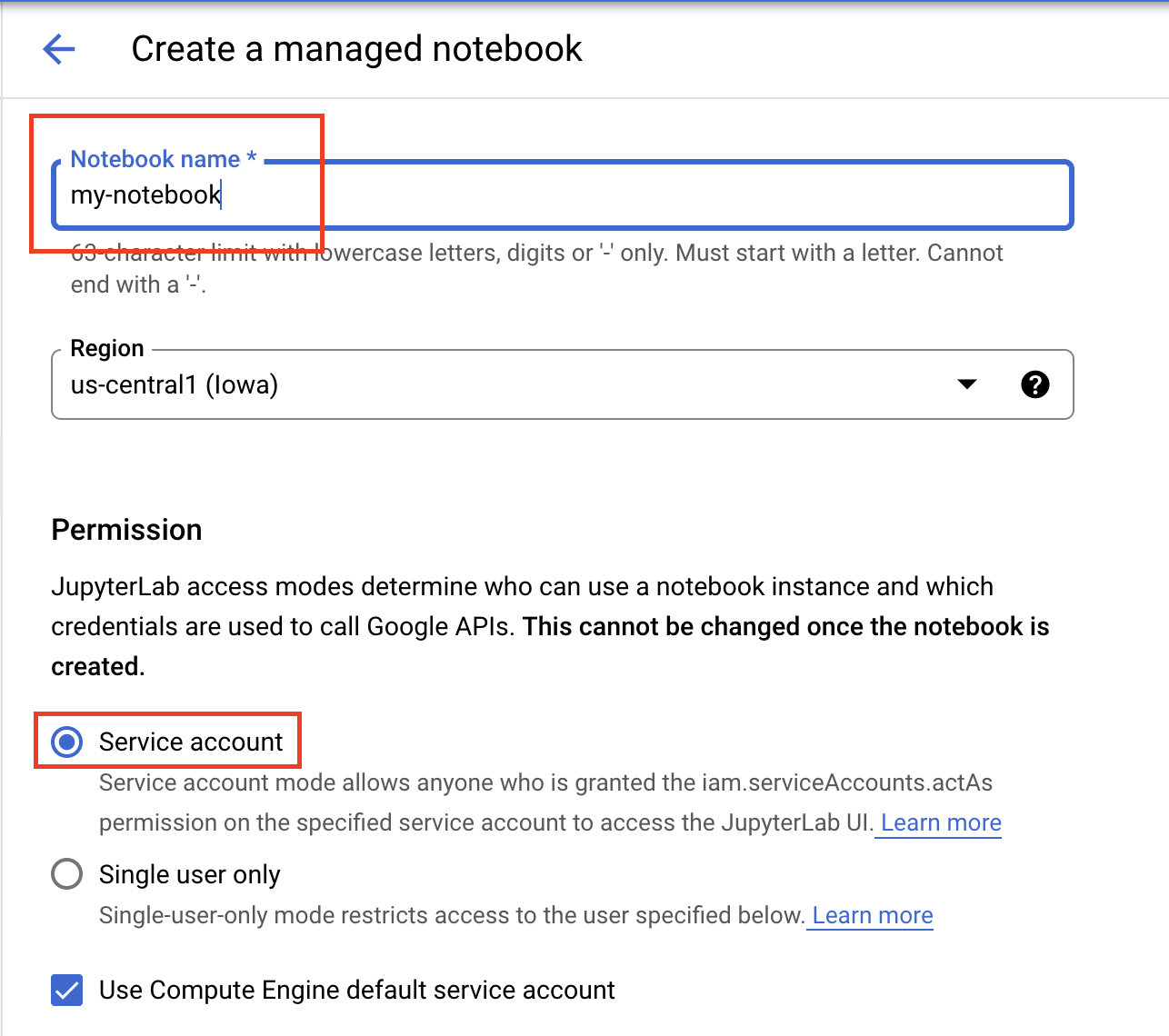
Geben Sie Ihrem Notebook einen Namen und wählen Sie unter Berechtigung die Option Dienstkonto aus.
Wählen Sie Erweiterte Einstellungen aus.
Wählen Sie unter Sicherheit die Option „Terminal aktivieren“ aus, falls sie noch nicht aktiviert ist.

Alle anderen erweiterten Einstellungen können Sie unverändert lassen.
Klicken Sie auf Erstellen. Die Bereitstellung der Instanz kann einige Minuten dauern.
Nachdem die Instanz erstellt wurde, klicken Sie auf JUPYTERLAB ÖFFNEN.

5. Modell trainieren
Bevor wir die Co-Hosting-Funktion ausprobieren können, müssen wir zuerst ein Modell trainieren und die gespeicherten Modellartefakte in einem Cloud Storage-Bucket speichern. Wir verwenden den Workbench-Notebook-Executor, um den Trainingsjob zu starten.
Schritt 1: Cloud Storage-Bucket erstellen
Wenn Sie bereits einen Bucket in Ihrem Projekt haben, den Sie verwenden möchten, können Sie diesen Schritt überspringen. Öffnen Sie andernfalls über den Launcher eine neue Terminalsitzung.

Führen Sie im Terminal den folgenden Befehl aus, um eine Umgebungsvariable für Ihr Projekt zu definieren. Ersetzen Sie dabei your-cloud-project durch die ID Ihres Projekts:
PROJECT_ID='your-cloud-project'
Führen Sie als Nächstes den folgenden Befehl aus, um einen neuen Bucket in Ihrem Projekt zu erstellen.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Schritt 2: Notebookausführung starten
Öffnen Sie über den Launcher Ihrer Workbench-Instanz ein neues TensorFlow 2-Notebook.

Im folgenden Code wird ein binärer Sentiment-Klassifikator (positiv oder negativ) für das IMDB-Dataset mit Filmrezensionen trainiert. Fügen Sie den Code in Ihr Notebook ein.
Ersetzen Sie {YOUR_BUCKET} durch den Bucket, den Sie im vorherigen Schritt erstellt haben (oder einen anderen Bucket in Ihrem Projekt). Hier speichern wir die gespeicherten Modellartefakte, die wir später benötigen, wenn wir das Modell in Vertex AI Model Registry hochladen.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
Klicken Sie dann auf die Schaltfläche Ausführen.
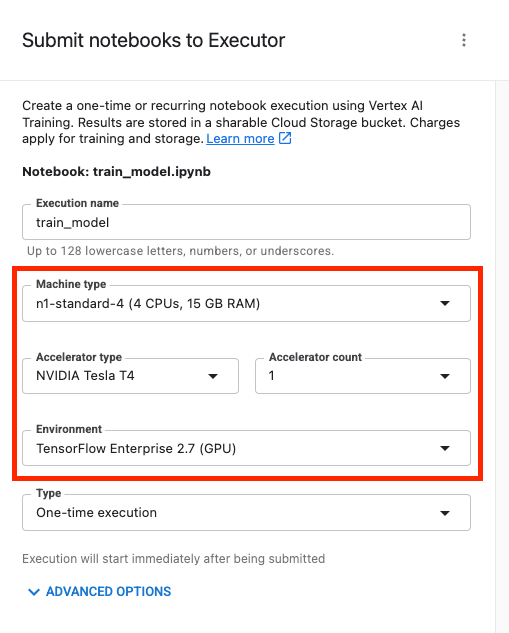
Konfigurieren Sie dann die Ausführung wie folgt und klicken Sie auf SENDEN.
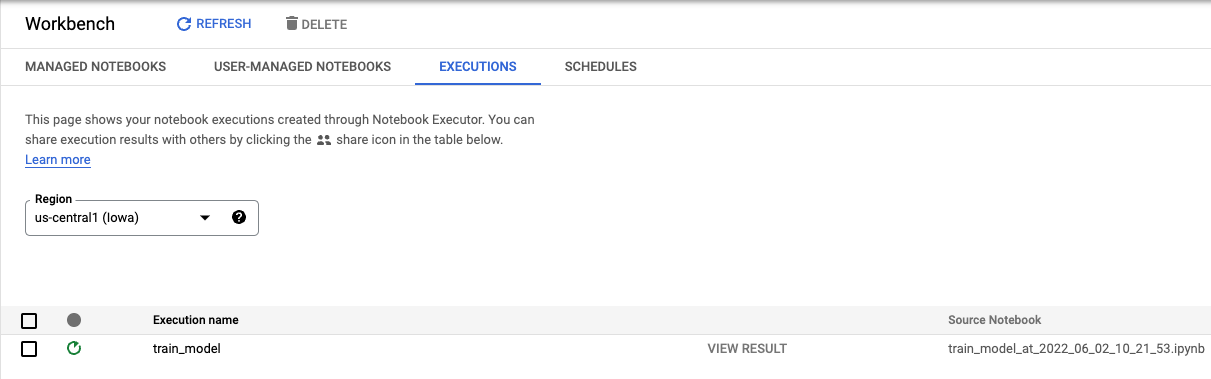
Auf dem Tab „Ausführungen“ in der Console können Sie den Status Ihres Trainingsjobs verfolgen.
6. Modell bereitstellen
Schritt 1: Modell hochladen
Kehren Sie nach Abschluss der Ausführung zum Workbench-Notebook zurück, um das Modell hochzuladen. Erstellen Sie ein neues TensorFlow-Notebook.

Zuerst das Vertex AI Python SDK importieren
from google.cloud import aiplatform
Laden Sie dann das Modell hoch und ersetzen Sie {YOUR_BUCKET} durch den Bucket, den Sie im Trainingscode angegeben haben.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
Zu Demonstrationszwecken laden wir dieses Modell zweimal hoch und erstellen so zwei verschiedene Modellressourcen in Vertex AI. So können wir das Bereitstellen mehrerer Modelle auf einem einzelnen Endpunkt in einem Ressourcenpool für die Bereitstellung testen. In einem realen Szenario würden Sie zwei verschiedene Modelle verwenden, anstatt Modelle aus denselben gespeicherten Artefakten zu erstellen. Dies ist jedoch eine Abkürzung, damit wir keine weitere Trainingsausführung starten müssen. Außerdem können Sie die beiden Modelle auch auf verschiedenen Endpunkten im selben Deployment-Ressourcenpool bereitstellen.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
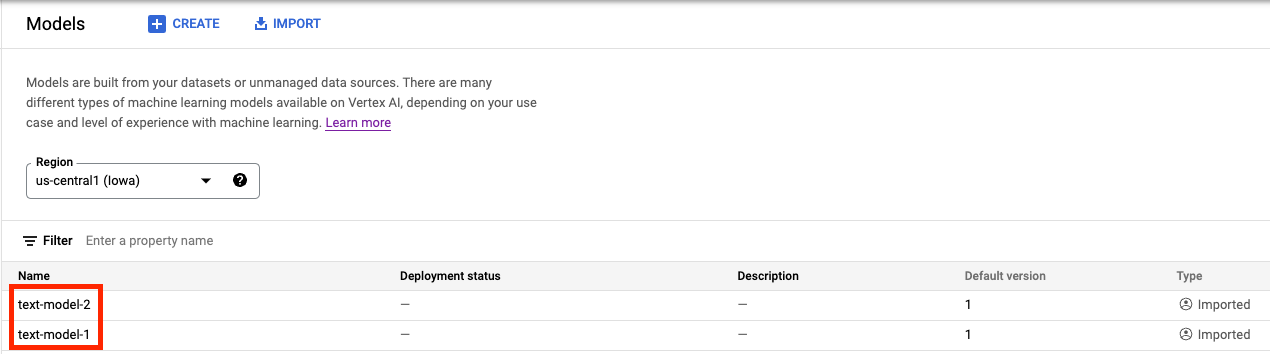
In der Vertex AI Model Registry sollten Sie jetzt beide Modelle sehen. Der Bereitstellungsstatus ist leer, da wir die Modelle noch nicht bereitgestellt haben.
Schritt 2: Endpunkt erstellen
Erstellen Sie einen Endpunkt. Das ist nicht dasselbe wie die Bereitstellung eines Modells auf einem Endpunkt.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
Wenn der Endpunkt erstellt wurde, wird er in der Konsole angezeigt.

Schritt 3: DeploymentResourcePool erstellen
Sie können den DeploymentResourcePool mit dem folgenden Befehl erstellen. Ersetzen Sie {YOUR_PROJECT} durch Ihre Projekt-ID.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
Sie können den Pool mit dem folgenden Befehl aufrufen:
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
Schritt 4: Modelle für den Endpunkt bereitstellen
Nachdem der Ressourcenpool erstellt wurde, können wir die Modelle im Ressourcenpool bereitstellen.
Zuerst stellen wir model_1 bereit. Ersetzen Sie MODEL_1_ID und ENDPOINT_ID durch die entsprechenden IDs.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
Mit dem folgenden Befehl wird model_1 am Endpunkt im Ressourcenpool bereitgestellt.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Das dauert einige Minuten. Wenn der Vorgang abgeschlossen ist, wird das Modell in der Console auf dem Endpunkt bereitgestellt.
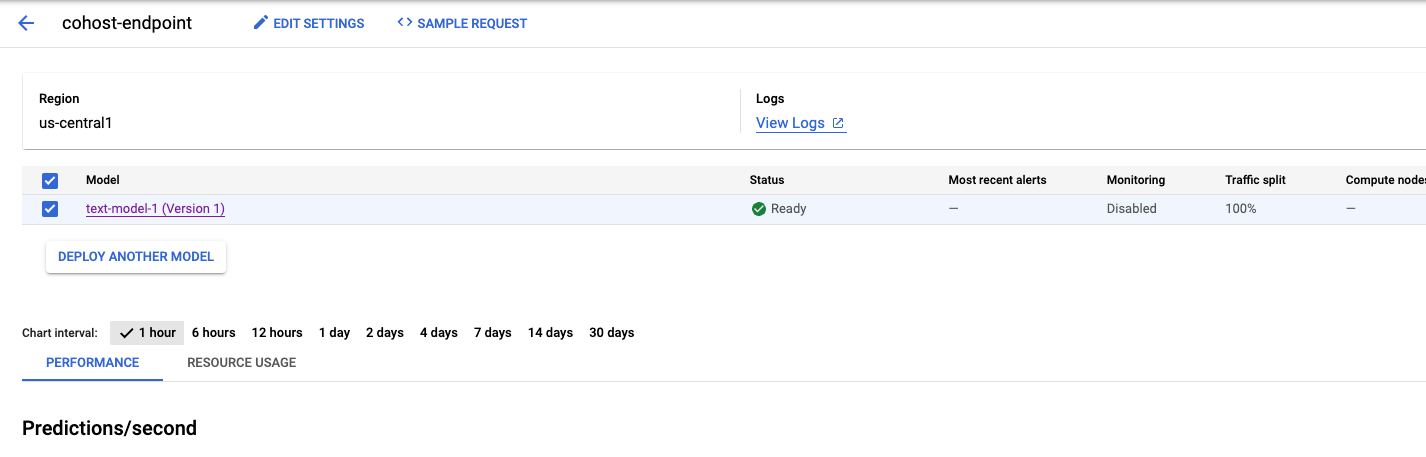
Als Nächstes können wir model_2 im selben Bereitstellungspool bereitstellen. Wir stellen sie am selben Endpunkt wie model_1 bereit. Sie könnenmodel_2aber auch an einem anderen Endpunkt im selben Ressourcenpool bereitstellen.
Ersetzen Sie MODEL_ID durch die ID für model_2. Auch diese ID können Sie mit dem Befehl model_2.name abrufen.
MODEL_2_ID="{MODEL_2_ID}"
Stellen Sie dann model_2 bereit. Da model_1 bereits auf dem Endpunkt bereitgestellt ist, müssen wir trafficSplit aktualisieren, damit der Traffic zwischen den beiden Modellen aufgeteilt wird. Wir müssten die trafficSplit nicht aktualisieren, wenn wir model_2 an einem anderen Endpunkt im selben Ressourcenpool bereitstellen.
Wenn Sie die Traffic-Aufteilung aktualisieren möchten, müssen Sie die DeployedModel-ID für model_1 definieren. Beachten Sie, dass sich die bereitgestellte Modell-ID von der Modell-ID unterscheidet.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
Führen Sie dann den folgenden Befehl aus, um das zweite Modell bereitzustellen.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Auch in diesem Beispiel wurden die beiden Modelle auf demselben Endpunkt bereitgestellt. Sie können Modelle aber auch im selben Ressourcenpool hosten, die auf verschiedenen Endpunkten bereitgestellt werden. In diesem Fall müssten Sie sich keine Gedanken über die Aufteilung des Traffics machen.
Nachdem das zweite Modell bereitgestellt wurde, werden beide in der Konsole angezeigt.
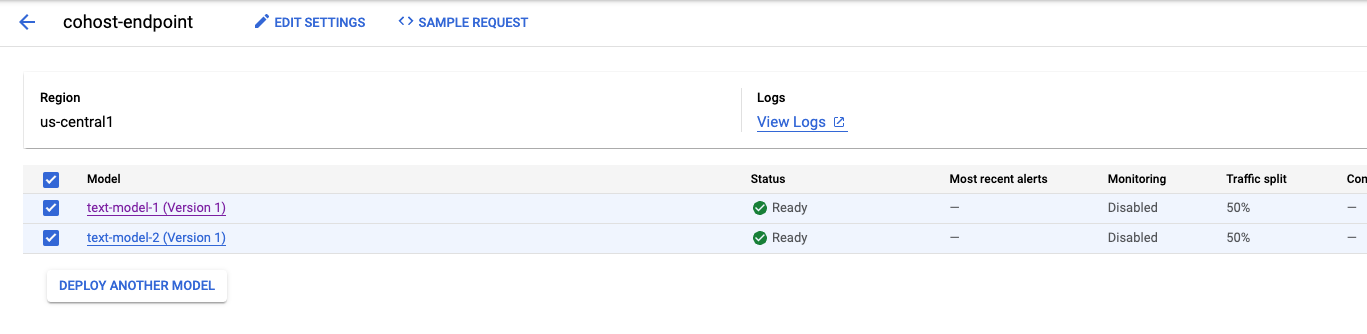
Schritt 5: Vorhersagen abrufen
Im letzten Schritt testen Sie den Endpunkt und rufen Vorhersagen ab.
Definieren wir zuerst den Testsatz.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
Rufen Sie dann „predict“ für den Endpunkt auf. Dadurch wird eine Vorhersage von einem der Modelle zurückgegeben, die für den Endpunkt bereitgestellt wurden.
endpoint.predict(instances=x_test)
🎉 Das wars! 🎉
Sie haben gelernt, wie Sie Vertex AI für folgende Aufgaben verwenden:
- Modelle für Onlinevorhersagen gemeinsam auf derselben VM hosten
Weitere Informationen zu den verschiedenen Bereichen von Vertex finden Sie in der Dokumentation.
7. Bereinigen
Wenn Sie die Modelle nicht verwenden möchten, sollten Sie die Bereitstellung der Modelle am Endpunkt aufheben. Sie können den Endpunkt auch vollständig löschen. Sie können ein Modell jederzeit wieder auf einem Endpunkt bereitstellen.

Von Workbench verwaltete Notebooks laufen nach 180 Minuten Inaktivität automatisch ab. Sie müssen die Instanz also nicht herunterfahren. Wenn Sie die Instanz manuell herunterfahren möchten, klicken Sie im Bereich „Vertex AI Workbench“ der Console auf die Schaltfläche „Beenden“. Wenn Sie das Notebook vollständig löschen möchten, klicken Sie auf die Schaltfläche „Löschen“.

Wenn Sie den Storage-Bucket löschen möchten, rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf, wählen Sie den Bucket aus und klicken Sie auf „Löschen“:
