1. Présentation
Dans cet atelier, vous allez utiliser la fonctionnalité de modèle de co-hébergement dans Vertex AI pour héberger plusieurs modèles sur la même VM pour les prédictions en ligne.
Objectifs
Vous allez apprendre à effectuer les opérations suivantes :
- Créer un objet
DeploymentResourcePool - Déployer des modèles dans un
DeploymentResourcePool
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 2 $.
2. Présentation de Vertex AI
Cet atelier utilise la toute dernière offre de produits d'IA de Google Cloud. Vertex AI simplifie l'expérience de développement en intégrant toutes les offres de ML de Google Cloud. Auparavant, les modèles entraînés avec AutoML et les modèles personnalisés étaient accessibles depuis des services distincts. La nouvelle offre regroupe ces deux types de modèles mais aussi d'autres nouveaux produits en une seule API. Vous pouvez également migrer des projets existants vers Vertex AI. Pour envoyer un commentaire, consultez la page d'assistance.
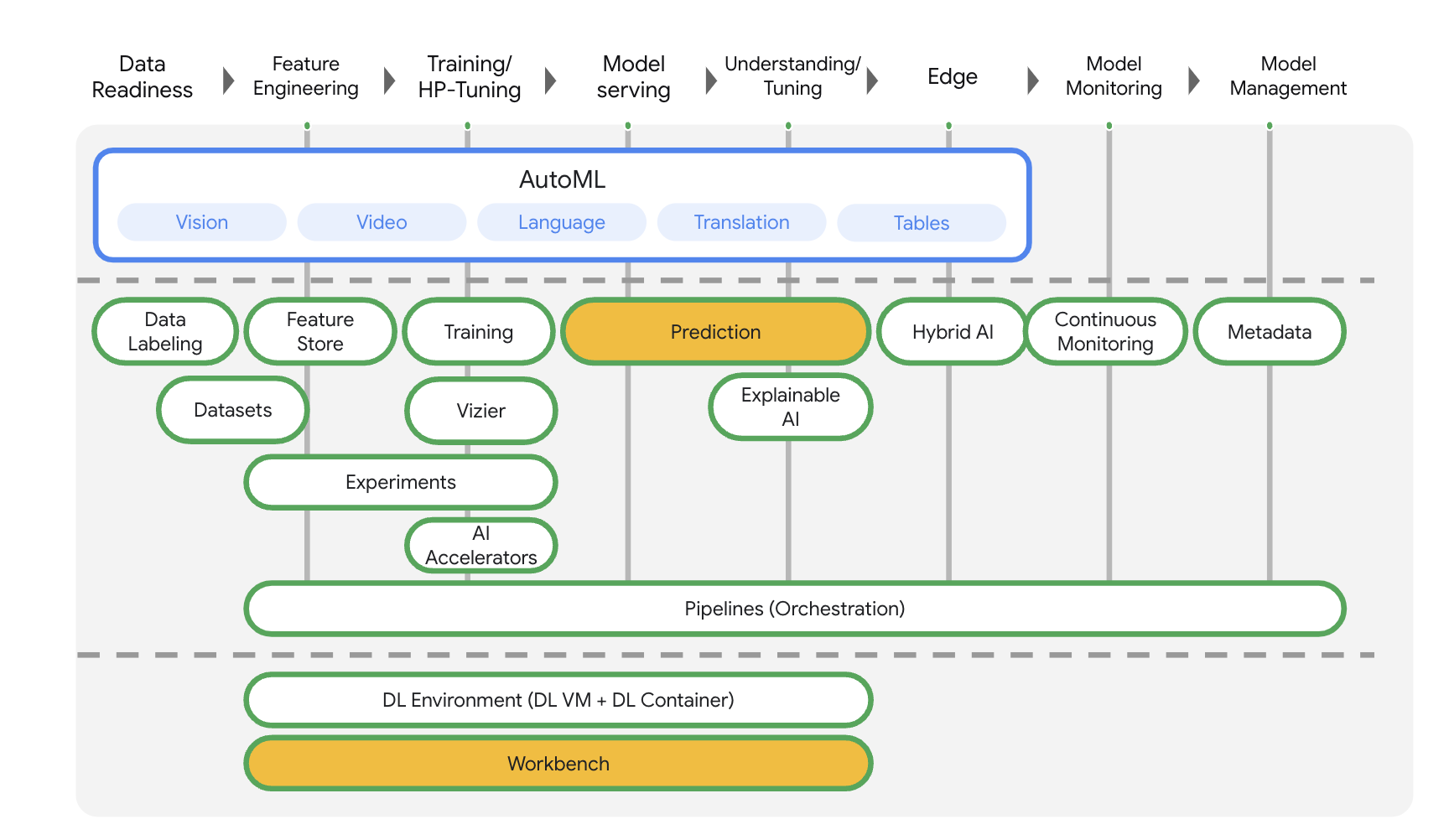
Vertex AI comprend de nombreux produits différents qui permettent de gérer les workflows de ML de bout en bout. Cet atelier se concentre sur les produits mis en évidence ci-dessous : Predictions et Workbench.
3. Présentation du cas d'utilisation
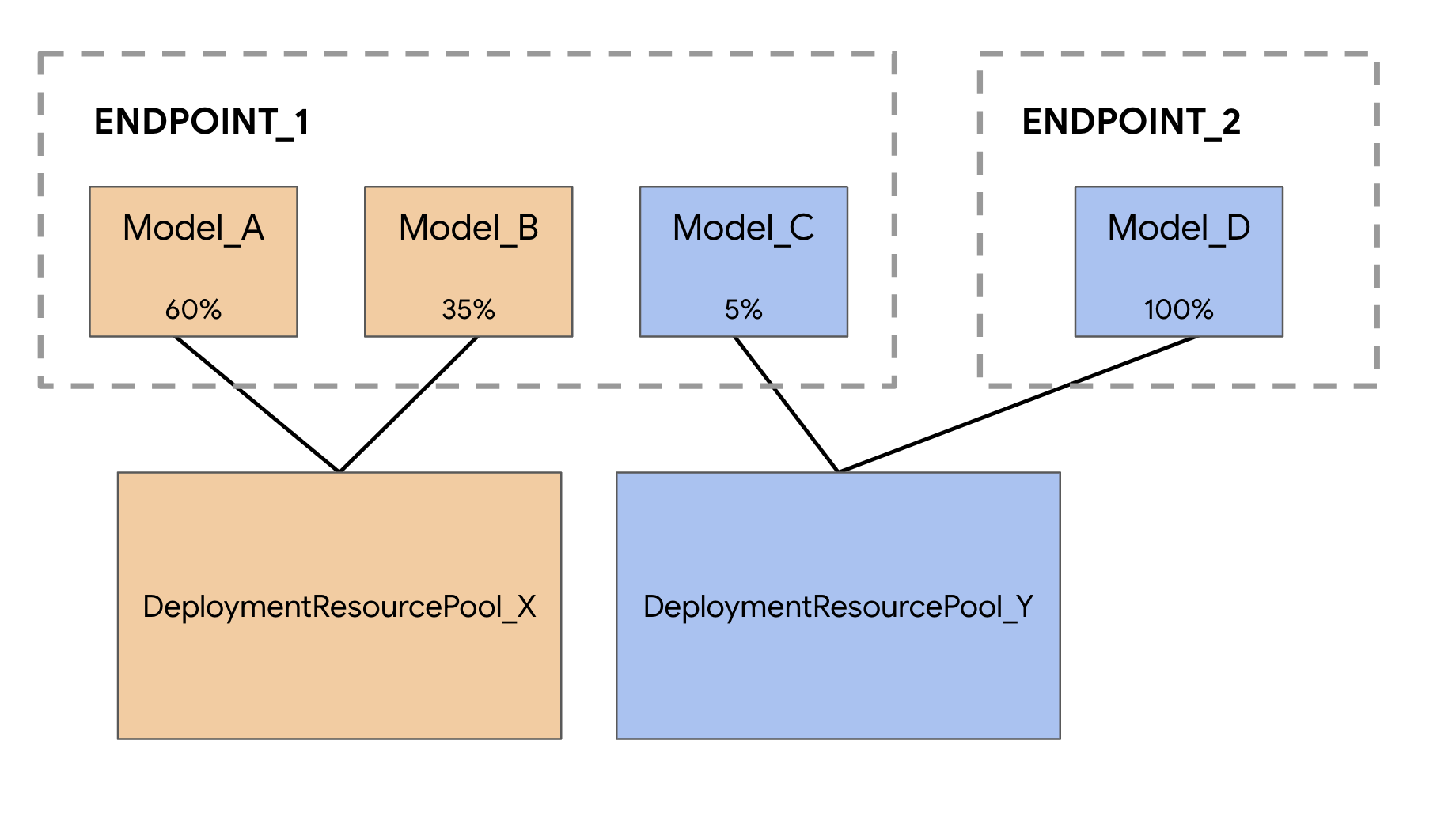
Lorsque vous déployez des modèles sur le service de prédiction Vertex AI, chaque modèle est déployé par défaut sur sa propre VM. Pour rendre l'hébergement plus rentable, vous pouvez héberger plusieurs modèles sur la même VM, ce qui permet de mieux utiliser la mémoire et les ressources de calcul. Le nombre de modèles que vous choisissez de déployer sur la même VM dépend de la taille des modèles et des modèles de trafic. Toutefois, cette fonctionnalité est particulièrement utile dans les scénarios où vous avez déployé de nombreux modèles avec un trafic clairsemé.
La gestion du co-hébergement de modèles introduit le concept de pool de ressources de déploiement, qui regroupe des modèles pour partager des ressources au sein d'une VM. Les modèles peuvent partager une VM s'ils partagent un point de terminaison, mais aussi s'ils sont déployés sur des points de terminaison différents. Actuellement, les modèles d'un même pool de ressources doivent avoir la même image de conteneur, y compris la version du framework des conteneurs prédéfinis Vertex Prediction. De plus, seuls les conteneurs prédéfinis Vertex Prediction avec le framework de modèle TensorFlow sont compatibles avec cette version. Les autres frameworks de modèles et les conteneurs personnalisés ne sont pas encore acceptés.
4. Configurer votre environnement
Pour suivre cet atelier de programmation, vous aurez besoin d'un projet Google Cloud Platform dans lequel la facturation est activée. Pour créer un projet, suivez ces instructions.
Étape 1 : Activez l'API Compute Engine
Accédez à Compute Engine et cliquez sur Activer si ce n'est pas déjà fait.
Étape 2 : Activez l'API Vertex AI
Accédez à la section Vertex AI de Cloud Console, puis cliquez sur Activer l'API Vertex AI.
Étape 3 : Créez une instance Vertex AI Workbench
Dans la section Vertex AI de Cloud Console, cliquez sur Workbench :
Activez l'API Notebooks si ce n'est pas déjà fait.
Une fois l'API activée, cliquez sur NOTEBOOKS GÉRÉS :

Sélectionnez ensuite NOUVEAU NOTEBOOK.
Attribuez un nom à votre notebook, puis sous Autorisation, sélectionnez Compte de service.
Sélectionnez Paramètres avancés.
Dans la section Sécurité, sélectionnez "Activer le terminal" si ce n'est pas déjà fait.
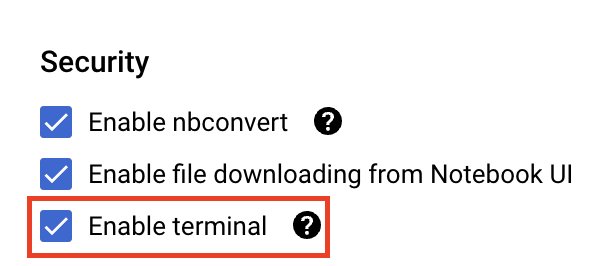
Vous pouvez conserver tous les autres paramètres avancés tels quels.
Cliquez ensuite sur Créer. Le provisionnement de l'instance prend quelques minutes.
Une fois l'instance créée, sélectionnez OUVRIR JUPYTERLAB :

5. Entraîner le modèle
Avant de pouvoir tester la fonctionnalité de co-hébergement, nous devons d'abord entraîner un modèle et stocker les artefacts de modèle enregistrés dans un bucket Cloud Storage. Nous allons utiliser l'exécuteur de notebooks Workbench pour lancer le job d'entraînement.
Étape 1 : Créez un bucket Cloud Storage
Si vous disposez déjà d'un bucket dans votre projet que vous souhaitez utiliser, vous pouvez ignorer cette étape. Sinon, ouvrez une nouvelle session de terminal depuis le lanceur.

Depuis le terminal, exécutez la commande suivante afin de définir une variable d'environnement pour votre projet, en veillant à remplacer your-cloud-project par l'ID de votre projet :
PROJECT_ID='your-cloud-project'
Ensuite, exécutez la commande suivante pour créer un bucket dans votre projet.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Étape 2 : Lancer l'exécution du notebook
Depuis le menu de lancement de votre instance Workbench, ouvrez un nouveau notebook TensorFlow 2.

Le code ci-dessous entraîne un classificateur de sentiments binaires (positifs ou négatifs) sur l'ensemble de données d'avis sur les films IMDB. Collez le code dans votre notebook.
Assurez-vous de remplacer {YOUR_BUCKET} par le bucket que vous avez créé à l'étape précédente (ou un autre bucket de votre projet). C'est là que nous stockerons les artefacts de modèle enregistrés, dont nous aurons besoin plus tard lorsque nous importerons le modèle dans Vertex AI Model Registry.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
Cliquez ensuite sur le bouton Exécuter.
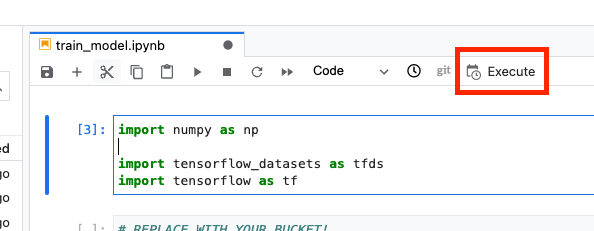
Configurez ensuite votre exécution comme suit, puis cliquez sur ENVOYER.
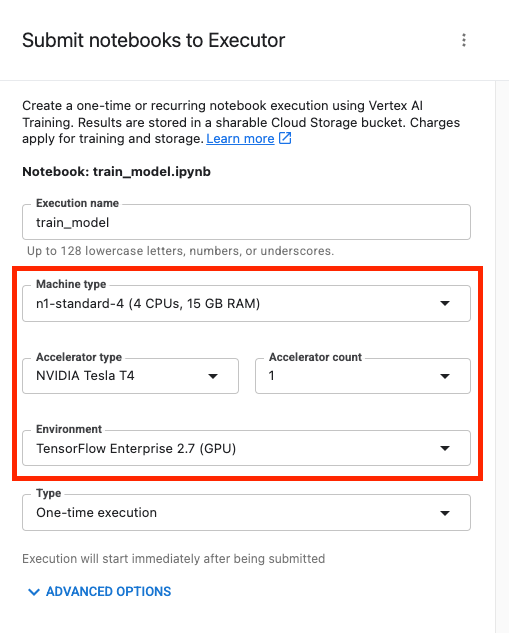
Dans l'onglet "Exécutions" de la console, vous pouvez suivre l'état de votre job d'entraînement.
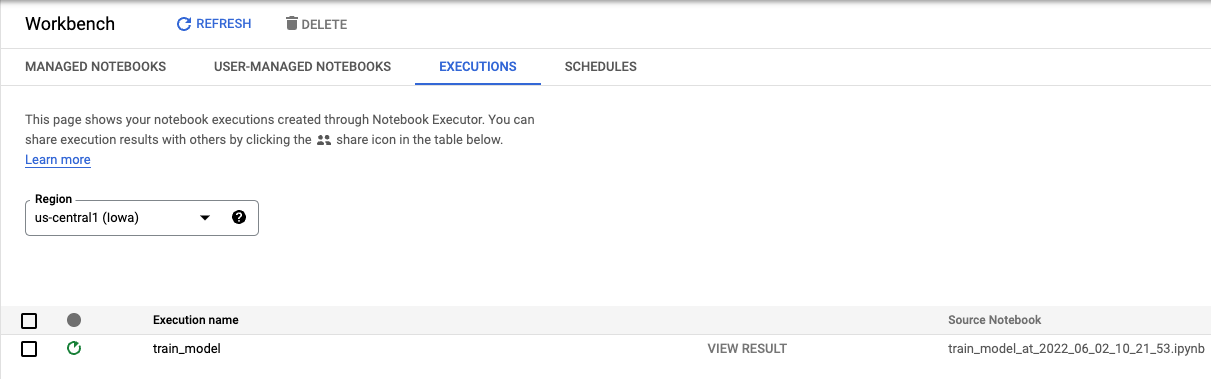
6. Déployer un modèle
Étape 1 : Importez le modèle
Une fois l'exécution terminée, revenez au notebook Workbench pour importer le modèle. Créez un notebook TensorFlow.

Commencez par importer le SDK Python Vertex AI.
from google.cloud import aiplatform
Ensuite, importez le modèle en remplaçant {YOUR_BUCKET} par le bucket que vous avez spécifié dans le code d'entraînement.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
À des fins de démonstration, nous allons importer ce modèle deux fois, ce qui créera deux ressources de modèle différentes dans Vertex AI. Cela nous permet de tester le déploiement de plusieurs modèles sur un même point de terminaison au sein d'un pool de ressources de déploiement. Dans un scénario réel, vous auriez deux modèles différents au lieu de créer des modèles à partir des mêmes artefacts enregistrés. Il s'agit toutefois d'un raccourci pour éviter de lancer une autre exécution d'entraînement. Vous pouvez également choisir de déployer les deux modèles sur des points de terminaison différents au sein du même pool de ressources de déploiement.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
Dans Vertex AI Model Registry, vous devriez maintenant voir les deux modèles. L'état du déploiement est vide, car nous n'avons pas encore déployé les modèles.
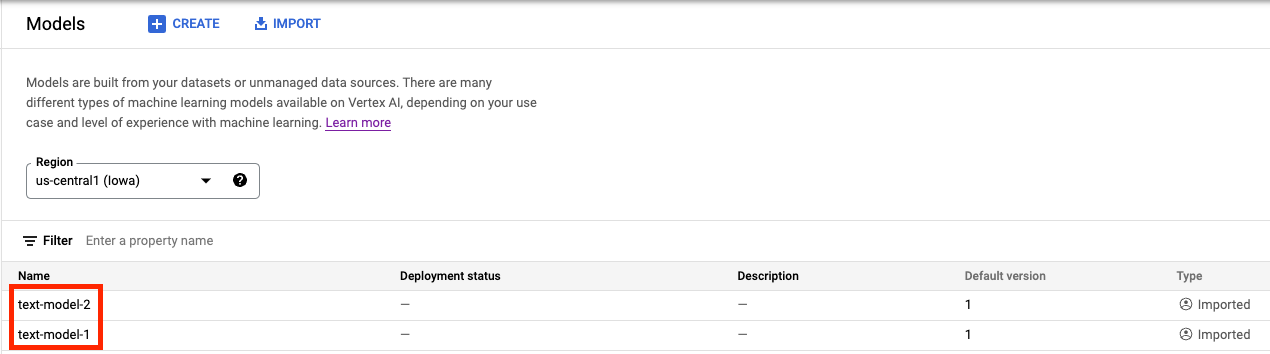
Étape 2 : Créez un point de terminaison
Créer un point de terminaison. Notez que cette opération est différente du déploiement d'un modèle sur un point de terminaison.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
Une fois le point de terminaison créé, il apparaît dans la console.
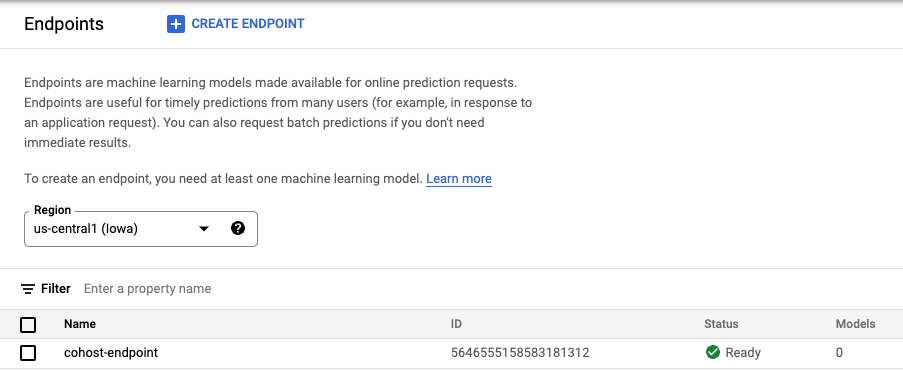
Étape 3 : Créer le DeploymentResourcePool
Vous pouvez créer DeploymentResourcePool à l'aide de la commande suivante. Veillez à remplacer {YOUR_PROJECT} par l'ID de votre projet.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
Vous pouvez voir le pool en exécutant
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
Étape 4 : Déployer les modèles sur le point de terminaison
Maintenant que le pool de ressources a été créé, nous pouvons déployer les modèles dans le pool de ressources.
Tout d'abord, nous allons déployer model_1. Veillez à remplacer MODEL_1_ID et ENDPOINT_ID par les ID respectifs.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
La commande suivante déploie model_1 au point de terminaison du pool de ressources.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Cette opération prendra quelques minutes, mais une fois terminée, vous verrez le modèle déployé sur le point de terminaison dans la console.
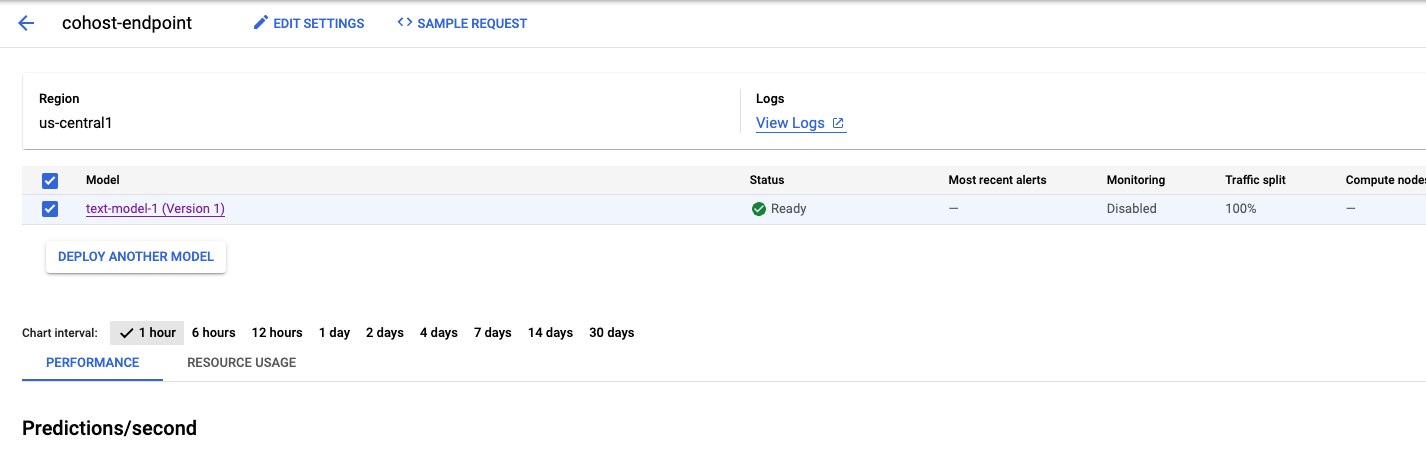
Nous pouvons ensuite déployer model_2 dans le même pool de déploiement. Nous allons le déployer sur le même point de terminaison que model_1. Toutefois, vous pouvez également choisir de déployermodel_2 sur un autre point de terminaison du même pool de ressources.
Remplacez MODEL_ID par l'ID de model_2. Vous pouvez obtenir cet ID en exécutant model_2.name.
MODEL_2_ID="{MODEL_2_ID}"
Déployez ensuite model_2. Étant donné que model_1 est déjà déployé sur le point de terminaison, nous devons mettre à jour trafficSplit afin que le trafic soit réparti entre les deux modèles. Nous n'aurions pas à mettre à jour trafficSplit si nous choisissions de déployer model_2 sur un autre point de terminaison au sein du même pool de ressources.
Pour mettre à jour la répartition du trafic, vous devez définir l'ID DeployedModel pour model_1. Notez que cette valeur est différente de l'ID du modèle.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
Exécutez ensuite la commande suivante pour déployer le deuxième modèle.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Dans cet exemple, les deux modèles ont été déployés sur le même point de terminaison, mais vous pouvez également les co-héberger dans le même pool de ressources, déployé sur des points de terminaison différents. Dans ce cas, vous n'aurez pas à vous soucier de la répartition du trafic.
Une fois le deuxième modèle déployé, vous les verrez tous les deux dans la console.
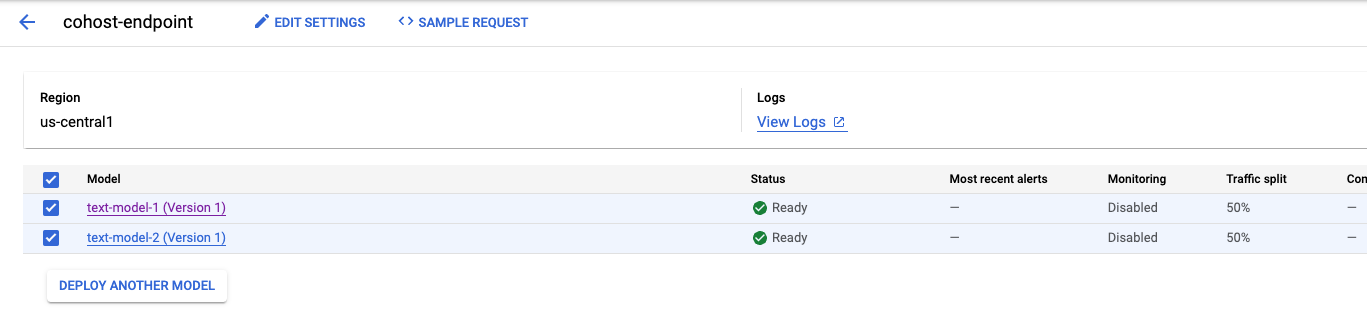
Étape 5 : Obtenir des prédictions
La dernière étape consiste à tester le point de terminaison et à obtenir des prédictions.
Tout d'abord, définissez notre phrase de test.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
Appelez ensuite la fonction de prédiction sur le point de terminaison, qui renverra une prédiction de l'un des modèles déployés sur le point de terminaison.
endpoint.predict(instances=x_test)
🎉 Félicitations ! 🎉
Vous savez désormais utiliser Vertex AI pour :
- Co-héberger des modèles sur la même VM pour les prédictions en ligne
Pour en savoir plus sur les différents composants de Vertex, consultez la documentation.
7. Nettoyage
Nous vous recommandons d'annuler le déploiement des modèles sur le point de terminaison si vous ne prévoyez pas de les utiliser. Vous pouvez également supprimer l'intégralité du point de terminaison. Vous pouvez toujours redéployer un modèle sur un point de terminaison si nécessaire.

Les notebooks gérés par Workbench expirent automatiquement après 180 minutes d'inactivité. Vous n'avez donc pas à vous soucier de l'arrêt de l'instance. Si vous souhaitez arrêter l'instance manuellement, cliquez sur le bouton "Arrêter" dans la section "Vertex AI Workbench" de la console. Si vous souhaitez supprimer le notebook définitivement, cliquez sur le bouton "Supprimer".

Pour supprimer le bucket de stockage, utilisez le menu de navigation de la console Cloud pour accéder à Stockage, sélectionnez votre bucket puis cliquez sur "Supprimer" :