1. Ringkasan
Di lab ini, Anda akan menggunakan fitur model hosting bersama di Vertex AI untuk menghosting beberapa model di VM yang sama untuk prediksi online.
Yang Anda pelajari
Anda akan mempelajari cara:
- Membuat
DeploymentResourcePool - Men-deploy model dalam
DeploymentResourcePool
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $2.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI. Jika Anda memiliki masukan, harap lihat halaman dukungan.
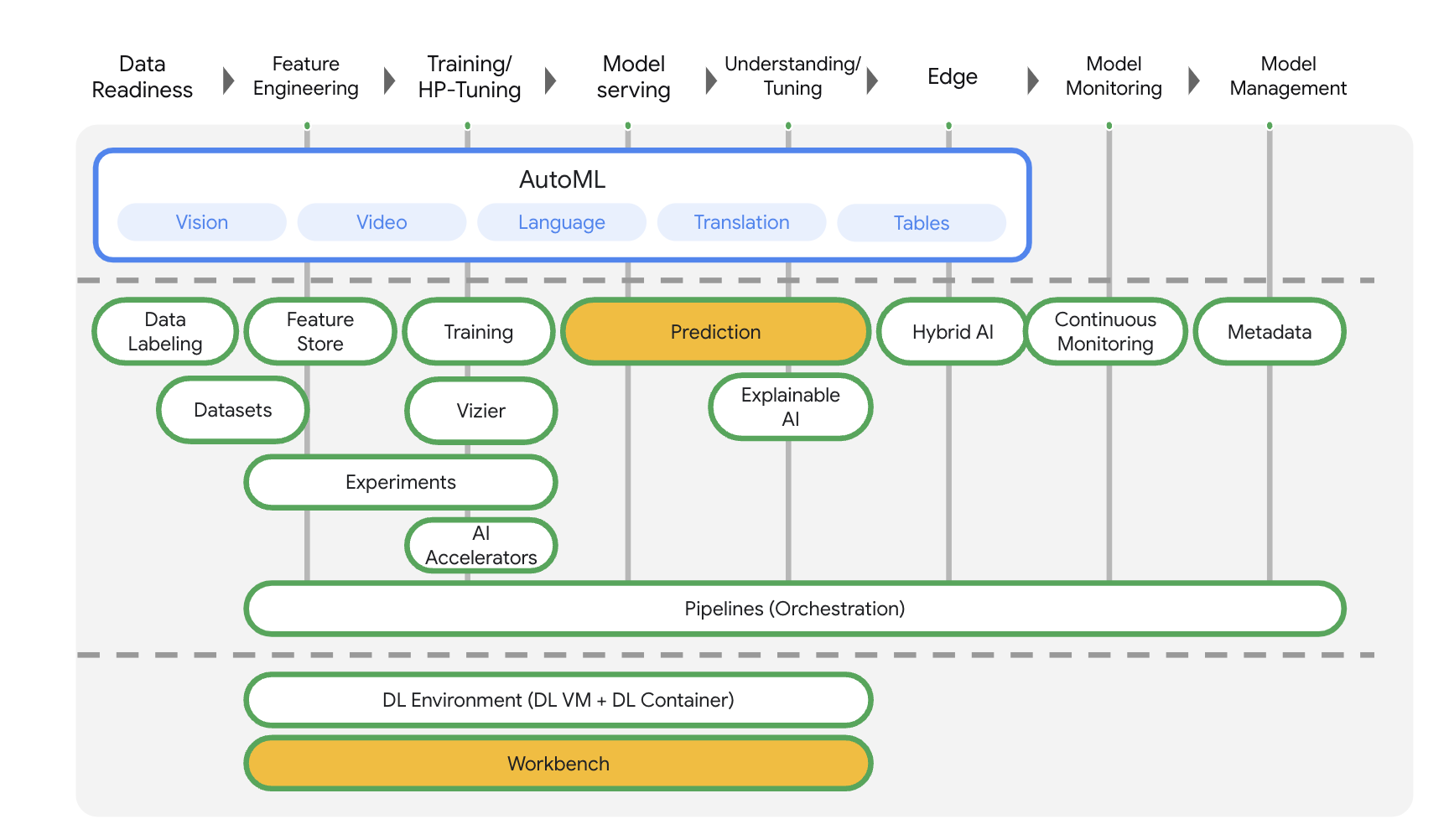
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada produk yang disorot di bawah: Prediksi dan Workbench
3. Ringkasan kasus penggunaan
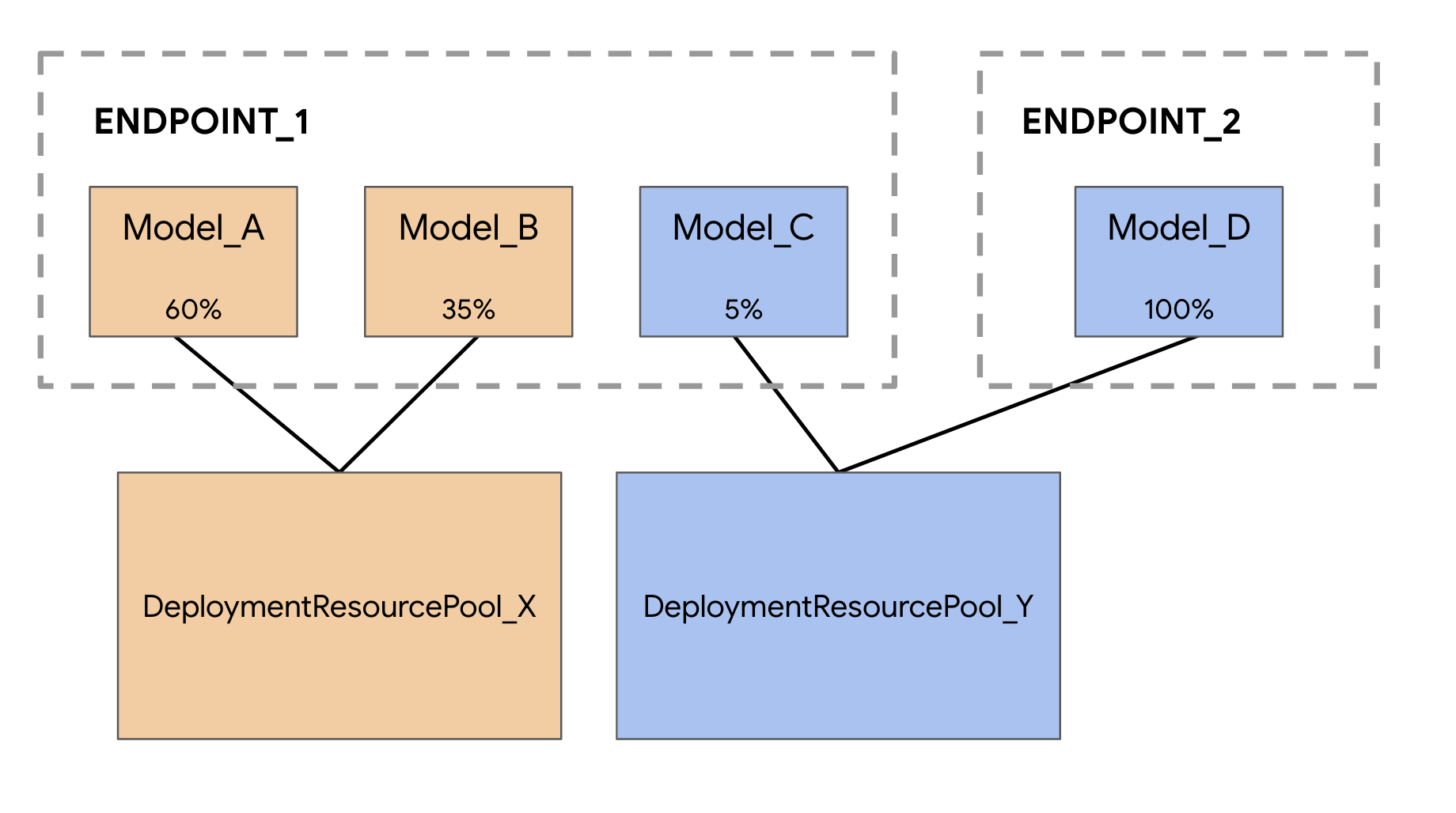
Saat men-deploy model ke layanan prediksi Vertex AI, setiap model di-deploy ke VM-nya sendiri secara default. Untuk membuat hosting lebih hemat biaya, Anda dapat menghosting beberapa model di VM yang sama, sehingga pemanfaatan memori dan resource komputasi menjadi lebih baik. Jumlah model yang Anda pilih untuk di-deploy ke VM yang sama akan bergantung pada ukuran model dan pola traffic, tetapi fitur ini sangat berguna untuk skenario saat Anda memiliki banyak model yang di-deploy dengan traffic yang jarang.
Dukungan model hosting bersama memperkenalkan konsep Kumpulan Resource Deployment, yang mengelompokkan model untuk berbagi resource dalam VM. Model dapat berbagi VM jika model tersebut berbagi endpoint, dan juga jika model tersebut di-deploy ke endpoint yang berbeda. Saat ini, model dalam kumpulan resource yang sama harus memiliki image container yang sama, termasuk versi framework container bawaan Vertex Prediction. Selain itu, hanya container bawaan Vertex Prediction dengan framework model Tensorflow yang didukung dalam rilis ini. Framework model lain dan container kustom belum didukung.
4. Menyiapkan lingkungan Anda
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Langkah 1: Aktifkan Compute Engine API
Buka Compute Engine dan pilih Aktifkan jika belum diaktifkan.
Langkah 2: Aktifkan Vertex AI API
Buka bagian Vertex AI di Cloud Console Anda, lalu klik Aktifkan Vertex AI API.
Langkah 3: Membuat instance Vertex AI Workbench
Dari bagian Vertex AI di Cloud Console Anda, klik Workbench:
Aktifkan Notebooks API jika belum diaktifkan.
Setelah diaktifkan, klik NOTEBOOK TERKELOLA:

Kemudian, pilih NOTEBOOK BARU.
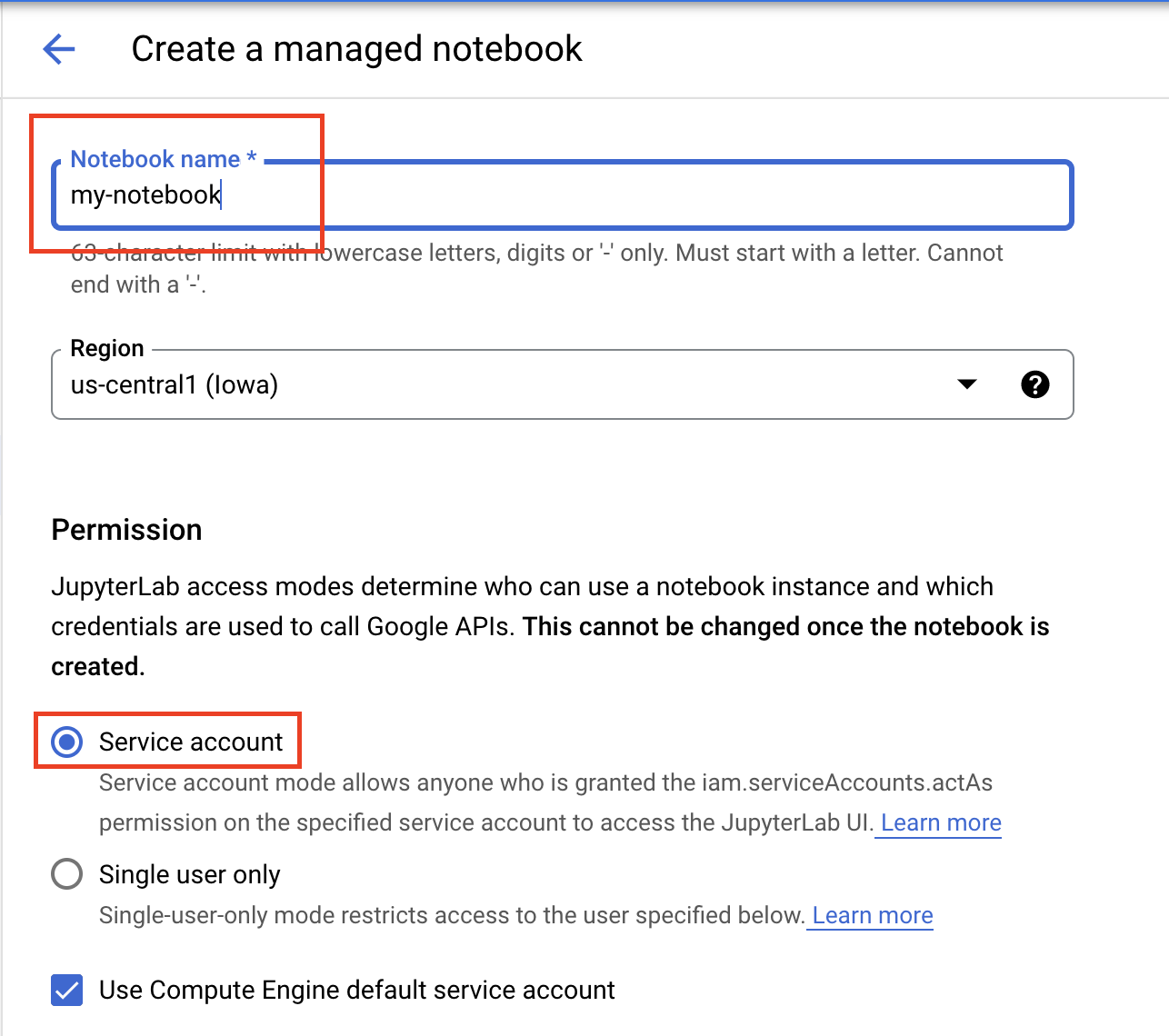
Namai notebook Anda, lalu di bagian Izin, pilih Akun layanan
Pilih Setelan Lanjutan.
Di bagian Keamanan, pilih "Aktifkan terminal" jika belum diaktifkan.
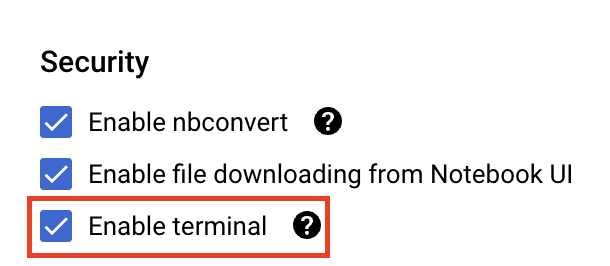
Anda dapat membiarkan semua setelan lanjutan lainnya apa adanya.
Selanjutnya, klik Buat. Instance akan memerlukan waktu beberapa menit untuk disediakan.
Setelah instance dibuat, pilih BUKA JUPYTERLAB.

5. Latih model
Sebelum dapat mencoba fitur co-hosting, kita harus melatih model terlebih dahulu dan menyimpan artefak model yang disimpan ke bucket Cloud Storage. Kita akan menggunakan Workbench notebook executor untuk meluncurkan tugas pelatihan.
Langkah 1: Buat bucket Cloud Storage
Jika memiliki bucket yang sudah ada di project yang ingin digunakan, Anda dapat melewati langkah ini. Jika tidak, buka sesi terminal baru dari peluncur.

Dari terminal, jalankan perintah berikut untuk menentukan variabel env untuk project Anda, pastikan untuk mengganti your-cloud-project dengan ID project Anda:
PROJECT_ID='your-cloud-project'
Selanjutnya, jalankan perintah berikut untuk membuat bucket baru dalam project Anda.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Langkah 2: Luncurkan eksekusi notebook
Dari peluncur instance Workbench Anda, buka notebook TensorFlow 2 baru.

Kode di bawah melatih pengklasifikasi sentimen biner (positif atau negatif) pada dataset ulasan film IMDB. Tempelkan kode ke notebook Anda.
Pastikan Anda mengganti {YOUR_BUCKET} dengan bucket yang Anda buat di langkah sebelumnya (atau bucket lain di project Anda). Di sini kita akan menyimpan artefak model tersimpan, yang akan kita perlukan nanti saat mengupload model ke Vertex AI Model Registry.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
Selanjutnya, pilih tombol Execute.
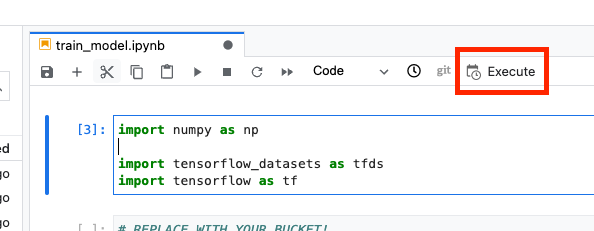
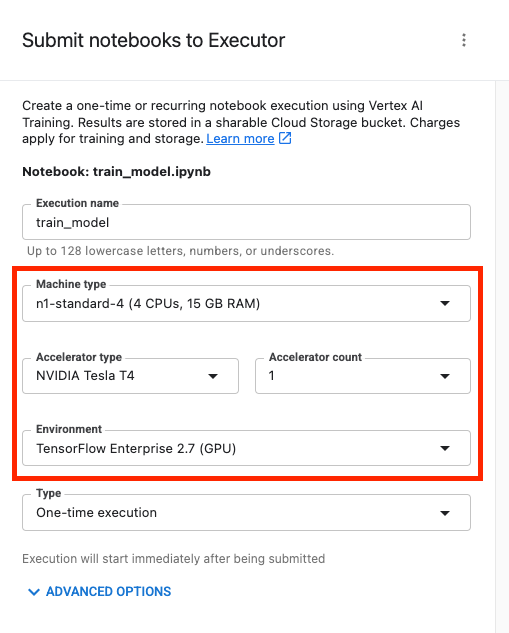
Kemudian, konfigurasi eksekusi Anda sebagai berikut, lalu klik SUBMIT
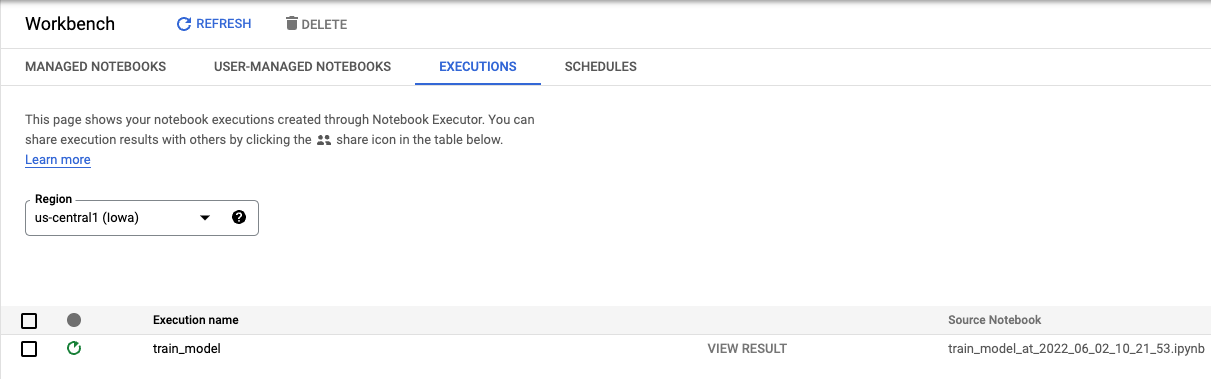
Dari tab Eksekusi di konsol, Anda dapat melacak status tugas pelatihan.
6. Deploy model
Langkah 1: Upload model
Setelah eksekusi selesai, kembali ke notebook Workbench untuk mengupload model. Buat notebook TensorFlow baru.

Pertama, impor Vertex AI Python SDK
from google.cloud import aiplatform
Kemudian, upload model, dengan mengganti {YOUR_BUCKET} dengan bucket yang Anda tentukan dalam kode pelatihan.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
Untuk tujuan demonstrasi, kita akan mengupload model ini dua kali, sehingga membuat dua resource model yang berbeda di Vertex AI. Hal ini dilakukan agar kita dapat menguji deployment beberapa model ke satu endpoint dalam kumpulan resource deployment. Dalam skenario nyata, Anda akan memiliki dua model yang berbeda, bukan membuat model dari artefak tersimpan yang sama, tetapi ini adalah cara pintas agar kita tidak perlu meluncurkan eksekusi pelatihan lain. Selain itu, Anda juga dapat memilih untuk men-deploy kedua model ke endpoint berbeda dalam kumpulan resource deployment yang sama.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
Di Vertex AI Model Registry, Anda akan melihat kedua model. Status deployment kosong karena kita belum men-deploy model.
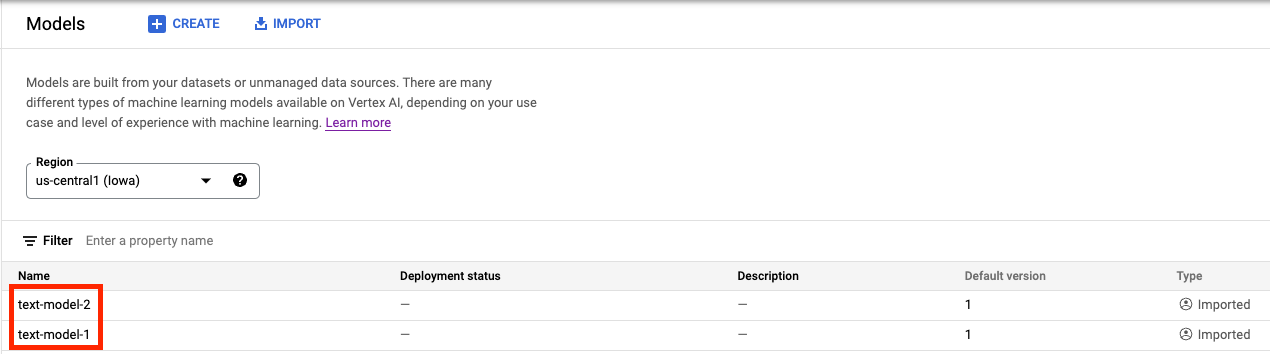
Langkah 2: Buat endpoint
Buat endpoint Perhatikan bahwa ini berbeda dengan men-deploy model ke endpoint.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
Setelah endpoint dibuat, Anda akan melihatnya di konsol.
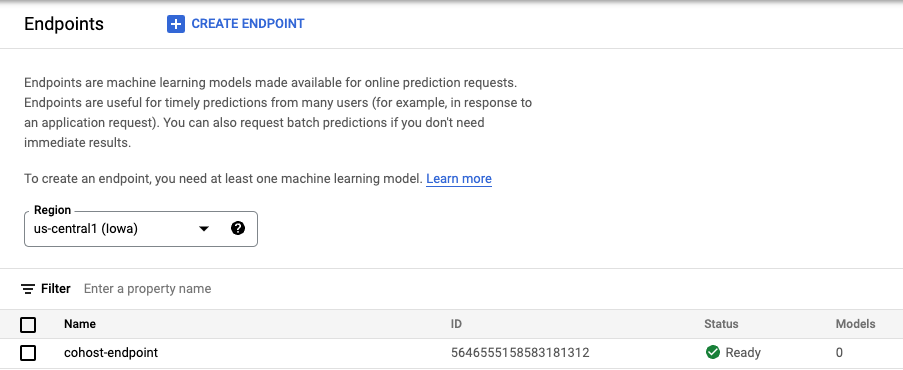
Langkah 3: Buat DeploymentResourcePool
Anda dapat membuat DeploymentResourcePool dengan perintah berikut. Pastikan untuk mengganti {YOUR_PROJECT} dengan project ID Anda.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
Anda dapat melihat kumpulan dengan menjalankan
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
Langkah 4: Deploy model ke endpoint
Setelah kumpulan resource dibuat, kita dapat men-deploy model dalam kumpulan resource.
Pertama, kita akan men-deploy model_1. Pastikan untuk mengganti MODEL_1_ID dan ENDPOINT_ID dengan ID masing-masing.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
Perintah berikut akan men-deploy model_1 ke endpoint dalam kumpulan resource.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Proses ini akan memerlukan waktu beberapa menit, tetapi setelah selesai, Anda akan melihat model yang di-deploy ke endpoint di konsol.
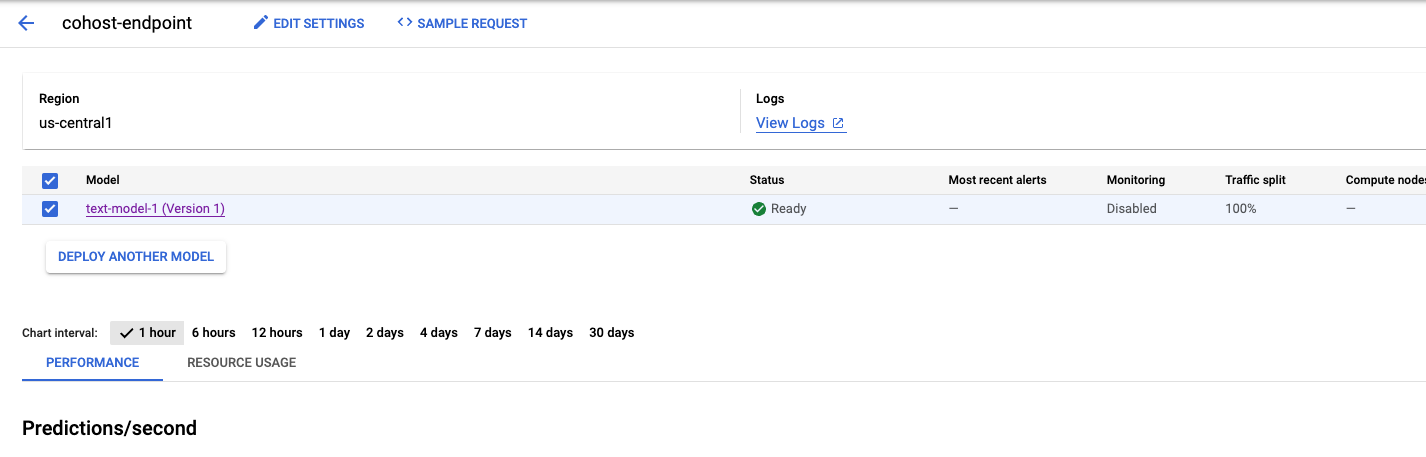
Selanjutnya, kita dapat men-deploy model_2 dalam kumpulan deployment yang sama. Kita akan men-deploy-nya ke endpoint yang sama dengan model_1. Namun, Anda juga dapat memilih untuk men-deploymodel_2 ke endpoint lain dalam kumpulan resource yang sama.
Perbarui MODEL_ID dengan ID untuk model_2. Sekali lagi, Anda bisa mendapatkan ID ini dengan menjalankan model_2.name
MODEL_2_ID="{MODEL_2_ID}"
Kemudian, deploy model_2. Karena kita sudah men-deploy model_1 ke endpoint, kita perlu memperbarui trafficSplit sehingga traffic dibagi antara kedua model. Kita tidak perlu memperbarui trafficSplit jika memilih untuk men-deploy model_2 ke endpoint lain dalam kumpulan resource yang sama.
Untuk memperbarui pembagian traffic, Anda harus menentukan ID DeployedModel untuk model_1. Perhatikan bahwa ini berbeda dengan ID model.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
Kemudian, jalankan perintah berikut untuk men-deploy model kedua.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Sekali lagi, dalam contoh ini, kedua model di-deploy ke endpoint yang sama, tetapi Anda juga dapat menghosting bersama model ke kumpulan resource yang sama yang di-deploy ke endpoint berbeda. Dalam hal ini, Anda tidak perlu mengkhawatirkan pemisahan traffic.
Setelah model kedua di-deploy, Anda akan melihat keduanya di konsol.
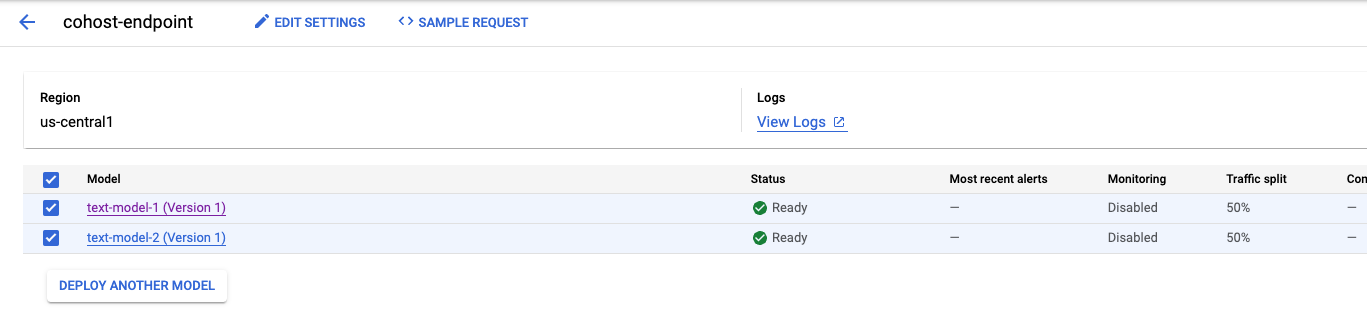
Langkah 5: Dapatkan prediksi
Langkah terakhir adalah menguji endpoint dan mendapatkan prediksi.
Pertama, tentukan kalimat pengujian kita.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
Kemudian, panggil prediksi di endpoint yang akan menampilkan prediksi dari salah satu model yang di-deploy ke endpoint.
endpoint.predict(instances=x_test)
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Meng-hosting bersama model di VM yang sama untuk prediksi online
Untuk mempelajari lebih lanjut berbagai bagian Vertex, lihat dokumentasinya.
7. Pembersihan
Anda dapat membatalkan deployment model dari endpoint tersebut jika tidak berencana menggunakannya. Anda juga dapat menghapus endpoint secara keseluruhan. Anda dapat men-deploy ulang model ke endpoint kapan saja jika diperlukan.

Notebook terkelola Workbench akan kehabisan waktu secara otomatis setelah 180 menit tidak ada aktivitas, jadi jangan khawatir untuk menonaktifkan instance-nya. Jika Anda ingin menonaktifkan instance secara manual, klik tombol Hentikan di bagian Vertex AI Workbench pada konsol. Jika Anda ingin menghapus notebook secara keseluruhan, klik tombol Hapus.

Untuk menghapus Bucket Penyimpanan, menggunakan menu Navigasi di Konsol Cloud, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus: