1. 개요
이 실습에서는 Vertex AI의 모델 공동 호스팅 기능을 사용하여 온라인 예측을 위해 동일한 VM에서 여러 모델을 호스팅합니다.
학습 내용
다음 작업을 수행하는 방법을 배우게 됩니다.
DeploymentResourcePool를 만드는 방법DeploymentResourcePool내에서 모델 배포
Google Cloud에서 이 실습을 진행하는 데 드는 총 비용은 약 $2입니다.
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다. 의견이 있는 경우 지원 페이지를 참고하세요.
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습에서는 아래에 강조 표시된 예측 및 Workbench 제품에 중점을 둡니다.
3. 사용 사례 개요
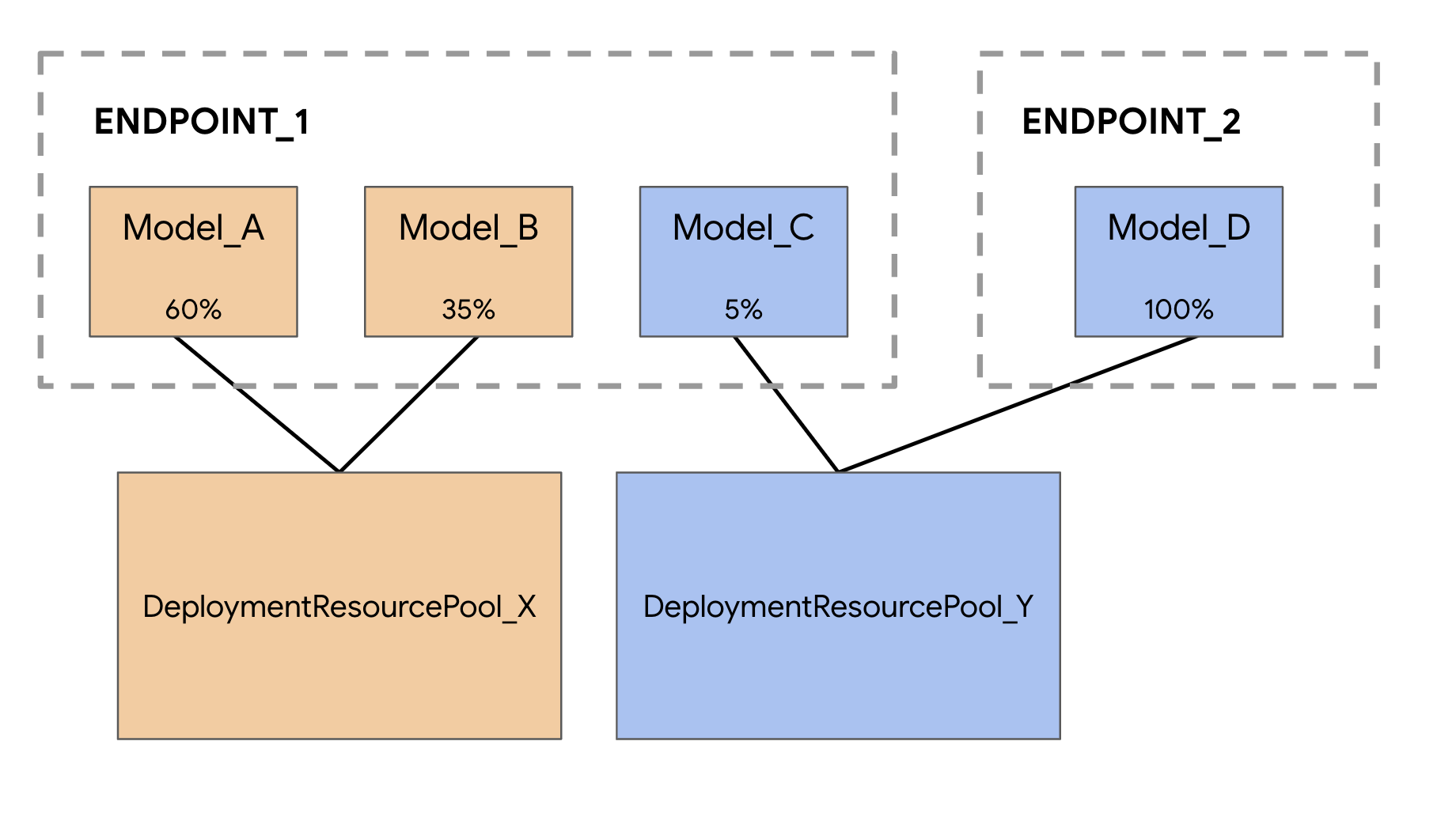
모델을 Vertex AI 예측 서비스에 배포할 때 각 모델은 기본적으로 자체 VM에 배포됩니다. 호스팅의 비용 효율성을 높이기 위해 동일한 VM에서 여러 모델을 호스팅할 수 있어 메모리 및 컴퓨팅 리소스의 활용도가 높아지는 결과를 얻을 수 있습니다. 동일한 VM에 배포하기 위해 선택하는 모델의 수는 모델 크기와 트래픽 패턴에 따라 달라지지만, 이 기능은 트래픽이 적은 모델을 많이 배포한 시나리오에 특히 유용합니다.
공동 호스팅 모델 지원은 VM 내에서 리소스를 공유하기 위해 모델을 함께 그룹화하는 배포 리소스 풀 개념을 도입합니다. 모델은 엔드포인트를 공유하는 경우뿐만 아니라 다른 엔드포인트에 배포되는 경우에도 VM을 공유할 수 있습니다. 현재 동일한 리소스 풀에 있는 모델은 Vertex Prediction 사전 빌드된 컨테이너의 프레임워크 버전을 포함한 컨테이너 이미지가 동일해야 합니다. 또한 이 출시에서는 Tensorflow 모델 프레임워크가 있는 Vertex 예측 사전 빌드된 컨테이너만 지원되며 다른 모델 프레임워크와 커스텀 컨테이너는 아직 지원되지 않습니다.
4. 환경 설정하기
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
1단계: Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine으로 이동하고 사용 설정을 선택합니다.
2단계: Vertex AI API 사용 설정
Cloud Console의 Vertex AI 섹션으로 이동하고 Vertex AI API 사용 설정을 클릭합니다.
3단계: Vertex AI Workbench 인스턴스 만들기
Cloud 콘솔의 Vertex AI 섹션에서 'Workbench'를 클릭합니다.
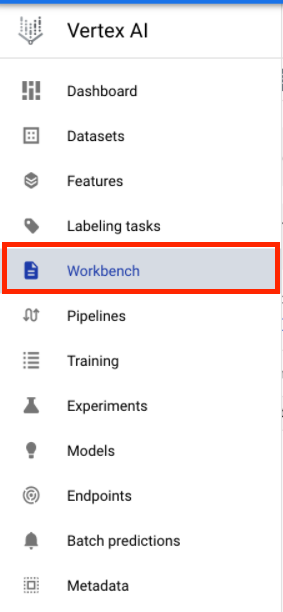
Notebooks API를 아직 사용 설정하지 않은 경우 사용 설정합니다.
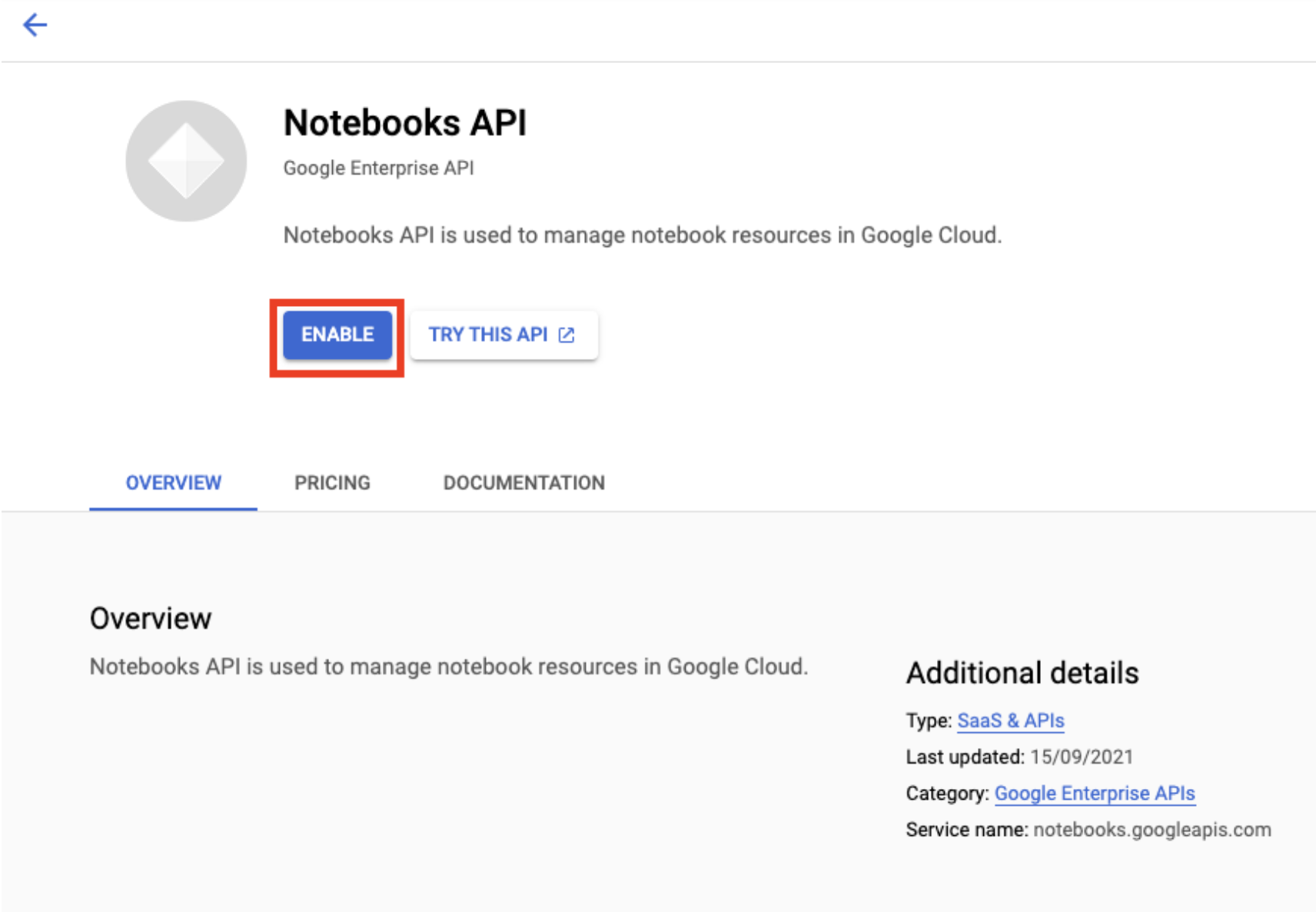
사용 설정했으면 관리형 노트북을 클릭합니다.

그런 다음 새 노트북을 선택합니다.
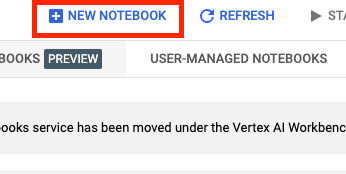
노트북 이름을 지정하고 권한에서 서비스 계정을 선택합니다.
고급 설정을 선택합니다.
아직 사용 설정되지 않은 경우 보안에서 '터미널 사용 설정'을 선택합니다.
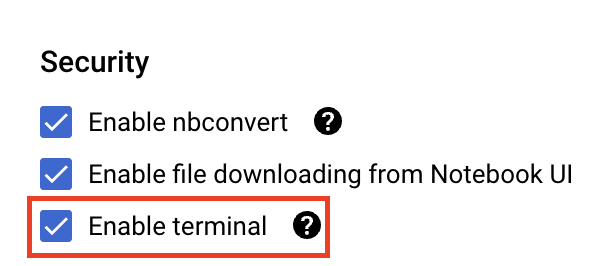
다른 고급 설정은 모두 그대로 두면 됩니다.
그런 다음 만들기를 클릭합니다. 인스턴스를 프로비저닝하는 데 몇 분 정도 걸립니다.
인스턴스가 생성되면 JupyterLab 열기를 선택합니다.

5. 모델 학습
공동 호스팅 기능을 사용해 보려면 먼저 모델을 학습시키고 저장된 모델 아티팩트를 Cloud Storage 버킷에 저장해야 합니다. Workbench 노트북 실행기를 사용하여 학습 작업을 실행합니다.
1단계: Cloud Storage 버킷 만들기
사용할 기존 버킷이 프로젝트에 있는 경우 이 단계를 건너뛸 수 있습니다. 그렇지 않으면 런처에서 새 터미널 세션을 엽니다.

터미널에서 다음을 실행하여 프로젝트의 env 변수를 정의하고 your-cloud-project를 프로젝트의 ID로 바꿉니다.
PROJECT_ID='your-cloud-project'
다음으로 다음 명령어를 실행하여 프로젝트에 새 버킷을 만듭니다.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
2단계: 노트북 실행 시작
Workbench 인스턴스의 런처에서 새로운 TensorFlow 2 노트북을 엽니다.

아래 코드는 IMDB 영화 리뷰 데이터 세트에서 이진 감정 분류기 (긍정 또는 부정)를 학습시킵니다. 코드를 노트북에 붙여넣습니다.
{YOUR_BUCKET}을 이전 단계에서 만든 버킷 (또는 프로젝트의 다른 버킷)으로 바꿔야 합니다. 여기에 저장된 모델 아티팩트가 저장됩니다. 이 아티팩트는 나중에 모델을 Vertex AI Model Registry에 업로드할 때 필요합니다.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
그런 다음 실행 버튼을 선택합니다.
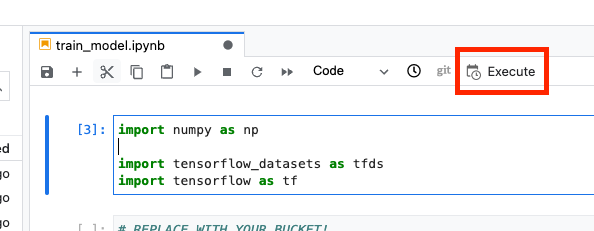
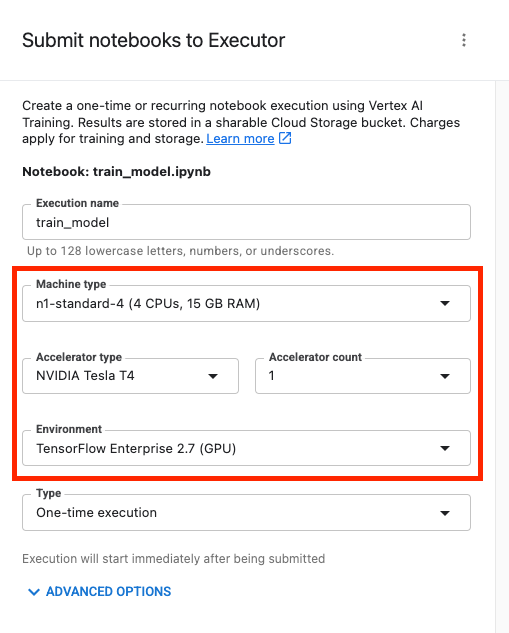
그런 다음 다음과 같이 실행을 구성하고 제출을 클릭합니다.
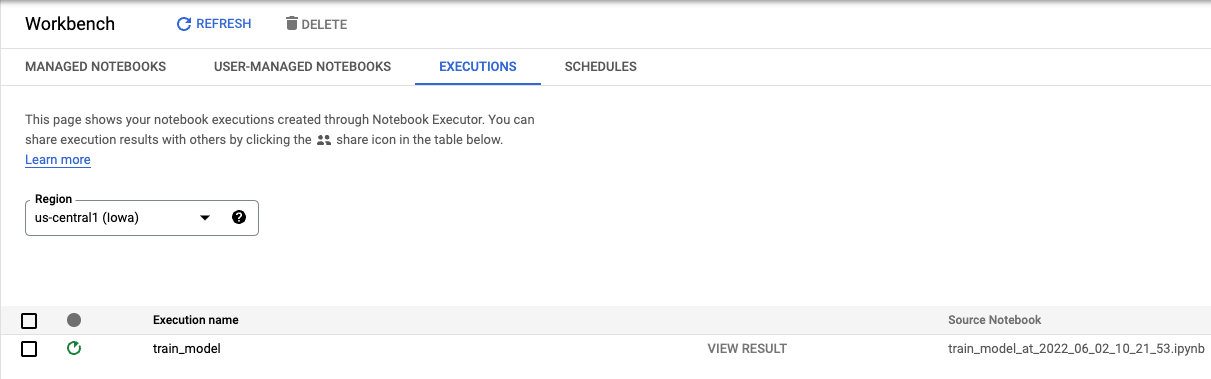
콘솔의 실행 탭에서 학습 작업의 상태를 추적할 수 있습니다.
6. 모델 배포
1단계: 모델 업로드
실행이 완료되면 워크벤치 노트북으로 돌아가 모델을 업로드합니다. 새 TensorFlow 노트북을 만듭니다.

먼저 Vertex AI Python SDK를 가져옵니다.
from google.cloud import aiplatform
그런 다음 모델을 업로드합니다. 이때 {YOUR_BUCKET}을 학습 코드에서 지정한 버킷으로 바꿉니다.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
데모를 위해 이 모델을 두 번 업로드하여 Vertex AI에서 두 개의 서로 다른 모델 리소스를 만듭니다. 이는 배포 리소스 풀 내의 단일 엔드포인트에 여러 모델을 배포하는 것을 테스트하기 위한 것입니다. 실제 시나리오에서는 동일한 저장된 아티팩트에서 모델을 만드는 대신 서로 다른 두 모델을 사용하지만, 여기서는 다른 학습 실행을 시작하지 않아도 되도록 이 방법을 사용합니다. 또한 동일한 배포 리소스 풀 내의 서로 다른 엔드포인트에 두 모델을 배포할 수도 있습니다.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
이제 Vertex AI Model Registry에 두 모델이 모두 표시됩니다. 아직 모델을 배포하지 않았으므로 배포 상태가 비어 있습니다.
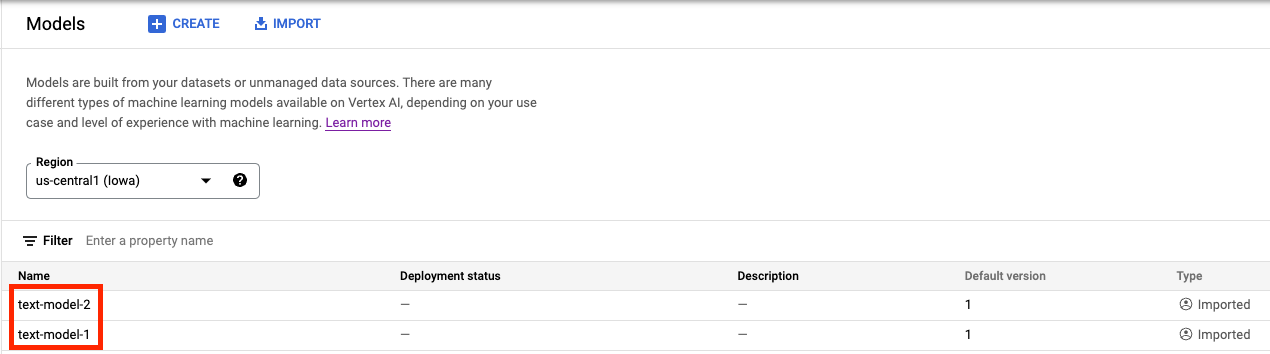
2단계: 엔드포인트 만들기
엔드포인트를 만듭니다. 엔드포인트에 모델을 배포하는 것과 다르다는 점에 유의하세요.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
엔드포인트가 생성되면 콘솔에 표시됩니다.
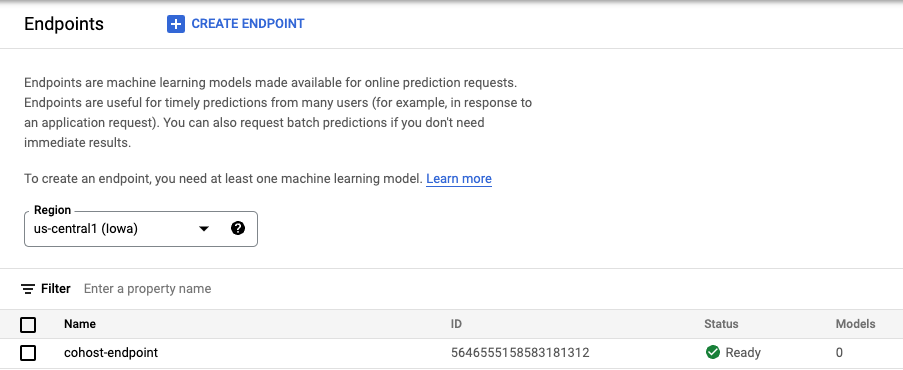
3단계: DeploymentResourcePool 만들기
다음 명령어로 DeploymentResourcePool을 만들 수 있습니다. {YOUR_PROJECT}을 프로젝트 ID로 바꿔야 합니다.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
다음을 실행하여 풀을 확인할 수 있습니다.
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
4단계: 엔드포인트에 모델 배포
이제 리소스 풀이 생성되었으므로 리소스 풀 내에 모델을 배포할 수 있습니다.
먼저 model_1를 배포합니다. MODEL_1_ID 및 ENDPOINT_ID을 각 ID로 바꿔야 합니다.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
다음 명령어는 리소스 풀 내의 엔드포인트에 model_1를 배포합니다.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
몇 분 정도 걸리지만 완료되면 콘솔에서 엔드포인트에 배포된 모델을 확인할 수 있습니다.
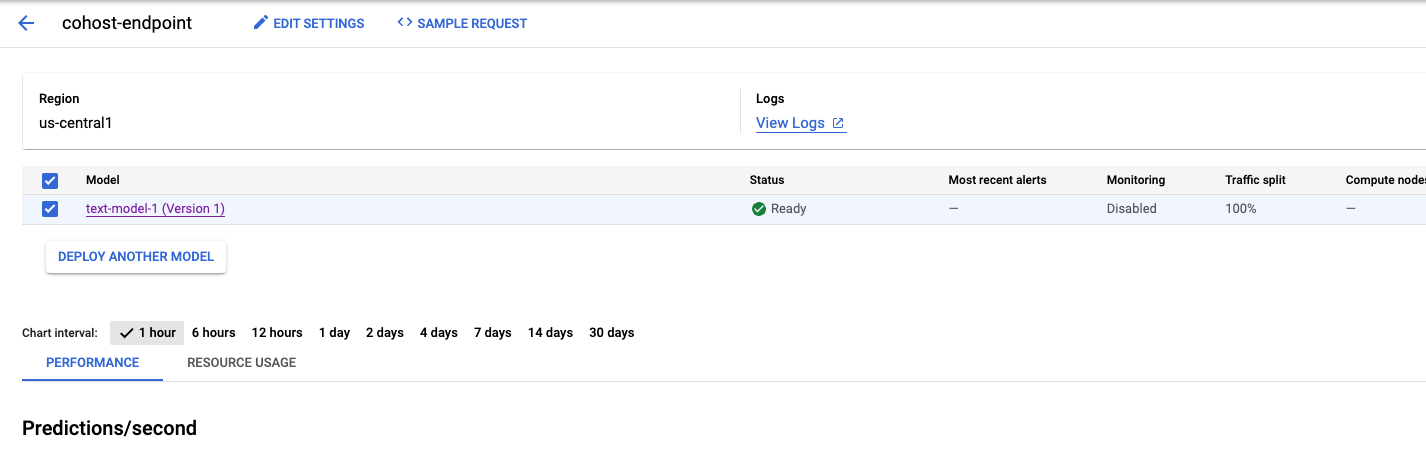
그런 다음 동일한 배포 풀 내에 model_2을 배포할 수 있습니다. model_1과 동일한 엔드포인트에 배포합니다. 하지만 동일한 리소스 풀 내의 다른 엔드포인트에model_2를 배포할 수도 있습니다.
MODEL_ID을 model_2의 ID로 업데이트합니다. model_2.name를 실행하여 이 ID를 가져올 수 있습니다.
MODEL_2_ID="{MODEL_2_ID}"
그런 다음 model_2를 배포합니다. 엔드포인트에 model_1가 이미 배포되어 있으므로 트래픽이 두 모델 간에 분할되도록 trafficSplit를 업데이트해야 합니다. 동일한 리소스 풀 내의 다른 엔드포인트에 model_2를 배포하는 경우 trafficSplit를 업데이트하지 않아도 됩니다.
트래픽 분할을 업데이트하려면 model_1의 DeployedModel ID를 정의해야 합니다. 이는 모델 ID와 다릅니다.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
그런 다음 다음을 실행하여 두 번째 모델을 배포합니다.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
이 예시에서는 두 모델이 동일한 엔드포인트에 배포되었지만 다른 엔드포인트에 배포된 모델을 동일한 리소스 풀에 공동 호스팅할 수도 있습니다. 이 경우 트래픽 분할에 대해 걱정하지 않아도 됩니다.
두 번째 모델이 배포되면 콘솔에 두 모델이 모두 표시됩니다.
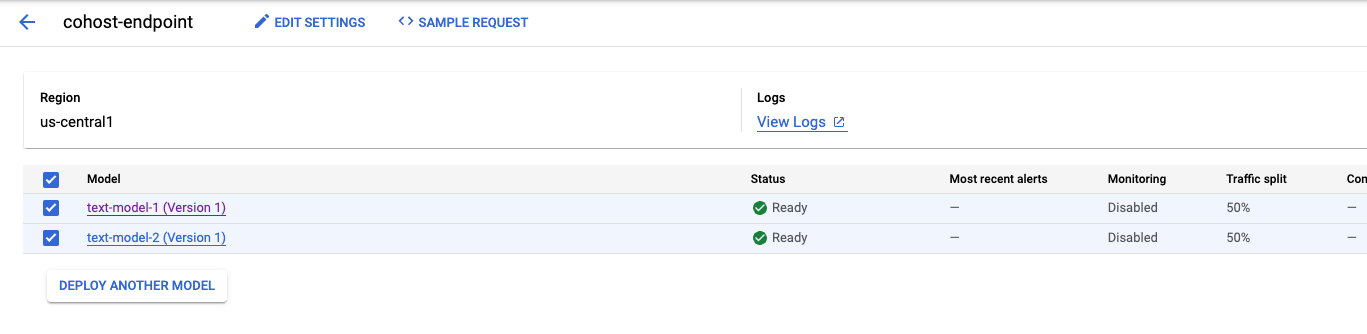
5단계: 예측 가져오기
마지막 단계는 엔드포인트를 테스트하고 예측을 가져오는 것입니다.
먼저 테스트 문장을 정의합니다.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
그런 다음 엔드포인트에서 predict를 호출합니다. 그러면 엔드포인트에 배포된 모델 중 하나의 예측이 반환됩니다.
endpoint.predict(instances=x_test)
🎉 수고하셨습니다. 🎉
Vertex AI를 사용하여 다음을 수행하는 방법을 배웠습니다.
- 온라인 예측을 위해 동일한 VM에 모델 공동 호스팅하기
Vertex의 다른 부분에 대해 자세히 알아보려면 문서를 확인하세요.
7. 정리
모델을 사용할 계획이 없다면 엔드포인트에서 모델 배포를 취소할 수 있습니다. 엔드포인트를 완전히 삭제할 수도 있습니다. 필요한 경우 언제든지 모델을 엔드포인트에 재배포할 수 있습니다.

Workbench 관리형 노트북은 180분의 유휴 시간이 지나면 자동으로 타임아웃되므로 인스턴스 종료에 대해 걱정할 필요가 없습니다. 인스턴스를 수동으로 종료하려면 콘솔의 Vertex AI Workbench 섹션에서 '중지' 버튼을 클릭합니다. 노트북을 완전히 삭제하려면 '삭제' 버튼을 클릭합니다.

스토리지 버킷을 삭제하려면 Cloud 콘솔의 탐색 메뉴를 사용하여 스토리지로 이동하고 버킷을 선택하고 '삭제'를 클릭합니다.