1. Descripción general
En este lab, usarás la función de co-hosting de modelos en Vertex AI para alojar varios modelos en la misma VM para realizar predicciones en línea.
Qué aprenderá
Aprenderás a hacer lo siguiente:
- Cómo crear un
DeploymentResourcePool - Implementa modelos dentro de un
DeploymentResourcePool
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $2.
2. Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI. Para enviarnos comentarios, visita la página de asistencia.
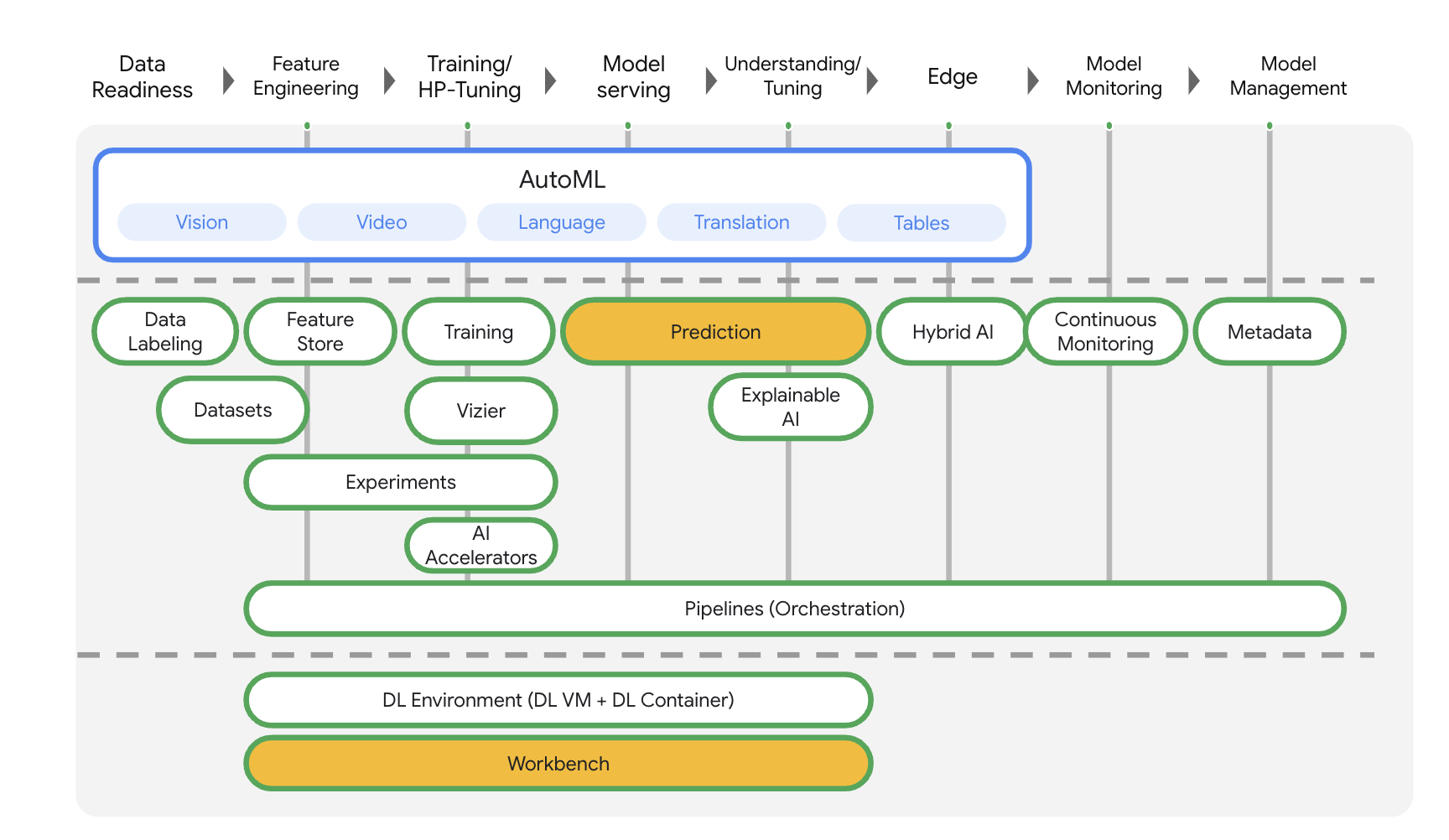
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se enfocará en los productos que se destacan a continuación: Prediction y Workbench
3. Descripción general del caso de uso
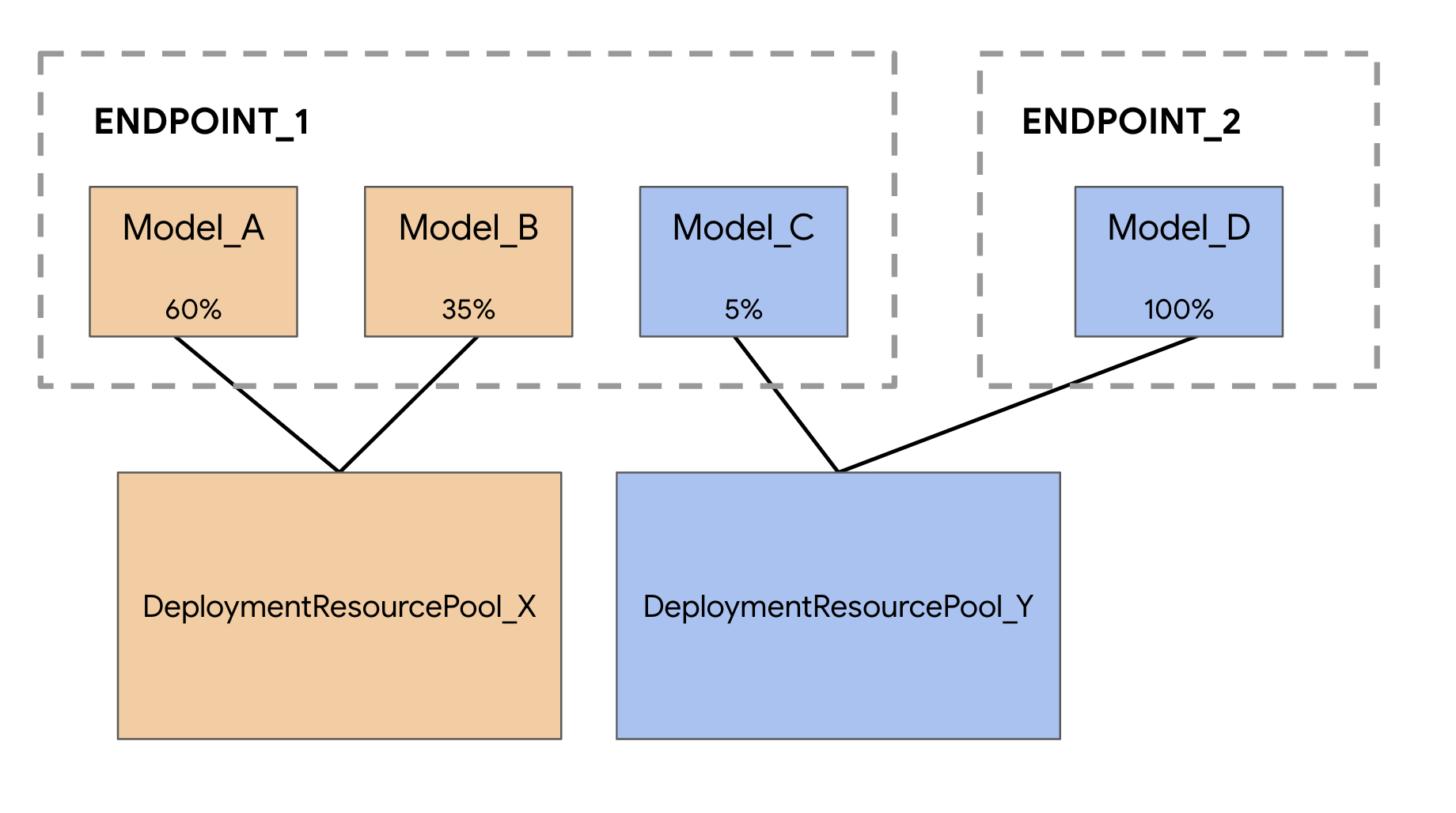
Cuando se implementan modelos en el servicio de predicción de Vertex AI, cada modelo se implementa de forma predeterminada en su propia VM. Para que el alojamiento sea más rentable, puedes alojar varios modelos en la misma VM, lo que genera una mejor utilización de la memoria y los recursos de procesamiento. La cantidad de modelos que elijas implementar en la misma VM dependerá de los tamaños de los modelos y de los patrones de tráfico, pero esta función es particularmente útil para situaciones en las que tienes muchos modelos implementados con tráfico escaso.
La compatibilidad con modelos de hosting compartido presenta el concepto de grupo de recursos de implementación, que agrupa modelos para compartir recursos dentro de una VM. Los modelos pueden compartir una VM si comparten un extremo y también si se implementan en diferentes extremos. Actualmente, los modelos del mismo grupo de recursos deben tener la misma imagen de contenedor, incluida la versión del framework de los contenedores previamente compilados de Vertex Prediction. Además, en esta versión solo se admiten contenedores precompilados de Vertex Prediction con el framework del modelo de TensorFlow. Aún no se admiten otros frameworks ni contenedores personalizados de modelos.
4. Configura el entorno
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform que tenga habilitada la facturación. Para crear un proyecto, sigue estas instrucciones.
Paso 1: Habilita la API de Compute Engine
Ve a Compute Engine y selecciona Habilitar (si aún no está habilitada).
Paso 2: Habilita la API de Vertex AI
Navegue hasta la sección de Vertex AI en la consola de Cloud y haga clic en Habilitar API de Vertex AI.
Paso 3: Crea una instancia de Vertex AI Workbench
En la sección Vertex AI de Cloud Console, haz clic en Workbench:
Habilita la API de Notebooks si aún no está habilitada.
Una vez habilitada, haz clic en NOTEBOOKS ADMINISTRADOS (MANAGED NOTEBOOKS):

Luego, selecciona NUEVO NOTEBOOK (NEW NOTEBOOK).
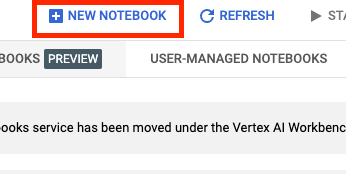
Asígnale un nombre al notebook y en Permiso (Permission), selecciona Cuenta de servicio (Service account).
Selecciona Configuración avanzada.
En Seguridad (Security), selecciona la opción “Habilitar terminal” (Enable terminal) si aún no está habilitada.
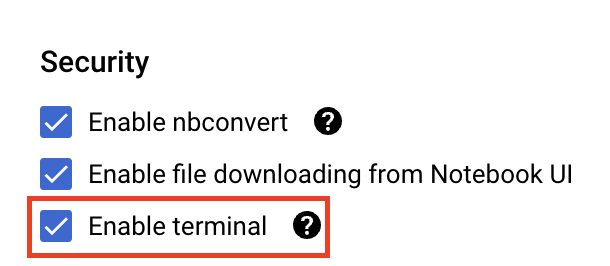
Puedes dejar el resto de la configuración avanzada tal como está.
Luego, haz clic en Crear. La instancia tardará algunos minutos en aprovisionarse.
Una vez que se cree la instancia, selecciona ABRIR JUPYTERLAB (OPEN JUPYTERLAB).

5. Entrenar modelo
Antes de probar la función de coalojamiento, primero debemos entrenar un modelo y almacenar los artefactos del modelo guardado en un bucket de Cloud Storage. Usaremos el ejecutor del notebook de Workbench para iniciar el trabajo de entrenamiento.
Paso 1: Crea un bucket de Cloud Storage
Si tienes un bucket existente en tu proyecto que deseas usar, puedes omitir este paso. De lo contrario, desde el selector, abre una nueva sesión de terminal.

En la terminal, ejecuta lo siguiente para definir una variable de entorno para tu proyecto y asegúrate de reemplazar your-cloud-project por el ID de tu proyecto:
PROJECT_ID='your-cloud-project'
Luego, ejecuta el siguiente comando para crear un bucket nuevo en tu proyecto.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Paso 2: Inicia la ejecución del notebook
Desde el selector de tu instancia de Workbench, abre un nuevo notebook de TensorFlow 2.

El siguiente código entrena un clasificador de opiniones binario (positivo o negativo) en el conjunto de datos de opiniones sobre películas de IMDB. Pega el código en tu notebook.
Asegúrate de reemplazar {YOUR_BUCKET} por el bucket que creaste en el paso anterior (o por otro bucket de tu proyecto). Aquí es donde almacenaremos los artefactos del modelo guardado, que necesitaremos más adelante cuando suba el modelo a Vertex AI Model Registry.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
Luego, selecciona el botón Ejecutar.
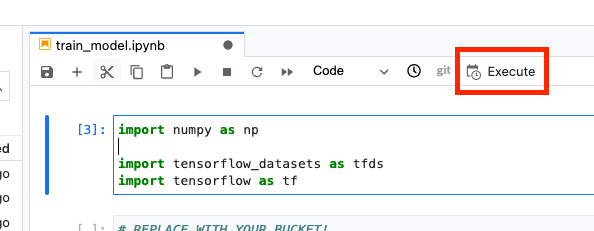
Luego, configura tu ejecución de la siguiente manera y haz clic en ENVIAR.
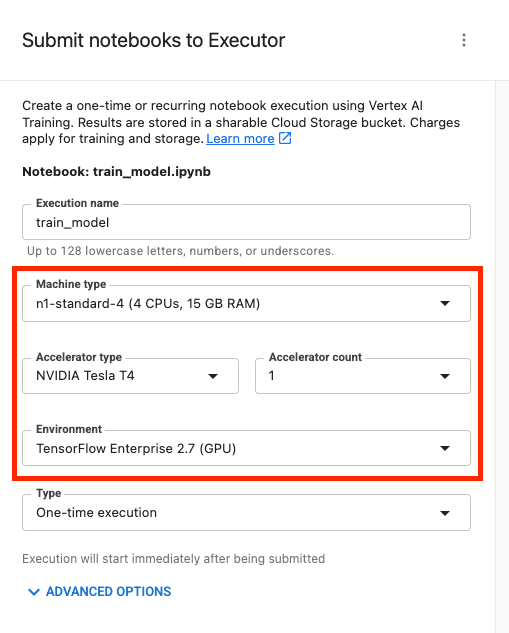
En la pestaña Ejecuciones de la consola, puedes hacer un seguimiento del estado de tu trabajo de entrenamiento.
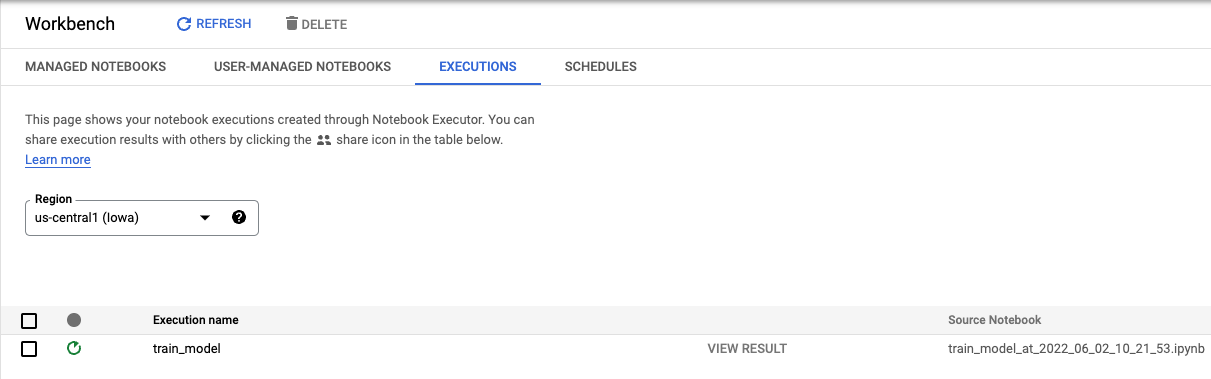
6. Implementar el modelo
Paso 1: Sube el modelo
Cuando se complete la ejecución, regresa al notebook de Workbench para subir el modelo. Crea un nuevo notebook de TensorFlow.

Primero, importa el SDK de Vertex AI para Python
from google.cloud import aiplatform
Luego, sube el modelo y reemplaza {YOUR_BUCKET} por el bucket que especificaste en el código de entrenamiento.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
A modo de demostración, subiremos este modelo dos veces y crearemos dos recursos de modelo diferentes en Vertex AI. Esto es para que podamos probar la implementación de varios modelos en un solo extremo dentro de un grupo de recursos de implementación. En una situación real, tendrías dos modelos diferentes en lugar de crear modelos a partir de los mismos artefactos guardados, pero este es un atajo para que no tengamos que iniciar otra ejecución de entrenamiento. Además, también puedes implementar los dos modelos en extremos diferentes dentro del mismo grupo de recursos de implementación.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
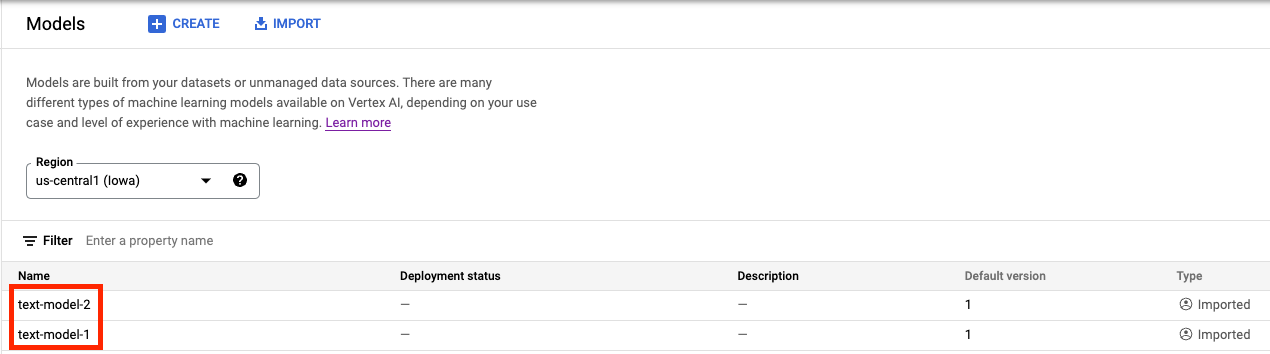
En Vertex AI Model Registry, deberías ver ambos modelos. El estado de implementación está en blanco porque aún no implementamos los modelos.
Paso 2: Crea un extremo
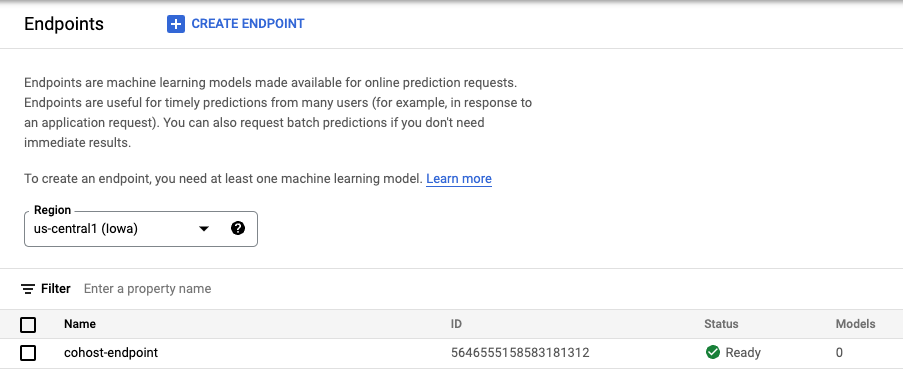
Crear un extremo. Ten en cuenta que esto es diferente de implementar un modelo en un extremo.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
Cuando se cree el extremo, lo verás en la consola.
Paso 3: Crea el DeploymentResourcePool
Puedes crear el DeploymentResourcePool con el siguiente comando. Asegúrate de reemplazar {YOUR_PROJECT} por tu ID del proyecto.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
Para ver el grupo, ejecuta
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
Paso 4: Implementa los modelos en el extremo
Ahora que se creó el grupo de recursos, podemos implementar los modelos dentro de él.
Primero, implementaremos model_1. Asegúrate de reemplazar MODEL_1_ID y ENDPOINT_ID por los IDs respectivos.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
El siguiente comando implementará model_1 en el extremo dentro del grupo de recursos.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Este proceso tardará unos minutos, pero cuando se complete, verás el modelo implementado en el extremo en la consola.
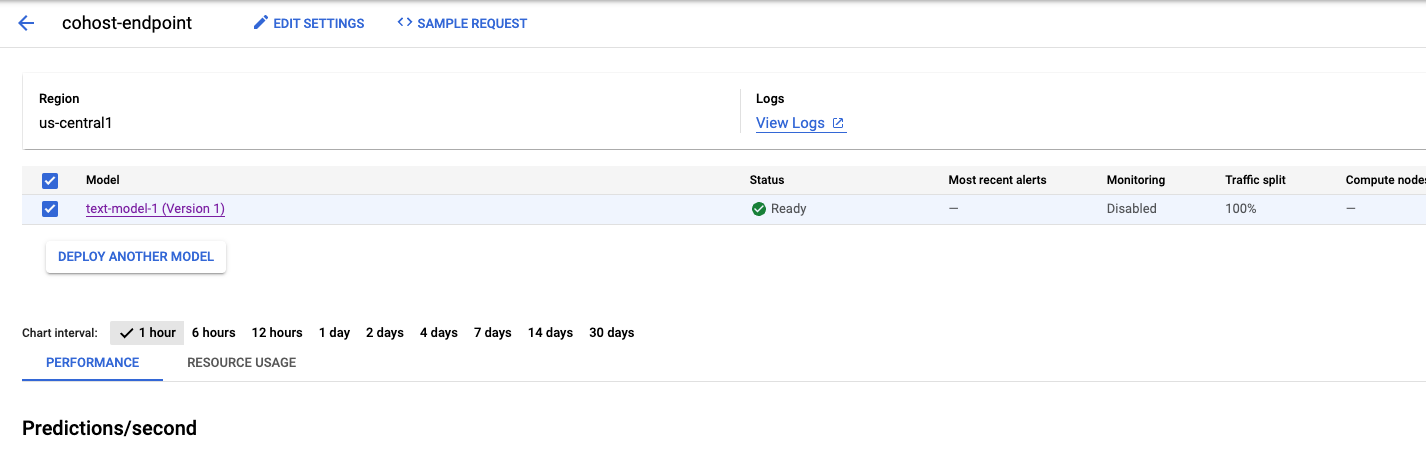
A continuación, podemos implementar model_2 dentro del mismo grupo de implementación. La implementaremos en el mismo extremo que model_1. Sin embargo, también puedes implementar model_2 en un extremo diferente dentro del mismo grupo de recursos.
Actualiza MODEL_ID con el ID de model_2. Una vez más, puedes obtener este ID si ejecutas model_2.name.
MODEL_2_ID="{MODEL_2_ID}"
Luego, implementa model_2. Como ya implementamos model_1 en el extremo, debemos actualizar trafficSplit para que el tráfico se divida entre los dos modelos. No tendríamos que actualizar trafficSplit si elegimos implementar model_2 en un extremo diferente dentro del mismo grupo de recursos.
Para actualizar la división del tráfico, deberás definir el ID de DeployedModel para model_1. Ten en cuenta que es diferente del ID del modelo.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
Luego, ejecuta el siguiente comando para implementar el segundo modelo.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Nuevamente, en este ejemplo, los dos modelos se implementaron en el mismo extremo, pero también puedes alojar modelos en el mismo grupo de recursos que se implementaron en extremos diferentes. En ese caso, no tendrías que preocuparte por la división del tráfico.
Después de implementar el segundo modelo, verás ambos en la consola.
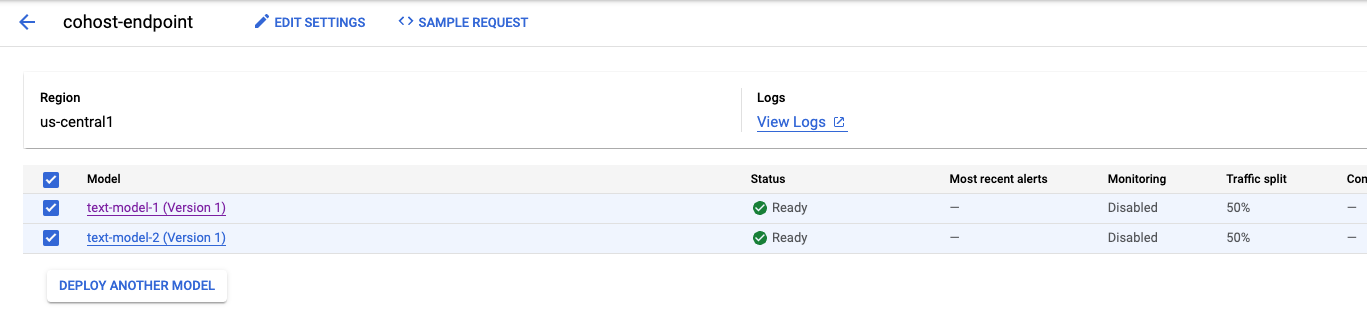
Paso 5: Obtén predicciones
El último paso es probar el extremo y obtener predicciones.
Primero, definamos nuestra oración de prueba.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
Luego, llama a predict en el extremo, que mostrará una predicción de uno de los modelos implementados en el extremo.
endpoint.predict(instances=x_test)
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI para hacer lo siguiente:
- Aloja modelos en la misma VM para predicciones en línea
Para obtener más información sobre las distintas partes de Vertex, consulte la documentación.
7. Realiza una limpieza
Te recomendamos anular la implementación de los modelos en el extremo si no planeas usarlos. También puedes borrar todo el extremo. Puedes volver a implementar los modelos si lo necesitas.

El tiempo de espera de los notebooks administrados de Workbench se agota automáticamente después de 180 minutos de inactividad, por lo que no necesitas preocuparte de cerrar la instancia. Si quieres cerrar la instancia de forma manual, haz clic en el botón Detener (Stop) en la sección Vertex AI Workbench de la consola. Si quieres borrar el notebook por completo, haz clic en el botón Borrar (Delete).

Para borrar el bucket de almacenamiento, en el menú de navegación de la consola de Cloud, navega a Almacenamiento, selecciona tu bucket y haz clic en Borrar (Delete):