1. Visão geral
Neste laboratório, você vai usar o recurso de modelo de co-hospedagem na Vertex AI para hospedar vários modelos na mesma VM para previsões on-line.
Conteúdo do laboratório
Você vai aprender a:
- Criar um
DeploymentResourcePool - Implantar modelos em um
DeploymentResourcePool
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$ 2.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos existentes para a Vertex AI. Se você tiver algum feedback, consulte a página de suporte.
A Vertex AI inclui vários produtos diferentes para dar suporte a fluxos de trabalho integrais de ML. Os produtos destacados abaixo são o foco deste laboratório: Previsões e Workbench
3. Visão geral do caso de uso
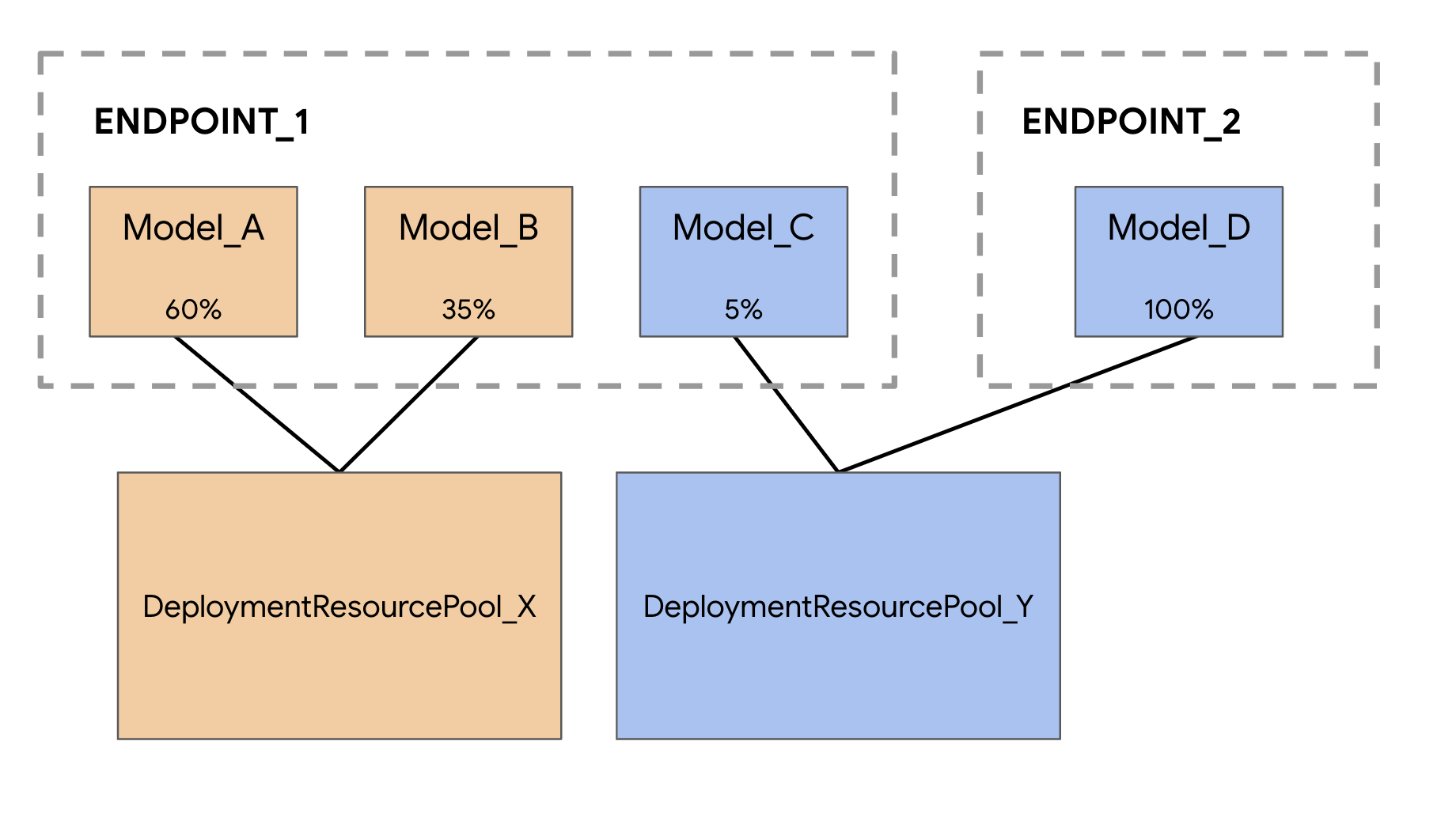
Ao implantar modelos no serviço de previsão da Vertex AI, cada modelo é implantado por padrão na própria VM. Para tornar a hospedagem mais econômica, é possível hospedar vários modelos na mesma VM, resultando em melhor utilização da memória e dos recursos computacionais. O número de modelos que você escolhe implantar na mesma VM depende dos tamanhos dos modelos e dos padrões de tráfego, mas esse recurso é particularmente útil para cenários em que você tem muitos modelos implantados com tráfego esparso.
A compatibilidade com co-hospedagem de modelos introduz o conceito de pool de recursos de implantação, que agrupa modelos para compartilhar recursos em uma VM. Os modelos podem compartilhar uma VM se compartilharem um endpoint e também se forem implantados em endpoints diferentes. No momento, os modelos no mesmo pool de recursos precisam ter a mesma imagem de contêiner, incluindo a versão do framework dos contêineres pré-criados da Vertex Prediction. Além disso, somente os contêineres pré-criados do Vertex Prediction com o framework de modelo do TensorFlow são compatíveis nesta versão. Outros frameworks de modelo e contêineres personalizados ainda não são compatíveis.
4. Configurar o ambiente
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Etapa 1: ativar a API Compute Engine
Acesse o Compute Engine e selecione Ativar, caso essa opção ainda não esteja ativada.
Etapa 2: ativar a API Vertex AI
Navegue até a seção "Vertex AI" do Console do Cloud e clique em Ativar API Vertex AI.
Etapa 3: criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":
Ative a API Notebooks, se ela ainda não tiver sido ativada.
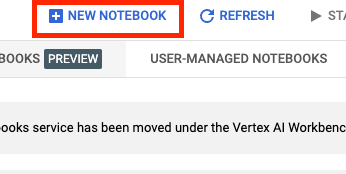
Após a ativação, clique em NOTEBOOK GERENCIADO:

Em seguida, selecione NOVO NOTEBOOK.
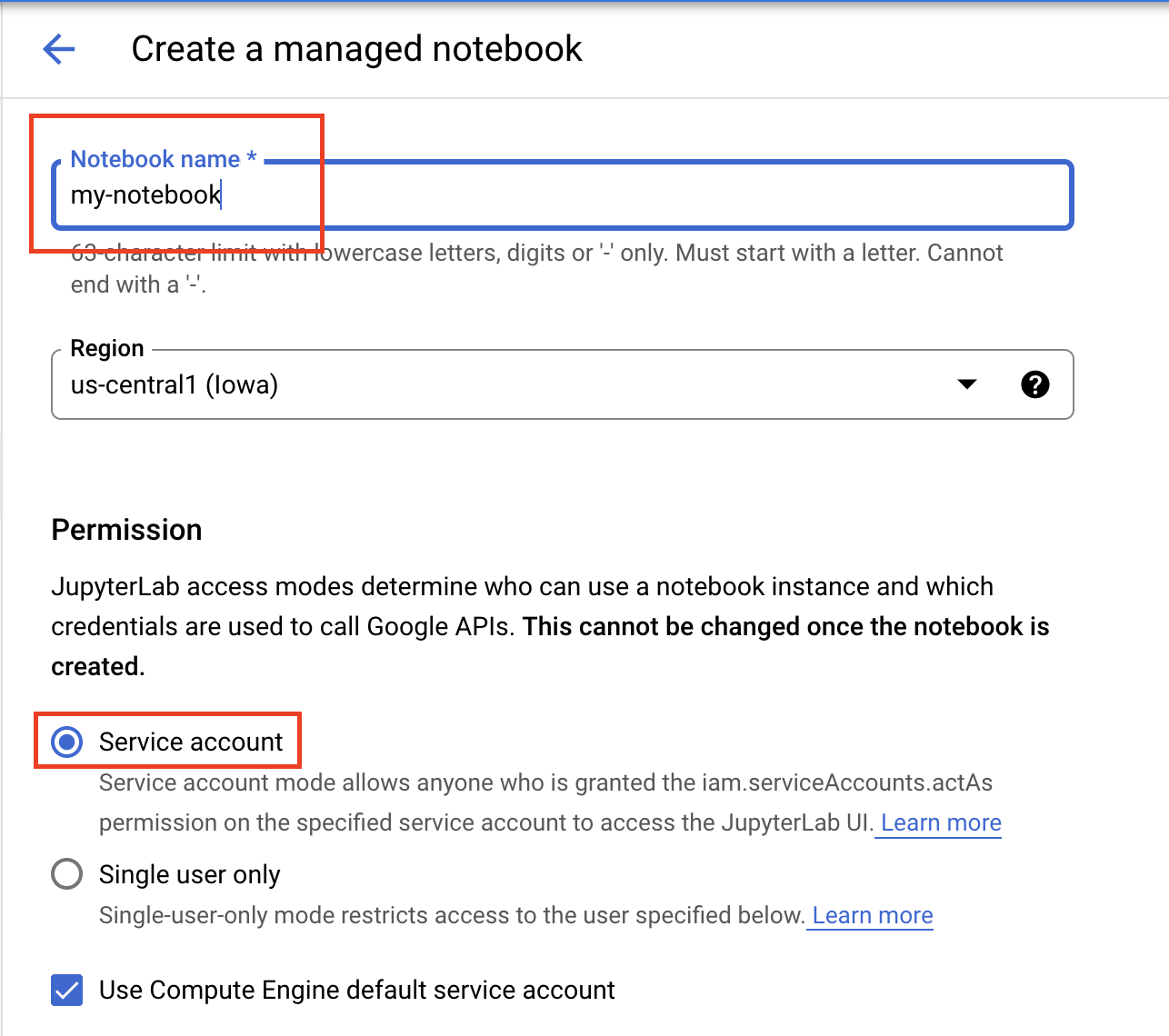
Dê um nome ao notebook. Em Permissão selecione Conta de serviço.
Selecione Configurações avançadas.
Em Segurança, selecione "Ativar terminal", se essa opção ainda não estiver ativada.
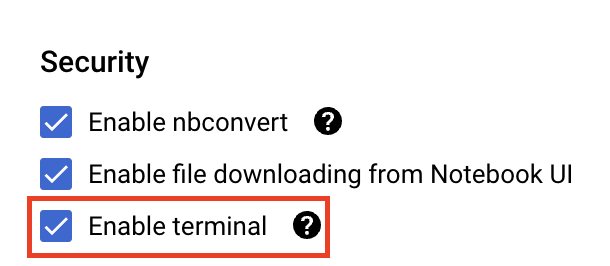
Você pode manter as outras configurações avançadas como estão.
Em seguida, clique em Criar. O provisionamento da instância vai levar alguns minutos.
Quando a instância tiver sido criada, selecione ABRIR O JUPYTERLAB.

5. Treinar modelo
Antes de testar o recurso de co-hospedagem, precisamos treinar um modelo e armazenar os artefatos salvos em um bucket do Cloud Storage. Vamos usar o executor de notebook do Workbench para iniciar o job de treinamento.
Etapa 1: criar um bucket do Cloud Storage
Se você já tiver um bucket no projeto que quer usar, pule esta etapa. Caso contrário, abra uma nova sessão de terminal na tela de início.

No terminal, execute o comando a seguir e defina uma variável env para o projeto. Lembre-se de substituir your-cloud-project pelo ID do projeto.
PROJECT_ID='your-cloud-project'
Em seguida, execute o comando abaixo para criar um novo bucket no projeto.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Etapa 2: iniciar a execução do notebook
Na tela de início da sua instância do Workbench, abra um novo notebook do TensorFlow 2.

O código abaixo treina um classificador de sentimento binário (positivo ou negativo) no conjunto de dados de avaliações de filmes do IMDB. Cole o código no notebook.
Substitua {YOUR_BUCKET} pelo bucket criado na etapa anterior (ou outro bucket no projeto). É aqui que vamos armazenar os artefatos do modelo salvo, que vamos precisar mais tarde ao fazer upload do modelo para o Vertex AI Model Registry.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
Em seguida, clique no botão Executar.
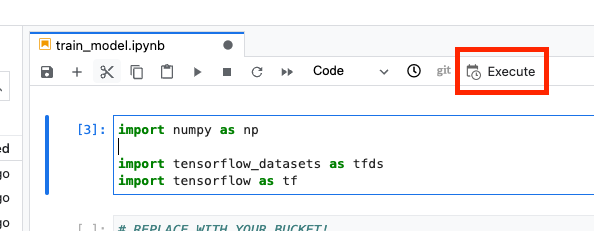
Em seguida, configure a execução da seguinte maneira e clique em ENVIAR.
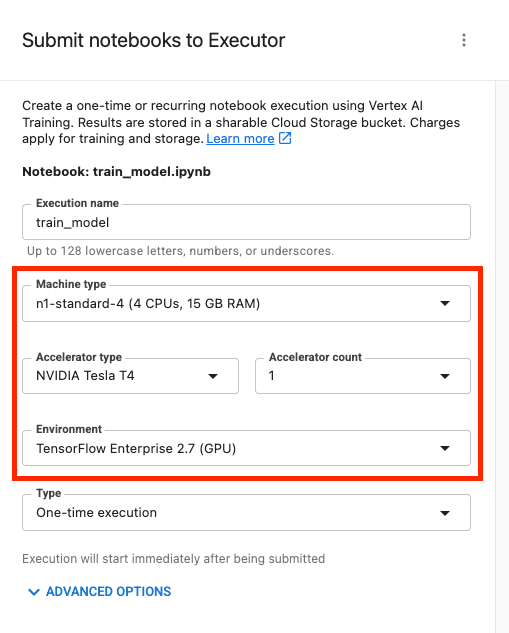
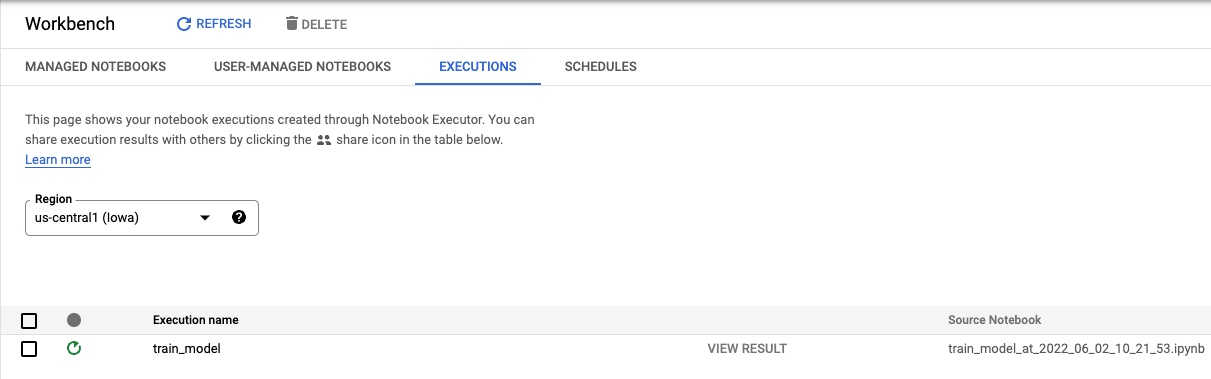
Na guia "Execuções" do console, é possível acompanhar o status do job de treinamento.
6. Implantar o modelo
Etapa 1: fazer upload do modelo
Quando a execução for concluída, volte ao notebook do Workbench para fazer upload do modelo. Crie um notebook do TensorFlow.

Primeiro, importe o SDK da Vertex AI para Python
from google.cloud import aiplatform
Em seguida, faça upload do modelo, substituindo {YOUR_BUCKET} pelo bucket especificado no código de treinamento.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
Para fins de demonstração, vamos fazer upload desse modelo duas vezes, criando dois recursos de modelo diferentes na Vertex AI. Assim, podemos testar a implantação de vários modelos em um único endpoint em um pool de recursos de implantação. Em um cenário real, você teria dois modelos diferentes em vez de criar modelos com os mesmos artefatos salvos. No entanto, este é um atalho para não precisar iniciar outra execução de treinamento. Além disso, é possível implantar os dois modelos em endpoints diferentes no mesmo pool de recursos de implantação.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
No Vertex AI Model Registry, agora você vai encontrar os dois modelos. O status da implantação está em branco porque ainda não implantamos os modelos.
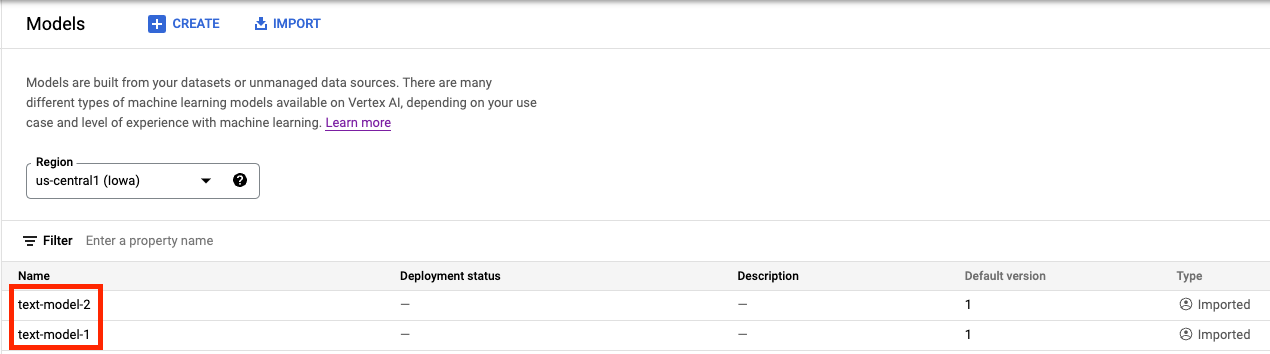
Etapa 2: criar um endpoint
Crie um endpoint Observe que isso é diferente de implantar um modelo em um endpoint.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
Quando o endpoint for criado, ele vai aparecer no console.
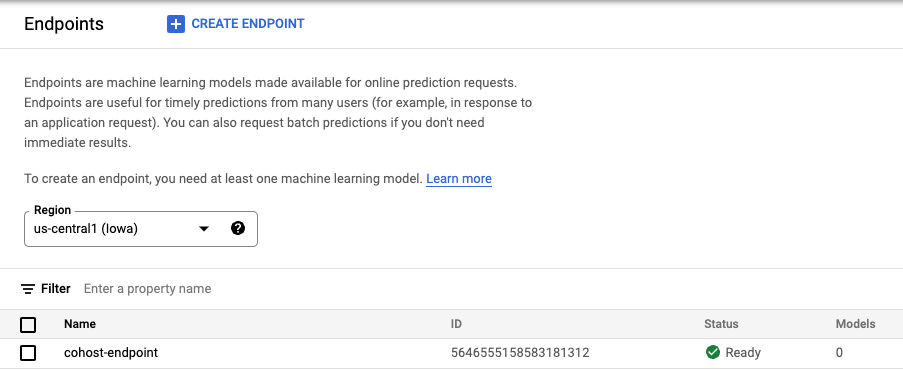
Etapa 3: crie o DeploymentResourcePool
É possível criar o DeploymentResourcePool com o seguinte comando. Substitua {YOUR_PROJECT} pelo ID do projeto.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
Para conferir o pool, execute
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
Etapa 4: implante os modelos no endpoint
Agora que o pool de recursos foi criado, podemos implantar os modelos nele.
Primeiro, vamos implantar model_1. Substitua MODEL_1_ID e ENDPOINT_ID pelos IDs respectivos.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
O comando a seguir implanta model_1 no endpoint dentro do pool de recursos.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Isso leva alguns minutos, mas quando terminar, o modelo vai aparecer implantado no endpoint do console.
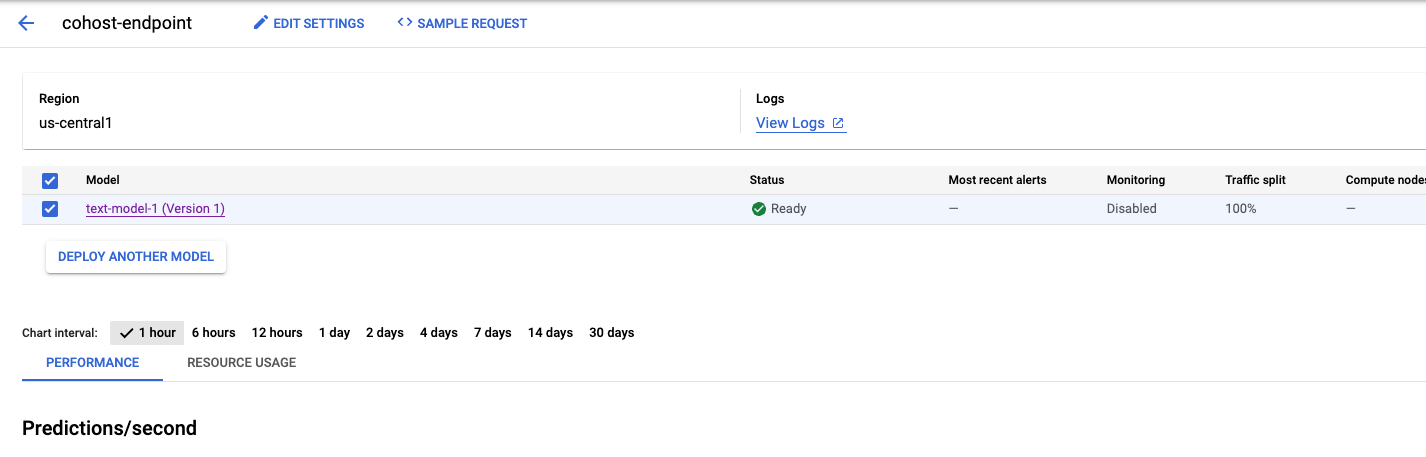
Em seguida, podemos implantar model_2 no mesmo pool de implantação. Vamos implantá-lo no mesmo endpoint que model_1. No entanto, você também pode implantarmodel_2 em um endpoint diferente no mesmo pool de recursos.
Atualize MODEL_ID com o ID de model_2. Para conseguir esse ID, execute model_2.name.
MODEL_2_ID="{MODEL_2_ID}"
Em seguida, implante model_2. Como já temos model_1 implantado no endpoint, precisamos atualizar trafficSplit para que o tráfego seja dividido entre os dois modelos. Não precisaríamos atualizar o trafficSplit se optarmos por implantar model_2 em um endpoint diferente no mesmo pool de recursos.
Para atualizar a divisão de tráfego, defina o ID do DeployedModel para model_1. Observe que isso é diferente do ID do modelo.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
Em seguida, execute o comando abaixo para implantar o segundo modelo.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Neste exemplo, os dois modelos foram implantados no mesmo endpoint, mas também é possível hospedar modelos no mesmo pool de recursos que são implantados em endpoints diferentes. Nesse caso, você não precisaria se preocupar com a divisão de tráfego.
Depois que o segundo modelo for implantado, os dois vão aparecer no console.
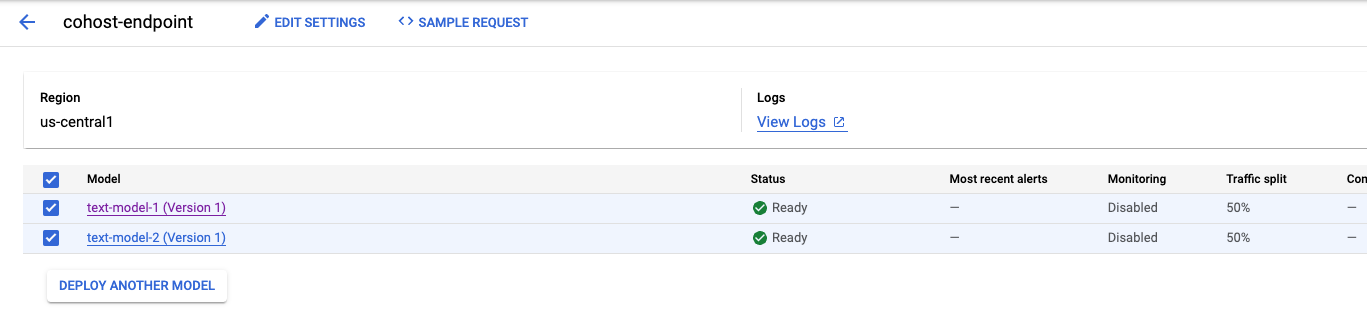
Etapa 5: receber previsões
A etapa final é testar o endpoint e receber previsões.
Primeiro, defina a frase de teste.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
Em seguida, chame "predict" no endpoint, que vai retornar uma previsão de um dos modelos implantados nele.
endpoint.predict(instances=x_test)
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Co-hospedar modelos na mesma VM para previsões on-line
Para saber mais sobre as diferentes partes da Vertex, consulte a documentação.
7. Limpeza
Cancele a implantação dos modelos que não planeja usar em um endpoint. Também é possível excluir o endpoint inteiro. A qualquer momento, você pode implantar de novo um modelo em um endpoint se necessário.

Os notebooks gerenciados do Workbench expiram automaticamente depois de 180 minutos inativos. Para encerrar a instância manualmente, clique no botão "Parar" na seção "Vertex AI Workbench" do console. Se quiser excluir o notebook completamente, clique no botão "Excluir".

Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":