
1. Обзор
В этой лабораторной работе вы узнаете, как использовать пользовательские процедуры прогнозирования в Vertex AI для написания собственной логики предварительной и постобработки. Хотя в этом примере используется Scikit-learn, пользовательские процедуры прогнозирования могут работать и с другими фреймворками машинного обучения на Python, такими как XGBoost, PyTorch и TensorFlow.
Чему вы научитесь
Вы научитесь:
- Разработайте собственную логику прогнозирования с помощью пользовательских процедур прогнозирования.
- Протестируйте пользовательский контейнер для подачи блюд и модель локально.
- Протестируйте пользовательский контейнер для подачи блюд в Vertex AI Predictions.
Общая стоимость запуска этой лабораторной работы в Google Cloud составляет около 1 доллара США.
2. Введение в Vertex AI
В этой лабораторной работе используется новейший продукт для искусственного интеллекта, доступный в Google Cloud. Vertex AI интегрирует предложения машинного обучения в Google Cloud в единый процесс разработки. Ранее модели, обученные с помощью AutoML, и пользовательские модели были доступны через отдельные сервисы. Новое предложение объединяет оба варианта в единый API, а также включает другие новые продукты. Вы также можете перенести существующие проекты в Vertex AI.
Vertex AI включает в себя множество различных продуктов для поддержки комплексных рабочих процессов машинного обучения. В этой лабораторной работе мы сосредоточимся на Predictions и Workbench .

3. Обзор вариантов использования
Вариант использования
В этой лабораторной работе вы создадите модель регрессии на основе случайного леса для прогнозирования цены бриллианта на основе таких характеристик, как огранка, чистота и размер.
Вам предстоит написать собственную логику предварительной обработки данных, чтобы убедиться, что данные на момент обслуживания соответствуют формату, ожидаемому моделью. Также вам потребуется написать собственную логику постобработки для округления прогнозов и преобразования их в строки. Для написания этой логики вы будете использовать собственные процедуры прогнозирования.
Введение в пользовательские процедуры прогнозирования
Встроенные контейнеры Vertex AI обрабатывают запросы на прогнозирование, выполняя операцию прогнозирования в рамках системы машинного обучения. До появления пользовательских процедур прогнозирования, если вам нужно было предварительно обработать входные данные перед выполнением прогнозирования или постобработать прогноз модели перед возвратом результата, вам требовалось создать собственный контейнер.
Для создания собственного контейнера для обслуживания требуется написать HTTP-сервер, который будет инкапсулировать обученную модель, преобразовывать HTTP-запросы во входные данные модели и преобразовывать выходные данные модели в ответы.
Благодаря настраиваемым алгоритмам прогнозирования, Vertex AI предоставляет вам компоненты, необходимые для обслуживания клиентов, позволяя сосредоточиться на преобразовании модели и данных.
4. Настройте свою среду.
Для выполнения этого практического задания вам потребуется проект Google Cloud Platform с включенной оплатой. Чтобы создать проект, следуйте инструкциям здесь .
Шаг 1: Включите API Compute Engine.
Перейдите в Compute Engine и выберите «Включить», если эта опция еще не включена. Она понадобится для создания экземпляра ноутбука.
Шаг 2: Включите API реестра артефактов.
Перейдите в раздел «Реестр артефактов» и выберите «Включить», если эта опция еще не включена. Это позволит создать пользовательский контейнер для обслуживания.
Шаг 3: Включите API Vertex AI
Перейдите в раздел Vertex AI в вашей облачной консоли и нажмите «Включить API Vertex AI» .

Шаг 4: Создайте экземпляр Vertex AI Workbench.
В разделе Vertex AI вашей облачной консоли нажмите на Workbench:

Включите API для блокнотов, если он еще не включен.
После включения нажмите «ЭКЗЕМПЛЯРЫ» , а затем выберите «СОЗДАТЬ НОВЫЙ» .
Примите параметры по умолчанию и нажмите «Создать» .
Когда экземпляр будет готов, нажмите кнопку OPEN JUPYTERLAB , чтобы открыть его.
5. Напишите код для обучения.
Шаг 1: Создайте хранилище в облаке.
Модель и артефакты предварительной обработки будут сохранены в хранилище Cloud Storage. Если в вашем проекте уже есть хранилище, которое вы хотите использовать, вы можете пропустить этот шаг.
С помощью лаунчера откройте новую сессию терминала.

В терминале выполните следующую команду, чтобы определить переменную окружения для вашего проекта, заменив your-cloud-project на идентификатор вашего проекта:
PROJECT_ID='your-cloud-project'
Далее выполните в терминале следующую команду, чтобы создать новый бакет в вашем проекте.
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
Шаг 2: Обучение модели
В терминале создайте новую директорию с именем cpr-codelab и перейдите в неё с помощью команды cd.
mkdir cpr-codelab
cd cpr-codelab
В файловом менеджере перейдите в новую директорию cpr-codelab , а затем с помощью средства запуска создайте новый блокнот Python 3 с именем task.ipynb .

Теперь содержимое вашей директории cpr-codelab должно выглядеть следующим образом:
+ cpr-codelab/
+ task.ipynb
Вставьте следующий код в блокнот.
Сначала напишите файл requirements.txt .
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.0
numpy~=1.20
scikit-learn>=1.2.2
pandas
google-cloud-storage>=1.26.0,<2.0.0dev
google-cloud-aiplatform[prediction]>=1.16.0
Развертываемая вами модель будет иметь другой набор предварительно установленных зависимостей, чем среда вашего ноутбука. Поэтому вам следует перечислить все зависимости для модели в файле requirements.txt , а затем использовать pip для установки точно таких же зависимостей в ноутбук. Позже вы протестируете модель локально перед развертыванием в Vertex AI, чтобы убедиться, что среды совпадают.
Установите зависимости в ноутбуке с помощью команды `pip install`.
!pip install -U --user -r requirements.txt
Обратите внимание, что после завершения установки через pip вам потребуется перезапустить ядро.

Далее создайте каталоги, в которых вы будете хранить модель и артефакты предварительной обработки.
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
Теперь содержимое вашей директории cpr-codelab должно выглядеть следующим образом:
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
Теперь, когда структура каталогов настроена, пришло время обучить модель!
Сначала импортируйте библиотеки.
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
Затем определите следующие переменные. Обязательно замените PROJECT_ID на идентификатор вашего проекта, а BUCKET_NAME на имя корзины, созданной вами на предыдущем шаге.
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
Загрузите данные из библиотеки seaborn, а затем создайте два датафрейма: один с признаками, а другой с метками.
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
Давайте посмотрим на обучающие данные. Вы видите, что каждая строка представляет собой ромб.
x_train.head()
А на этикетках указаны соответствующие цены.
y_train.head()
Теперь определим преобразование столбцов в sklearn для кодирования категориальных признаков методом one-hot и масштабируем числовые признаки.
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
Определите модель случайного леса.
regr = RandomForestRegressor(max_depth=10, random_state=0)
Далее создайте конвейер sklearn . Это означает, что данные, поступающие в этот конвейер, сначала будут закодированы/масштабированы, а затем переданы модели.
my_pipeline = make_pipeline(column_transform, regr)
Обучите конвейер обработки данных на обучающих данных.
my_pipeline.fit(x_train, y_train)
Давайте проверим модель, чтобы убедиться, что она работает должным образом. Вызовем метод predict модели, передав в него тестовый пример.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
Теперь мы можем сохранить конвейер в каталог model_artifacts и скопировать его в хранилище Cloud Storage.
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Шаг 3: Сохраните артефакт предварительной обработки.
Далее вы создадите артефакт предварительной обработки. Этот артефакт будет загружен в пользовательский контейнер при запуске сервера моделей. Ваш артефакт предварительной обработки может иметь практически любую форму (например, файл pickle), но в данном случае вы запишете словарь в файл JSON.
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
В наших обучающих данных признак clarity всегда был в сокращенном виде (например, "FL" вместо "Flawless"). При развертывании мы хотим убедиться, что данные для этого признака также представлены в сокращенном виде. Это связано с тем, что наша модель умеет кодировать "FL" в один цикл, но не "Flawless". Вы напишете эту пользовательскую логику предварительной обработки позже. А пока просто сохраните эту таблицу поиска в файл JSON, а затем запишите ее в хранилище Cloud Storage.
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Теперь ваша локальная директория cpr-codelab должна выглядеть следующим образом:
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
6. Создайте собственный контейнер для обслуживания, используя сервер модели CPR.
Теперь, когда модель обучена и артефакт предварительной обработки сохранен, пришло время создать пользовательский контейнер для обслуживания. Обычно для создания контейнера для обслуживания требуется написать код для сервера модели. Однако, при использовании пользовательских процедур прогнозирования, Vertex AI Predictions генерирует сервер модели и создает для вас пользовательский образ контейнера.
Пользовательский контейнер для подачи контента содержит следующие 3 фрагмента кода:
- Сервер моделей (он будет автоматически сгенерирован SDK и сохранен в
scr_dir/).- HTTP-сервер, на котором размещена модель
- Отвечает за настройку маршрутов/портов и т.д.
- Обработчик запросов
- Отвечает за аспекты обработки запросов на веб-сервере, такие как десериализация тела запроса и сериализация ответа, установка заголовков ответа и т. д.
- В этом примере вы будете использовать обработчик по умолчанию,
google.cloud.aiplatform.prediction.handler.PredictionHandler, предоставляемый SDK.
- Предиктор
- Отвечает за логику машинного обучения для обработки запроса на прогнозирование.
Каждый из этих компонентов может быть настроен в соответствии с требованиями вашего конкретного случая. В этом примере вы реализуете только предиктор.
Предсказатель отвечает за логику машинного обучения для обработки запроса на прогнозирование, например, за пользовательскую предварительную и постобработку. Для написания собственной логики прогнозирования необходимо создать подкласс интерфейса Vertex AI Predictor.
В этом выпуске пользовательских алгоритмов прогнозирования представлены многократно используемые алгоритмы прогнозирования XGBoost и Sklearn, но если вам необходимо использовать другую платформу, вы можете создать свой собственный алгоритм, унаследовав его от базового алгоритма.
Ниже вы можете увидеть пример предиктора Sklearn . Это весь код, который вам потребуется написать для создания этого пользовательского сервера моделей.

Вставьте в свой блокнот следующий код, чтобы создать подкласс SklearnPredictor и записать его в файл Python в src_dir/ . Обратите внимание, что в этом примере мы настраиваем только методы load , preprocess и postprocess , а не метод predict .
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
Давайте подробнее рассмотрим каждый из этих методов.
- Метод
loadзагружает артефакт предварительной обработки, который в данном случае представляет собой словарь, сопоставляющий значения чистоты бриллианта с их аббревиатурами. - Метод
preprocessиспользует этот артефакт, чтобы гарантировать, что во время обслуживания функция ясности будет представлена в сокращенном формате. В противном случае он преобразует полную строку в ее сокращенный формат. - Метод
postprocessвозвращает прогнозируемое значение в виде строки со знаком $ и округляет это значение.
Далее используйте Python SDK от Vertex AI для сборки образа. С помощью пользовательских процедур прогнозирования будет сгенерирован Dockerfile, и образ будет собран.
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
Напишите тестовый файл с двумя примерами для прогнозирования. Один из экземпляров имеет сокращенное название Clarity, а другой необходимо сначала преобразовать.
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
Протестируйте контейнер локально, развернув локальную модель.
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
Результаты прогнозирования можно посмотреть здесь:
predict_response.content
7. Разверните модель в Vertex AI.
Теперь, когда вы протестировали контейнер локально, пришло время отправить образ в реестр артефактов и загрузить модель в реестр моделей Vertex AI.
Сначала настройте Docker для доступа к реестру артефактов.
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
Затем загрузите изображение.
local_model.push_image()
И загрузите модель.
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
После загрузки модели вы должны увидеть её в консоли:
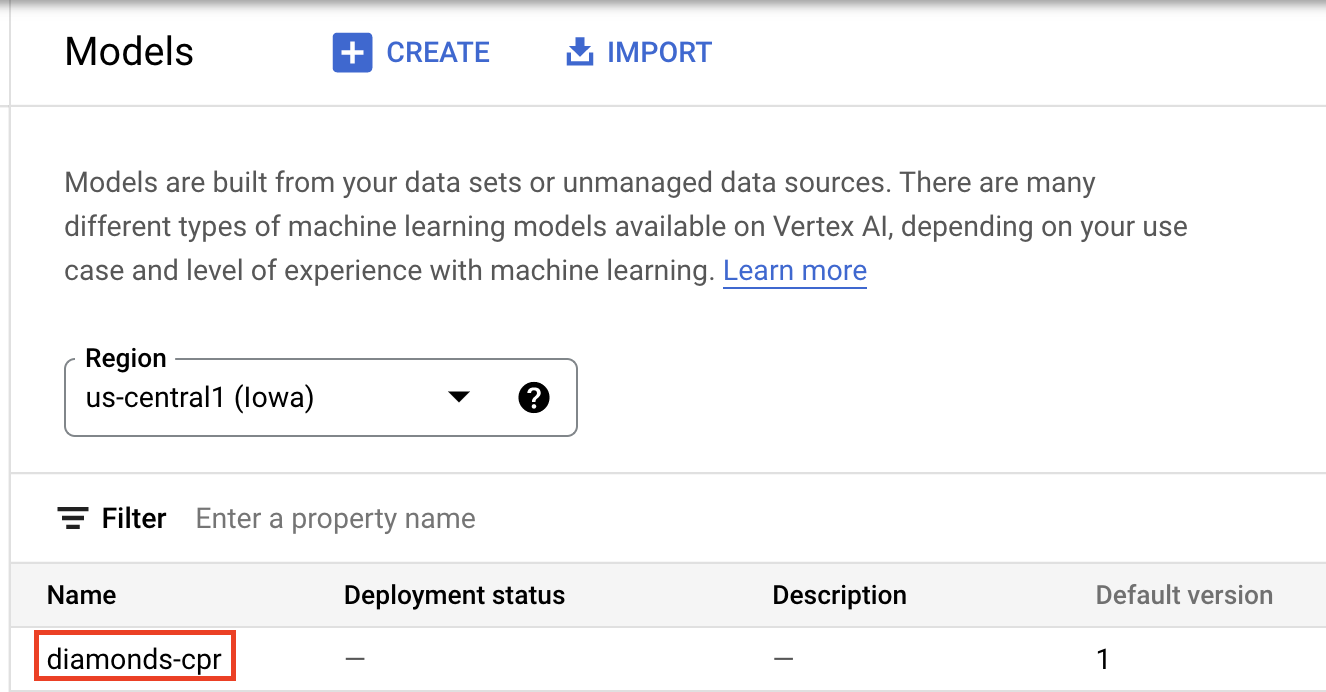
Далее разверните модель, чтобы вы могли использовать ее для онлайн-прогнозирования. Пользовательские процедуры прогнозирования работают и с пакетным прогнозированием, поэтому, если ваш сценарий использования не требует онлайн-прогнозирования, вам не нужно развертывать модель.
endpoint = model.deploy(machine_type="n1-standard-2")
Наконец, протестируйте развернутую модель, получив прогноз.
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 Поздравляем! 🎉
Вы научились использовать Vertex AI для:
- Разработайте собственную логику предварительной и постобработки с использованием пользовательских процедур прогнозирования.
Чтобы узнать больше о различных компонентах Vertex AI, ознакомьтесь с документацией .
8. Уборка
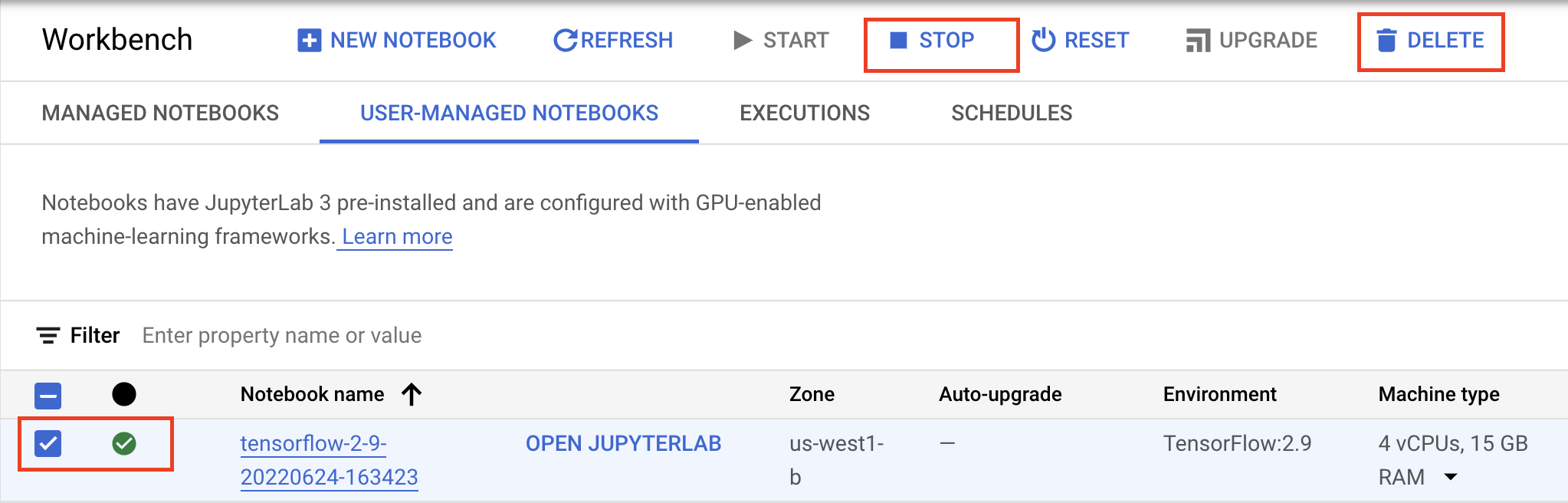
Если вы хотите продолжить использовать созданный в этой лабораторной работе блокнот, рекомендуется выключать его, когда он не используется. В пользовательском интерфейсе Workbench в консоли Google Cloud выберите блокнот, а затем нажмите «Остановить» .
Если вы хотите полностью удалить блокнот, нажмите кнопку «Удалить» в правом верхнем углу.
Чтобы удалить развернутую конечную точку, перейдите в раздел «Конечные точки» консоли, щелкните по созданной вами конечной точке, а затем выберите «Удалить модель из конечной точки» :

Чтобы удалить образ контейнера, перейдите в реестр артефактов, выберите созданный вами репозиторий и нажмите «Удалить».

Чтобы удалить сегмент хранилища, воспользуйтесь меню навигации в консоли Cloud Console, перейдите в раздел «Хранилище», выберите свой сегмент и нажмите «Удалить» .
