
1. ภาพรวม
ในแล็บนี้ คุณจะได้เรียนรู้วิธีใช้กิจวัตรการคาดการณ์ที่กำหนดเองใน Vertex AI เพื่อเขียนตรรกะการประมวลผลก่อนและหลังที่กำหนดเอง แม้ว่าตัวอย่างนี้จะใช้ Scikit-learn แต่กิจวัตรการคาดการณ์ที่กำหนดเองก็ใช้ได้กับเฟรมเวิร์ก ML แบบ Python อื่นๆ เช่น XGBoost, PyTorch และ TensorFlow
สิ่งที่คุณจะได้เรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- เขียนตรรกะการคาดการณ์ที่กำหนดเองด้วยกิจวัตรการคาดการณ์ที่กำหนดเอง
- ทดสอบคอนเทนเนอร์การแสดงผลและโมเดลที่กำหนดเองในเครื่อง
- ทดสอบคอนเทนเนอร์การแสดงผลที่กำหนดเองใน Vertex AI Predictions
ต้นทุนทั้งหมดในการเรียกใช้ Lab นี้ใน Google Cloud อยู่ที่ประมาณ $1 USD
2. ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
แล็บนี้ใช้ผลิตภัณฑ์ AI ใหม่ล่าสุดที่พร้อมให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้ากับประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้ โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองจะเข้าถึงได้ผ่านบริการแยกต่างหาก ข้อเสนอใหม่นี้จะรวมทั้ง 2 อย่างไว้ใน API เดียว พร้อมกับผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย
Vertex AI มีผลิตภัณฑ์มากมายที่แตกต่างกันเพื่อรองรับเวิร์กโฟลว์ ML แบบครบวงจร ห้องทดลองนี้จะมุ่งเน้นที่การคาดการณ์และเวิร์กเบนช์

3. ภาพรวมกรณีการใช้งาน
กรณีการใช้งาน
ในแล็บนี้ คุณจะได้สร้างโมเดลการถดถอยแบบสุ่มเพื่อคาดการณ์ราคาของเพชรตามแอตทริบิวต์ต่างๆ เช่น การเจียระไน ความใส และขนาด
คุณจะเขียนตรรกะการประมวลผลล่วงหน้าที่กำหนดเองเพื่อตรวจสอบว่าข้อมูล ณ เวลาที่ให้บริการอยู่ในรูปแบบที่โมเดลคาดไว้ นอกจากนี้ คุณยังต้องเขียนตรรกะการประมวลผลภายหลังที่กำหนดเองเพื่อปัดเศษการคาดการณ์และแปลงเป็นสตริง หากต้องการเขียนตรรกะนี้ คุณจะต้องใช้กิจวัตรการคาดการณ์ที่กำหนดเอง
ข้อมูลเบื้องต้นเกี่ยวกับกิจวัตรการคาดการณ์ที่กำหนดเอง
คอนเทนเนอร์ที่สร้างไว้ล่วงหน้าของ Vertex AI จะจัดการคำขอการคาดการณ์โดยการดำเนินการคาดการณ์ของเฟรมเวิร์กแมชชีนเลิร์นนิง ก่อนที่จะมีกิจวัตรการคาดการณ์ที่กำหนดเอง หากต้องการประมวลผลอินพุตล่วงหน้าก่อนทำการคาดการณ์ หรือประมวลผลภายหลังการคาดการณ์ของโมเดลก่อนแสดงผลลัพธ์ คุณจะต้องสร้างคอนเทนเนอร์ที่กำหนดเอง
การสร้างคอนเทนเนอร์การแสดงผลที่กำหนดเองต้องเขียนเซิร์ฟเวอร์ HTTP ที่ห่อหุ้มโมเดลที่ฝึกแล้ว แปลคำขอ HTTP เป็นอินพุตของโมเดล และแปลเอาต์พุตของโมเดลเป็นการตอบกลับ
กิจวัตรการคาดการณ์ที่กำหนดเองช่วยให้ Vertex AI มีคอมโพเนนต์ที่เกี่ยวข้องกับการแสดงผลสำหรับคุณ เพื่อให้คุณมุ่งเน้นไปที่โมเดลและการเปลี่ยนรูปแบบข้อมูลได้
4. ตั้งค่าสภาพแวดล้อม
คุณจะต้องมีโปรเจ็กต์ Google Cloud Platform ที่เปิดใช้การเรียกเก็บเงินเพื่อเรียกใช้ Codelab นี้ หากต้องการสร้างโปรเจ็กต์ ให้ทำตามวิธีการที่นี่
ขั้นตอนที่ 1: เปิดใช้ Compute Engine API
ไปที่ Compute Engine แล้วเลือกเปิดใช้หากยังไม่ได้เปิดใช้ คุณจะต้องใช้ข้อมูลนี้เพื่อสร้างอินสแตนซ์ Notebook
ขั้นตอนที่ 2: เปิดใช้ Artifact Registry API
ไปที่ Artifact Registry แล้วเลือกเปิดใช้หากยังไม่ได้เปิดใช้ คุณจะใช้สิ่งนี้เพื่อสร้างคอนเทนเนอร์การแสดงผลที่กำหนดเอง
ขั้นตอนที่ 3: เปิดใช้ Vertex AI API
ไปที่ส่วน Vertex AI ของ Cloud Console แล้วคลิกเปิดใช้ Vertex AI API

ขั้นตอนที่ 4: สร้างอินสแตนซ์ Vertex AI Workbench
จากส่วน Vertex AI ของ Cloud Console ให้คลิก Workbench

เปิดใช้ Notebooks API หากยังไม่ได้เปิด

เมื่อเปิดใช้แล้ว ให้คลิกอินสแตนซ์ แล้วเลือกสร้างใหม่
ยอมรับตัวเลือกเริ่มต้น แล้วคลิกสร้าง
เมื่ออินสแตนซ์พร้อมแล้ว ให้คลิกเปิด JUPYTERLAB เพื่อเปิดอินสแตนซ์
5. เขียนโค้ดการฝึก
ขั้นตอนที่ 1: สร้าง Bucket ของ Cloud Storage
คุณจะจัดเก็บโมเดลและอาร์ติแฟกต์การประมวลผลล่วงหน้าไว้ใน Bucket ของ Cloud Storage หากมีที่เก็บข้อมูลในโปรเจ็กต์ที่ต้องการใช้อยู่แล้ว คุณสามารถข้ามขั้นตอนนี้ได้
เปิดเซสชันเทอร์มินัลใหม่จาก Launcher

จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ โดยแทนที่ your-cloud-project ด้วยรหัสโปรเจ็กต์
PROJECT_ID='your-cloud-project'
จากนั้นเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลเพื่อสร้างที่เก็บข้อมูลใหม่ในโปรเจ็กต์
BUCKET="gs://${PROJECT_ID}-cpr-bucket"
gsutil mb -l us-central1 $BUCKET
ขั้นตอนที่ 2: ฝึกโมเดล
จากเทอร์มินัล ให้สร้างไดเรกทอรีใหม่ชื่อ cpr-codelab แล้วใช้คำสั่ง cd เพื่อเข้าไปในไดเรกทอรี
mkdir cpr-codelab
cd cpr-codelab
ในโปรแกรมเรียกดูไฟล์ ให้ไปที่ไดเรกทอรี cpr-codelab ใหม่ แล้วใช้ตัวเรียกใช้เพื่อสร้าง Notebook Python 3 ใหม่ชื่อ task.ipynb

ตอนนี้ไดเรกทอรี cpr-codelab ควรมีลักษณะดังนี้
+ cpr-codelab/
+ task.ipynb
วางโค้ดต่อไปนี้ใน Notebook
ก่อนอื่น ให้เขียนไฟล์ requirements.txt
%%writefile requirements.txt
fastapi
uvicorn==0.17.6
joblib~=1.0
numpy~=1.20
scikit-learn>=1.2.2
pandas
google-cloud-storage>=1.26.0,<2.0.0dev
google-cloud-aiplatform[prediction]>=1.16.0
โมเดลที่คุณทำให้ใช้งานได้จะมีชุดทรัพยากร Dependency ที่ติดตั้งไว้ล่วงหน้าแตกต่างจากสภาพแวดล้อมของ Notebook ด้วยเหตุนี้ คุณจึงควรแสดงรายการทรัพยากร Dependency ทั้งหมดของโมเดลใน requirements.txt จากนั้นใช้ pip เพื่อติดตั้งทรัพยากร Dependency เดียวกันใน Notebook จากนั้นคุณจะทดสอบโมเดลในเครื่องก่อนที่จะนำไปใช้งานใน Vertex AI เพื่อตรวจสอบอีกครั้งว่าสภาพแวดล้อมตรงกัน
ติดตั้งการอ้างอิงใน Notebook โดยใช้ Pip
!pip install -U --user -r requirements.txt
โปรดทราบว่าคุณจะต้องรีสตาร์ทเคอร์เนลหลังจากที่ pip ติดตั้งเสร็จสมบูรณ์

จากนั้นสร้างไดเรกทอรีที่จะจัดเก็บโมเดลและอาร์ติแฟกต์การประมวลผลล่วงหน้า
USER_SRC_DIR = "src_dir"
!mkdir $USER_SRC_DIR
!mkdir model_artifacts
# copy the requirements to the source dir
!cp requirements.txt $USER_SRC_DIR/requirements.txt
ตอนนี้ไดเรกทอรี cpr-codelab ควรมีลักษณะดังนี้
+ cpr-codelab/
+ model_artifacts/
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
เมื่อตั้งค่าโครงสร้างไดเรกทอรีแล้ว ก็ถึงเวลาฝึกโมเดล
ก่อนอื่น ให้นำเข้าไลบรารี
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
import joblib
import logging
# set logging to see the docker container logs
logging.basicConfig(level=logging.INFO)
จากนั้นกำหนดตัวแปรต่อไปนี้ อย่าลืมแทนที่ PROJECT_ID ด้วยรหัสโปรเจ็กต์และ BUCKET_NAME ด้วย Bucket ที่คุณสร้างในขั้นตอนก่อนหน้า
REGION = "us-central1"
MODEL_ARTIFACT_DIR = "sklearn-model-artifacts"
REPOSITORY = "diamonds"
IMAGE = "sklearn-image"
MODEL_DISPLAY_NAME = "diamonds-cpr"
# Replace with your project
PROJECT_ID = "{PROJECT_ID}"
# Replace with your bucket
BUCKET_NAME = "gs://{BUCKET_NAME}"
โหลดข้อมูลจากไลบรารี Seaborn แล้วสร้าง DataFrame 2 รายการ โดยรายการหนึ่งมีฟีเจอร์และอีกรายการหนึ่งมีป้ายกำกับ
data = sns.load_dataset('diamonds', cache=True, data_home=None)
label = 'price'
y_train = data['price']
x_train = data.drop(columns=['price'])
มาดูข้อมูลฝึกฝนกัน คุณจะเห็นว่าแต่ละแถวแสดงถึงเพชร
x_train.head()
และป้ายกำกับซึ่งเป็นราคาที่เกี่ยวข้อง
y_train.head()
ตอนนี้ให้กำหนด column transform ของ sklearn เพื่อเข้ารหัสแบบ One-Hot ฟีเจอร์เชิงหมวดหมู่และปรับขนาดฟีเจอร์เชิงตัวเลข
column_transform = make_column_transformer(
(preprocessing.OneHotEncoder(), [1,2,3]),
(preprocessing.StandardScaler(), [0,4,5,6,7,8]))
กำหนดโมเดล Random Forest
regr = RandomForestRegressor(max_depth=10, random_state=0)
จากนั้นสร้างไปป์ไลน์ sklearn ซึ่งหมายความว่าข้อมูลที่ป้อนไปยังไปป์ไลน์นี้จะได้รับการเข้ารหัส/ปรับขนาดก่อน จากนั้นจึงส่งไปยังโมเดล
my_pipeline = make_pipeline(column_transform, regr)
พอดีกับไปป์ไลน์ในข้อมูลฝึกฝน
my_pipeline.fit(x_train, y_train)
มาลองใช้โมเดลเพื่อตรวจสอบว่าทำงานได้ตามที่คาดไว้ เรียกใช้เมธอด predict ในโมเดลโดยส่งตัวอย่างทดสอบ
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])
ตอนนี้เราสามารถบันทึกไปป์ไลน์ไปยังไดเรกทอรี model_artifacts และคัดลอกไปยัง Bucket ของ Cloud Storage ได้แล้ว
joblib.dump(my_pipeline, 'model_artifacts/model.joblib')
!gsutil cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
ขั้นตอนที่ 3: บันทึกอาร์ติแฟกต์การประมวลผลล่วงหน้า
จากนั้นคุณจะสร้างอาร์ติแฟกต์การประมวลผลล่วงหน้า ระบบจะโหลดอาร์ติแฟกต์นี้ในคอนเทนเนอร์ที่กำหนดเองเมื่อเซิร์ฟเวอร์โมเดลเริ่มต้น อาร์ติแฟกต์การประมวลผลล่วงหน้าอาจอยู่ในรูปแบบใดก็ได้ (เช่น ไฟล์ Pickle) แต่ในกรณีนี้ คุณจะต้องเขียนพจนานุกรมลงในไฟล์ JSON
clarity_dict={"Flawless": "FL",
"Internally Flawless": "IF",
"Very Very Slightly Included": "VVS1",
"Very Slightly Included": "VS2",
"Slightly Included": "S12",
"Included": "I3"}
clarity ในข้อมูลฝึกฝนของเราอยู่ในรูปแบบย่อเสมอ (เช่น "FL" แทน "Flawless") ในเวลาที่แสดง เราต้องการตรวจสอบว่าข้อมูลสำหรับฟีเจอร์นี้ก็ย่อด้วยเช่นกัน เนื่องจากโมเดลของเราทราบวิธีเข้ารหัสแบบ One-Hot สำหรับ "FL" แต่ไม่ทราบวิธีเข้ารหัสสำหรับ "Flawless" คุณจะเขียนตรรกะการประมวลผลล่วงหน้าที่กำหนดเองนี้ในภายหลัง แต่ตอนนี้ ให้บันทึกตารางการค้นหานี้ลงในไฟล์ JSON แล้วเขียนลงในที่เก็บข้อมูล Cloud Storage
import json
with open("model_artifacts/preprocessor.json", "w") as f:
json.dump(clarity_dict, f)
!gsutil cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
ตอนนี้ไดเรกทอรี cpr-codelab ในเครื่องควรมีลักษณะดังนี้
+ cpr-codelab/
+ model_artifacts/
+ model.joblib
+ preprocessor.json
+ scr_dir/
+ requirements.txt
+ task.ipynb
+ requirements.txt
6. สร้างคอนเทนเนอร์การแสดงผลที่กำหนดเองโดยใช้เซิร์ฟเวอร์โมเดล CPR
ตอนนี้โมเดลได้รับการฝึกแล้วและบันทึกอาร์ติแฟกต์การประมวลผลล่วงหน้าแล้ว ก็ถึงเวลาสร้างคอนเทนเนอร์การแสดงผลที่กำหนดเอง โดยปกติแล้ว การสร้างคอนเทนเนอร์ที่แสดงจะต้องเขียนโค้ดเซิร์ฟเวอร์โมเดล อย่างไรก็ตาม เมื่อใช้กิจวัตรการคาดการณ์ที่กำหนดเอง การคาดการณ์ของ Vertex AI จะสร้างเซิร์ฟเวอร์โมเดลและสร้างอิมเมจคอนเทนเนอร์ที่กำหนดเองให้คุณ
คอนเทนเนอร์การแสดงผลที่กำหนดเองมีโค้ด 3 ส่วนต่อไปนี้
- เซิร์ฟเวอร์โมเดล (SDK จะสร้างเซิร์ฟเวอร์นี้โดยอัตโนมัติและจัดเก็บไว้ใน
scr_dir/)- เซิร์ฟเวอร์ HTTP ที่โฮสต์โมเดล
- รับผิดชอบในการตั้งค่าเส้นทาง/พอร์ต/ฯลฯ
- ตัวแฮนเดิลคำขอ
- รับผิดชอบด้านเว็บเซิร์ฟเวอร์ในการจัดการคำขอ เช่น การยกเลิกการซีเรียลไลซ์เนื้อหาคำขอ และการซีเรียลไลซ์การตอบกลับ การตั้งค่าส่วนหัวการตอบกลับ ฯลฯ
- ในตัวอย่างนี้ คุณจะใช้ตัวแฮนเดิลเริ่มต้น
google.cloud.aiplatform.prediction.handler.PredictionHandlerที่มีให้ใน SDK
- ตัวทำนาย
- รับผิดชอบตรรกะ ML สำหรับการประมวลผลคำขอการคาดการณ์
คุณปรับแต่งแต่ละองค์ประกอบเหล่านี้ได้ตามข้อกำหนดของกรณีการใช้งาน ในตัวอย่างนี้ คุณจะติดตั้งใช้งานเฉพาะตัวคาดการณ์
ตัวคาดการณ์มีหน้าที่รับผิดชอบตรรกะ ML สำหรับการประมวลผลคำขอการคาดการณ์ เช่น การประมวลผลล่วงหน้าและการประมวลผลภายหลังที่กำหนดเอง หากต้องการเขียนตรรกะการคาดการณ์ที่กำหนดเอง คุณจะต้องสร้างคลาสย่อยของอินเทอร์เฟซ Vertex AI Predictor
การเผยแพร่กิจวัตรการคาดการณ์ที่กำหนดเองนี้มาพร้อมกับตัวคาดการณ์ XGBoost และ Sklearn ที่นำกลับมาใช้ใหม่ได้ แต่หากต้องการใช้เฟรมเวิร์กอื่น คุณสามารถสร้างเฟรมเวิร์กของคุณเองได้โดยการสร้างคลาสย่อยของตัวคาดการณ์ฐาน
ดูตัวอย่างเครื่องมือคาดการณ์ Sklearn ได้ที่ด้านล่าง นี่คือโค้ดทั้งหมดที่คุณต้องเขียนเพื่อสร้างเซิร์ฟเวอร์โมเดลที่กำหนดเองนี้

ใน Notebook ให้วางโค้ดต่อไปนี้เพื่อสร้างคลาสย่อยของ SklearnPredictor และเขียนลงในไฟล์ Python ใน src_dir/ โปรดทราบว่าในตัวอย่างนี้ เราจะปรับแต่งเฉพาะเมธอด load, preprocess และ postprocess เท่านั้น ไม่ใช่เมธอด predict
%%writefile $USER_SRC_DIR/predictor.py
import joblib
import numpy as np
import json
from google.cloud import storage
from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor
class CprPredictor(SklearnPredictor):
def __init__(self):
return
def load(self, artifacts_uri: str) -> None:
"""Loads the sklearn pipeline and preprocessing artifact."""
super().load(artifacts_uri)
# open preprocessing artifact
with open("preprocessor.json", "rb") as f:
self._preprocessor = json.load(f)
def preprocess(self, prediction_input: np.ndarray) -> np.ndarray:
"""Performs preprocessing by checking if clarity feature is in abbreviated form."""
inputs = super().preprocess(prediction_input)
for sample in inputs:
if sample[3] not in self._preprocessor.values():
sample[3] = self._preprocessor[sample[3]]
return inputs
def postprocess(self, prediction_results: np.ndarray) -> dict:
"""Performs postprocessing by rounding predictions and converting to str."""
return {"predictions": [f"${value}" for value in np.round(prediction_results)]}
มาดูรายละเอียดของแต่ละวิธีกัน
loadเมธอดจะโหลดในอาร์ติแฟกต์การประมวลผลล่วงหน้า ซึ่งในกรณีนี้คือพจนานุกรมที่เชื่อมโยงค่าความใสของเพชรกับตัวย่อ- เมธอด
preprocessใช้สิ่งประดิษฐ์ดังกล่าวเพื่อให้แน่ใจว่าในเวลาที่แสดง ฟีเจอร์ความชัดเจนจะอยู่ในรูปแบบย่อ หากไม่ ระบบจะแปลงสตริงทั้งหมดเป็นตัวย่อ - เมธอด
postprocessจะแสดงผลค่าที่คาดการณ์เป็นสตริงที่มีเครื่องหมาย $ และปัดค่า
จากนั้นใช้ Vertex AI Python SDK เพื่อสร้างอิมเมจ เมื่อใช้กิจวัตรการคาดการณ์ที่กำหนดเอง ระบบจะสร้าง Dockerfile และสร้างอิมเมจให้คุณ
from google.cloud import aiplatform
aiplatform.init(project=PROJECT_ID, location=REGION)
import os
from google.cloud.aiplatform.prediction import LocalModel
from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR
local_model = LocalModel.build_cpr_model(
USER_SRC_DIR,
f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}",
predictor=CprPredictor,
requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"),
)
เขียนไฟล์ทดสอบที่มีตัวอย่าง 2 รายการสำหรับการคาดการณ์ อินสแตนซ์หนึ่งมีชื่อความชัดเจนแบบย่อ แต่อีกอินสแตนซ์หนึ่งต้องแปลงก่อน
import json
sample = {"instances": [
[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43],
[0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}
with open('instances.json', 'w') as fp:
json.dump(sample, fp)
ทดสอบคอนเทนเนอร์ในเครื่องโดยการติดตั้งใช้งานโมเดลในเครื่อง
with local_model.deploy_to_local_endpoint(
artifact_uri = 'model_artifacts/', # local path to artifacts
) as local_endpoint:
predict_response = local_endpoint.predict(
request_file='instances.json',
headers={"Content-Type": "application/json"},
)
health_check_response = local_endpoint.run_health_check()
คุณดูผลการคาดการณ์ได้โดยใช้
predict_response.content
7. ทำให้โมเดลใช้งานได้ใน Vertex AI
ตอนนี้คุณได้ทดสอบคอนเทนเนอร์ในเครื่องแล้ว ก็ถึงเวลาพุชอิมเมจไปยัง Artifact Registry และอัปโหลดโมเดลไปยัง Vertex AI Model Registry
ก่อนอื่น ให้กำหนดค่า Docker เพื่อเข้าถึง Artifact Registry
!gcloud artifacts repositories create {REPOSITORY} --repository-format=docker \
--location=us-central1 --description="Docker repository"
!gcloud auth configure-docker {REGION}-docker.pkg.dev --quiet
จากนั้นดันรูปภาพ
local_model.push_image()
แล้วอัปโหลดโมเดล
model = aiplatform.Model.upload(local_model = local_model,
display_name=MODEL_DISPLAY_NAME,
artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)
เมื่ออัปโหลดโมเดลแล้ว คุณควรเห็นโมเดลในคอนโซล

จากนั้น ให้ทําให้โมเดลใช้งานได้เพื่อให้คุณใช้โมเดลสําหรับการคาดการณ์ออนไลน์ได้ กิจวัตรการคาดการณ์ที่กำหนดเองใช้ได้กับการคาดการณ์แบบกลุ่มด้วย ดังนั้นหากกรณีการใช้งานของคุณไม่จำเป็นต้องมีการคาดการณ์ออนไลน์ คุณก็ไม่จำเป็นต้องทำให้โมเดลใช้งานได้
endpoint = model.deploy(machine_type="n1-standard-2")
สุดท้าย ให้ทดสอบโมเดลที่ใช้งานจริงโดยรับการคาดการณ์
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])
🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI เพื่อทำสิ่งต่อไปนี้
- เขียนตรรกะการประมวลผลก่อนและหลังที่กำหนดเองด้วยกิจวัตรการคาดการณ์ที่กำหนดเอง
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex AI ได้ที่เอกสารประกอบ
8. ล้างข้อมูล
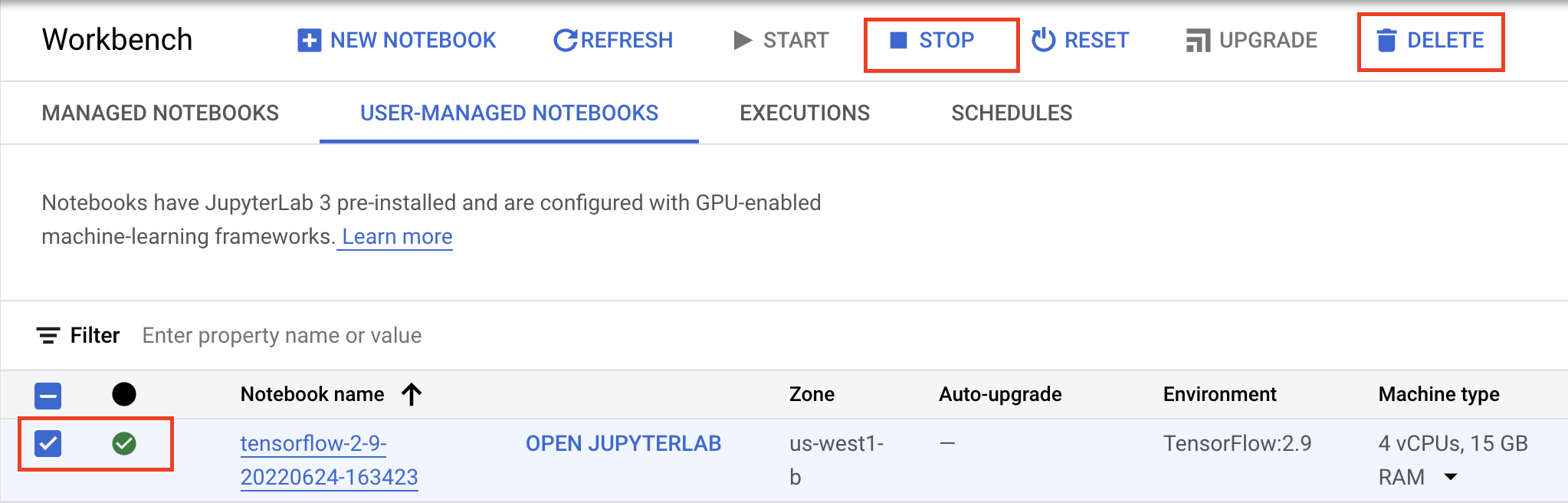
หากต้องการใช้ Notebook ที่สร้างขึ้นใน Lab นี้ต่อไป ขอแนะนำให้ปิดเมื่อไม่ได้ใช้งาน จาก UI ของ Workbench ในคอนโซล Google Cloud ให้เลือก Notebook แล้วเลือกหยุด
หากต้องการลบ Notebook ทั้งหมด ให้คลิกปุ่มลบที่ด้านขวาบน
หากต้องการลบปลายทางที่ติดตั้งใช้งาน ให้ไปที่ส่วนปลายทางของคอนโซล คลิกปลายทางที่สร้างขึ้น แล้วเลือกเลิกติดตั้งใช้งานโมเดลจากปลายทาง

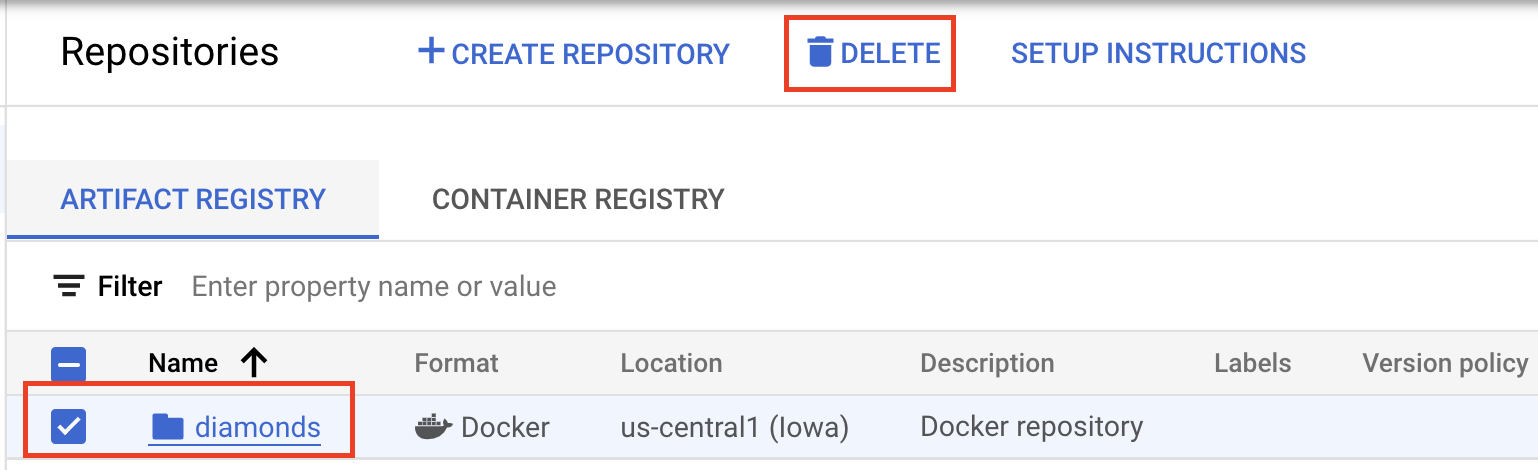
หากต้องการลบอิมเมจคอนเทนเนอร์ ให้ไปที่ Artifact Registry เลือกที่เก็บที่คุณสร้างขึ้น แล้วเลือกลบ
หากต้องการลบ Storage Bucket ให้ใช้เมนูการนำทางใน Cloud Console ไปที่ Storage เลือก Bucket แล้วคลิกลบ
