
1. Descripción general
En este lab, usarás Vertex AI para obtener predicciones a partir de un modelo de clasificación de imágenes entrenado previamente.
Qué aprenderá
Aprenderás a hacer lo siguiente:
- Importa un modelo de TensorFlow a Vertex AI Model Registry
- Obtén predicciones en línea
- Actualiza una función de TensorFlow Serving
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $1.
2. Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI.
Vertex AI incluye muchos productos distintos para respaldar flujos de trabajo de AA de extremo a extremo. Este lab se enfocará en los productos que se destacan a continuación: Prediction y Workbench

3. Descripción general del caso de uso
En este lab, aprenderás a tomar un modelo previamente entrenado de TensorFlow Hub y a implementarlo en Vertex AI. TensorFlow Hub es un repositorio de modelos entrenados para una variedad de dominios de problemas, como incorporaciones, generación de texto, voz a texto, segmentación de imágenes y mucho más.
El ejemplo que se usa en este lab es un modelo de clasificación de imágenes MobileNet V1 entrenado previamente en el conjunto de datos de ImageNet. Si aprovechas los modelos listos para usar de TensorFlow Hub o de otros repositorios similares de aprendizaje profundo, puedes implementar modelos de AA de alta calidad para una serie de tareas de predicción sin tener que preocuparte por el entrenamiento de modelos.
4. Configura el entorno
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform que tenga habilitada la facturación. Para crear un proyecto, sigue estas instrucciones.
Paso 1: Habilita la API de Compute Engine
Ve a Compute Engine y selecciona Habilitar (si aún no está habilitada).
Paso 2: Habilita la API de Vertex AI
Navegue hasta la sección de Vertex AI en la consola de Cloud y haga clic en Habilitar API de Vertex AI.

Paso 3: Crea una instancia de Vertex AI Workbench
En la sección Vertex AI de Cloud Console, haz clic en Workbench:

Habilita la API de Notebooks si aún no está habilitada.

Una vez habilitada, haz clic en NOTEBOOKS ADMINISTRADOS (MANAGED NOTEBOOKS):

Luego, selecciona NUEVO NOTEBOOK (NEW NOTEBOOK).

Asígnale un nombre al notebook y en Permiso (Permission), selecciona Cuenta de servicio (Service account).

Selecciona Configuración avanzada.
En Seguridad (Security), selecciona la opción “Habilitar terminal” (Enable terminal) si aún no está habilitada.

Puedes dejar el resto de la configuración avanzada tal como está.
Luego, haz clic en Crear. La instancia tardará algunos minutos en aprovisionarse.
Una vez que se cree la instancia, selecciona ABRIR JUPYTERLAB (OPEN JUPYTERLAB).

5. Registrar modelo
Paso 1: Sube el modelo a Cloud Storage
Haz clic en este vínculo para ir a la página de TensorFlow Hub del modelo MobileNet V1 entrenado en el conjunto de datos ImageNet.
Selecciona Descargar para descargar los artefactos del modelo guardado.

En la sección Cloud Storage de la consola de Google Cloud, selecciona CREAR.

Asigna un nombre a tu bucket y selecciona us-central1 como la región. Luego, haz clic en CREAR.

Sube al bucket el modelo de TensorFlow Hub que descargaste. Primero, asegúrate de descomprimir el archivo.

Tu bucket debería verse de la siguiente manera:
imagenet_mobilenet_v1_050_128_classification_5/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
Paso 2: Importa el modelo al registro
Navega a la sección Model Registry de Vertex AI en la consola de Cloud.

Selecciona IMPORTAR (IMPORT).
Selecciona Importar como modelo nuevo y, luego, asígnale un nombre al modelo.

En Configuración del modelo, especifica el contenedor compilado previamente más reciente de TensorFlow. Luego, selecciona la ruta de acceso en Cloud Storage en la que almacenaste los artefactos del modelo.

Puedes omitir la sección Explicabilidad.
Luego, selecciona IMPORT.
Una vez que se importe, verás tu modelo en Model Registry

6. Implementar el modelo
En el registro de modelos, selecciona los tres puntos que se encuentran a la derecha del modelo y haz clic en Implementar en el extremo.
En Define tu extremo, selecciona Crear extremo nuevo y, luego, asígnale un nombre.
En Configuración del modelo, establece la Cantidad máxima de nodos de procesamiento en 1 y el tipo de máquina en n1-standard-2, y deja todos los demás parámetros de configuración como están. Luego, haz clic en DEPLOY.

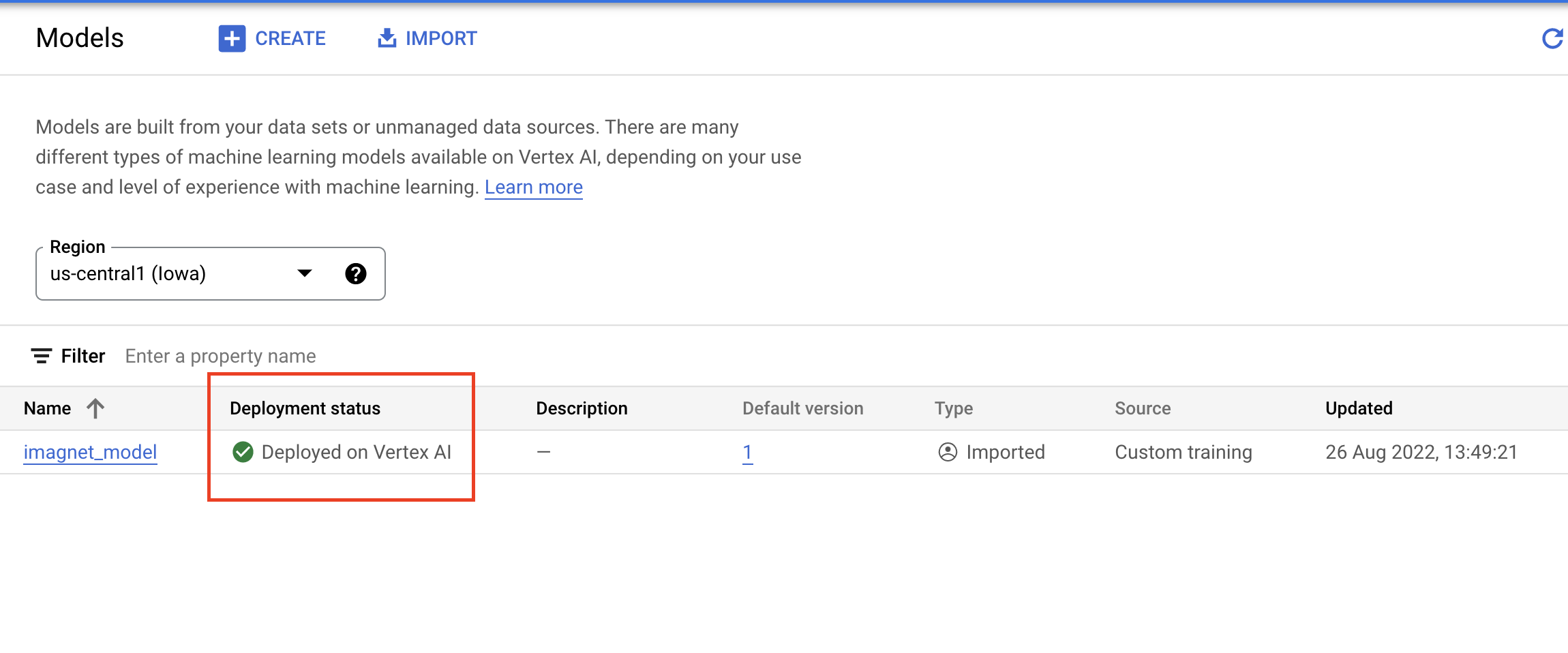
Cuando se implemente, el estado de implementación cambiará a Implementado en Vertex AI.
7. Obtén predicciones
Abre el notebook de Workbench que creaste en los pasos de configuración. En el selector, crea un nuevo notebook de TensorFlow 2.

Ejecuta la siguiente celda para importar las bibliotecas necesarias.
from google.cloud import aiplatform
import tensorflow as tf
import numpy as np
from PIL import Image
El modelo MobileNet que descargaste de TensorFlow Hub se entrenó con el conjunto de datos ImageNet. El resultado del modelo MobileNet es un número que corresponde a una etiqueta de clase en el conjunto de datos de ImageNet. Para traducir ese número en una etiqueta de cadena, deberás descargar las etiquetas de imagen.
# Download image labels
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
Para acceder al extremo, deberás definir el recurso del extremo. Asegúrate de reemplazar {PROJECT_NUMBER} y {ENDPOINT_ID}.
PROJECT_NUMBER = "{PROJECT_NUMBER}"
ENDPOINT_ID = "{ENDPOINT_ID}"
endpoint = aiplatform.Endpoint(
endpoint_name=f"projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
Puedes encontrar el número del proyecto en la página principal de la consola.

El ID del extremo en la sección Extremos de Vertex AI

A continuación, probarás tu extremo.
Primero, descarga la siguiente imagen y súbela a tu instancia.

Abre la imagen con PIL. Luego, cambia el tamaño y la escala en 255. Ten en cuenta que el tamaño de imagen que espera el modelo se puede encontrar en la página de TensorFlow Hub del modelo.
IMAGE_PATH = "test-image.jpg"
IMAGE_SIZE = (128, 128)
im = Image.open(IMAGE_PATH)
im = im.resize(IMAGE_SIZE
im = np.array(im)/255.0
A continuación, convierte los datos de NumPy en una lista para que se puedan enviar en el cuerpo de la solicitud HTTP.
x_test = im.astype(np.float32).tolist()
Por último, realiza una llamada de predicción al extremo y, luego, busca la etiqueta de cadena correspondiente.
# make prediction request
result = endpoint.predict(instances=[x_test]).predictions
# post process result
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
8. [Opcional] Usa TF Serving para optimizar las predicciones
Para obtener ejemplos más realistas, te recomendamos que envíes la imagen directamente al endpoint, en lugar de cargarla primero en NumPy. Este método es más eficiente, pero deberás modificar la función de entrega del modelo de TensorFlow. Esta modificación es necesaria para convertir los datos de entrada al formato que espera tu modelo.
Paso 1: Modifica la función de procesamiento
Abre un nuevo notebook de TensorFlow y, luego, importa las bibliotecas necesarias.
from google.cloud import aiplatform
import tensorflow as tf
En lugar de descargar los artefactos del modelo guardado, esta vez cargarás el modelo en TensorFlow con hub.KerasLayer, que encapsula un modelo guardado de TensorFlow como una capa de Keras. Para crear el modelo, puedes usar la API de Keras Sequential con el modelo de TF Hub descargado como una capa y especificar la forma de entrada del modelo.
tfhub_model = tf.keras.Sequential(
[hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v1_050_128/classification/5")]
)
tfhub_model.build([None, 128, 128, 3])
Define el URI del bucket que creaste anteriormente.
BUCKET_URI = "gs://{YOUR_BUCKET}"
MODEL_DIR = BUCKET_URI + "/bytes_model"
Cuando envías una solicitud a un servidor de predicción en línea, un servidor HTTP la recibe. El servidor HTTP extrae la solicitud de predicción del cuerpo del contenido de la solicitud HTTP. La solicitud de predicción extraída se reenvía a la función de entrega. En el caso de los contenedores de predicción compilados previamente de Vertex AI, el contenido de la solicitud se pasa a la función de entrega como un tf.string.
Para pasar imágenes al servicio de predicción, deberás codificar los bytes de imagen comprimidos en base 64, lo que hace que el contenido sea seguro contra modificaciones mientras se transmiten datos binarios a través de la red.
Dado que el modelo implementado espera datos de entrada como bytes sin procesar (sin comprimir), debes asegurarte de que los datos codificados en base64 se conviertan de nuevo en bytes sin procesar (p. ej., JPEG) y, luego, se preprocesen para que coincidan con los requisitos de entrada del modelo antes de que se pasen como entrada al modelo implementado.
Para resolver este problema, define una función de procesamiento (serving_fn) y adjúntala al modelo como un paso de procesamiento previo. Agrega un decorador @tf.function para que la función de entrega se fusione con el modelo subyacente (en lugar de hacerlo de forma ascendente en una CPU).
CONCRETE_INPUT = "numpy_inputs"
def _preprocess(bytes_input):
decoded = tf.io.decode_jpeg(bytes_input, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
resized = tf.image.resize(decoded, size=(128, 128))
return resized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(bytes_inputs):
decoded_images = tf.map_fn(
_preprocess, bytes_inputs, dtype=tf.float32, back_prop=False
)
return {
CONCRETE_INPUT: decoded_images
} # User needs to make sure the key matches model's input
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(bytes_inputs):
images = preprocess_fn(bytes_inputs)
prob = m_call(**images)
return prob
m_call = tf.function(tfhub_model.call).get_concrete_function(
[tf.TensorSpec(shape=[None, 128, 128, 3], dtype=tf.float32, name=CONCRETE_INPUT)]
)
tf.saved_model.save(tfhub_model, MODEL_DIR, signatures={"serving_default": serving_fn})
Cuando envías datos para la predicción como un paquete de solicitud HTTP, los datos de la imagen se codifican en base64, pero el modelo de TensorFlow toma la entrada de numpy. Tu función de servicio realizará la conversión de base64 a un array de NumPy.
Cuando realices una solicitud de predicción, deberás enrutarla a la función de entrega en lugar de al modelo, por lo que deberás conocer el nombre de la capa de entrada de la función de entrega. Podemos obtener este nombre de la firma de la función de procesamiento.
loaded = tf.saved_model.load(MODEL_DIR)
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input name:", serving_input)
Paso 2: Importa al registro y realiza la implementación
En las secciones anteriores, viste cómo importar un modelo a Vertex AI Model Registry a través de la IU. En esta sección, verás una forma alternativa de usar el SDK. Ten en cuenta que, si lo prefieres, puedes usar la IU aquí.
model = aiplatform.Model.upload(
display_name="optimized-model",
artifact_uri=MODEL_DIR,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
print(model)
También puedes implementar el modelo con el SDK en lugar de la IU.
endpoint = model.deploy(
deployed_model_display_name='my-bytes-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
Paso 3: Prueba el modelo
Ahora puedes probar el extremo. Como modificamos la función de entrega, esta vez puedes enviar la imagen directamente (codificada en base64) en la solicitud en lugar de cargarla primero en NumPy. Esto también te permitirá enviar imágenes más grandes sin alcanzar el límite de tamaño de Vertex AI Predictions.
Vuelve a descargar las etiquetas de imágenes
import numpy as np
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
Codifica la imagen en Base64.
import base64
with open("test-image.jpg", "rb") as f:
data = f.read()
b64str = base64.b64encode(data).decode("utf-8")
Realiza una llamada de predicción y especifica el nombre de la capa de entrada de la función de entrega que definimos antes en la variable serving_input.
instances = [{serving_input: {"b64": b64str}}]
# Make request
result = endpoint.predict(instances=instances).predictions
# Convert image class to string label
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI para hacer lo siguiente:
- Aloja e implementa un modelo previamente entrenado
Para obtener más información sobre las distintas partes de Vertex, consulte la documentación.
9. Limpieza
Debido a que los notebooks administrados de Vertex AI Workbench tienen una función de cierre por inactividad, no necesitas preocuparte por cerrar la instancia. Si quieres cerrar la instancia de forma manual, haz clic en el botón Detener (Stop) en la sección Vertex AI Workbench de la consola. Si quieres borrar el notebook por completo, haz clic en el botón Borrar (Delete).

Para borrar el bucket de almacenamiento, en el menú de navegación de la consola de Cloud, navega a Almacenamiento, selecciona tu bucket y haz clic en Borrar (Delete):
