
1. 概要
このラボでは、Vertex AI を使用して、事前トレーニング済みの画像分類モデルから予測を取得します。
学習内容
次の方法を学習します。
- TensorFlow モデルを Vertex AI Model Registry にインポートする
- オンライン予測を取得する
- TensorFlow サービス提供関数を更新する
このラボを Google Cloud で実行するための総費用は約 $1 です。
2. Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルにそれぞれ個別のサービスを介してアクセスする必要がありましたが、Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API へと結合します。既存のプロジェクトを Vertex AI に移行することもできます。
Vertex AI には、エンドツーエンドの ML ワークフローをサポートするさまざまなプロダクトが含まれています。このラボでは、以下でハイライト表示されているプロダクト(Predictions と Workbench)を中心に学習します。

3. ユースケースの概要
このラボでは、TensorFlow Hub から事前トレーニング済みモデルを取得して Vertex AI にデプロイする方法を学びます。TensorFlow Hub は、エンベディング、テキスト生成、音声テキスト変換、画像セグメンテーションなど、さまざまな問題領域のトレーニング済みモデルのリポジトリです。
このラボで使用する例は、ImageNet データセットで事前トレーニングされた MobileNet V1 画像分類モデルです。TensorFlow Hub や他の同様のディープ ラーニング リポジトリの既製モデルを活用することで、モデルのトレーニングを気にすることなく、さまざまな予測タスクに高品質の ML モデルをデプロイできます。
4. 環境の設定
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順を行ってください。
ステップ 1: Compute Engine API を有効にする
[Compute Engine] に移動して、まだ有効になっていない場合は [**有効にする**] を選択します。
ステップ 2: Vertex AI API を有効にする
Cloud コンソールの [Vertex AI] セクションに移動し、[**Vertex AI API を有効にする**] をクリックします。

ステップ 3: Vertex AI Workbench インスタンスを作成する
Cloud Console の [Vertex AI] セクションで [ワークベンチ] をクリックします。

Notebooks API をまだ有効にしていない場合は、有効にします。

有効にしたら、[マネージド ノートブック] をクリックします。

[新しいノートブック] を選択します。

ノートブックの名前を指定して、[権限] で [Service account] を選択します。

[詳細設定] を選択します。
まだ有効になっていない場合は、[セキュリティ] で、[Enable terminal] を選択します。

詳細設定のその他の設定はそのままで構いません。
[作成] をクリックします。インスタンスがプロビジョニングされるまでに数分かかります。
インスタンスが作成されたら、[JUPYTERLAB を開く] を選択します。

5. モデルの登録
ステップ 1: モデルを Cloud Storage にアップロードする
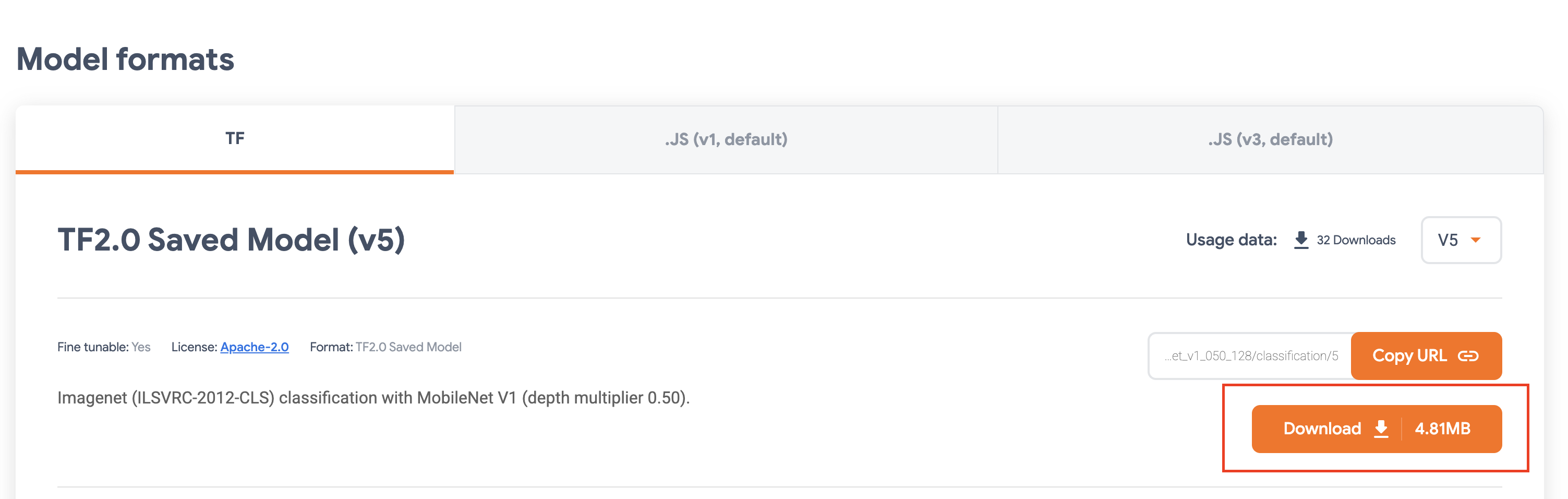
このリンクをクリックして、ImagNet データセットでトレーニングされた MobileNet V1 モデルの TensorFlow Hub ページに移動します。
[ダウンロード] を選択して、保存済みモデル アーティファクトをダウンロードします。
Google Cloud コンソールの [Cloud Storage] セクションで、[作成] を選択します。

バケットに名前を付けて、リージョンとして us-central1 を選択します。次に [作成] をクリックします。

ダウンロードした TensorFlow Hub モデルをバケットにアップロードします。まずファイルを解凍してください。

バケットは次のようになります。
imagenet_mobilenet_v1_050_128_classification_5/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
ステップ 2: モデルをレジストリにインポートする
Cloud コンソールの Vertex AI [Model Registry] セクションに移動します。

[IMPORT] を選択します。
[新しいモデルとしてインポート] を選択して、モデルの名前を入力します。

[モデル設定] で、最新のビルド済み TensorFlow コンテナを指定します。次に、モデル アーティファクトを保存した Cloud Storage のパスを選択します。

[説明可能性] セクションはスキップできます。
次に [IMPORT] を選択します。
インポートすると、モデルが Model Registry に表示されます。

6. モデルをデプロイする
Model Registry で、モデルの右側にあるその他アイコンを選択し、[エンドポイントにデプロイ] をクリックします。

[エンドポイントの定義] で [新しいエンドポイントを作成する] を選択し、エンドポイントに名前を付けます。
[モデル設定] で、[コンピューティング ノードの最大数] を 1 に、マシンタイプを n1-standard-2 に設定し、他の設定はそのままにします。次に [デプロイ] をクリックします。

デプロイされると、デプロイ ステータスが [Vertex AI にデプロイ済み] に変わります。

7. 予測を取得する
設定手順で作成した Workbench ノートブックを開きます。Launcher から新しい TensorFlow 2 ノートブックを作成します。

次のセルを実行して、必要なライブラリをインポートします。
from google.cloud import aiplatform
import tensorflow as tf
import numpy as np
from PIL import Image
TensorFlow Hub からダウンロードした MobileNet モデルは、ImageNet データセットでトレーニングされています。MobileNet モデルの出力は、ImageNet データセットのクラスラベルに対応する数値です。その数値を文字列ラベルに変換するには、画像ラベルをダウンロードする必要があります。
# Download image labels
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
エンドポイントにアクセスするには、エンドポイント リソースを定義する必要があります。{PROJECT_NUMBER} と {ENDPOINT_ID} を必ず置き換えてください。
PROJECT_NUMBER = "{PROJECT_NUMBER}"
ENDPOINT_ID = "{ENDPOINT_ID}"
endpoint = aiplatform.Endpoint(
endpoint_name=f"projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
プロジェクト番号は、コンソールのホームページで確認できます。

エンドポイント ID は、Vertex AI の [エンドポイント] セクションにあります。

次に、エンドポイントをテストします。
まず、次の画像をダウンロードして、インスタンスにアップロードします。

PIL で画像を開きます。次に、サイズを変更して 255 でスケーリングします。モデルが想定する画像サイズは、モデルの TensorFlow Hub ページで確認できます。
IMAGE_PATH = "test-image.jpg"
IMAGE_SIZE = (128, 128)
im = Image.open(IMAGE_PATH)
im = im.resize(IMAGE_SIZE
im = np.array(im)/255.0
次に、NumPy データをリストに変換して、HTTP リクエストの本文で送信できるようにします。
x_test = im.astype(np.float32).tolist()
最後に、エンドポイントに予測呼び出しを行い、対応する文字列ラベルを検索します。
# make prediction request
result = endpoint.predict(instances=[x_test]).predictions
# post process result
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
8. [省略可] TF Serving を使用して予測を最適化する
より現実的な例では、画像を NumPy に読み込むのではなく、画像自体をエンドポイントに直接送信することをおすすめします。この方が効率的ですが、TensorFlow モデルのサービス提供関数を変更する必要があります。この変更は、入力データをモデルが想定する形式に変換するために必要です。
ステップ 1: サービス提供関数を変更する
新しい TensorFlow ノートブックを開き、必要なライブラリをインポートします。
from google.cloud import aiplatform
import tensorflow as tf
今回は、保存済みモデル アーティファクトをダウンロードする代わりに、hub.KerasLayer を使用してモデルを TensorFlow に読み込みます。これは、TensorFlow SavedModel を Keras レイヤとしてラップします。モデルを作成するには、ダウンロードした TF Hub モデルをレイヤとして Keras Sequential API を使用し、モデルの入力形状を指定します。
tfhub_model = tf.keras.Sequential(
[hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v1_050_128/classification/5")]
)
tfhub_model.build([None, 128, 128, 3])
前に作成したバケットの URI を定義します。
BUCKET_URI = "gs://{YOUR_BUCKET}"
MODEL_DIR = BUCKET_URI + "/bytes_model"
オンライン予測サーバーにリクエストを送信すると、リクエストは HTTP サーバーによって受信されます。HTTP サーバーは、HTTP リクエスト コンテンツの本文から予測リクエストを抽出します。抽出された予測リクエストは、サービス提供関数に転送されます。Vertex AI のビルド済み予測コンテナの場合、リクエスト コンテンツは tf.string としてサービス提供関数に渡されます。
画像を予測サービスに渡すには、圧縮された画像バイトを base64 にエンコードする必要があります。これにより、ネットワーク経由でバイナリデータを送信する際にコンテンツが変更されるのを防ぐことができます。
デプロイされたモデルは入力データを未加工(圧縮されていない)バイトとして想定しているため、base64 でエンコードされたデータが未加工バイト(JPEG など)に変換され、モデルの入力要件に合わせて前処理されてから、デプロイされたモデルに入力として渡されるようにする必要があります。
この問題を解決するには、サービス提供関数(serving_fn)を定義し、前処理ステップとしてモデルにアタッチします。@tf.function デコレータを追加すると、サービス提供関数が(CPU のアップストリームではなく)基盤となるモデルに統合されます。
CONCRETE_INPUT = "numpy_inputs"
def _preprocess(bytes_input):
decoded = tf.io.decode_jpeg(bytes_input, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
resized = tf.image.resize(decoded, size=(128, 128))
return resized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(bytes_inputs):
decoded_images = tf.map_fn(
_preprocess, bytes_inputs, dtype=tf.float32, back_prop=False
)
return {
CONCRETE_INPUT: decoded_images
} # User needs to make sure the key matches model's input
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(bytes_inputs):
images = preprocess_fn(bytes_inputs)
prob = m_call(**images)
return prob
m_call = tf.function(tfhub_model.call).get_concrete_function(
[tf.TensorSpec(shape=[None, 128, 128, 3], dtype=tf.float32, name=CONCRETE_INPUT)]
)
tf.saved_model.save(tfhub_model, MODEL_DIR, signatures={"serving_default": serving_fn})
予測用のデータを HTTP リクエスト パケットとして送信すると、画像データは base64 でエンコードされますが、TensorFlow モデルは numpy 入力を受け取ります。サービス提供関数は、base64 から numpy 配列への変換を行います。
予測リクエストを行う場合は、リクエストをモデルではなくサービス提供関数にルーティングする必要があります。そのため、サービス提供関数の入力レイヤ名を知る必要があります。この名前は、サービス提供関数の署名から取得できます。
loaded = tf.saved_model.load(MODEL_DIR)
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input name:", serving_input)
ステップ 2: レジストリにインポートしてデプロイする
前のセクションでは、UI を使用してモデルを Vertex AI Model Registry にインポートする方法について説明しました。このセクションでは、代わりに SDK を使用する方法について説明します。必要に応じて、ここで UI を使用することもできます。
model = aiplatform.Model.upload(
display_name="optimized-model",
artifact_uri=MODEL_DIR,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
print(model)
UI ではなく SDK を使用してモデルをデプロイすることもできます。
endpoint = model.deploy(
deployed_model_display_name='my-bytes-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
ステップ 3: モデルをテストする
これで、エンドポイントをテストできます。サービス提供関数を変更したため、今回は画像を NumPy に読み込むのではなく、リクエストで画像を直接(base64 でエンコード)送信できます。これにより、Vertex AI Predictions のサイズ上限に達することなく、より大きな画像を送信することもできます。
画像ラベルを再度ダウンロードします。
import numpy as np
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
画像を base64 でエンコードします。
import base64
with open("test-image.jpg", "rb") as f:
data = f.read()
b64str = base64.b64encode(data).decode("utf-8")
予測呼び出しを行い、前に serving_input 変数で定義したサービス提供関数の入力レイヤ名を指定します。
instances = [{serving_input: {"b64": b64str}}]
# Make request
result = endpoint.predict(instances=instances).predictions
# Convert image class to string label
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
お疲れさまでした🎉
Vertex AI を使って次のことを行う方法を学びました。
- 事前トレーニング済みモデルをホストしてデプロイする
Vertex のさまざまな部分の説明については、ドキュメントをご覧ください。
9. クリーンアップ
Vertex AI Workbench マネージド ノートブックにはアイドル シャットダウン機能があります。インスタンスのシャットダウンを気にする必要はありません。インスタンスを手動でシャットダウンする場合は、コンソールで [Vertex AI] の [ワークベンチ] セクションにある [停止] ボタンをクリックします。ノートブックを完全に削除する場合は、[削除] ボタンをクリックします。

ストレージ バケットを削除するには、Cloud コンソールのナビゲーション メニューで [ストレージ] に移動してバケットを選択し、[削除] をクリックします。
