
1. 總覽
在本實驗室中,您將使用 Vertex AI,從預先訓練的圖像分類模型取得預測結果。
課程內容
內容如下:
- 將 TensorFlow 模型匯入 Vertex AI Model Registry
- 取得線上預測
- 更新 TensorFlow Serving 函式
在 Google Cloud 上執行這個實驗室的總費用約為 $1 美元。
2. Vertex AI 簡介
本實驗室使用 Google Cloud 最新推出的 AI 產品服務。Vertex AI 整合了 Google Cloud 機器學習服務,提供流暢的開發體驗。以 AutoML 訓練的模型和自訂模型,先前需透過不同的服務存取。這項新服務將兩者併至單一 API,並加入其他新產品。您也可以將現有專案遷移至 Vertex AI。
Vertex AI 包含許多不同的產品,可支援端對端機器學習工作流程。本實驗室將著重於下列產品:Predictions和Workbench

3. 用途總覽
在本實驗室中,您將瞭解如何從 TensorFlow Hub 取得預先訓練的模型,並部署至 Vertex AI。TensorFlow Hub 是已訓練模型的存放區,適用於各種問題領域,例如嵌入、文字生成、語音轉文字、影像分割等。
本實驗室使用的範例是以 ImageNet 資料集預先訓練的 MobileNet V1 圖片分類模型。只要運用 TensorFlow Hub 或其他類似的深度學習存放區提供的現成模型,您就能為多項預測工作部署高品質的機器學習模型,不必擔心模型訓練問題。
4. 設定環境
您必須擁有已啟用計費功能的 Google Cloud Platform 專案,才能執行這項程式碼研究室。如要建立專案,請按照這裡的說明操作。
步驟 1:啟用 Compute Engine API
前往「Compute Engine」,然後選取「啟用」 (如果尚未啟用)。
步驟 2:啟用 Vertex AI API
前往 Cloud 控制台的 Vertex AI 專區,然後點選「啟用 Vertex AI API」。

步驟 3:建立 Vertex AI Workbench 執行個體
在 Cloud 控制台的「Vertex AI」部分中,按一下「Workbench」:

如果尚未啟用 Notebooks API,請先啟用。

啟用後,按一下「MANAGED NOTEBOOKS」(代管型筆記本):

然後選取「新增記事本」。

為筆記本命名,然後在「權限」下方選取「服務帳戶」

選取「進階設定」。
在「安全性」下方,選取「啟用終端機」(如果尚未啟用)。

其他進階設定可以保留原樣。
接著點選「建立」。執行個體會在幾分鐘內佈建完畢。
建立執行個體後,請選取「OPEN JUPYTERLAB」。

5. 註冊模型
步驟 1:將模型上傳至 Cloud Storage
按一下這個連結,前往 TensorFlow Hub 頁面,查看以 ImageNet 資料集訓練的 MobileNet V1 模型。
選取 下載,即可下載儲存的模型構件。

在 Google Cloud 控制台的 Cloud Storage 專區中,選取「CREATE」(建立)

為 bucket 命名,並選取 us-central1 做為區域。然後按一下「建立」。
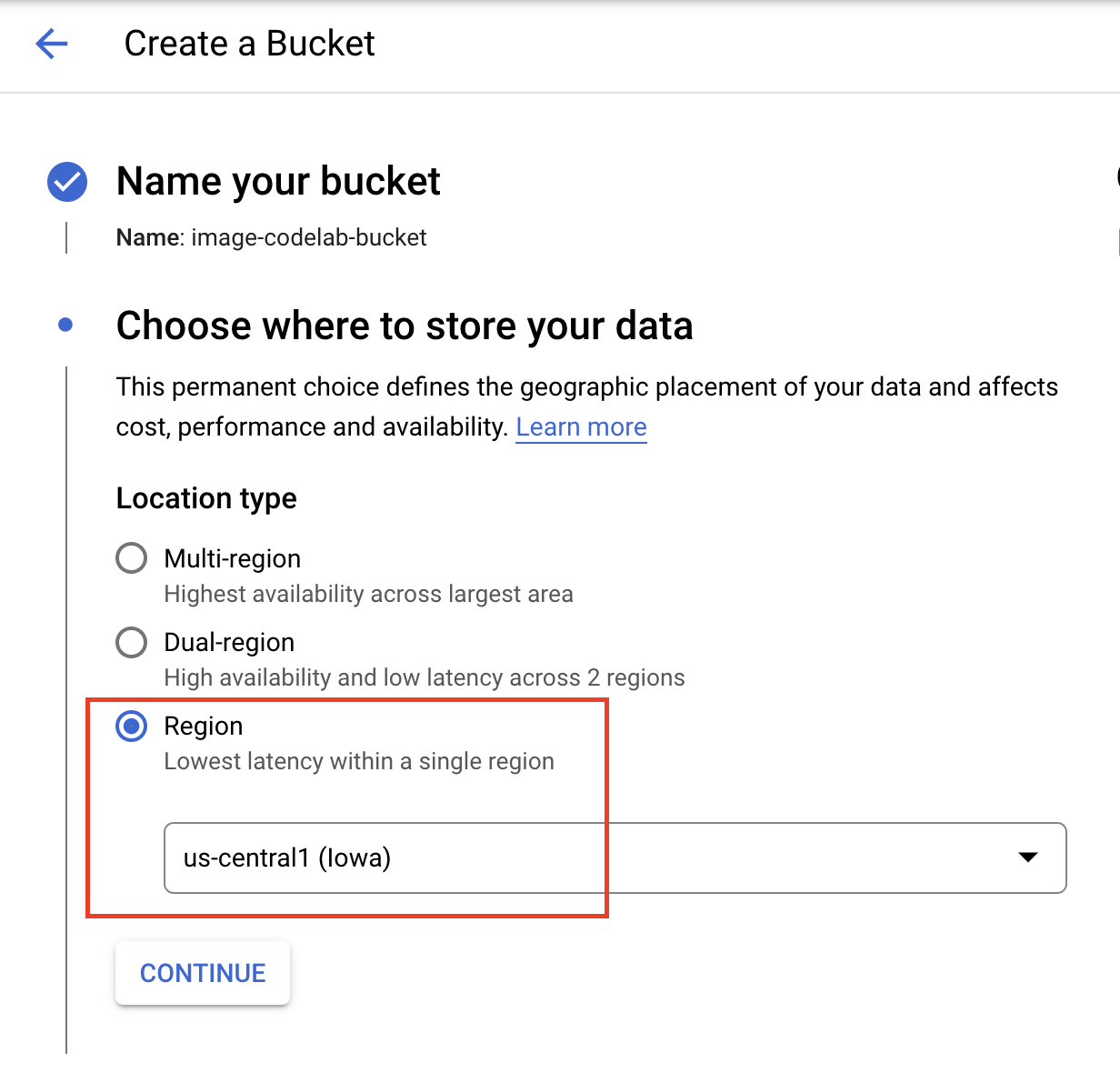
將下載的 TensorFlow Hub 模型上傳至值區。請務必先解壓縮檔案。

您的儲存空間應如下所示:
imagenet_mobilenet_v1_050_128_classification_5/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
步驟 2:將模型匯入登錄檔
前往 Cloud 控制台的 Vertex AI 模型登錄專區。

選取「匯入」IMPORT
選取「匯入為新模型」,然後為模型命名。
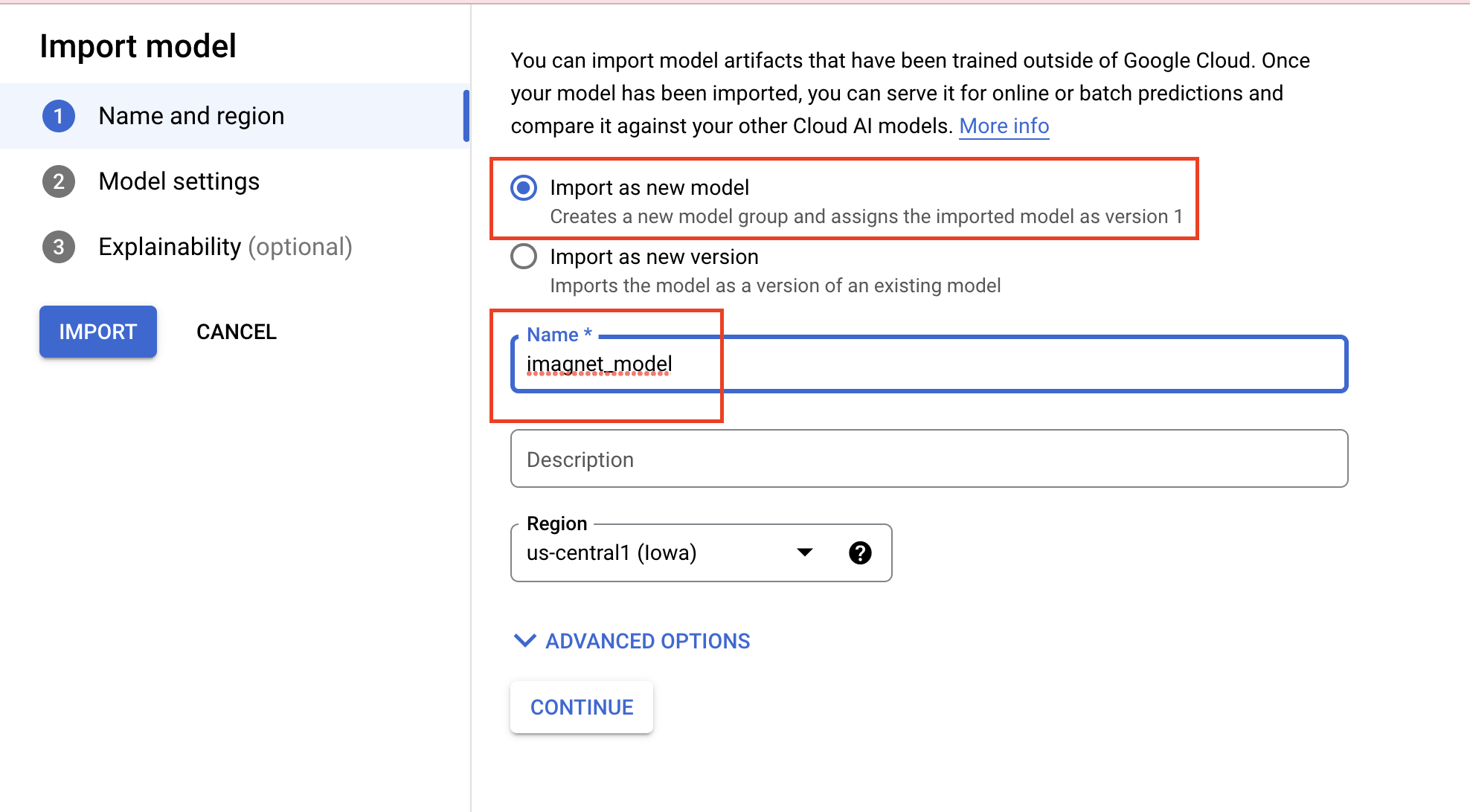
在「模型設定」下方,指定最新的預建 TensorFlow 容器。然後選取 Cloud Storage 中儲存模型構件的路徑。

您可以略過「可解釋性」部分。
然後選取「匯入」IMPORT
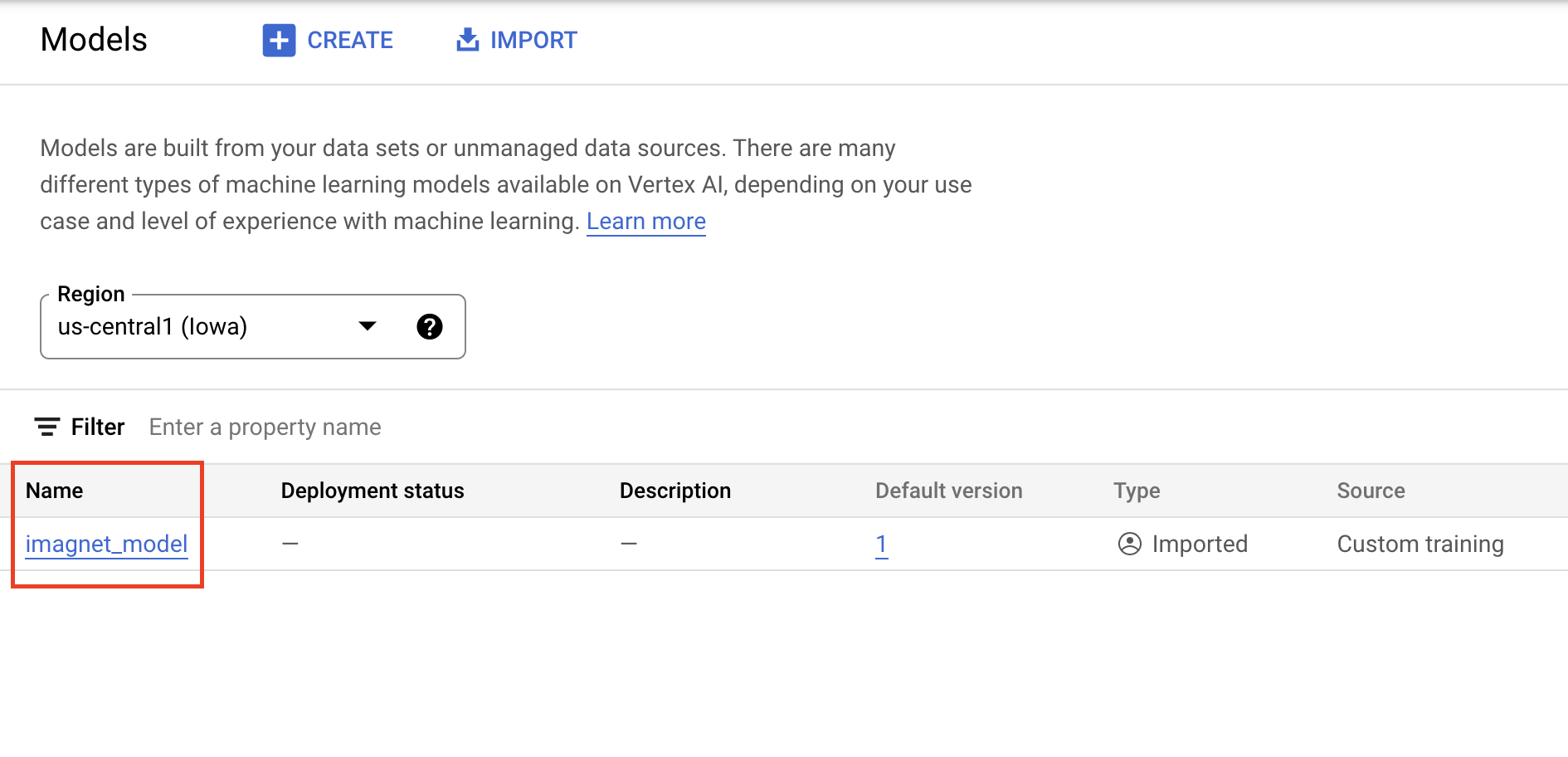
匯入完成後,模型就會顯示在模型登錄中
6. 部署模型
在「模型登錄」中,選取模型右側的三點圖示,然後按一下「Deploy to endpoint」(部署至端點)。

在「定義端點」下方,選取「建立新端點」,然後為端點命名。
在「模型設定」下方,將「運算節點數上限」設為 1,機型設為 n1-standard-2,其餘設定維持不變。然後點按「部署」。

部署完成後,部署狀態會變更為「已在 Vertex AI 上部署」。

7. 取得預測結果
開啟您在設定步驟中建立的 Workbench 筆記本。從啟動器建立新的 TensorFlow 2 筆記本。

執行下列儲存格,匯入必要的程式庫
from google.cloud import aiplatform
import tensorflow as tf
import numpy as np
from PIL import Image
從 TensorFlow Hub 下載的 MobileNet 模型是透過 ImageNet 資料集訓練的。MobileNet 模型的輸出內容是數字,對應至 ImageNet 資料集中的類別標籤。如要將該數字轉換為字串標籤,請下載圖片標籤。
# Download image labels
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
如要存取端點,您必須定義端點資源。請務必替換 {PROJECT_NUMBER} 和 {ENDPOINT_ID}。
PROJECT_NUMBER = "{PROJECT_NUMBER}"
ENDPOINT_ID = "{ENDPOINT_ID}"
endpoint = aiplatform.Endpoint(
endpoint_name=f"projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
您可以在控制台首頁找到專案編號。

以及 Vertex AI「端點」部分中的端點 ID。

接著,您會測試端點。
首先,請下載下列圖片,然後上傳至執行個體。

使用 PIL 開啟圖片。然後調整大小並縮放 255。請注意,模型預期的圖片大小可在模型的 TensorFlow Hub 頁面找到。
IMAGE_PATH = "test-image.jpg"
IMAGE_SIZE = (128, 128)
im = Image.open(IMAGE_PATH)
im = im.resize(IMAGE_SIZE
im = np.array(im)/255.0
接著,將 NumPy 資料轉換為清單,以便在 HTTP 要求的本文中傳送。
x_test = im.astype(np.float32).tolist()
最後,對端點發出預測呼叫,然後查閱對應的字串標籤。
# make prediction request
result = endpoint.predict(instances=[x_test]).predictions
# post process result
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
8. [選用] 使用 TF Serving 最佳化預測結果
如要查看更貼近現實的範例,您可能需要直接將圖片傳送至端點,而不是先載入 NumPy。這種做法效率較高,但您必須修改 TensorFlow 模型的服務函式。這項修改作業是為了將輸入內容轉換為模型預期的格式。
步驟 1:修改服務函式
開啟新的 TensorFlow 筆記本,然後匯入必要程式庫。
from google.cloud import aiplatform
import tensorflow as tf
這次您不會下載儲存的模型構件,而是使用 hub.KerasLayer 將模型載入 TensorFlow,這會將 TensorFlow SavedModel 包裝為 Keras 層。如要建立模型,您可以搭配使用 Keras Sequential API 和下載的 TF Hub 模型 (做為層),並指定模型的輸入形狀。
tfhub_model = tf.keras.Sequential(
[hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v1_050_128/classification/5")]
)
tfhub_model.build([None, 128, 128, 3])
定義您先前建立的 bucket 的 URI。
BUCKET_URI = "gs://{YOUR_BUCKET}"
MODEL_DIR = BUCKET_URI + "/bytes_model"
當您將要求傳送至線上預測伺服器時,HTTP 伺服器會收到該要求。HTTP 伺服器會從 HTTP 要求內容主體中擷取預測要求。擷取的預測要求會轉送至服務函式。如果是 Vertex AI 預建預測容器,要求內容會以 tf.string 形式傳遞至服務函式。
如要將圖片傳遞至預測服務,您需要將壓縮的圖片位元組編碼為 Base64,這樣在透過網路傳輸二進位資料時,內容就不會遭到修改。
由於已部署的模型預期輸入資料為原始 (未壓縮) 位元組,因此您需要確保 base64 編碼資料會轉換回原始位元組 (例如 JPEG),然後經過預先處理,符合模型輸入需求,再做為輸入內容傳遞至已部署的模型。
如要解決這個問題,請定義服務函式 (serving_fn),並將其附加至模型做為前處理步驟。您會新增 @tf.function 裝飾器,以便將服務函式融合至基礎模型 (而非 CPU 上的上游)。
CONCRETE_INPUT = "numpy_inputs"
def _preprocess(bytes_input):
decoded = tf.io.decode_jpeg(bytes_input, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
resized = tf.image.resize(decoded, size=(128, 128))
return resized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(bytes_inputs):
decoded_images = tf.map_fn(
_preprocess, bytes_inputs, dtype=tf.float32, back_prop=False
)
return {
CONCRETE_INPUT: decoded_images
} # User needs to make sure the key matches model's input
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(bytes_inputs):
images = preprocess_fn(bytes_inputs)
prob = m_call(**images)
return prob
m_call = tf.function(tfhub_model.call).get_concrete_function(
[tf.TensorSpec(shape=[None, 128, 128, 3], dtype=tf.float32, name=CONCRETE_INPUT)]
)
tf.saved_model.save(tfhub_model, MODEL_DIR, signatures={"serving_default": serving_fn})
以 HTTP 要求封包形式傳送預測資料時,圖片資料會經過 base64 編碼,但 TensorFlow 模型會採用 NumPy 輸入。服務函式會將 base64 轉換為 NumPy 陣列。
提出預測要求時,您需要將要求路徑導向服務函式,而非模型,因此您有知情必要知道服務函式的輸入層名稱。我們可以從服務函式簽章取得這個名稱。
loaded = tf.saved_model.load(MODEL_DIR)
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input name:", serving_input)
步驟 2:匯入登錄檔並部署
在先前的章節中,您已瞭解如何透過 UI 將模型匯入 Vertex AI Model Registry。本節將說明如何使用 SDK 進行替代操作。請注意,您還是可以改用這裡的 UI。
model = aiplatform.Model.upload(
display_name="optimized-model",
artifact_uri=MODEL_DIR,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
print(model)
您也可以使用 SDK 部署模型,而非 UI。
endpoint = model.deploy(
deployed_model_display_name='my-bytes-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
步驟 3:測試模型
現在可以測試端點。由於我們修改了服務函式,這次您可以直接在要求中傳送圖片 (採用 Base64 編碼),不必先將圖片載入 NumPy。這樣一來,您就能傳送較大的圖片,不會達到 Vertex AI Predictions 的大小限制。
再次下載圖片標籤
import numpy as np
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
將圖片進行 Base64 編碼。
import base64
with open("test-image.jpg", "rb") as f:
data = f.read()
b64str = base64.b64encode(data).decode("utf-8")
進行預測呼叫,指定服務函式的輸入層名稱,也就是我們稍早定義的 serving_input 變數。
instances = [{serving_input: {"b64": b64str}}]
# Make request
result = endpoint.predict(instances=instances).predictions
# Convert image class to string label
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
🎉 恭喜!🎉
您已瞭解如何使用 Vertex AI 執行下列作業:
- 代管及部署預先訓練模型
如要進一步瞭解 Vertex 的其他部分,請參閱說明文件。
9. 清除
由於 Vertex AI Workbench 代管筆記本具有閒置關機功能,因此我們不必擔心執行個體關機問題。如要手動關閉執行個體,請按一下控制台 Vertex AI Workbench 專區的「停止」按鈕。如要徹底刪除筆記本,請按一下「刪除」按鈕。

如要刪除 Storage Bucket,請使用 Cloud 控制台中的導覽選單瀏覽至 Storage,選取 bucket,然後按一下「Delete」:
