1. Descripción general
En este lab, aprenderás a analizar metadatos de tus ejecuciones de Vertex Pipelines con Vertex ML Metadata.
Qué aprenderá
Aprenderás a hacer lo siguiente:
- Usa el SDK de Kubeflow Pipelines para compilar una canalización de AA que cree un conjunto de datos en Vertex AI y entrene e implemente un modelo personalizado de Scikit-learn en ese conjunto de datos
- Escribe componentes personalizados de canalización que generen artefactos y metadatos
- Comparar las ejecuciones de Vertex Pipelines, tanto en la consola de Cloud como de manera programática
- Realiza un seguimiento del linaje de los artefactos generados por canalización
- Consulta los metadatos de ejecución de tu canalización
El costo total de la ejecución de este lab en Google Cloud es de aproximadamente $2.
2. Introducción a Vertex AI
En este lab, se utiliza la oferta de productos de IA más reciente de Google Cloud. Vertex AI integra las ofertas de AA de Google Cloud en una experiencia de desarrollo fluida. Anteriormente, se podía acceder a los modelos personalizados y a los entrenados con AutoML mediante servicios independientes. La nueva oferta combina ambos en una sola API, junto con otros productos nuevos. También puedes migrar proyectos existentes a Vertex AI.
Además de los servicios de entrenamiento y de implementación de modelos, Vertex AI también incluye una variedad de productos de operaciones de AA, como Vertex Pipelines, ML Metadata, Model Monitoring, Feature Store y muchos más. Puedes ver todas las ofertas de productos de Vertex AI en el diagrama que se muestra a continuación.
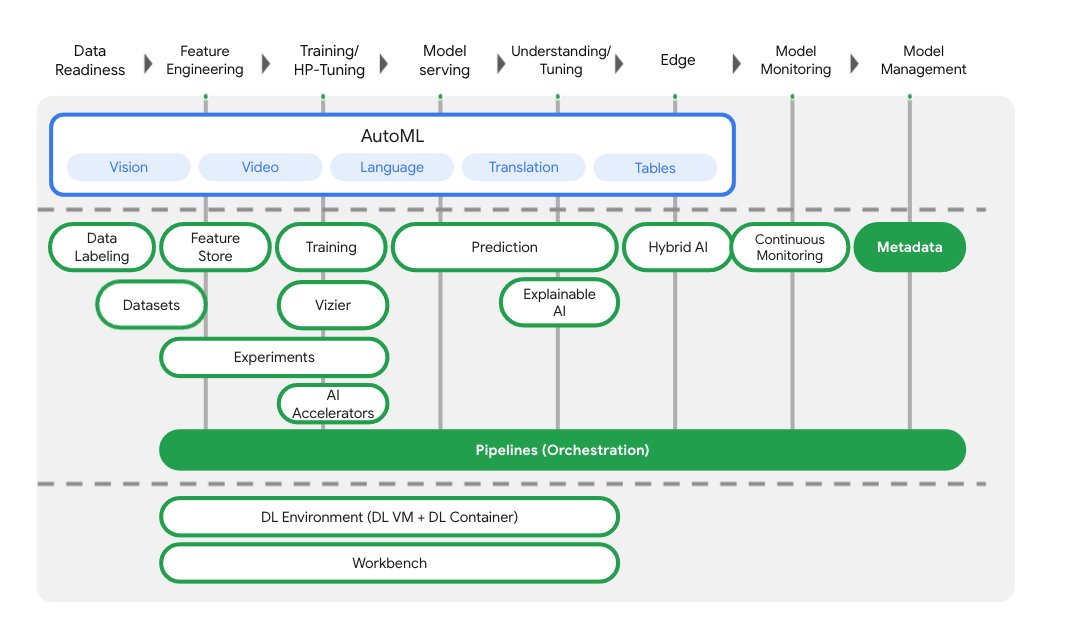
Este lab se enfoca en Vertex Pipelines y Vertex ML Metadata.
Si tienes comentarios sobre Vertex AI, consulta la página de asistencia.
¿Por qué son útiles las canalizaciones de AA?
Antes de comenzar, primero debes comprender por qué deberías usar canalizaciones. Imagina que estás compilando un flujo de trabajo de AA que incluye procesar datos, implementar y entrenar modelos, ajustar hiperparámetros y realizar evaluaciones. Es posible que cada uno de estos pasos tenga dependencias diferentes, lo que podría ser difícil de manejar si tratas todo el flujo de trabajo como una aplicación monolítica. A medida que empiezas a escalar tu proceso de AA, es posible que quieras compartir el flujo de trabajo de AA con otras personas de tu equipo para que puedan ejecutarlo y agregar más código. Pero esto puede ser complicado sin un proceso confiable y reproducible. Con las canalizaciones, cada paso en tu proceso de AA tiene su propio contenedor. Así, podrás desarrollar pasos de forma independiente y hacer un seguimiento de la entrada y salida en cada paso de manera reproducible. Además, puedes programar o activar ejecuciones para tu canalización en función de otros eventos de tu entorno de Cloud, como iniciar la ejecución de una canalización cuando hay nuevos datos de entrenamiento disponibles.
Resumen: Las canalizaciones te ayudan a automatizar y reproducir tu flujo de trabajo de AA.
3. Configura el entorno de Cloud
Para ejecutar este codelab, necesitarás un proyecto de Google Cloud Platform que tenga habilitada la facturación. Para crear un proyecto, sigue estas instrucciones.
Inicie Cloud Shell
En este lab, trabajarás con una sesión de Cloud Shell, que es un intérprete de comandos alojado en una máquina virtual que se ejecuta en la nube de Google. Podrías ejecutar fácilmente esta sección de forma local, en tu computadora, pero Cloud Shell brinda una experiencia reproducible en un entorno coherente para todo el mundo. Después de este lab, puedes volver a probar esta sección en tu computadora.
Activar Cloud Shell
En la parte superior derecha de la consola de Cloud, haz clic en el siguiente botón para Activar Cloud Shell:

Si nunca has iniciado Cloud Shell, aparecerá una pantalla intermedia (mitad inferior de la página) en la que se describirá qué es. Si ese es el caso, haz clic en Continuar (y no volverás a verla). Así es como se ve la pantalla única:
El aprovisionamiento y la conexión a Cloud Shell solo tomará unos minutos.

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Gran parte de tu trabajo en este codelab, si no todo, se puede hacer simplemente con un navegador o tu Chromebook.
Una vez conectado a Cloud Shell, debería ver que ya se autenticó y que el proyecto ya se configuró con tu ID del proyecto.
En Cloud Shell, ejecuta el siguiente comando para confirmar que está autenticado:
gcloud auth list
Resultado del comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto:
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
De lo contrario, puedes configurarlo con el siguiente comando:
gcloud config set project <PROJECT_ID>
Resultado del comando
Updated property [core/project].
Cloud Shell tiene algunas variables de entorno, incluida GOOGLE_CLOUD_PROJECT, que contiene el nombre de nuestro proyecto de Cloud actual. La usaremos en varias secciones de este lab. Para verla, debes ejecutar lo siguiente:
echo $GOOGLE_CLOUD_PROJECT
Habilita las APIs
En pasos posteriores, verás en qué momento se necesitan estos servicios y por qué. Por ahora, ejecuta este comando para que tu proyecto pueda acceder a los servicios de Compute Engine, Container Registry y Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Si se realizó correctamente, se mostrará un mensaje similar a este:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Crea un bucket de Cloud Storage
Para ejecutar un trabajo de entrenamiento en Vertex AI, necesitaremos un bucket de almacenamiento para almacenar los recursos del modelo guardados. El bucket debe ser regional. Usaremos us-central aquí, pero puedes usar otra región (solo debes reemplazarla durante el lab). Si ya tiene un bucket, puede omitir este paso.
Ejecuta los siguientes comandos en la terminal de Cloud Shell para crear un bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
A continuación, le daremos a la cuenta de servicio de Compute acceso a este bucket. Esto garantizará que Vertex Pipelines tenga los permisos necesarios para escribir archivos en el bucket. Ejecute el siguiente comando para agregar este permiso:
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
Crea una instancia de Vertex AI Workbench
En la sección Vertex AI de Cloud Console, haz clic en Workbench:
Allí, en notebooks administrados por el usuario, haz clic en Notebook nuevo:

Luego, selecciona el tipo de instancia TensorFlow Enterprise 2.3 (con LTS) sin GPUs:
Usa las opciones predeterminadas y, luego, haz clic en Crear.
Abre tu notebook
Una vez que se crea la instancia, selecciona Abrir JupyterLab:

4. Configuración de Vertex Pipelines
Existen algunas bibliotecas adicionales que debemos instalar para usar Vertex Pipelines:
- Kubeflow Pipelines: Este es el SDK que usaremos para compilar nuestra canalización. Vertex Pipelines admite canalizaciones en ejecución compiladas con Kubeflow Pipelines o TFX.
- SDK de Vertex AI: Este SDK optimiza la experiencia para llamar a la API de Vertex AI. La usaremos para ejecutar nuestra canalización en Vertex AI.
Crea notebooks de Python y, luego, instala bibliotecas
Primero, en el menú Selector de tu instancia de notebook, selecciona Python 3 para crear un notebook:

Para instalar los dos servicios que usaremos en este lab, primero hay que establecer la marca de usuario en una celda del notebook:
USER_FLAG = "--user"
Luego, ejecuta el siguiente comando en tu notebook:
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
Luego de instalar estos paquetes, deberá reiniciar el kernel:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
A continuación, verifica que instalaste correctamente la versión del SDK de KFP. Debe ser superior o igual a 1.8:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
Luego, confirma que la versión del SDK de Vertex AI sea >= 1.6.2:
!pip list | grep aiplatform
Configure su ID del proyecto y bucket
Durante este lab, podrá hacer referencia al ID del proyecto de Cloud y al bucket que creó anteriormente. A continuación, crearemos variables para cada uno de ellos.
Si desconoce el ID de su proyecto, probablemente logre obtenerlo mediante la ejecución del siguiente comando:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
De lo contrario, configúralo aquí:
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
Luego, cree una variable para almacenar el nombre de su bucket. Si lo creó en este lab, lo siguiente funcionará. De lo contrario, deberá configurarlo de forma manual:
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
Importa las bibliotecas
Agrega lo siguiente para importar las bibliotecas que usaremos durante este codelab:
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
Define constantes
Lo último que debemos hacer antes de crear nuestra canalización es definir algunas variables constantes. PIPELINE_ROOT es la ruta de Cloud Storage en la que se escribirán los artefactos que cree nuestra canalización. Aquí usaremos us-central1 como la región, pero si usaste una región diferente cuando creaste tu bucket, actualiza la variable REGION en el siguiente código:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Luego de ejecutar el código anterior, debería ver impreso el directorio raíz de su canalización. Esta es la ubicación de Cloud Storage en la que se escribirán los artefactos de su canalización, y tendrá el siguiente formato: gs://YOUR-BUCKET-NAME/pipeline_root/.
5. Crea una canalización de 3 pasos con componentes personalizados
El objetivo de este lab es comprender los metadatos de las ejecuciones de canalización. Para ello, necesitaremos una canalización que se ejecute en Vertex Pipelines, que es donde comenzaremos. Aquí definiremos una canalización de 3 pasos con los siguientes componentes personalizados:
get_dataframe: Recupera datos de una tabla de BigQuery y conviértelos en un DataFrame de Pandastrain_sklearn_model: Usa el DataFrame de Pandas para entrenar y exportar un modelo de Scikit Learn, junto con algunas métricas.deploy_model: Implementa el modelo de Scikit Learn exportado en un extremo de Vertex AI.
En esta canalización, usaremos el conjunto de datos de frijoles secos de UCI Machine Learning de KOKLU, M. y OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques"."En Computers and Electronics in Agriculture, 174, 105507. DOI.
Este es un conjunto de datos tabular y, en nuestra canalización, lo usaremos para entrenar, evaluar y, luego, implementar un modelo de Scikit-learn que clasifique los frijoles en uno de 7 tipos según sus características. ¡Comencemos a programar!
Crea componentes basados en funciones de Python
Con el SDK de KFP, podemos crear componentes basados en las funciones de Python. Lo usaremos para los 3 componentes de esta canalización.
Descarga datos de BigQuery y conviértelos a CSV
Primero, compilaremos el componente get_dataframe:
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
Analicemos con más detalle lo que sucede en este componente:
- El decorador
@componentcompila esta función en un componente cuando se ejecuta la canalización. Lo utilizarás cada vez que escribas un componente personalizado. - El parámetro
base_imageespecifica la imagen de contenedor que usará este componente. - Este componente usará algunas bibliotecas de Python, que especificamos a través del parámetro
packages_to_install. - El parámetro
output_component_filees opcional y especifica el archivo yaml en el que se escribirá el componente compilado. Luego de ejecutar la celda, deberías ver que ese archivo se escribió en tu instancia de notebook. Si quieres compartir este componente con otra persona, puedes enviar el archivo yaml generado para que lo cargue con el siguiente comando:
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- A continuación, este componente usa la biblioteca cliente de BigQuery para Python para descargar nuestros datos de BigQuery en un DataFrame de Pandas y, luego, crea un artefacto de salida de esos datos como un archivo CSV. Esto se pasará como entrada a nuestro siguiente componente.
Crea un componente para entrenar un modelo de Scikit-learn
En este componente, tomaremos el CSV que generamos anteriormente y lo usaremos para entrenar un modelo de árbol de decisión de Scikit-learn. Este componente exporta el modelo de Scikit resultante, junto con un artefacto Metrics que incluye la precisión, el framework y el tamaño de nuestro modelo del conjunto de datos que se usó para entrenarlo:
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
Define un componente para subir y, luego, implementar el modelo en Vertex AI
Por último, nuestro último componente tomará el modelo entrenado del paso anterior, lo subirá a Vertex AI y lo implementará en un extremo:
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Aquí usamos el SDK de Vertex AI para subir el modelo con un contenedor creado previamente para la predicción. Luego, implementa el modelo en un extremo y muestra los URIs al modelo y a los recursos del extremo. Más adelante en este codelab, aprenderás más sobre lo que significa mostrar estos datos como artefactos.
Define y compila la canalización
Ahora que ya definimos los tres componentes, crearemos la definición de la canalización. Aquí se describe cómo fluyen los artefactos de entrada y salida entre los pasos:
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
El siguiente comando generará un archivo JSON que utilizará para ejecutarla:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
Inicia dos ejecuciones de canalizaciones
A continuación, iniciaremos dos ejecuciones de nuestra canalización. Primero, definamos una marca de tiempo para usar en los IDs de trabajo de canalización:
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Recuerda que nuestra canalización toma un parámetro cuando la ejecutamos: el bq_table que queremos usar para los datos de entrenamiento. Esta ejecución de canalización usará una versión más pequeña del conjunto de datos de frijoles:
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
A continuación, crea otra ejecución de canalización con una versión más grande del mismo conjunto de datos.
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
Por último, inicie ejecuciones de canalizaciones para ambas ejecuciones. Es mejor hacerlo en dos celdas de notebook separadas para que puedas ver el resultado de cada ejecución.
run1.submit()
Luego, inicia la segunda ejecución:
run2.submit()
Después de ejecutar esta celda, verás un vínculo para ver cada canalización en la consola de Vertex AI. Abre ese vínculo para ver más detalles sobre tu canalización:

Cuando se complete (esta canalización tarda entre 10 y 15 minutos por ejecución), verás algo como lo siguiente:
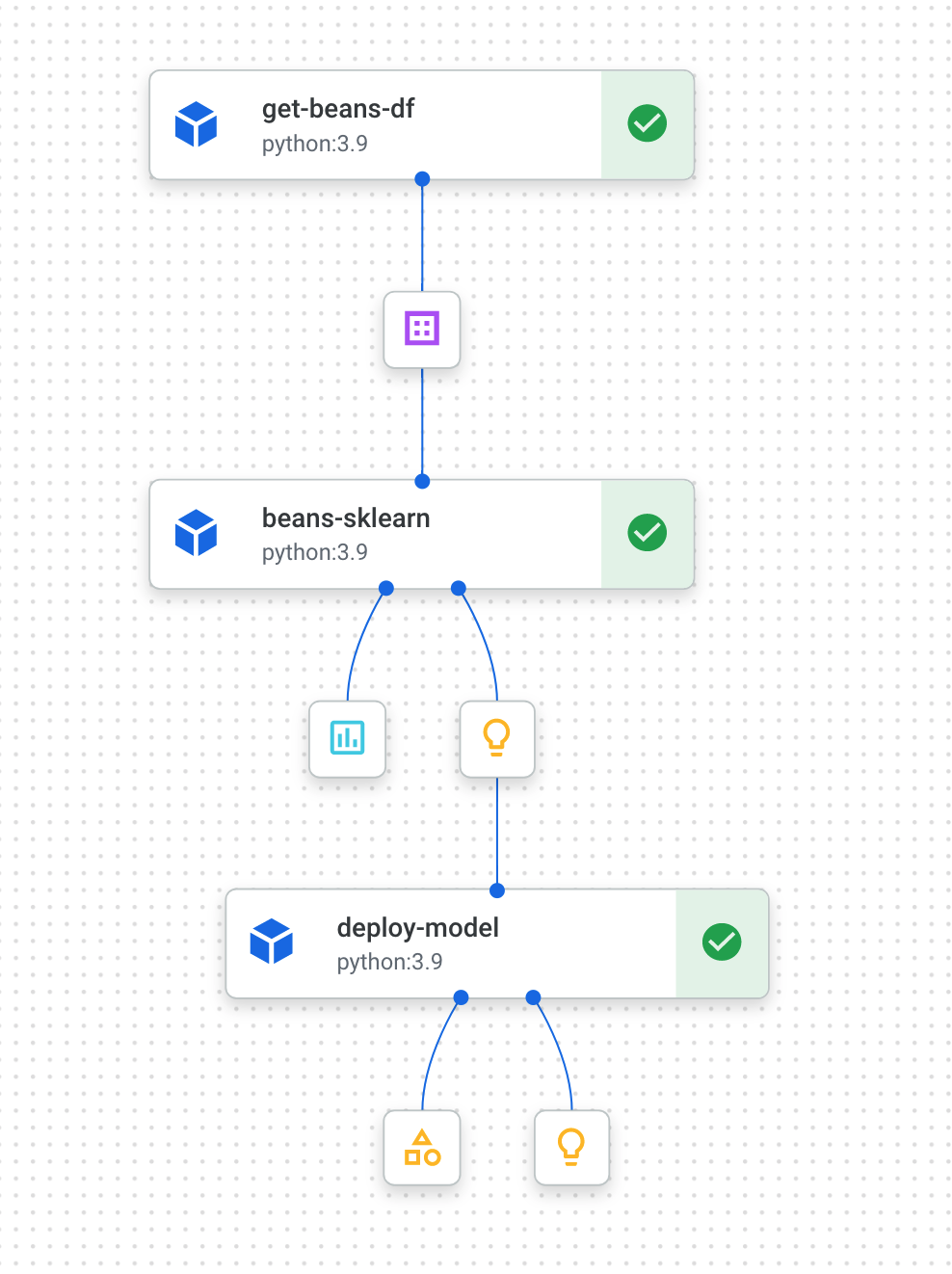
Ahora que tienes dos ejecuciones de canalizaciones completas, está todo listo para que analices con más detalle los artefactos, las métricas y el linaje de las canalizaciones.
6. Información sobre los artefactos y el linaje de la canalización
En el gráfico de tu canalización, verás pequeños cuadros después de cada paso. Esos son artefactos, o resultados generados a partir de un paso de canalización. Existen muchos tipos de artefactos. En esta canalización en particular, tenemos artefactos de conjuntos de datos, métricas, modelos y extremos. Haz clic en el control deslizante Expand Artifacts en la parte superior de la IU para ver más detalles sobre cada uno:
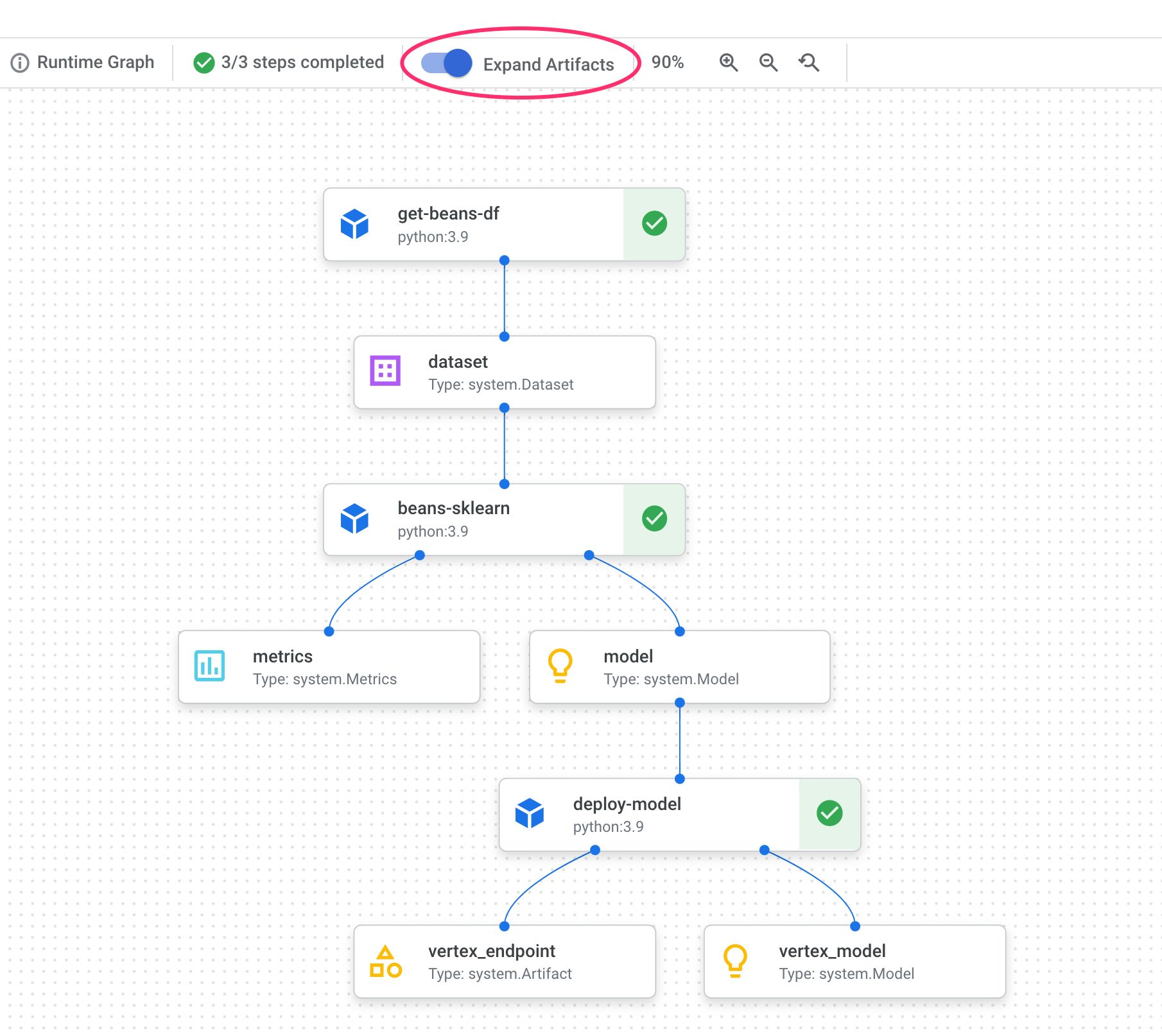
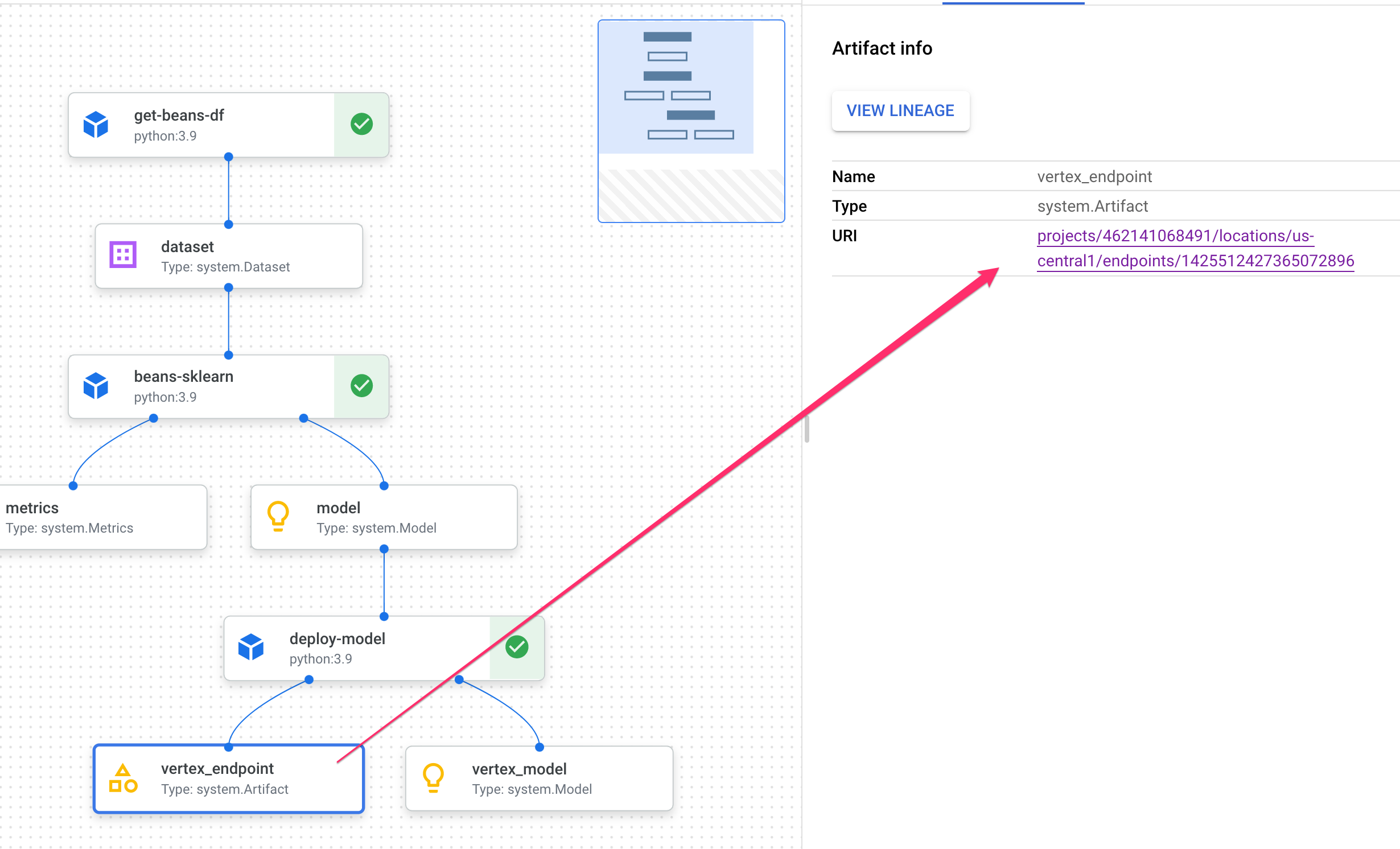
Si haces clic en un artefacto, se mostrarán más detalles sobre él, incluido su URI. Por ejemplo, si haces clic en el artefacto vertex_endpoint, se mostrará el URI en el que puedes encontrar ese extremo implementado en tu consola de Vertex AI:
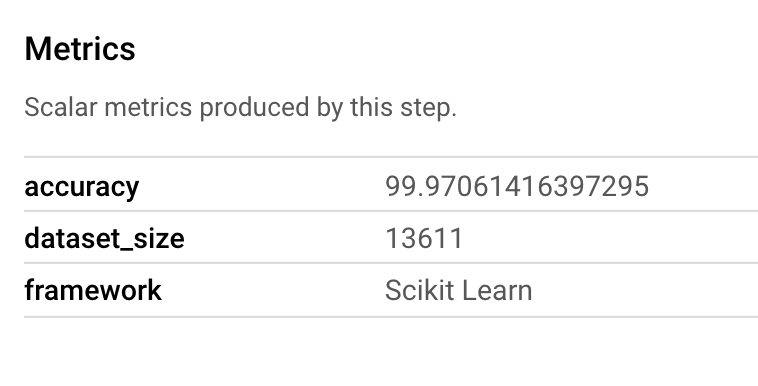
Un artefacto Metrics te permite pasar métricas personalizadas asociadas con un paso de canalización en particular. En el componente sklearn_train de nuestra canalización, registramos métricas sobre la precisión, el framework y el tamaño del conjunto de datos de nuestro modelo. Haz clic en el artefacto de métricas para ver esos detalles:
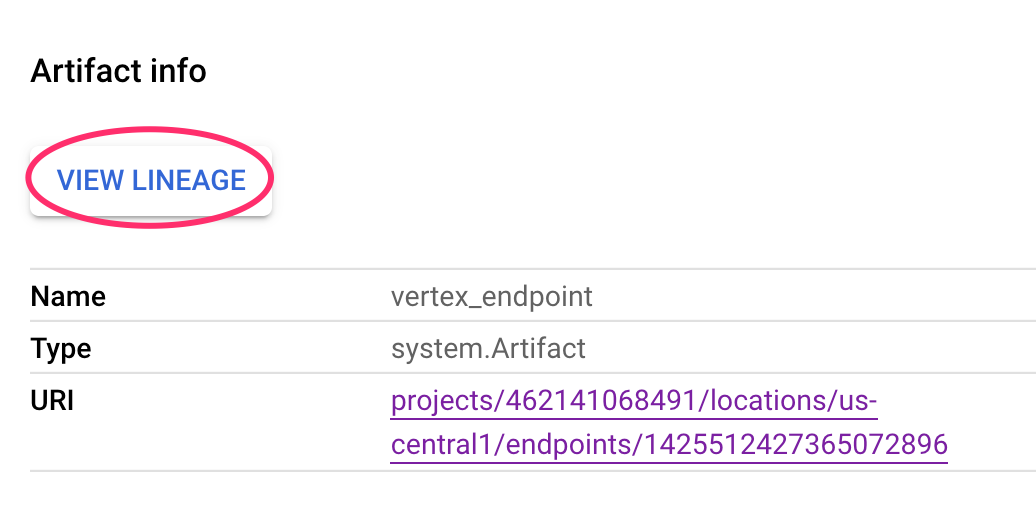
Cada artefacto tiene linaje, que describe los otros artefactos a los que está conectado. Vuelve a hacer clic en el artefacto vertex_endpoint de tu canalización y, luego, en el botón Ver linaje:
Se abrirá una pestaña nueva en la que podrás ver todos los artefactos conectados al que seleccionaste. Tu gráfico de linaje se verá de la siguiente manera:
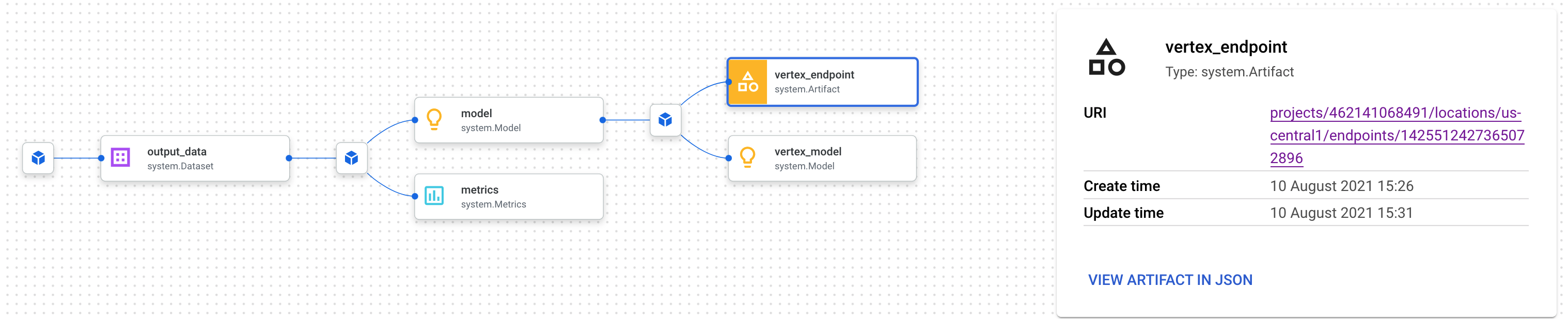
Esto nos muestra el modelo, las métricas y el conjunto de datos asociados con este extremo. ¿Por qué es útil? Es posible que tengas un modelo implementado en varios extremos o que necesites conocer el conjunto de datos específico que se usó para entrenar el modelo implementado en el extremo que estás consultando. El gráfico de linaje te ayuda a comprender cada artefacto en el contexto del resto de tu sistema de AA. También puedes acceder al linaje de forma programática, como veremos más adelante en este codelab.
7. Comparación de ejecuciones de canalizaciones
Es probable que una sola canalización se ejecute varias veces, tal vez con diferentes parámetros de entrada, datos nuevos o por parte de personas de tu equipo. Para hacer un seguimiento de las ejecuciones de canalización, sería útil tener una forma de compararlas según varias métricas. En esta sección, exploraremos dos formas de comparar ejecuciones.
Comparación de ejecuciones en la IU de Pipelines
En la consola de Cloud, navega a tu panel Canales. Esto proporciona una descripción general de cada ejecución de canalización que realizaste. Marca las dos últimas ejecuciones y, luego, haz clic en el botón Comparar en la parte superior:
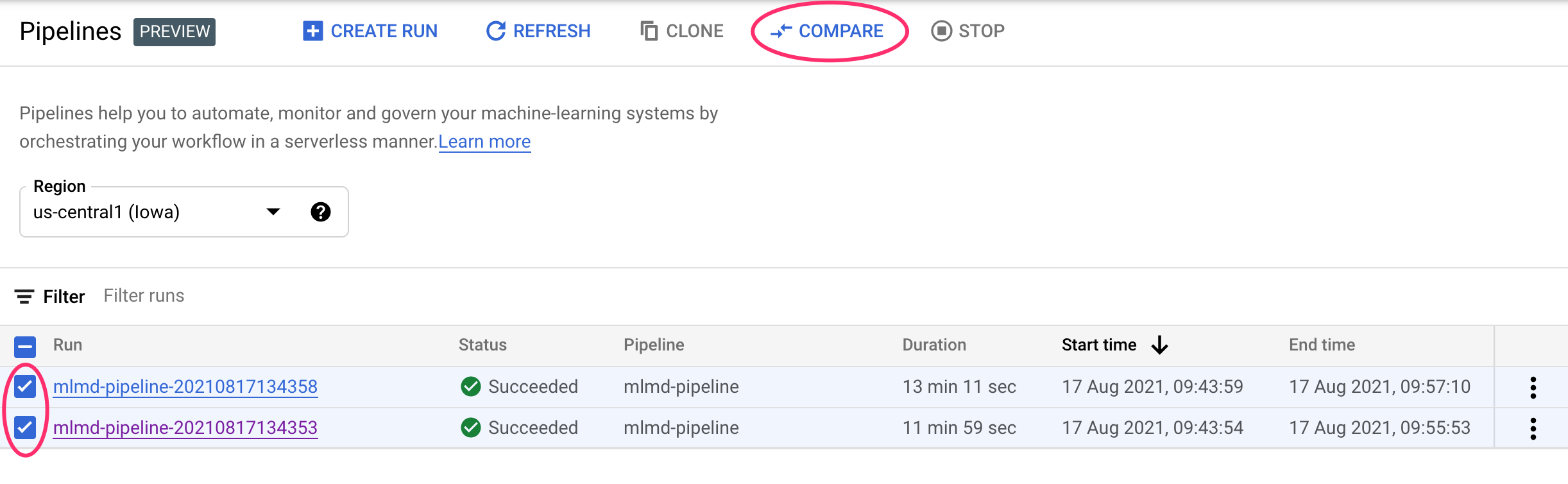
Esto nos lleva a una página en la que podemos comparar los parámetros de entrada y las métricas de cada una de las ejecuciones que seleccionamos. Para estas dos ejecuciones, observa las diferentes tablas de BigQuery, tamaños de conjuntos de datos y valores de exactitud:
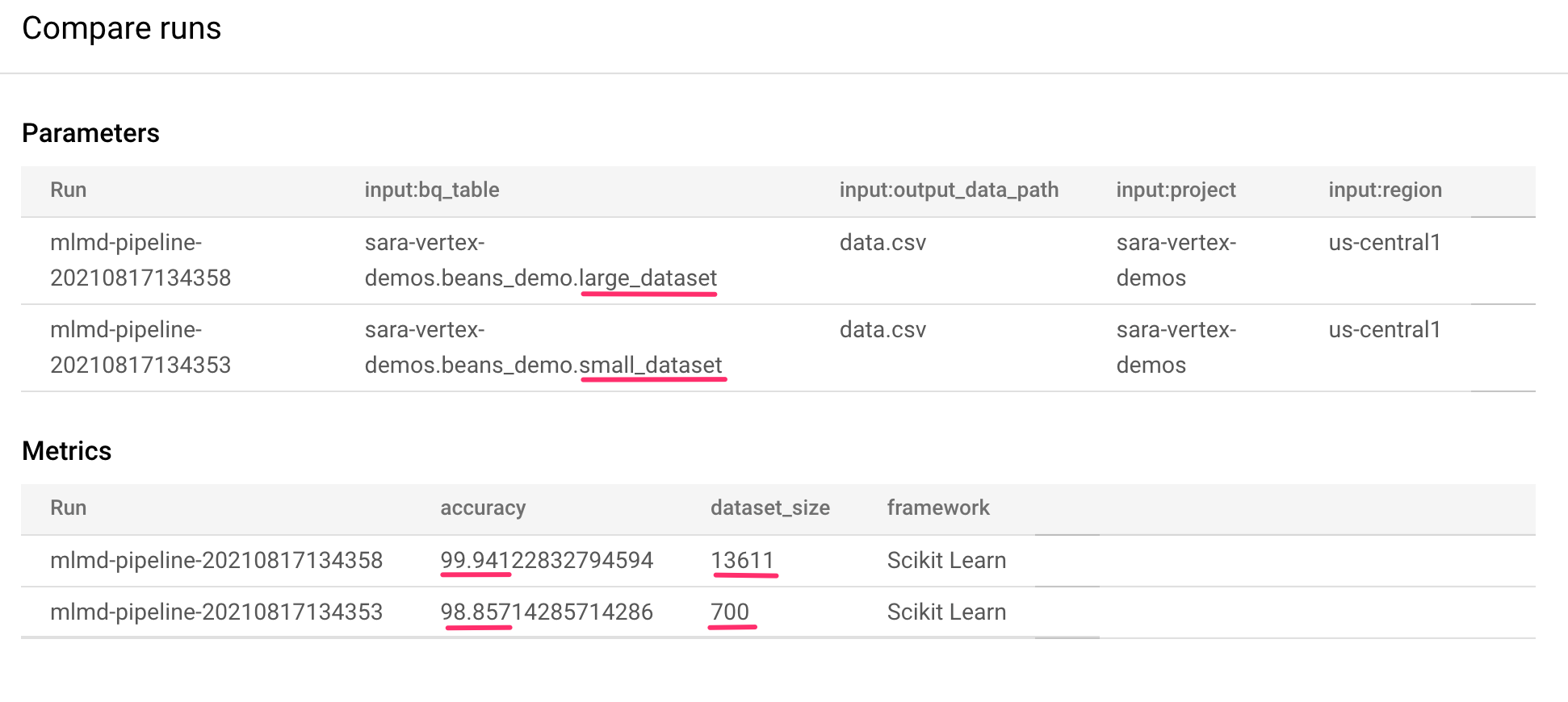
Puedes usar esta función de la IU para comparar más de dos ejecuciones, incluso ejecuciones de diferentes canalizaciones.
Compara ejecuciones con el SDK de Vertex AI
Con muchas ejecuciones de canalización, es posible que desees obtener estas métricas de comparación de forma programática para profundizar en los detalles de las métricas y crear visualizaciones.
Puedes usar el método aiplatform.get_pipeline_df() para acceder a los metadatos de la ejecución. Aquí, obtendremos los metadatos de las últimas dos ejecuciones de la misma canalización y los cargaremos en un DataFrame de Pandas. El parámetro pipeline aquí hace referencia al nombre que le asignamos a nuestra canalización en la definición de la canalización:
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
Cuando imprimas el DataFrame, verás algo como lo siguiente:

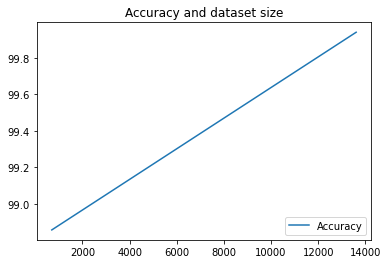
Solo ejecutamos nuestra canalización dos veces, pero puedes imaginar cuántas métricas tendrías con más ejecuciones. A continuación, crearemos una visualización personalizada con matplotlib para ver la relación entre la precisión de nuestro modelo y la cantidad de datos que se usan para el entrenamiento.
Ejecuta lo siguiente en una celda de notebook nueva:
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
Debería ver algo como esto:
8. Consulta las métricas de las canalizaciones
Además de obtener un DataFrame de todas las métricas de la canalización, te recomendamos que consultes de forma programática los artefactos creados en tu sistema de AA. Desde allí, puedes crear un panel personalizado o permitir que otras personas de tu organización obtengan detalles sobre artefactos específicos.
Cómo obtener todos los artefactos del modelo
Para consultar artefactos de esta manera, crearemos un MetadataServiceClient:
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
A continuación, realizaremos una solicitud list_artifacts a ese extremo y pasaremos un filtro que indique qué artefactos queremos en nuestra respuesta. Primero, obtengamos todos los artefactos de nuestro proyecto que sean modelos. Para ello, ejecuta lo siguiente en tu notebook:
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
La respuesta model_artifacts resultante contiene un objeto iterable para cada artefacto de modelo de tu proyecto, junto con los metadatos asociados para cada modelo.
Filtra objetos y muestra en un DataFrame
Sería útil si pudiéramos visualizar más fácilmente la consulta de artefacto resultante. A continuación, obtengamos todos los artefactos creados después del 10 de agosto de 2021 con un estado LIVE. Después de ejecutar esta solicitud, mostraremos los resultados en un DataFrame de Pandas. Primero, ejecuta la solicitud:
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
Luego, muestra los resultados en un DataFrame:
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
Verás algo como esto:

También puedes filtrar artefactos según otros criterios, además de los que probaste aquí.
Con eso, habrás terminado el lab.
🎉 ¡Felicitaciones! 🎉
Aprendiste a usar Vertex AI para hacer lo siguiente:
- Usa el SDK de Kubeflow Pipelines para compilar una canalización de AA que cree un conjunto de datos en Vertex AI y entrene e implemente un modelo personalizado de scikit-learn en ese conjunto de datos
- Escribe componentes personalizados de canalización que generen artefactos y metadatos
- Comparar las ejecuciones de Vertex Pipelines, tanto en la consola de Cloud como de manera programática
- Realiza un seguimiento del linaje de los artefactos generados por canalización
- Consulta los metadatos de ejecución de tu canalización
Para obtener más información sobre las distintas partes de Vertex, consulte la documentación.
9. Limpieza
Para que no se te cobre, te recomendamos que borres los recursos que creaste a lo largo de este lab.
Detén o borra tu instancia de Notebooks
Si quieres continuar usando el notebook que creaste en este lab, te recomendamos que lo desactives cuando no lo utilices. En la IU de Notebooks de la consola de Cloud, selecciona el notebook y, luego, haz clic en Detener. Si quieres borrar la instancia por completo, selecciona Borrar:
Borra tus extremos de Vertex AI
Para borrar el extremo que implementaste, navega a la sección Extremos de la consola de Vertex AI y haz clic en el ícono de borrar:

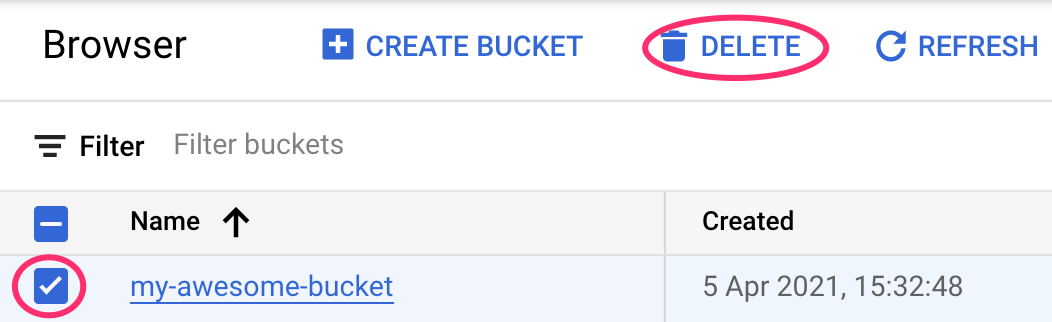
Borra el bucket de Cloud Storage
Para borrar el bucket de almacenamiento, en el menú de navegación de la consola de Cloud, navega a Almacenamiento, selecciona tu bucket y haz clic en Borrar (Delete):