1. Visão geral
Neste laboratório, você vai aprender a analisar metadados das suas execuções do Vertex Pipelines com o Vertex ML Metadata.
Conteúdo do laboratório
Você vai aprender a:
- Usar o SDK do Kubeflow Pipelines para criar um pipeline de ML que cria um conjunto de dados na Vertex AI e treina e implanta um modelo personalizado do Scikit-learn nesse conjunto de dados
- Gravar componentes de pipeline personalizados que geram artefatos e metadados
- Comparar as execuções do Vertex Pipelines no console do Cloud e de maneira programática
- Rastrear a linhagem para artefatos gerados por pipeline
- Consultar os metadados de execução do pipeline
O custo total da execução deste laboratório no Google Cloud é de aproximadamente US$ 2.
2. Introdução à Vertex AI
Este laboratório usa a mais nova oferta de produtos de IA disponível no Google Cloud. A Vertex AI integra as ofertas de ML do Google Cloud em uma experiência de desenvolvimento intuitiva. Anteriormente, modelos treinados com o AutoML e modelos personalizados eram acessíveis por serviços separados. A nova oferta combina ambos em uma única API, com outros novos produtos. Você também pode migrar projetos para a Vertex AI.
Além de oferecer treinamento de modelos e serviços de implantação, a Vertex AI também inclui uma variedade de produtos de MLOps, como o Vertex Pipelines, metadados de ML, Monitoramento de modelos, Feature Store e outros. Confira todos as ofertas de produtos da Vertex AI no diagrama abaixo.
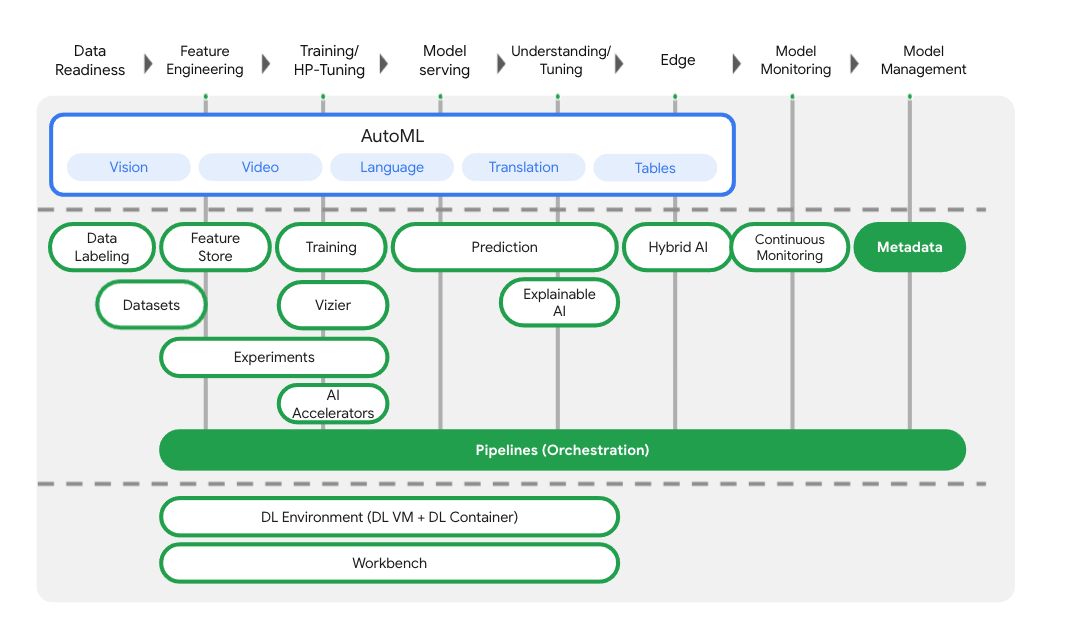
Este laboratório se concentra no Vertex Pipelines e no Vertex ML Metadata.
Se você tiver algum feedback sobre a Vertex AI, consulte a página de suporte.
Por que pipelines de ML são úteis?
Antes de começar, primeiro entenda em quais situações você usaria um pipeline. Imagine que você está criando um fluxo de trabalho de ML que inclui processamento de dados, treinamento de modelos, ajuste de hiperparâmetros, avaliação e implantação de modelos. Cada uma dessas etapas pode ter dependências diferentes, o que pode ser difícil de administrar se você tratar o fluxo inteiro como algo monolítico. Ao começar a escalonar seu processo de ML, você pode querer compartilhar seu fluxo de trabalho de ML com outras pessoas da sua equipe para que elas possam executar e colaborar com código. Sem um processo confiável e possível de ser reproduzido, isso pode ser difícil. Com pipelines, cada etapa do seu processo de ML é um contêiner próprio, o que permite que você desenvolva as etapas independentemente e rastreie a entrada e a saída de cada etapa de maneira possível de ser reproduzida. Você também pode agendar ou acionar execuções do seu pipeline com base em outros eventos do seu ambiente do Cloud, como iniciar uma execução de pipeline quando novos dados de treinamento estiverem disponíveis.
Em resumo: os pipelines ajudam você a automatizar e reproduzir seu fluxo de trabalho de ML.
3. configure o ambiente do Cloud
Para executar este codelab, você vai precisar de um projeto do Google Cloud Platform com o faturamento ativado. Para criar um projeto, siga estas instruções.
Iniciar o Cloud Shell
Neste laboratório, você vai trabalhar em uma sessão do Cloud Shell, que é um interpretador de comandos hospedado por uma máquina virtual em execução na nuvem do Google. A sessão também pode ser executada localmente no seu computador, mas se você usar o Cloud Shell, todas as pessoas vão ter acesso a uma experiência reproduzível em um ambiente consistente. Após concluir o laboratório, é uma boa ideia testar a sessão no seu computador.
Ativar o Cloud Shell
No canto superior direito do console do Cloud, clique no botão abaixo para Ativar o Cloud Shell:

Se você nunca iniciou o Cloud Shell, vai ver uma tela intermediária (abaixo da dobra) com a descrição dele. Se esse for o caso, clique em Continuar e você não a verá novamente. Esta é a aparência dessa tela única:
Leva apenas alguns instantes para provisionar e se conectar ao Cloud Shell.

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Praticamente todo o seu trabalho neste codelab pode ser feito em um navegador ou no seu Chromebook.
Depois de se conectar ao Cloud Shell, você já estará autenticado e o projeto já estará configurado com seu ID do projeto.
Execute o seguinte comando no Cloud Shell para confirmar que você está autenticado:
gcloud auth list
Resposta ao comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto:
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
Se o projeto não estiver configurado, configure-o usando este comando:
gcloud config set project <PROJECT_ID>
Resposta ao comando
Updated property [core/project].
O Cloud Shell tem algumas variáveis de ambiente, incluindo GOOGLE_CLOUD_PROJECT, que contém o nome do nosso projeto na nuvem atual. Vamos usar esses dados várias vezes neste laboratório. É possível ver essa variável ao executar:
echo $GOOGLE_CLOUD_PROJECT
Ativar APIs
Nas próximas etapas, você vai entender onde e por que esses serviços são necessários. Por enquanto, apenas execute este comando para conceder ao seu projeto acesso aos serviços do Compute Engine, Container Registry e Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Uma mensagem semelhante a esta vai aparecer:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Crie um bucket do Cloud Storage
Para executar um job de treinamento na Vertex AI, precisamos de um bucket de armazenamento para armazenar nossos recursos de modelo salvos. O bucket precisa ser regional. Estamos usando us-central aqui, mas você pode usar qualquer outra região. Basta fazer a substituição durante o laboratório. Se você já tem um bucket, pule esta etapa.
Execute os comandos a seguir no terminal do Cloud Shell para criar um bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
A próxima etapa é configurar o acesso da conta de serviço do computador a esse bucket. Isso garante que o Vertex Pipelines tenha as permissões necessárias para gravar arquivos no bucket. Execute o comando a seguir para adicionar essa permissão:
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
Criar uma instância do Vertex AI Workbench
Na seção Vertex AI do Console do Cloud, clique em "Workbench":
Em Notebooks gerenciados pelo usuário, clique em Novo notebook:

Em seguida, selecione o tipo de instância TensorFlow Enterprise 2.3 (com LTS) sem GPUs:
Use as opções padrão e clique em Criar.
Abra o notebook
Quando a instância tiver sido criada, selecione Abrir o JupyterLab:

4. Configuração do Vertex Pipelines
É preciso instalar algumas bibliotecas adicionais para usar o Vertex Pipelines:
- Kubeflow Pipelines: o SDK que vamos usar para criar o pipeline. O Vertex Pipelines suporta pipelines em execução criados com o Kubeflow Pipelines ou o TFX.
- SDK da Vertex AI: esse SDK otimiza a experiência de chamar a API Vertex AI. Vamos usá-lo para executar nosso pipeline na Vertex AI.
Criar notebook Python e instalar bibliotecas
Primeiro, no menu inicial da sua instância do notebook, selecione Python 3 para criar um notebook:

Para instalar os serviços que vamos usar neste laboratório, primeiro configure a sinalização do usuário em uma célula do notebook:
USER_FLAG = "--user"
Em seguida, execute o seguinte no seu notebook:
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
Depois de instalar esses pacotes, será necessário reiniciar o kernel:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Em seguida, verifique se você instalou a versão correta do SDK do KFP. Ele precisa ser >=1,8:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
Em seguida, confirme se a versão do SDK da Vertex AI é >= 1.6.2:
!pip list | grep aiplatform
definir o bucket e ID do projeto
Neste laboratório, você vai fazer referência ao ID do projeto do Cloud e ao bucket que você criou anteriormente. Em seguida, vamos criar variáveis para cada um.
Se não souber o ID do projeto, você pode consegui-lo executando o seguinte:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Caso contrário, defina aqui:
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
Depois, crie uma variável para armazenar o nome do seu bucket. Se você criou neste laboratório, as próximas etapas vão funcionar. Caso contrário, configure manualmente o que é mostrado a seguir:
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
Importar bibliotecas
Adicione o seguinte para importar as bibliotecas que vamos usar neste codelab:
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
definir constantes
Por último, precisamos definir algumas variáveis constantes antes de criar o pipeline. PIPELINE_ROOT é o caminho do Cloud Storage em que os artefatos criados pelo seu pipeline foram gravados. Estamos usando us-central1 como a região aqui, mas, se você usou uma região diferente ao criar o bucket, atualize a variável REGION no código abaixo:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Depois de executar o código acima, você verá o diretório raiz do seu pipeline. Esse é o local do Cloud Storage em que os artefatos do seu pipeline serão gravados. O formato é gs://YOUR-BUCKET-NAME/pipeline_root/
5. Como criar um pipeline de três etapas com componentes personalizados
O foco deste laboratório é entender os metadados das execuções de pipeline. Para isso, vamos precisar de um pipeline para executar no Vertex Pipelines, que é onde vamos começar. Aqui, vamos definir um pipeline de três etapas com os seguintes componentes personalizados:
get_dataframe: extrair dados de uma tabela do BigQuery e convertê-los em um DataFrame do Pandastrain_sklearn_model: use o DataFrame do Pandas para treinar e exportar um modelo do Scikit-Learn, além de algumas métricas.deploy_model: implante o modelo exportado do Scikit-Learn em um endpoint na Vertex AI
Nesse pipeline, vamos usar o conjunto de dados de feijão seco do UCI Machine Learning, de: KOKLU, M. e OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques."In Computers and Electronics in Agriculture, 174, 105507. DOI.
Esse é um conjunto de dados tabular que vamos usar no nosso pipeline para treinar, avaliar e implantar um modelo do Scikit-learn que classifica grãos em um dos sete tipos com base nas características deles. Vamos começar a programar!
Criar componentes baseados em função do Python
Usando o SDK do KFP, podemos criar componentes baseados em funções do Python. Vamos usar isso para os três componentes do pipeline.
Fazer o download dos dados do BigQuery e converter para CSV
Primeiro, vamos criar o componente get_dataframe:
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
Vamos analisar com mais atenção o que está acontecendo neste componente:
- O decorador
@componentcompila essa função em um componente quando o pipeline é executado. Você vai usar esse decorador sempre que criar um componente personalizado. - O parâmetro
base_imageespecifica a imagem do contêiner que esse componente vai usar. - Esse componente vai usar algumas bibliotecas Python, que especificamos com o parâmetro
packages_to_install. - O parâmetro
output_component_fileé opcional e especifica o arquivo yaml em que o componente compilado vai ser criado. Depois de executar a célula, você deve ver o arquivo gravado na sua instância do notebook. Se você quiser compartilhar esse componente com alguém, pode enviar o arquivo yaml gerado e pedir para a pessoa carregar com o seguinte:
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- Em seguida, esse componente usa a biblioteca de cliente Python do BigQuery para fazer o download dos dados do BigQuery em um DataFrame do Pandas e cria um artefato de saída desses dados como um arquivo CSV. que será transmitido como entrada para o próximo componente.
Criar um componente para treinar um modelo do scikit-learn
Neste componente, vamos usar o CSV gerado anteriormente para treinar um modelo de árvore de decisão do scikit-learn. Esse componente exporta o modelo Scikit resultante, junto com um artefato Metrics que inclui a acurácia, a estrutura e o tamanho do conjunto de dados usado para treinar o modelo:
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
Definir um componente para fazer upload e implantar o modelo na Vertex AI
Por fim, nosso último componente vai pegar o modelo treinado da etapa anterior, fazer upload dele para a Vertex AI e implantá-lo em um endpoint:
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Aqui, estamos usando o SDK da Vertex AI para fazer upload do modelo usando um contêiner pré-criado para previsão. Em seguida, ele implanta o modelo em um endpoint e retorna os URIs para os recursos de modelo e endpoint. Mais adiante neste codelab, você vai aprender mais sobre o que significa retornar esses dados como artefatos.
Definir e compilar o pipeline
Agora que definimos nossos três componentes, vamos criar a definição do pipeline. Isso descreve como os artefatos de entrada e saída fluem entre as etapas:
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
O código a seguir gera um arquivo JSON que você vai usar para executar o pipeline:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
Iniciar duas execuções de pipeline
Em seguida, vamos iniciar duas execuções do pipeline. Primeiro, vamos definir um carimbo de data/hora para usar nos IDs de job do pipeline:
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Lembre-se de que nosso pipeline usa um parâmetro quando é executado: o bq_table que queremos usar para dados de treinamento. Essa execução de pipeline vai usar uma versão menor do conjunto de dados de feijões:
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
Em seguida, crie outra execução de pipeline usando uma versão maior do mesmo conjunto de dados.
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
Por fim, inicie as execuções de pipeline para as duas execuções. É melhor fazer isso em duas células separadas do notebook para que você possa ver a saída de cada execução.
run1.submit()
Em seguida, inicie a segunda execução:
run2.submit()
Depois de executar essa célula, você vai encontrar um link para conferir cada pipeline no console da Vertex AI. Abra esse link para ver mais detalhes sobre seu pipeline:

Quando ele for concluído (esse pipeline leva cerca de 10 a 15 minutos por execução), você verá algo assim:
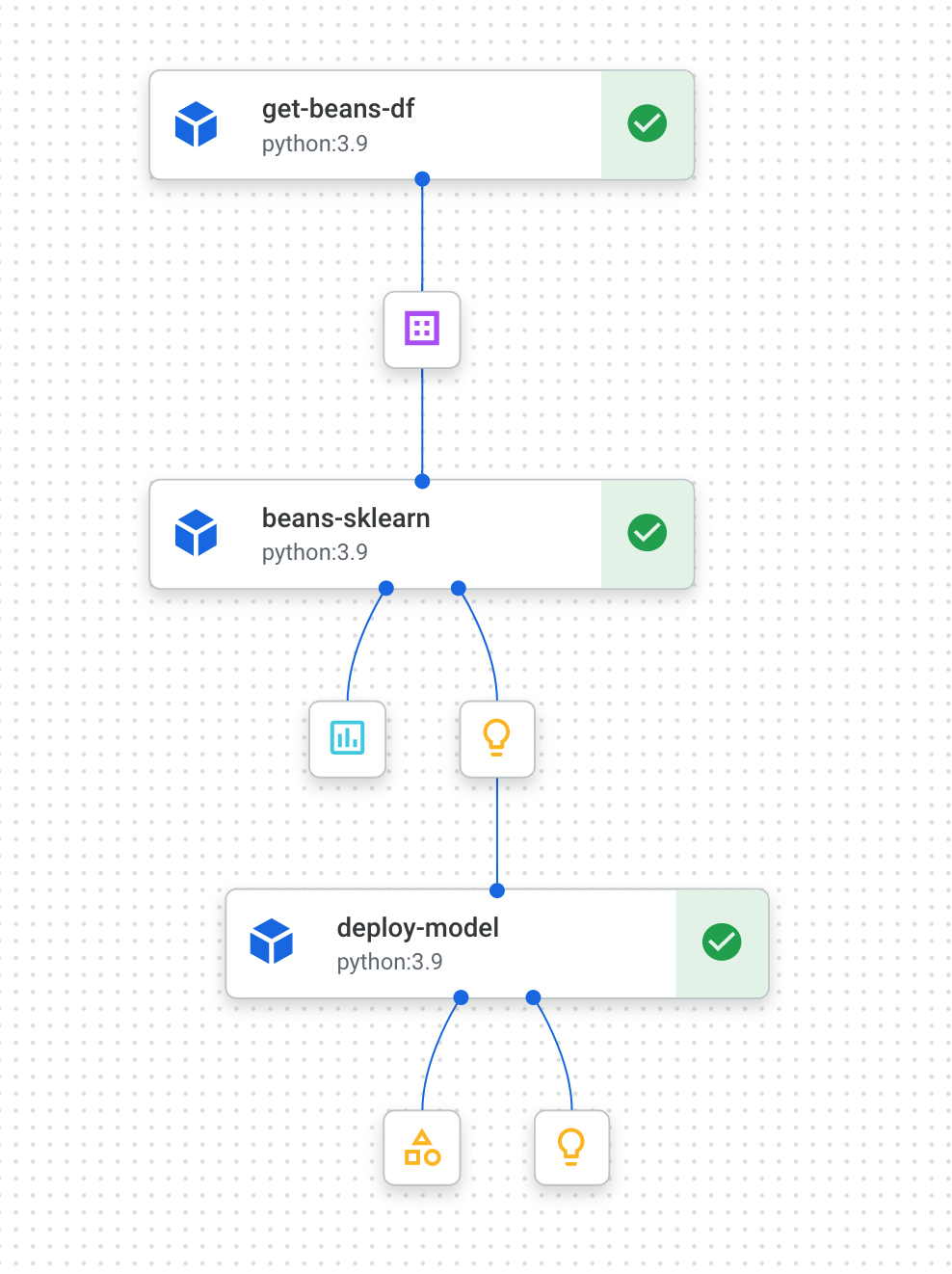
Agora que você tem duas execuções de pipeline concluídas, é hora de analisar os artefatos, as métricas e a linhagem do pipeline.
6. Noções básicas sobre artefatos e linhagem de pipeline
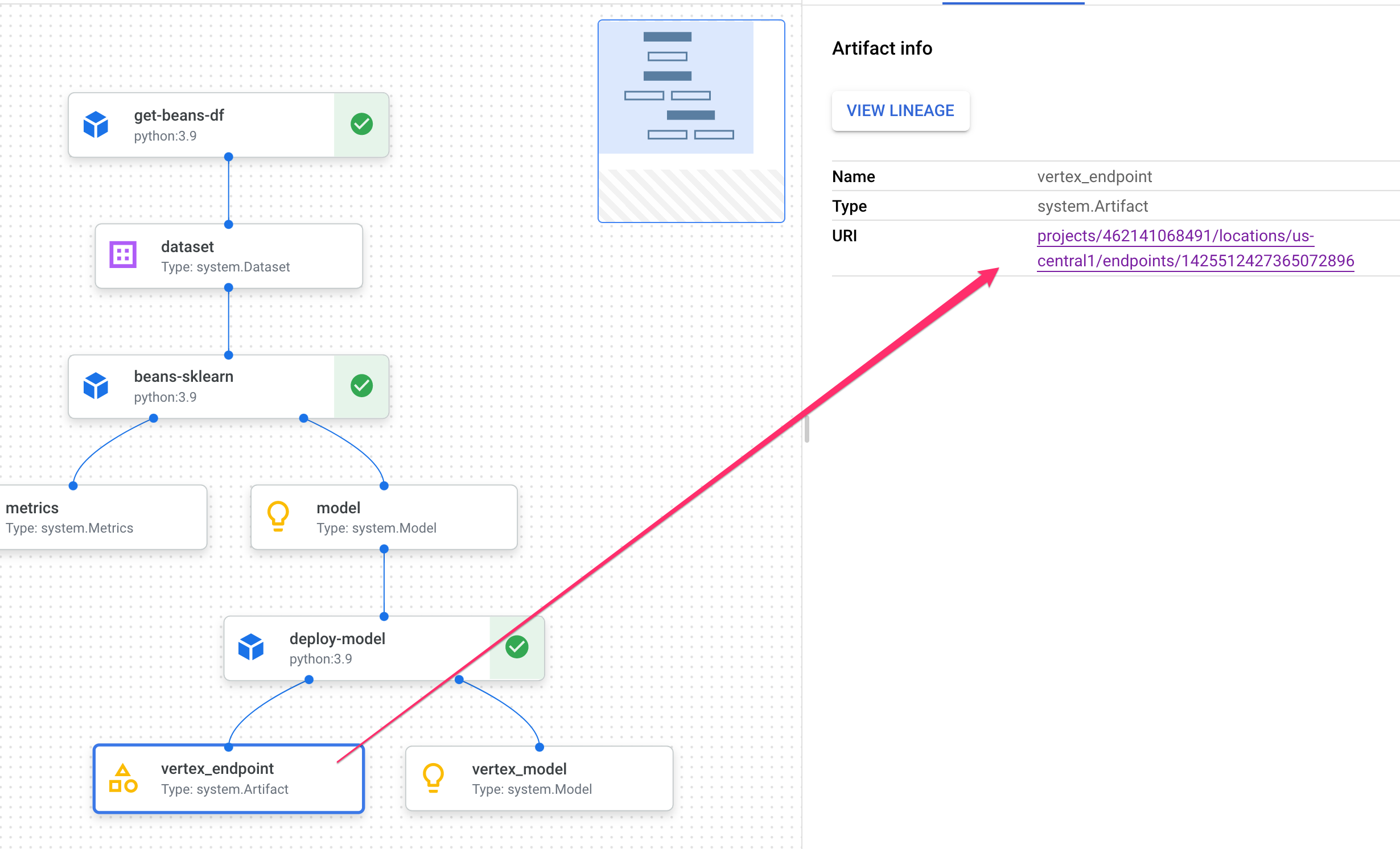
No gráfico do pipeline, você vai notar pequenas caixas após cada etapa. Esses são os artefatos, ou seja, a saída gerada de uma etapa do pipeline. Há muitos tipos de artefatos. Neste pipeline específico, temos artefatos de conjunto de dados, métricas, modelo e endpoint. Clique no controle deslizante Expandir artefatos na parte de cima da interface para ver mais detalhes sobre cada um:
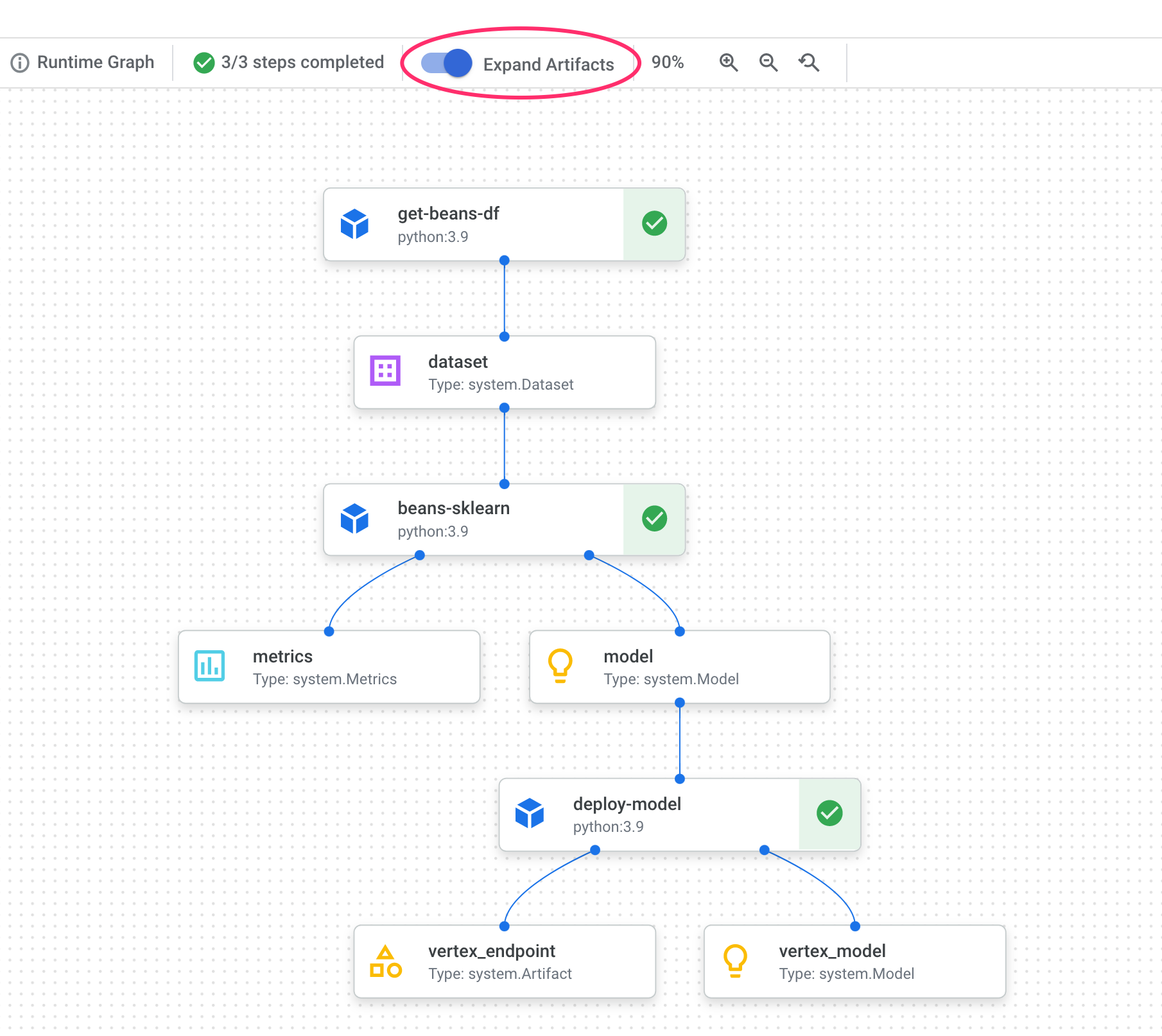
Ao clicar em um artefato, mais detalhes sobre ele são mostrados, incluindo o URI. Por exemplo, clicar no artefato vertex_endpoint mostra o URI em que é possível encontrar o endpoint implantado no console da Vertex AI:
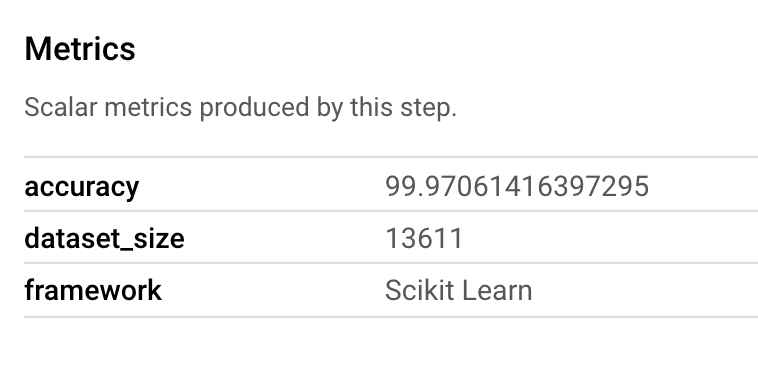
Um artefato Metrics permite transmitir métricas personalizadas associadas a uma etapa específica do pipeline. No componente sklearn_train do nosso pipeline, registramos métricas sobre a acurácia, o framework e o tamanho do conjunto de dados do nosso modelo. Clique no artefato de métricas para conferir os detalhes:
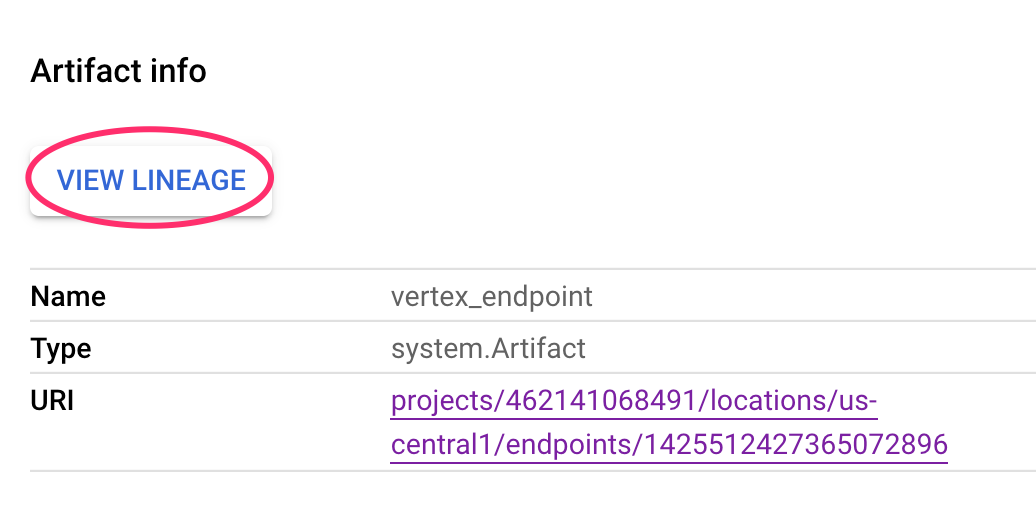
Todo artefato tem uma linhagem, que descreve os outros artefatos a que ele está conectado. Clique novamente no artefato vertex_endpoint do pipeline e no botão Ver linhagem:
Isso abre uma nova guia em que você pode ver todos os artefatos conectados ao que você selecionou. O gráfico de linhagem vai ser parecido com este:
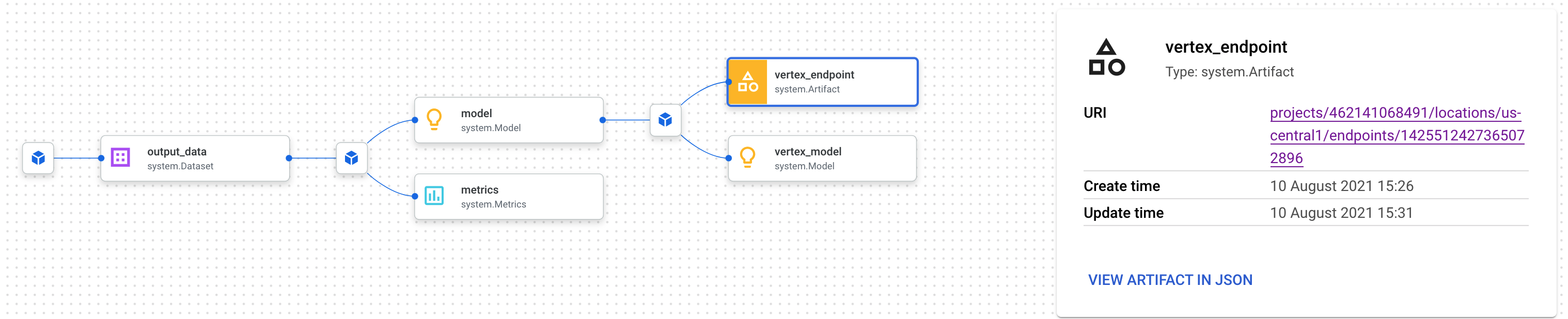
Isso mostra o modelo, as métricas e o conjunto de dados associados a esse endpoint. Por que isso é útil? Talvez você tenha um modelo implantado em vários endpoints ou precise saber o conjunto de dados específico usado para treinar o modelo implantado no endpoint que você está analisando. O gráfico de linhagem ajuda você a entender cada artefato no contexto do restante do sistema de ML. Também é possível acessar a linhagem de maneira programática, como veremos mais adiante neste codelab.
7. Comparar execuções de pipeline
É provável que um único pipeline seja executado várias vezes, talvez com parâmetros de entrada diferentes, novos dados ou por pessoas da sua equipe. Para acompanhar as execuções de pipeline, seria útil ter uma maneira de compará-las de acordo com várias métricas. Nesta seção, vamos explorar duas maneiras de comparar execuções.
Comparar execuções na interface do usuário do Pipelines
No console do Cloud, navegue até o painel de pipelines. Isso fornece uma visão geral de todas as execuções de pipeline que você fez. Verifique as duas últimas execuções e clique no botão Comparar na parte de cima:
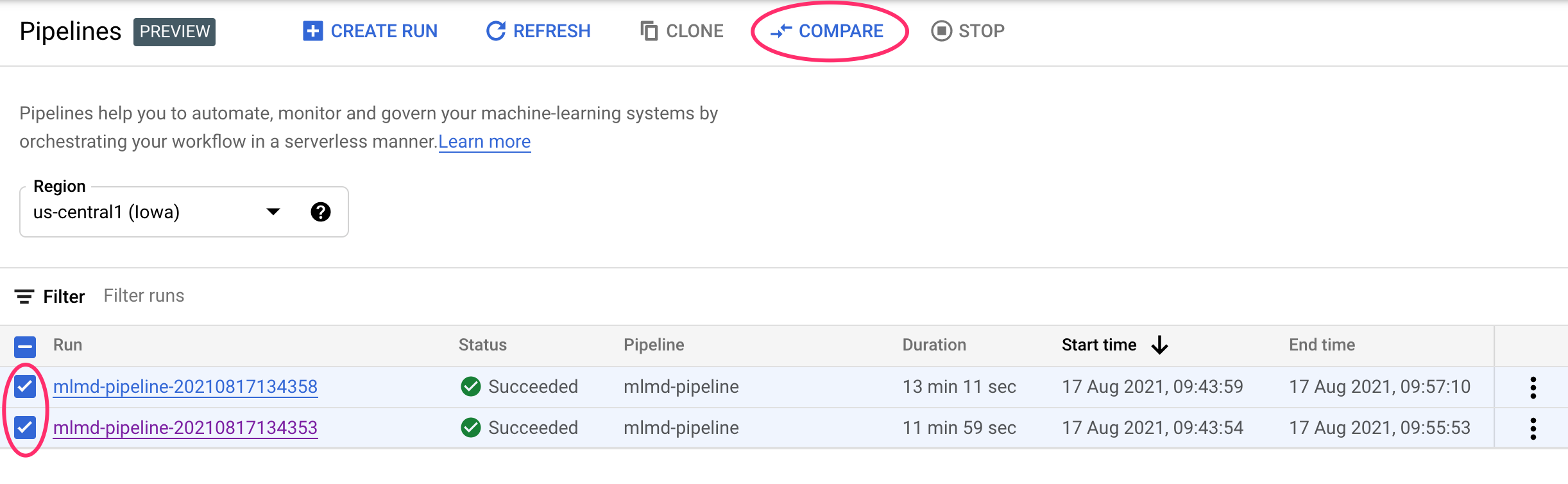
Isso nos leva a uma página em que podemos comparar parâmetros de entrada e métricas para cada uma das execuções selecionadas. Para essas duas execuções, observe as diferentes tabelas do BigQuery, tamanhos de conjuntos de dados e valores de acurácia:
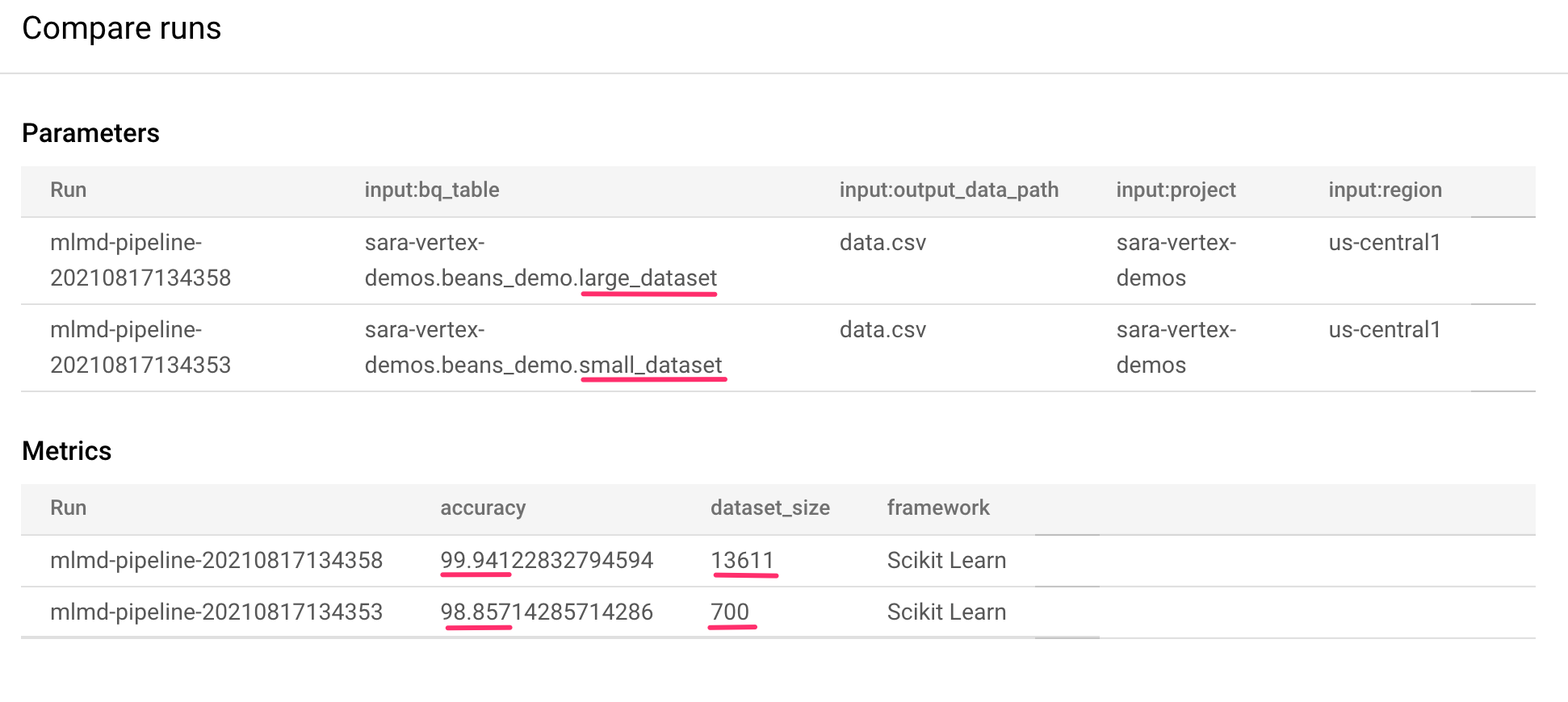
Você pode usar essa funcionalidade da interface para comparar mais de duas execuções, até mesmo de pipelines diferentes.
Comparar execuções com o SDK da Vertex AI
Com muitas execuções de pipeline, talvez você queira uma maneira de receber essas métricas de comparação de forma programática para analisar melhor os detalhes das métricas e criar visualizações.
É possível usar o método aiplatform.get_pipeline_df() para acessar os metadados da execução. Aqui, você vai receber metadados das duas últimas execuções do mesmo pipeline e carregá-los em um DataFrame do Pandas. O parâmetro pipeline aqui se refere ao nome que demos ao pipeline na definição dele:
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
Ao imprimir o DataFrame, você verá algo assim:

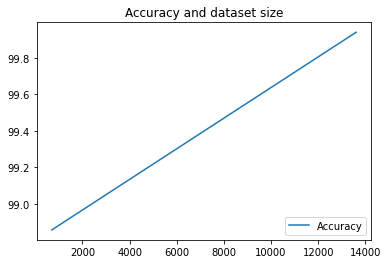
Executamos nosso pipeline apenas duas vezes aqui, mas você pode imaginar quantas métricas teria com mais execuções. Em seguida, vamos criar uma visualização personalizada com matplotlib para conferir a relação entre a acurácia do nosso modelo e a quantidade de dados usados para treinamento.
Execute o seguinte em uma nova célula do notebook:
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
Você verá algo como:
8. Como consultar métricas de pipeline
Além de receber um DataFrame com todas as métricas do pipeline, talvez você queira consultar programaticamente os artefatos criados no seu sistema de ML. Lá, você pode criar um painel personalizado ou permitir que outras pessoas na sua organização recebam detalhes sobre artefatos específicos.
Como receber todos os artefatos de modelo
Para consultar artefatos dessa forma, vamos criar um MetadataServiceClient:
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
Em seguida, vamos fazer uma solicitação list_artifacts para esse endpoint e transmitir um filtro indicando quais artefatos queremos na nossa resposta. Primeiro, vamos pegar todos os artefatos do nosso projeto que são modelos. Para isso, execute o seguinte no notebook:
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
A resposta model_artifacts resultante contém um objeto iterável para cada artefato de modelo no seu projeto, além de metadados associados para cada modelo.
Filtrar objetos e mostrar em um DataFrame
Seria útil se pudéssemos visualizar mais facilmente a consulta de artefato resultante. Em seguida, vamos receber todos os artefatos criados após 10 de agosto de 2021 com um estado LIVE. Depois de executar essa solicitação, vamos mostrar os resultados em um DataFrame do Pandas. Primeiro, execute a solicitação:
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
Em seguida, mostre os resultados em um DataFrame:
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
Você vai encontrar algo como:

Você também pode filtrar artefatos com base em outros critérios além do que você tentou aqui.
Com isso, você concluiu o laboratório.
Parabéns! 🎉
Você aprendeu a usar a Vertex AI para:
- Usar o SDK do Kubeflow Pipelines para criar um pipeline de ML que cria um conjunto de dados na Vertex AI e treina e implanta um modelo personalizado do Scikit-learn nesse conjunto de dados
- Gravar componentes de pipeline personalizados que geram artefatos e metadados
- Comparar as execuções do Vertex Pipelines no console do Cloud e de maneira programática
- Rastrear a linhagem para artefatos gerados por pipeline
- Consultar os metadados de execução do pipeline
Para saber mais sobre as diferentes partes da Vertex, consulte a documentação.
9. Limpeza
Para evitar cobranças, recomendamos que você exclua os recursos criados ao longo deste laboratório.
Interromper ou excluir a instância do Notebooks
Se você quiser continuar usando o notebook que criou neste laboratório, é recomendado que você o desligue quando não estiver usando. A partir da interface de Notebooks no seu Console do Cloud, selecione o notebook e depois clique em Parar. Se quiser excluir a instância completamente, selecione Excluir:
Excluir seus endpoints da Vertex AI
Para excluir o endpoint implantado, acesse a seção Endpoints do console da Vertex AI e clique no ícone de exclusão:

Exclua o bucket do Cloud Storage
Para excluir o bucket do Storage, use o menu de navegação do console do Cloud, acesse o Storage, selecione o bucket e clique em "Excluir":