1. Übersicht
In diesem Lab erfahren Sie, wie Sie Metadaten aus Ihren Vertex Pipelines-Ausführungen mit Vertex ML Metadata analysieren.
Lerninhalte
Die folgenden Themen werden behandelt:
- Verwenden Sie das Kubeflow Pipelines SDK, um eine ML-Pipeline zu erstellen, die ein Dataset in Vertex AI erstellt und ein benutzerdefiniertes Scikit-learn-Modell für dieses Dataset trainiert und bereitstellt.
- Schreiben Sie benutzerdefinierte Pipelinekomponenten, die Artefakte und Metadaten generieren
- Vertex Pipelines-Ausführungen sowohl in der Cloud Console als auch programmatisch vergleichen
- Herkunft von Pipeline-generierten Artefakten verfolgen
- Fragen Sie die Metadaten der Pipelineausführung ab
Die Gesamtkosten für die Ausführung dieses Labs in Google Cloud betragen etwa 2$.
2. Einführung in Vertex AI
In diesem Lab wird das neueste KI-Produkt von Google Cloud verwendet. Vertex AI vereint die ML-Angebote von Google Cloud in einer nahtlosen Entwicklungsumgebung. Bisher musste auf mit AutoML trainierte und benutzerdefinierte Modelle über verschiedene Dienste zugegriffen werden. Das neue Angebot kombiniert diese und weitere, neue Produkte zu einer einzigen API. Sie können auch vorhandene Projekte zu Vertex AI migrieren.
Neben Diensten für Modelltraining und ‑bereitstellung umfasst Vertex AI auch eine Vielzahl von MLOps-Produkten, darunter Vertex Pipelines, ML Metadata, Model Monitoring und Feature Store. Alle Vertex AI-Produkte finden Sie im folgenden Diagramm.
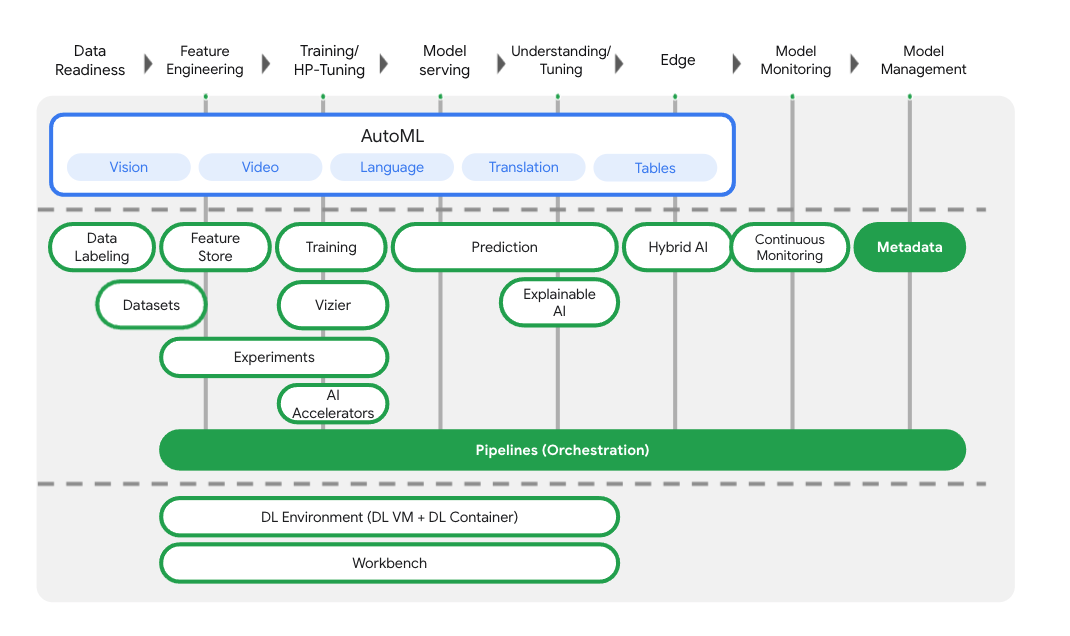
In diesem Lab geht es um Vertex Pipelines und Vertex ML Metadata.
Wenn Sie Feedback zu Vertex AI haben, lesen Sie die Supportseite.
Warum sind ML-Pipelines nützlich?
Sehen wir uns erst einmal an, warum der Einsatz von Pipelines sinnvoll ist. Stellen Sie sich vor, Sie entwickeln einen ML-Workflow, der Datenverarbeitung, Modelltraining, Hyperparameter-Abstimmung, Bewertung und Modellbereitstellung umfasst. Jeder dieser Schritte kann andere Abhängigkeiten haben, was die Bearbeitung erschweren kann, wenn Sie den gesamten Workflow als eine Einheit behandeln. Beim Skalieren des ML-Prozesses kann es sinnvoll sein, Ihren ML-Workflow mit anderen Teammitgliedern zu teilen, damit diese ihn ebenfalls ausführen und Code beitragen können. Ohne zuverlässigen, reproduzierbaren Prozess kann dies schwierig sein. Pipelines sorgen dafür, dass es für jeden Schritt des ML-Prozesses einen eigenen Container gibt. So können Sie Schritte unabhängig voneinander entwickeln und die Ein- und Ausgaben jedes Schrittes verfolgen und reproduzieren. Außerdem können Sie Ausführungen der Pipeline basierend auf anderen Ereignissen in Ihrer Cloud-Umgebung planen oder auslösen, zum Beispiel wenn neue Trainingsdaten verfügbar sind.
Kurz gesagt: Pipelines helfen Ihnen, Ihren ML-Workflow zu automatisieren und zu reproduzieren.
3. Cloud-Umgebung einrichten
Für dieses Codelab benötigen Sie ein Google Cloud Platform-Projekt mit aktivierter Abrechnung. Folgen Sie dieser Anleitung, um ein Projekt zu erstellen.
Cloud Shell starten
In diesem Lab arbeiten Sie in einer Cloud Shell-Sitzung. Das ist ein Befehlsinterpreter, der auf einer virtuellen Maschine in der Google-Cloud gehostet wird. Sie könnten diesen Abschnitt genauso gut lokal auf Ihrem eigenen Computer ausführen, aber mit Cloud Shell hat jeder Zugriff auf eine reproduzierbare Umgebung. Nach dem Lab können Sie diesen Abschnitt gern auf Ihrem eigenen Computer wiederholen.
Cloud Shell aktivieren
Klicken Sie oben rechts in der Cloud Console auf die Schaltfläche unten, um Cloud Shell zu aktivieren:

Wenn Sie die Cloud Shell zuvor noch nicht gestartet haben, wird ein Fenster mit einer Beschreibung eingeblendet. Klicken Sie in diesem Fall einfach auf Weiter. So sieht dieses Fenster aus:
Das Herstellen der Verbindung mit der Cloud Shell sollte nur wenige Augenblicke dauern.

Auf dieser virtuellen Maschine sind alle Entwicklungstools installiert, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Die meisten, wenn nicht sogar alle Aufgaben in diesem Codelab können mit einem Browser oder Ihrem Chromebook erledigt werden.
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist.
Führen Sie in der Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Sie authentifiziert sind:
gcloud auth list
Befehlsausgabe
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt:
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Ist dies nicht der Fall, können Sie die Einstellung mit diesem Befehl vornehmen:
gcloud config set project <PROJECT_ID>
Befehlsausgabe
Updated property [core/project].
Cloud Shell hat einige Umgebungsvariablen, darunter GOOGLE_CLOUD_PROJECT, die den Namen unseres aktuellen Cloud-Projekts enthält. Wir werden diese Variable an verschiedenen Stellen in diesem Lab verwenden. Sie können sie mit folgendem Befehl aufrufen:
echo $GOOGLE_CLOUD_PROJECT
APIs aktivieren
In späteren Schritten sehen Sie, wo diese Dienste benötigt werden und warum. Führen Sie jetzt diesen Befehl aus, um Ihrem Projekt Zugriff auf die Dienste Compute Engine, Container Registry und Vertex AI zu gewähren:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Wenn die Aktivierung erfolgreich war, erhalten Sie eine Meldung, die ungefähr so aussieht:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Cloud Storage-Bucket erstellen
Wenn wir einen Trainingsjob in Vertex AI ausführen möchten, benötigen wir einen Speicher-Bucket zum Speichern unserer gespeicherten Modell-Assets. Der Bucket muss regional sein. Wir verwenden hier us-central, Sie können aber auch eine andere Region verwenden (ersetzen Sie sie einfach in diesem Lab). Wenn Sie bereits einen Bucket haben, können Sie diesen Schritt überspringen.
Führen Sie die folgenden Befehle in Ihrem Cloud Shell-Terminal aus, um einen Bucket zu erstellen:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Als Nächstes gewähren wir unserem Compute-Dienstkonto Zugriff auf diesen Bucket. So wird sichergestellt, dass Vertex Pipelines die erforderlichen Berechtigungen zum Schreiben von Dateien in diesen Bucket hat. Führen Sie den folgenden Befehl aus, um diese Berechtigung hinzuzufügen:
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
Vertex AI Workbench-Instanz erstellen
Klicken Sie in der Cloud Console im Bereich „Vertex AI“ auf „Workbench“:
Klicken Sie dort unter Nutzerverwaltete Notebooks auf Neues Notebook:

Wählen Sie dann den Instanztyp TensorFlow Enterprise 2.3 (mit LTS) ohne GPUs aus:
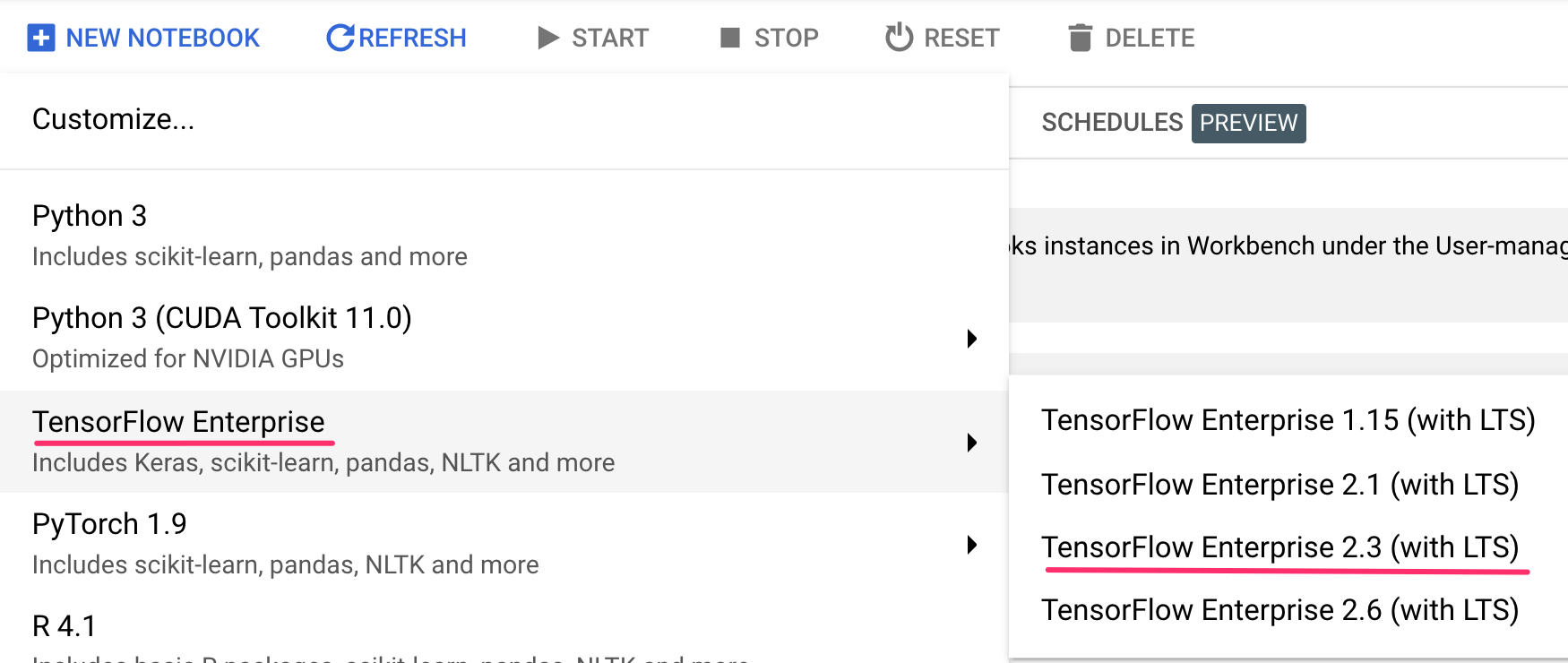
Übernehmen Sie die Standardoptionen und klicken Sie auf Erstellen.
Notebook öffnen
Nachdem die Instanz erstellt wurde, klicken Sie auf JupyterLab öffnen:

4. Vertex Pipelines einrichten
Damit wir Vertex Pipelines nutzen können, müssen wir noch einige zusätzliche Bibliotheken installieren:
- Kubeflow Pipelines: Dieses SDK wird zum Erstellen der Pipeline verwendet. Vertex Pipelines unterstützt das Ausführen von mit Kubeflow Pipelines oder TFX erstellten Pipelines.
- Vertex AI SDK: Dieses SDK optimiert den Aufruf der Vertex AI API. Wir verwenden sie, um unsere Pipeline in Vertex AI auszuführen.
Python-Notebook erstellen und Bibliotheken installieren
Erstellen Sie zuerst im Launcher-Menü in Ihrer Notebook-Instanz ein Notebook, indem Sie Python 3 auswählen:

Legen Sie zuerst das Flag „user“ in einer Notebook-Zelle fest, um beide für dieses Lab benötigten Dienste zu installieren:
USER_FLAG = "--user"
Führen Sie dann folgenden Code im Notebook aus:
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
Nach dem Installieren dieser Pakete müssen Sie den Kernel neu starten:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Prüfen Sie als Nächstes, ob Sie die KFP SDK-Version richtig installiert haben. Sie sollte mindestens 1,8 betragen:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
Prüfen Sie dann, ob Ihre Vertex AI SDK-Version >= 1.6.2 ist:
!pip list | grep aiplatform
Projekt-ID und Bucket festlegen
Während des Labs benötigen Sie immer wieder Ihre Cloud-Projekt-ID und den zuvor erstellten Bucket. Als Nächstes erstellen wir dafür Variablen.
Falls Sie die Projekt-ID nicht kennen, können Sie sie abrufen, indem Sie diesen Befehl ausführen:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Andernfalls legen Sie sie hier fest:
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
Erstellen Sie dann eine Variable zum Speichern des Bucket-Namens. Wenn Sie sie in diesem Lab erstellt haben, funktioniert Folgendes. Andernfalls müssen Sie dies manuell festlegen:
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
Bibliotheken importieren
Fügen Sie Folgendes hinzu, um die Bibliotheken für dieses Codelab zu importieren:
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
Konstanten definieren
Jetzt definieren wir noch einige konstante Variablen. Anschließend können wir mit dem Erstellen der Pipeline beginnen. PIPELINE_ROOT ist der Cloud Storage-Pfad, in den die durch die Pipeline erstellten Artefakte geschrieben werden. Wir verwenden hier us-central1 als Region, aber falls Sie beim Erstellen des Buckets eine andere Region ausgewählt haben, passen Sie die Variable REGION im folgenden Code an:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Nach dem Ausführen des obigen Codes sollte das Stammverzeichnis für Ihre Pipeline ausgegeben werden. Dies ist der Cloud Storage-Speicherort, in den die Artefakte aus Ihrer Pipeline geschrieben werden. Sie hat das Format gs://YOUR-BUCKET-NAME/pipeline_root/.
5. 3-stufige Pipeline mit benutzerdefinierten Komponenten erstellen
In diesem Lab geht es darum, Metadaten aus Pipeline-Ausführungen zu verstehen. Dazu benötigen wir eine Pipeline, die in Vertex Pipelines ausgeführt wird. Hier definieren wir eine Pipeline mit drei Schritten und den folgenden benutzerdefinierten Komponenten:
get_dataframe: Daten aus einer BigQuery-Tabelle abrufen und in einen Pandas DataFrame konvertierentrain_sklearn_model: Pandas-DataFrame zum Trainieren und Exportieren eines Scikit-Learn-Modells zusammen mit einigen Messwerten verwendendeploy_model: Exportiertes Scikit-Learn-Modell in einem Endpunkt in Vertex AI bereitstellen
In dieser Pipeline verwenden wir das UCI Machine Learning-Dataset Dry Beans aus: KOKLU, M. und OZKAN, I.A., (2020), „Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques“ in Computers and Electronics in Agriculture, 174, 105507. DOI
Dies ist ein tabellarisches Dataset, das wir in unserer Pipeline dazu verwenden, ein Scikit-learn-Modell zu trainieren, zu bewerten und bereitzustellen. Dieses Modell ordnet Bohnen anhand ihrer Merkmale einer von sieben Arten zu. Los gehts!
Auf Python-Funktionen basierende Komponenten erstellen
Mit dem KFP SDK können wir auf Python-Funktionen basierende Komponenten erstellen. Wir verwenden sie für die drei Komponenten in dieser Pipeline.
BigQuery-Daten herunterladen und in CSV konvertieren
Zuerst erstellen wir die get_dataframe-Komponente:
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
Sehen wir uns genauer an, was in dieser Komponente passiert:
- Der Decorator
@componentkompiliert diese Funktion in eine Komponente, wenn die Pipeline ausgeführt wird. Dies verwenden Sie immer, wenn Sie eine benutzerdefinierte Komponente schreiben. - Mit dem Parameter
base_imagewird das Container-Image angegeben, das diese Komponente verwendet. - Für diese Komponente werden einige Python-Bibliotheken verwendet, die wir über den Parameter
packages_to_installangeben. - Der Parameter
output_component_fileist optional. Er gibt die YAML-Datei an, in die die kompilierte Komponente geschrieben werden soll. Nachdem die Zelle ausgeführt wurde, sollte diese Datei in Ihre Notebook-Instanz geschrieben worden sein. Wenn Sie die Komponente für eine andere Person freigeben möchten, können Sie ihr die erstellte YAML-Datei senden und sie bitten, diese mit folgendem Befehl zu laden:
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- Als Nächstes verwendet diese Komponente die BigQuery-Python-Clientbibliothek, um unsere Daten aus BigQuery in einen Pandas-DataFrame herunterzuladen. Anschließend wird ein Ausgabeartefakt dieser Daten als CSV-Datei erstellt. Dieser Wert wird als Eingabe für die nächste Komponente übergeben.
Komponente zum Trainieren eines Scikit-learn-Modells erstellen
In dieser Komponente verwenden wir die zuvor generierte CSV-Datei, um ein Entscheidungsbaummodell von Scikit-learn zu trainieren. Diese Komponente exportiert das resultierende Scikit-Modell zusammen mit einem Metrics-Artefakt, das die Genauigkeit, das Framework und die Größe des Datasets enthält, das zum Trainieren des Modells verwendet wurde:
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
Komponente zum Hochladen und Bereitstellen des Modells in Vertex AI definieren
In der letzten Komponente wird das trainierte Modell aus dem vorherigen Schritt verwendet, in Vertex AI hochgeladen und auf einem Endpunkt bereitgestellt:
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Hier verwenden wir das Vertex AI SDK, um das Modell mit einem vorkonfigurierten Container für Vorhersagen hochzuladen. Anschließend wird das Modell auf einem Endpunkt bereitgestellt und die URIs für die Modell- und Endpunktressourcen werden zurückgegeben. Später in diesem Codelab erfahren Sie mehr darüber, was es bedeutet, diese Daten als Artefakte zurückzugeben.
Pipeline definieren und kompilieren
Nachdem wir unsere drei Komponenten definiert haben, erstellen wir als Nächstes die Pipelinedefinition. So werden Eingabe- und Ausgabe-Artefakte zwischen Schritten übertragen:
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
Mit dem folgenden Befehl erstellen Sie eine JSON-Datei, die Sie zum Ausführen der Pipeline verwenden:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
Zwei Pipelineausführungen starten
Als Nächstes starten wir zwei Ausführungen unserer Pipeline. Definieren wir zuerst einen Zeitstempel, der für unsere Pipelinejob-IDs verwendet werden soll:
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Unsere Pipeline benötigt einen Parameter, wenn wir sie ausführen: das bq_table, das wir für Trainingsdaten verwenden möchten. Bei dieser Pipelineausführung wird eine kleinere Version des Datasets „beans“ verwendet:
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
Als Nächstes erstellen Sie einen weiteren Pipeline-Lauf mit einer größeren Version desselben Datasets.
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
Starten Sie schließlich die Pipelineausführungen für beide Läufe. Am besten führen Sie die beiden Schritte in zwei separaten Notebook-Zellen aus, damit Sie die Ausgabe für jeden Lauf sehen können.
run1.submit()
Starten Sie dann den zweiten Lauf:
run2.submit()
Nachdem Sie diese Zelle ausgeführt haben, wird ein Link angezeigt, über den Sie jede Pipeline in der Vertex AI Console aufrufen können. Öffnen Sie den Link, um weitere Details zu Ihrer Pipeline zu sehen:

Wenn die Pipeline abgeschlossen ist (die Ausführung dauert etwa 10 bis 15 Minuten), sehen Sie in etwa Folgendes:
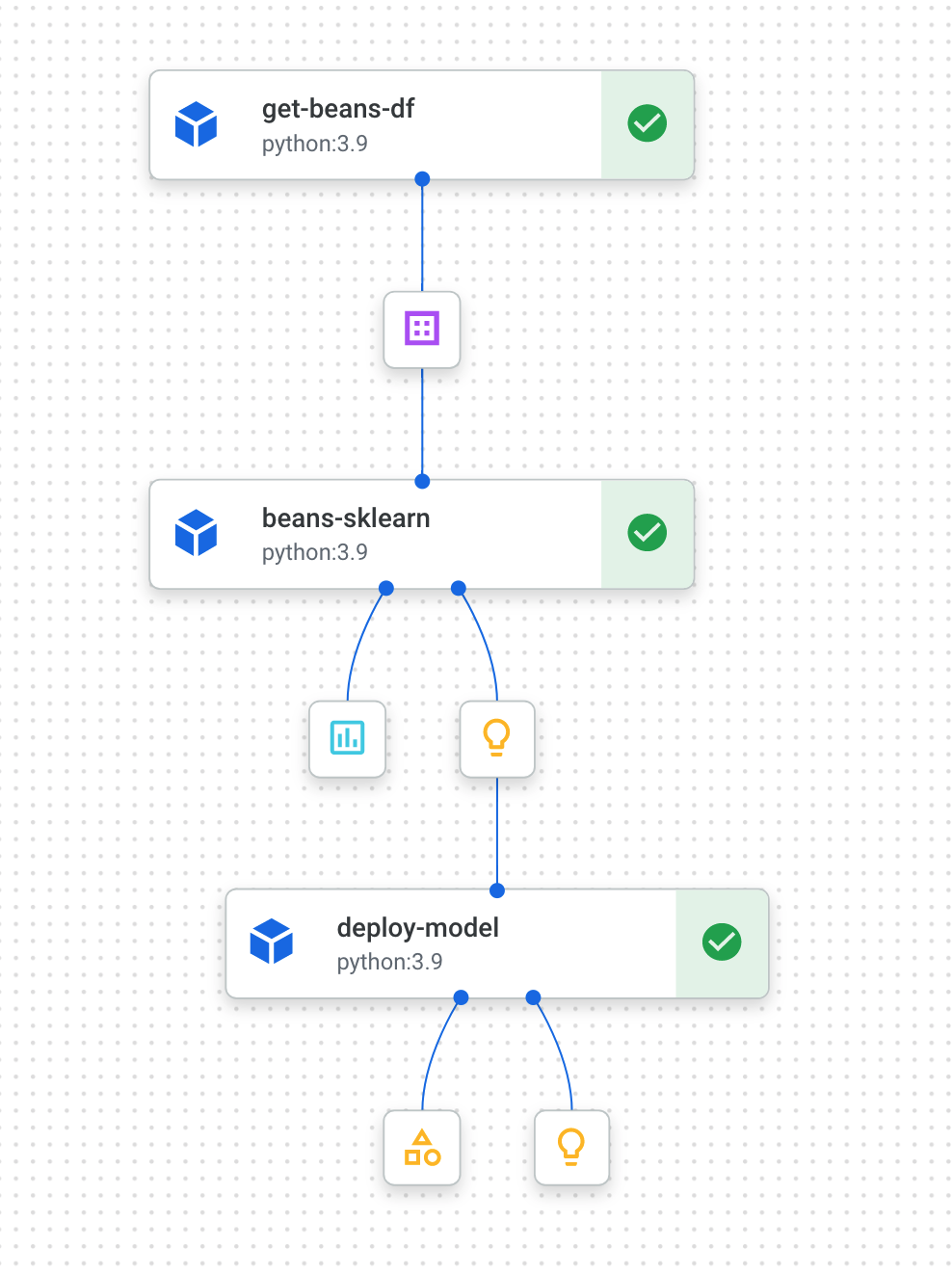
Nachdem Sie nun zwei abgeschlossene Pipelineausführungen haben, können Sie sich die Pipelineartefakte, ‑messwerte und ‑abstammung genauer ansehen.
6. Pipeline-Artefakte und ‑Herkunft verstehen
Im Pipeline-Diagramm sehen Sie nach jedem Schritt kleine Felder. Das sind Artefakte oder Ausgaben, die von einem Pipelineschritt generiert werden. Es gibt viele Arten von Artefakten. In dieser Pipeline haben wir Dataset-, Messwert-, Modell- und Endpunktartefakte. Klicken Sie oben in der Benutzeroberfläche auf den Schieberegler Artefakte maximieren, um weitere Details zu den einzelnen Artefakten aufzurufen:
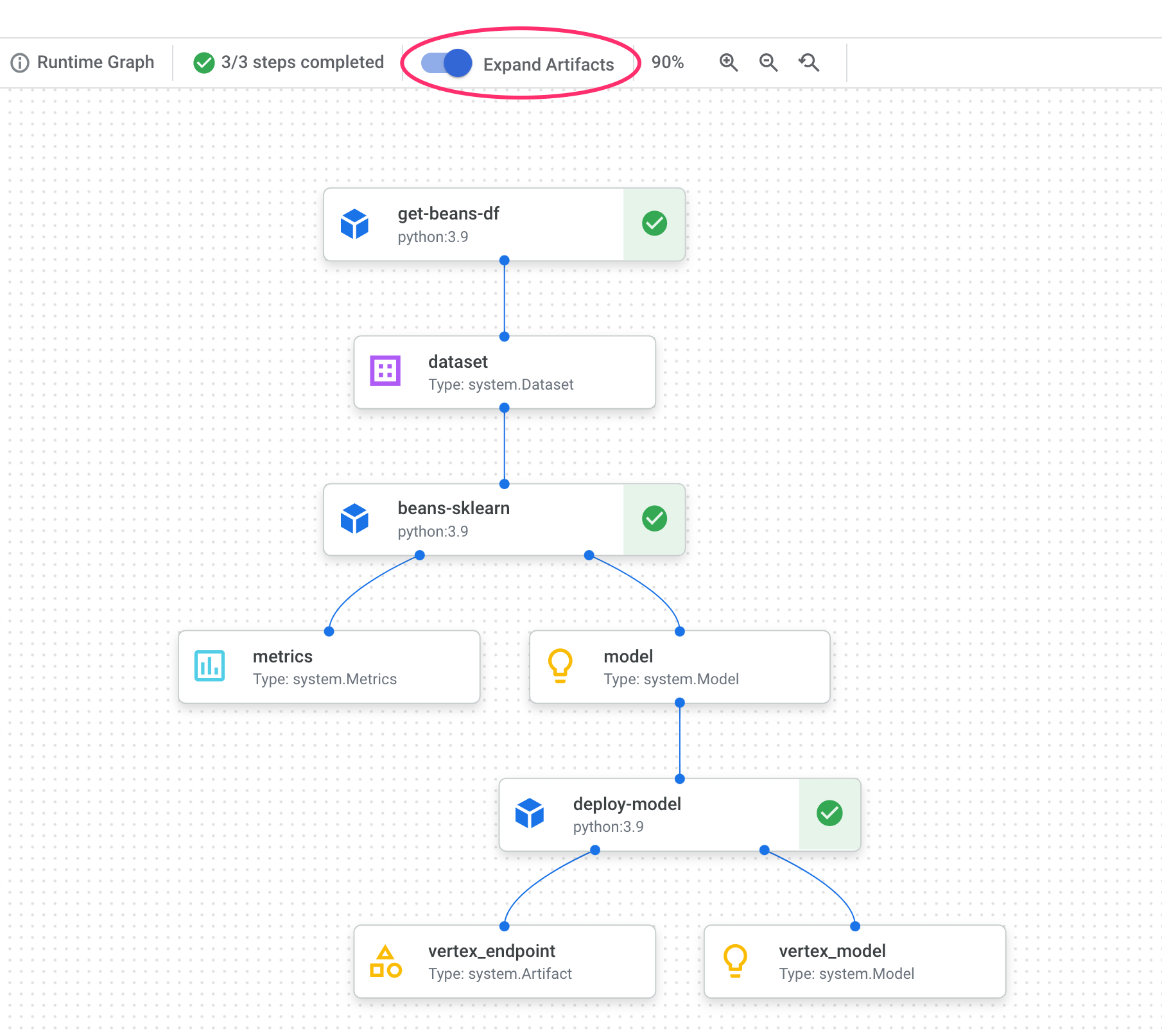
Wenn Sie auf ein Artefakt klicken, werden weitere Details dazu angezeigt, einschließlich des URI. Wenn Sie beispielsweise auf das Artefakt vertex_endpoint klicken, wird der URI angezeigt, unter dem Sie den bereitgestellten Endpunkt in der Vertex AI Console finden:
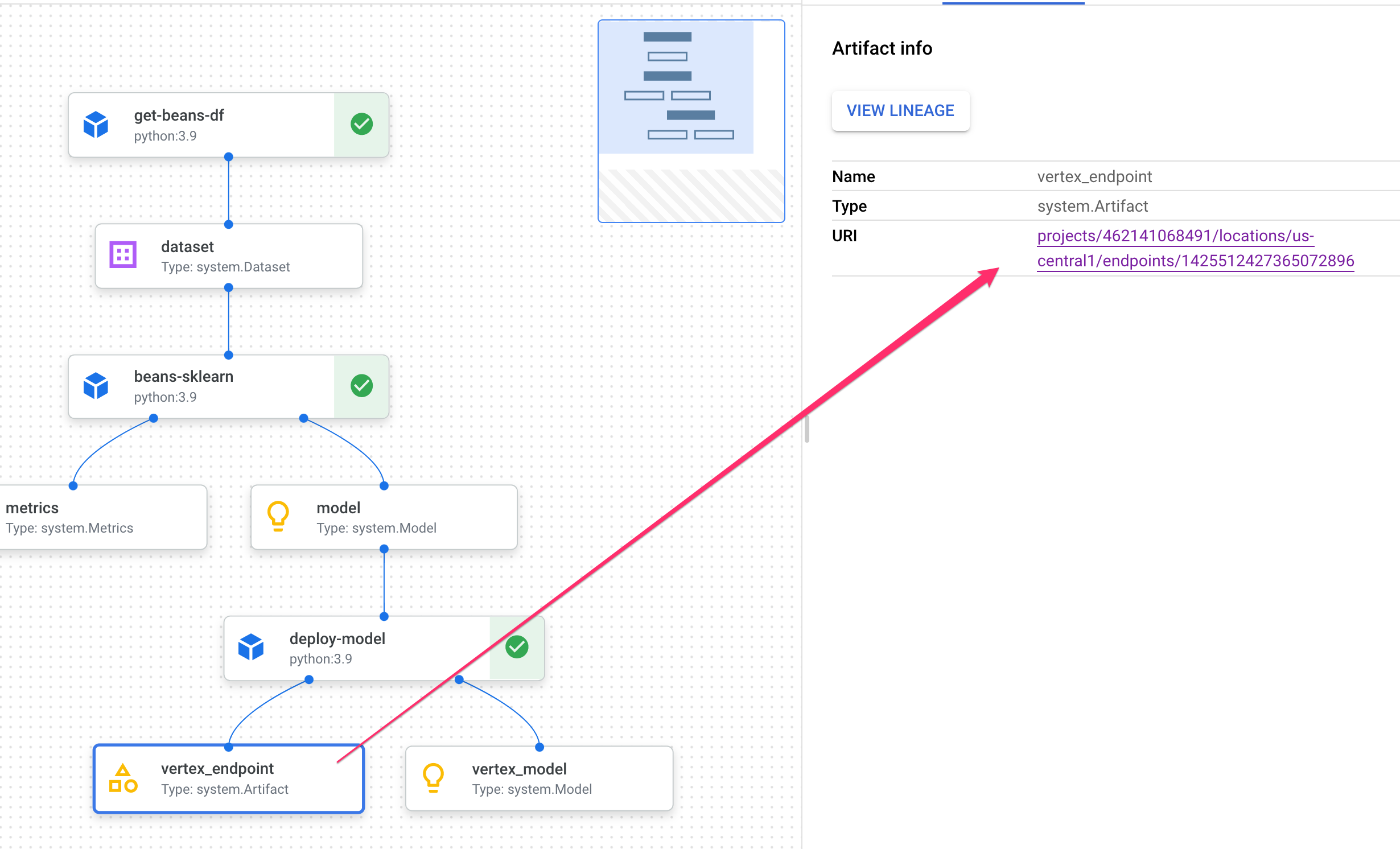
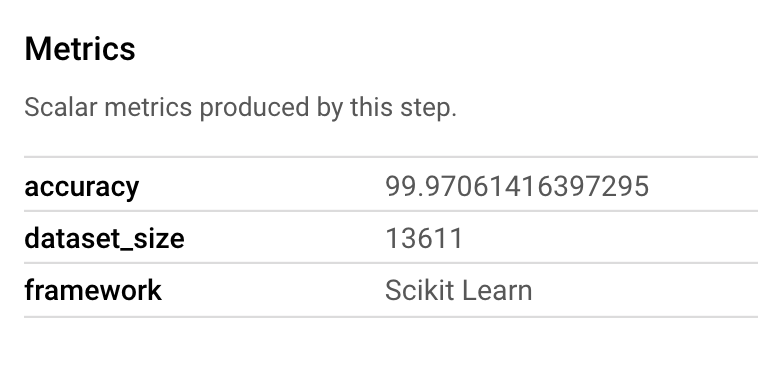
Mit einem Metrics-Artefakt können Sie benutzerdefinierte Messwerte übergeben, die einem bestimmten Pipelineschritt zugeordnet sind. In der sklearn_train-Komponente unserer Pipeline haben wir Messwerte zur Genauigkeit, zum Framework und zur Dataset-Größe unseres Modells protokolliert. Klicken Sie auf das Messwertartefakt, um diese Details aufzurufen:
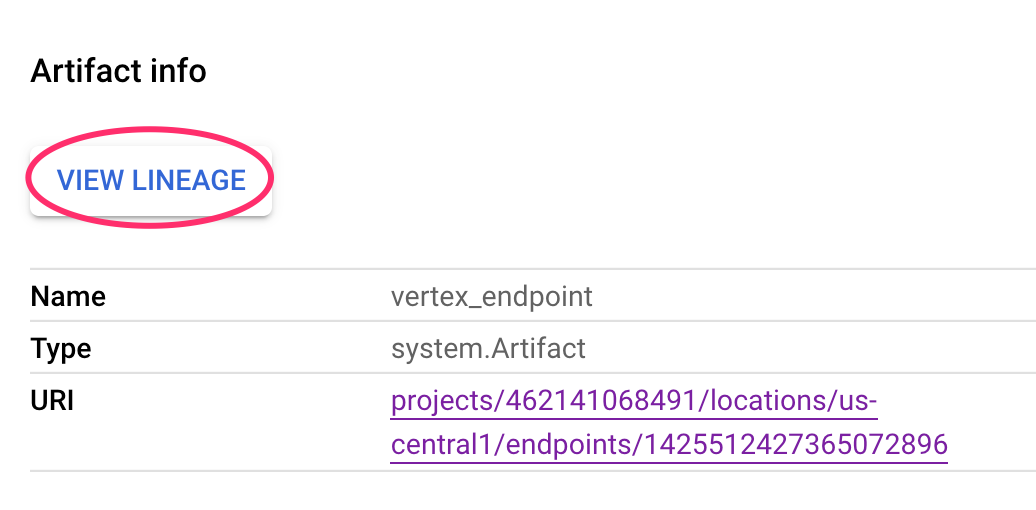
Jedes Artefakt hat eine Abstammung, die die anderen Artefakte beschreibt, mit denen es verbunden ist. Klicken Sie noch einmal auf das vertex_endpoint-Artefakt Ihrer Pipeline und dann auf die Schaltfläche Lineage ansehen:
Daraufhin wird ein neuer Tab geöffnet, auf dem Sie alle Artefakte sehen, die mit dem ausgewählten Artefakt verknüpft sind. Das Lineage-Diagramm sieht in etwa so aus:
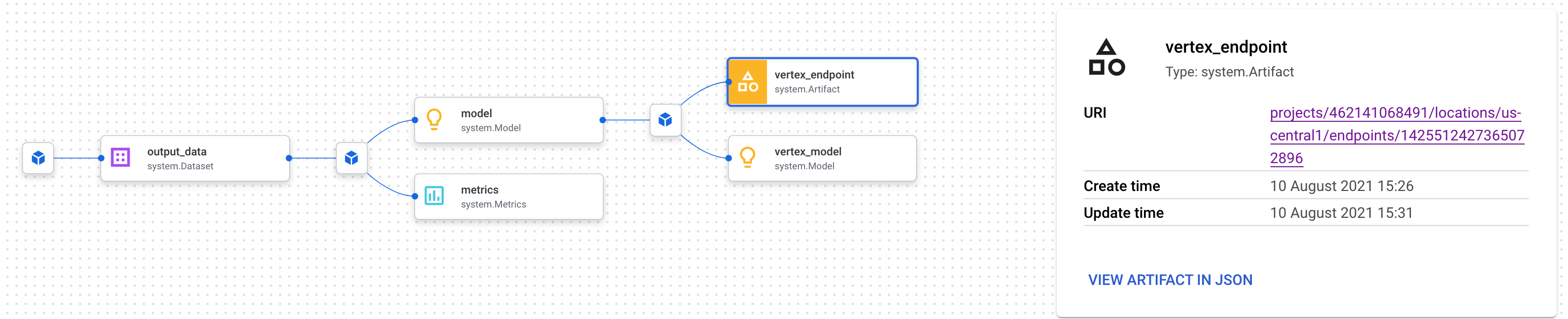
Hier sehen wir das Modell, die Messwerte und das Dataset, die mit diesem Endpunkt verknüpft sind. Welchen Nutzen bieten sie? Möglicherweise haben Sie ein Modell auf mehreren Endpunkten bereitgestellt oder müssen wissen, welches Dataset zum Trainieren des Modells verwendet wurde, das auf dem Endpunkt bereitgestellt wurde, den Sie sich ansehen. Anhand des Herkunftsgraphen können Sie jedes Artefakt im Kontext des restlichen ML-Systems betrachten. Sie können auch programmatisch auf die Herkunft zugreifen, wie wir später in diesem Codelab sehen werden.
7. Pipelineausführungen vergleichen
Wahrscheinlich wird eine einzelne Pipeline mehrmals ausgeführt, möglicherweise mit unterschiedlichen Eingabeparametern, neuen Daten oder von verschiedenen Personen in Ihrem Team. Um den Überblick über Pipelineausführungen zu behalten, ist es hilfreich, sie anhand verschiedener Messwerte vergleichen zu können. In diesem Abschnitt werden zwei Möglichkeiten zum Vergleichen von Läufen beschrieben.
Ausführungen in der Pipelines-Benutzeroberfläche vergleichen
Rufen Sie in der Cloud Console Ihr Pipelines-Dashboard auf. Hier finden Sie eine Übersicht über alle Pipelineausführungen. Sehen Sie sich die letzten beiden Läufe an und klicken Sie dann oben auf die Schaltfläche Vergleichen:
Auf dieser Seite können wir die Eingabeparameter und Messwerte für die ausgewählten Ausführungen vergleichen. Beachten Sie bei diesen beiden Läufen die unterschiedlichen BigQuery-Tabellen, Dataset-Größen und Genauigkeitswerte:
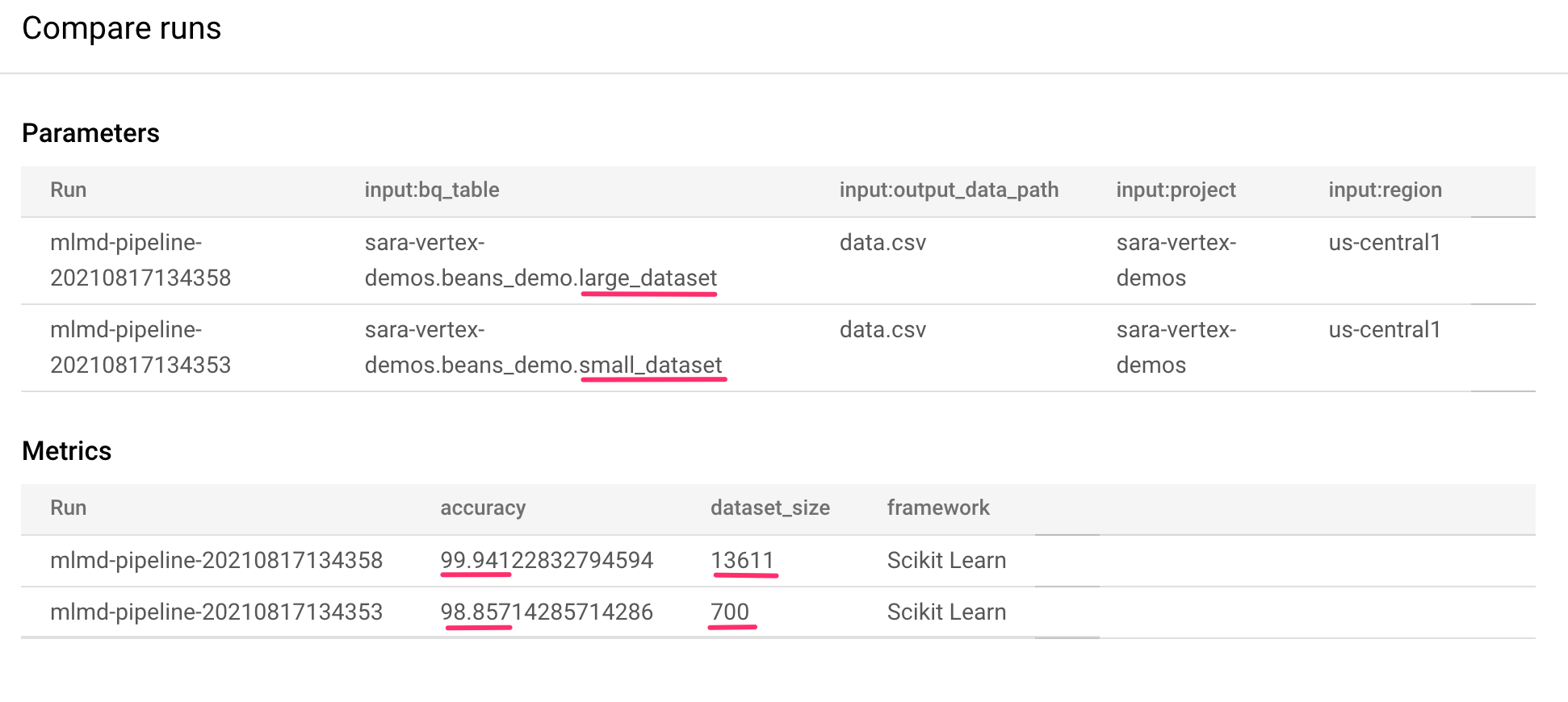
Mit dieser Benutzeroberflächenfunktion können Sie mehr als zwei Läufe und sogar Läufe aus verschiedenen Pipelines vergleichen.
Ausführungen mit dem Vertex AI SDK vergleichen
Bei vielen Pipeline-Ausführungen möchten Sie diese Vergleichsmesswerte möglicherweise programmatisch abrufen, um Messwertdetails genauer zu untersuchen und Visualisierungen zu erstellen.
Mit der Methode aiplatform.get_pipeline_df() können Sie auf die Metadaten der Ausführungen zugreifen. Hier erhalten wir Metadaten für die letzten beiden Ausführungen derselben Pipeline und laden diese in einen Pandas DataFrame. Der Parameter pipeline bezieht sich hier auf den Namen, den wir unserer Pipeline in der Pipelinedefinition gegeben haben:
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
Wenn Sie den DataFrame ausgeben, sehen Sie in etwa Folgendes:

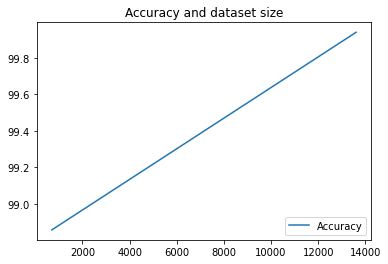
Wir haben unsere Pipeline hier nur zweimal ausgeführt. Sie können sich aber vorstellen, wie viele Messwerte Sie bei mehr Ausführungen erhalten würden. Als Nächstes erstellen wir mit Matplotlib eine benutzerdefinierte Visualisierung, um die Beziehung zwischen der Genauigkeit unseres Modells und der Menge der für das Training verwendeten Daten zu sehen.
Führen Sie den folgenden Code in einer neuen Notebook-Zelle aus:
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
Auf dem Bildschirm sollte Folgendes zu sehen sein:
8. Pipeline-Messwerte abfragen
Zusätzlich zu einem DataFrame mit allen Pipelinemesswerten möchten Sie möglicherweise Artefakte, die in Ihrem ML-System erstellt wurden, programmatisch abfragen. Dort können Sie ein benutzerdefiniertes Dashboard erstellen oder anderen in Ihrer Organisation Details zu bestimmten Artefakten zur Verfügung stellen.
Alle Modellartefakte abrufen
Um Artefakte auf diese Weise abzufragen, erstellen wir ein MetadataServiceClient:
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
Als Nächstes senden wir eine list_artifacts-Anfrage an diesen Endpunkt und übergeben einen Filter, der angibt, welche Artefakte wir in unserer Antwort haben möchten. Rufen wir zuerst alle Artefakte in unserem Projekt ab, die Modelle sind. Führen Sie dazu Folgendes in Ihrem Notebook aus:
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
Die resultierende model_artifacts-Antwort enthält ein iterierbares Objekt für jedes Modellartefakt in Ihrem Projekt sowie zugehörige Metadaten für jedes Modell.
Objekte filtern und in einem DataFrame anzeigen
Es wäre praktisch, wenn wir die resultierende Artefaktanfrage leichter visualisieren könnten. Als Nächstes rufen wir alle Artefakte ab, die nach dem 10. August 2021 mit dem Status LIVE erstellt wurden. Nachdem wir diese Anfrage ausgeführt haben, werden die Ergebnisse in einem Pandas DataFrame angezeigt. Führen Sie zuerst die Anfrage aus:
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
Stellen Sie die Ergebnisse dann in einem DataFrame dar:
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
Sie sehen etwa Folgendes:

Sie können Artefakte auch nach anderen Kriterien filtern.
Damit haben Sie das Lab abgeschlossen.
🎉 Das wars! 🎉
Sie haben gelernt, wie Sie Vertex AI für folgende Aufgaben verwenden:
- Verwenden Sie das Kubeflow Pipelines SDK, um eine ML-Pipeline zu erstellen, die ein Dataset in Vertex AI erstellt und ein benutzerdefiniertes Scikit-learn-Modell für dieses Dataset trainiert und bereitstellt.
- Schreiben Sie benutzerdefinierte Pipelinekomponenten, die Artefakte und Metadaten generieren
- Vertex Pipelines-Ausführungen sowohl in der Cloud Console als auch programmatisch vergleichen
- Herkunft von Pipeline-generierten Artefakten verfolgen
- Fragen Sie die Metadaten der Pipelineausführung ab
Weitere Informationen zu den verschiedenen Bereichen von Vertex finden Sie in der Dokumentation.
9. Bereinigen
Damit keine Gebühren anfallen, sollten Sie die in diesem Lab erstellten Ressourcen löschen.
Notebooks-Instanz beenden oder löschen
Wenn Sie das in diesem Lab erstellte Notebook weiterhin verwenden möchten, sollten Sie es deaktivieren, wenn Sie es nicht nutzen. Wählen Sie in der Notebooks-Benutzeroberfläche in der Cloud Console das Notebook und dann Beenden aus. Wenn Sie die Instanz vollständig löschen möchten, wählen Sie Löschen aus:
Vertex AI-Endpunkte löschen
Wenn Sie den bereitgestellten Endpunkt löschen möchten, rufen Sie in der Vertex AI Console den Abschnitt Endpunkte auf und klicken Sie auf das Symbol zum Löschen:

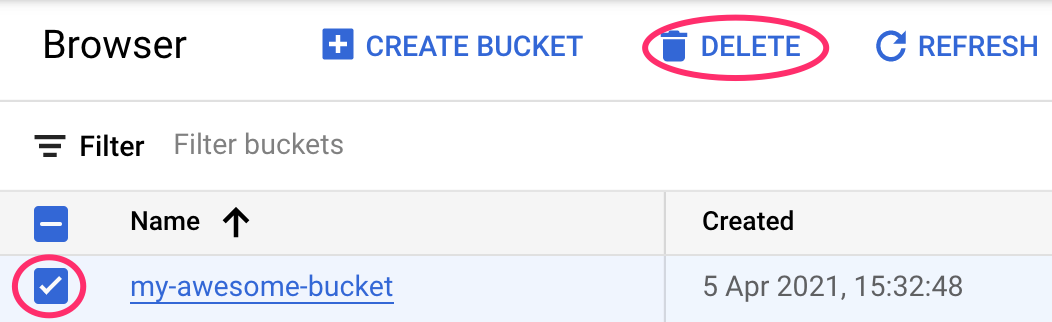
Cloud Storage-Bucket löschen
Wenn Sie den Storage-Bucket löschen möchten, rufen Sie in der Cloud Console über das Navigationsmenü „Storage“ auf, wählen Sie den Bucket aus und klicken Sie auf „Löschen“: