1. 개요
이 실습에서는 Vertex ML Metadata를 사용하여 Vertex Pipelines 실행의 메타데이터를 분석하는 방법을 알아봅니다.
학습 내용
다음 작업을 수행하는 방법을 배우게 됩니다.
- Kubeflow Pipelines SDK를 사용하여 Vertex AI에서 데이터 세트를 만들고 해당 데이터 세트에서 맞춤 Scikit-learn 모델을 학습시키고 배포하는 ML 파이프라인을 빌드합니다.
- 아티팩트와 메타데이터를 생성하는 커스텀 파이프라인 구성요소를 작성합니다.
- Cloud 콘솔과 프로그래매틱 방식으로 Vertex Pipelines 실행을 비교합니다.
- 파이프라인 생성 아티팩트의 계보 추적
- 파이프라인 실행 메타데이터를 쿼리합니다.
Google Cloud에서 이 실습을 진행하는 데 드는 총 비용은 약 $2입니다.
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다.
모델 학습 및 배포 서비스 외에도 Vertex AI에는 Vertex AI Pipelines, ML Metadata, Model Monitoring, Feature Store를 비롯한 다양한 MLOps 제품이 포함되어 있습니다. 아래 다이어그램에서 Vertex AI 제품을 모두 확인할 수 있습니다.
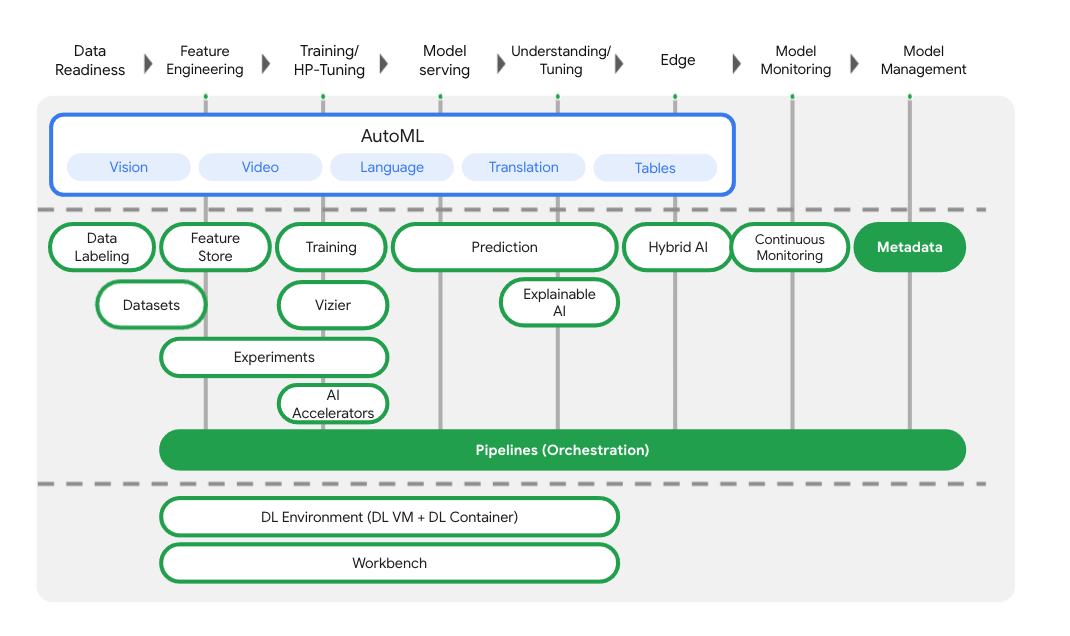
이 실습에서는 Vertex AI Pipelines 및 Vertex ML Metadata에 중점을 둡니다.
Vertex AI에 대한 의견이 있는 경우 지원 페이지를 참고하세요.
ML 파이프라인이 유용한 이유
자세히 알아보기 전에 먼저 파이프라인을 사용하려는 이유를 생각해 보겠습니다. 데이터 처리, 모델 학습, 하이퍼파라미터 튜닝, 평가, 모델 배포가 포함된 ML 워크플로를 빌드한다고 상상해 보세요. 각 단계에는 다양한 종속 항목이 있을 수 있어 전체 워크플로를 모놀리식으로 처리하면 관리가 힘들 수 있습니다. ML 프로세스를 확장하기 시작할 때 팀원이 워크플로를 실행하고 코드 개발에 참여하도록 팀원과 ML 워크플로를 공유하려는 경우를 생각해 보겠습니다. 신뢰할 수 있고 재현 가능한 프로세스가 없으면 이 작업이 어려워질 수 있습니다. 파이프라인을 사용하면 ML 프로세스의 각 단계는 자체 컨테이너가 됩니다. 이를 통해 단계를 독립적으로 개발하고 재현 가능한 방식으로 각 단계의 입력 및 출력을 추적할 수 있습니다. 새로운 학습 데이터가 제공될 때 파이프라인 실행을 시작하는 것과 같이 Cloud 환경의 다른 이벤트를 기반으로 파이프라인 실행을 예약하거나 트리거할 수도 있습니다.
요약: 파이프라인을 사용하면 ML 워크플로를 자동화하고 재현할 수 있습니다.
3. 클라우드 환경 설정
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
Cloud Shell 시작
이 실습에서는 Google의 클라우드에서 실행되는 가상 머신이 호스팅하는 명령어 인터프리터인 Cloud Shell 세션에서 작업합니다. 이 섹션은 사용자의 컴퓨터에서 로컬로 쉽게 실행할 수도 있지만, Cloud Shell을 사용하면 모든 사람이 일관되고 재현 가능한 환경에 액세스할 수 있습니다. 실습을 마치고 로컬 컴퓨터에서 이 섹션을 다시 시도하셔도 됩니다.
Cloud Shell 활성화
Cloud 콘솔의 오른쪽 상단에서 아래 버튼을 클릭하여 Cloud Shell을 활성화합니다.

이전에 Cloud Shell을 시작하지 않았으면 설명이 포함된 중간 화면 (스크롤해야 볼 수 있는 부분)이 제공됩니다. 이 경우 계속을 클릭합니다 (이후 다시 표시되지 않음). 이 일회성 화면은 다음과 같습니다.
Cloud Shell을 프로비저닝하고 연결하는 작업은 몇 분이면 끝납니다.

이 가상 머신에는 필요한 개발 도구가 모두 포함되어 로드됩니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab에서 대부분의 작업은 브라우저나 Chromebook만 사용하여 수행할 수 있습니다.
Cloud Shell에 연결되면 인증이 완료되었고 프로젝트가 해당 프로젝트 ID로 이미 설정된 것을 볼 수 있습니다.
Cloud Shell에서 다음 명령어를 실행하여 인증되었는지 확인합니다.
gcloud auth list
명령어 결과
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
명령어 결과
[core] project = <PROJECT_ID>
또는 다음 명령어로 설정할 수 있습니다.
gcloud config set project <PROJECT_ID>
명령어 결과
Updated property [core/project].
Cloud Shell에는 현재 Cloud 프로젝트의 이름이 포함된 GOOGLE_CLOUD_PROJECT를 비롯하여 몇 가지 환경 변수가 있습니다. 이는 이 실습에서 여러 차례 사용됩니다. 다음을 실행하여 환경 변수를 확인할 수 있습니다.
echo $GOOGLE_CLOUD_PROJECT
API 사용 설정
이러한 서비스가 필요한 경우와 그 이유는 이후 단계에서 설명하겠습니다. 우선 이 명령어를 실행하여 프로젝트에 Compute Engine, Container Registry, Vertex AI 서비스에 대한 액세스 권한을 부여해 보겠습니다.
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
그러면 다음과 비슷한 성공 메시지가 표시될 것입니다.
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Cloud Storage 버킷 만들기
Vertex AI에서 학습 작업을 실행하려면 저장된 모델 애셋을 저장할 스토리지 버킷이 필요합니다. 버킷은 리전을 기반으로 해야 합니다. 여기서는 us-central를 사용하고 있지만 다른 리전을 사용해도 됩니다. 단, 실습 전반에서 동일한 리전을 사용해야 합니다. 이미 버킷이 있는 경우 이 단계를 건너뛸 수 있습니다.
Cloud Shell 터미널에서 다음 명령어를 실행하여 버킷을 만듭니다.
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
다음으로 컴퓨팅 서비스 계정에 이 버킷에 대한 액세스 권한을 부여합니다. 이렇게 하면 Vertex Pipelines에 이 버킷에 파일을 쓰는 데 필요한 권한이 부여됩니다. 다음 명령어를 실행하여 이 권한을 추가합니다.
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
Vertex AI Workbench 인스턴스 생성
Cloud 콘솔의 Vertex AI 섹션에서 'Workbench'를 클릭합니다.
여기에서 사용자 관리 노트북 내에서 새 노트북을 클릭합니다.

그런 다음 GPU가 없는 TensorFlow Enterprise 2.3 (LTS 사용) 인스턴스 유형을 선택합니다.
기본 옵션을 사용한 다음 만들기를 클릭합니다.
노트북 열기
인스턴스가 생성되면 JupyterLab 열기를 선택합니다.

4. Vertex Pipelines 설정
Vertex Pipeline을 사용하려면 몇 가지 추가 라이브러리를 설치해야 합니다.
- Kubeflow Pipelines: 파이프라인을 빌드하는 데 사용되는 SDK입니다. Vertex Pipelines는 Kubeflow Pipelines 또는 TFX를 사용하여 빌드된 파이프라인 실행을 지원합니다.
- Vertex AI SDK: 이 SDK는 Vertex AI API 호출 환경을 최적화합니다. Vertex AI에서 파이프라인을 실행하는 데 사용됩니다.
Python 노트북 생성 및 라이브러리 설치하기
먼저 노트북 인스턴스의 런처 메뉴에서 Python 3을 선택하여 노트북을 생성합니다.

이 실습에서 사용할 두 서비스를 모두 설치하려면 먼저 노트북 셀에 사용자 플래그를 설정한 다음
USER_FLAG = "--user"
노트북에서 다음을 실행합니다.
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
다음 패키지를 설치한 후 커널을 다시 시작해야 합니다.
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
다음으로 KFP SDK 버전을 올바르게 설치했는지 확인합니다. 1.8 이상이어야 합니다.
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
그런 다음 Vertex AI SDK 버전이 1.6.2 이상인지 확인합니다.
!pip list | grep aiplatform
프로젝트 ID 및 버킷 설정하기
이 실습 전체에서 Cloud 프로젝트 ID와 이전에 만든 버킷을 참조합니다. 그런 다음 각 항목의 변수를 만듭니다.
프로젝트 ID를 모르는 경우 다음을 실행하여 프로젝트 ID를 확인할 수 있습니다.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
그렇지 않으면 다음에서 설정합니다.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
그런 다음, 버킷 이름을 저장할 변수를 만듭니다. 이 실습에서 변수를 만든 경우 다음이 작동합니다. 그렇지 않으면 수동으로 이를 설정해야 합니다.
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
라이브러리 가져오기
다음을 추가하여 이 Codelab에서 사용할 라이브러리를 가져옵니다.
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
상수 정의하기
파이프라인을 빌드하기 전 마지막으로 해야 할 일은 상수 변수를 정의하는 것입니다. PIPELINE_ROOT는 파이프라인에서 생성된 아티팩트가 작성될 Cloud Storage 경로입니다. 여기서는 us-central1을 리전으로 사용하고 있지만, 버킷을 만들 때 다른 리전을 사용했다면 아래 코드에서 REGION 변수를 업데이트하세요.
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
위의 코드를 실행한 후에는 파이프라인의 루트 디렉터리가 출력되어야 합니다. 이는 파이프라인의 아티팩트가 작성될 Cloud Storage 위치이며 gs://YOUR-BUCKET-NAME/pipeline_root/ 형식입니다.
5. 맞춤 구성요소로 3단계 파이프라인 만들기
이 실습에서는 파이프라인 실행의 메타데이터를 이해하는 데 중점을 둡니다. 이렇게 하려면 Vertex Pipelines에서 실행할 파이프라인이 필요합니다. 여기에서 시작합니다. 여기서는 다음 맞춤 구성요소를 사용하여 3단계 파이프라인을 정의합니다.
get_dataframe: BigQuery 테이블에서 데이터를 가져와 Pandas DataFrame으로 변환train_sklearn_model: Pandas DataFrame을 사용하여 측정항목과 함께 Scikit Learn 모델을 학습시키고 내보냅니다.deploy_model: 내보낸 Scikit Learn 모델을 Vertex AI의 엔드포인트에 배포합니다.
이 파이프라인에서는 UCI Machine Learning Dry beans dataset(출처: KOKLU, M. and OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques."In Computers and Electronics in Agriculture, 174, 105507. DOI
이 테이블 형식 데이터 세트는 파이프라인에서 특성에 따라 콩을 7가지 유형으로 분류하는 Scikit-learn 모델을 학습시키고, 평가하고, 배포하는 데 사용됩니다. 코딩을 시작해 볼까요?
Python 함수 기반 구성요소 만들기
KFP SDK를 사용하여 Python 함수를 기반으로 구성요소를 만들 수 있습니다. 이를 이 파이프라인의 3가지 구성요소에 사용해 보겠습니다.
BigQuery 데이터 다운로드 및 CSV로 변환
먼저 get_dataframe 구성요소를 빌드합니다.
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
이 구성요소에서 어떤 일이 일어나는지 자세히 살펴보겠습니다.
@component데코레이터는 파이프라인이 실행될 때 이 함수를 구성요소로 컴파일합니다. 커스텀 구성요소를 작성할 때마다 이 함수를 사용할 수 있습니다.base_image파라미터는 이 구성요소가 사용할 컨테이너 이미지를 지정합니다.- 이 구성요소는
packages_to_install매개변수를 통해 지정하는 몇 가지 Python 라이브러리를 사용합니다. output_component_file파라미터는 선택사항이며 컴파일된 구성요소를 작성할 yaml 파일을 지정합니다. 셀을 실행한 후에는 해당 파일이 노트북 인스턴스에 작성된 것을 확인할 수 있습니다. 이 구성요소를 다른 사용자와 공유하려면 생성된 yaml 파일을 다른 사용자에게 전송하고 다음을 사용하여 해당 파일을 로드하도록 하면 됩니다.
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- 그런 다음 이 구성요소는 BigQuery Python 클라이언트 라이브러리를 사용하여 BigQuery에서 Pandas DataFrame으로 데이터를 다운로드한 후 해당 데이터의 출력 아티팩트를 CSV 파일로 만듭니다. 이는 다음 구성요소에 입력으로 전달됩니다.
Scikit-learn 모델을 학습시키는 구성요소 만들기
이 구성요소에서는 이전에 생성한 CSV를 가져와 이를 사용하여 Scikit-learn 결정 트리 모델을 학습시킵니다. 이 구성요소는 모델의 정확도, 프레임워크, 학습에 사용된 데이터 세트의 크기가 포함된 Metrics 아티팩트와 함께 결과 Scikit 모델을 내보냅니다.
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
모델을 Vertex AI에 업로드하고 배포하는 구성요소 정의
마지막으로, 마지막 구성요소는 이전 단계에서 학습된 모델을 가져와 Vertex AI에 업로드하고 엔드포인트에 배포합니다.
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
여기서는 Vertex AI SDK를 사용하여 예측용 사전 빌드된 컨테이너를 사용하여 모델을 업로드합니다. 그런 다음 모델을 엔드포인트에 배포하고 모델과 엔드포인트 리소스의 URI를 모두 반환합니다. 이 Codelab의 뒷부분에서 이 데이터를 아티팩트로 반환하는 것이 어떤 의미인지 자세히 알아봅니다.
파이프라인 정의 및 컴파일
이제 세 가지 구성요소를 정의했으므로 다음으로 파이프라인 정의를 만들어 보겠습니다. 이는 단계 간에 입력 및 출력 아티팩트가 흐르는 방식을 설명합니다.
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
다음과 같이 파이프라인을 실행하는 데 사용할 JSON 파일을 생성합니다.
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
파이프라인 실행 두 개 시작
이제 파이프라인을 두 번 실행합니다. 먼저 파이프라인 작업 ID에 사용할 타임스탬프를 정의합니다.
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
파이프라인을 실행할 때 학습 데이터에 사용할 bq_table라는 매개변수 하나를 사용합니다. 이 파이프라인 실행에서는 더 작은 버전의 beans 데이터 세트를 사용합니다.
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
그런 다음 동일한 데이터 세트의 더 큰 버전을 사용하여 다른 파이프라인 실행을 만듭니다.
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
마지막으로 두 실행 모두에 대해 파이프라인 실행을 시작합니다. 각 실행의 출력을 확인할 수 있도록 별도의 노트북 셀 두 개에서 이 작업을 실행하는 것이 좋습니다.
run1.submit()
그런 다음 두 번째 실행을 시작합니다.
run2.submit()
이 셀을 실행하면 Vertex AI 콘솔에서 각 파이프라인을 볼 수 있는 링크가 표시됩니다. 해당 링크를 열어 파이프라인에 관한 자세한 내용을 확인하세요.

완료되면 (이 파이프라인은 실행당 10~15분 정도 소요됨) 다음과 같이 표시됩니다.
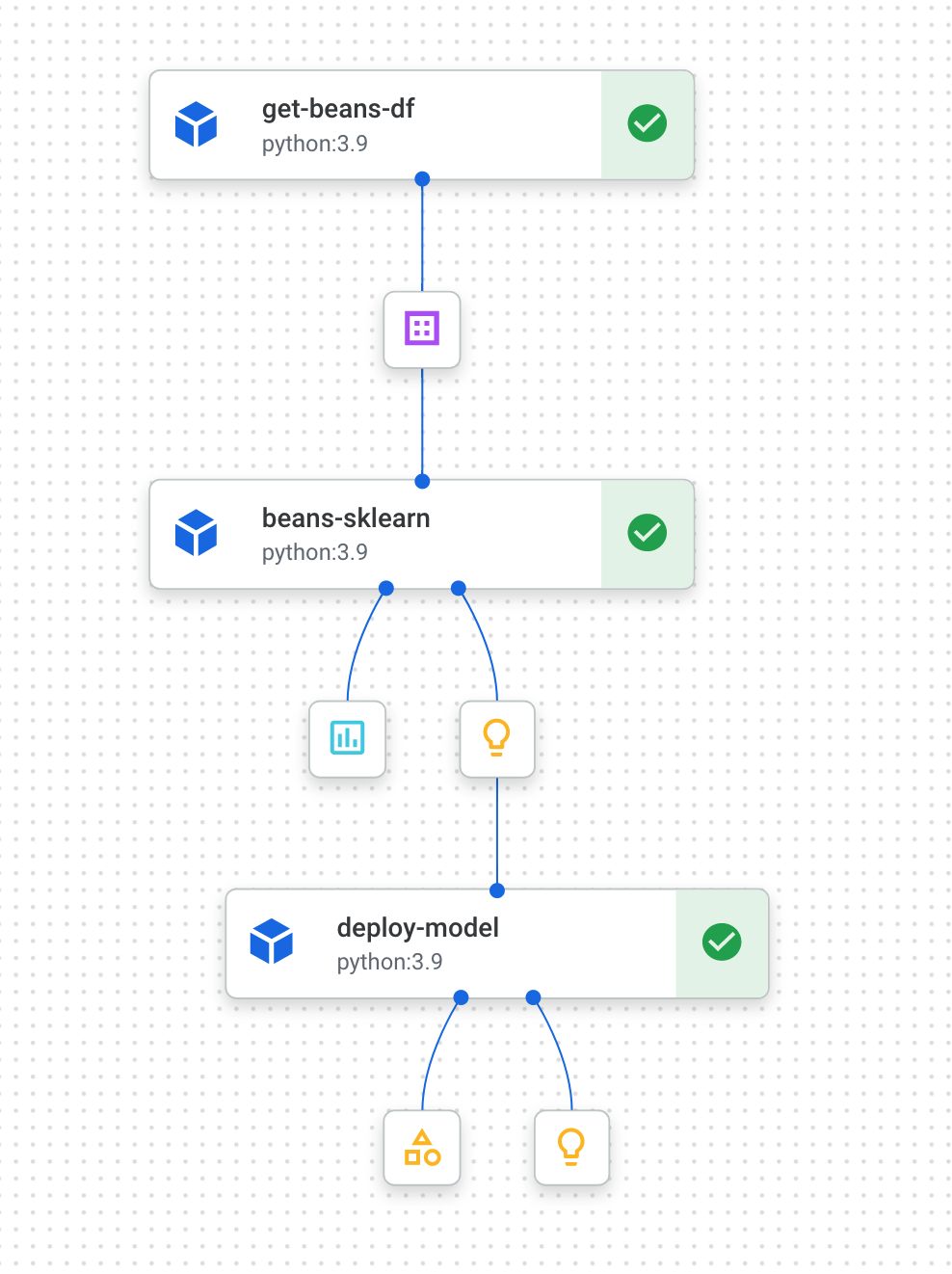
이제 파이프라인 실행이 두 번 완료되었으므로 파이프라인 아티팩트, 측정항목, 계보를 자세히 살펴볼 수 있습니다.
6. 파이프라인 아티팩트 및 계보 이해
파이프라인 그래프에서 각 단계 뒤에 작은 상자가 표시됩니다. 이러한 항목이 아티팩트, 즉 파이프라인 단계에서 생성된 출력입니다. 아티팩트에는 여러 유형이 있습니다. 이 특정 파이프라인에는 데이터 세트, 측정항목, 모델, 엔드포인트 아티팩트가 있습니다. UI 상단의 아티팩트 펼치기 슬라이더를 클릭하여 각 아티팩트에 대한 자세한 내용을 확인합니다.
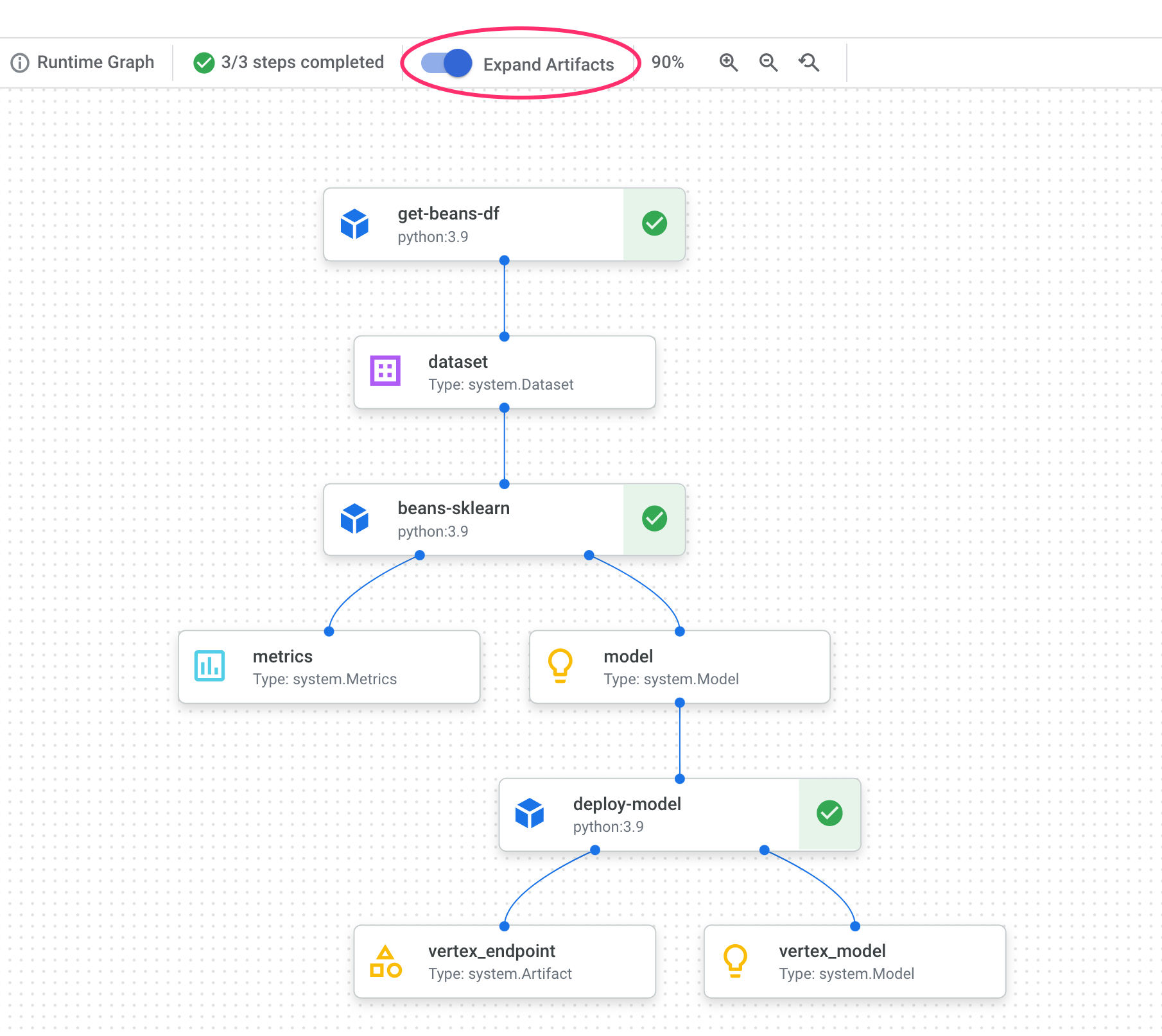
아티팩트를 클릭하면 URI를 비롯한 자세한 내용이 표시됩니다. 예를 들어 vertex_endpoint 아티팩트를 클릭하면 Vertex AI 콘솔에서 배포된 엔드포인트를 찾을 수 있는 URI가 표시됩니다.
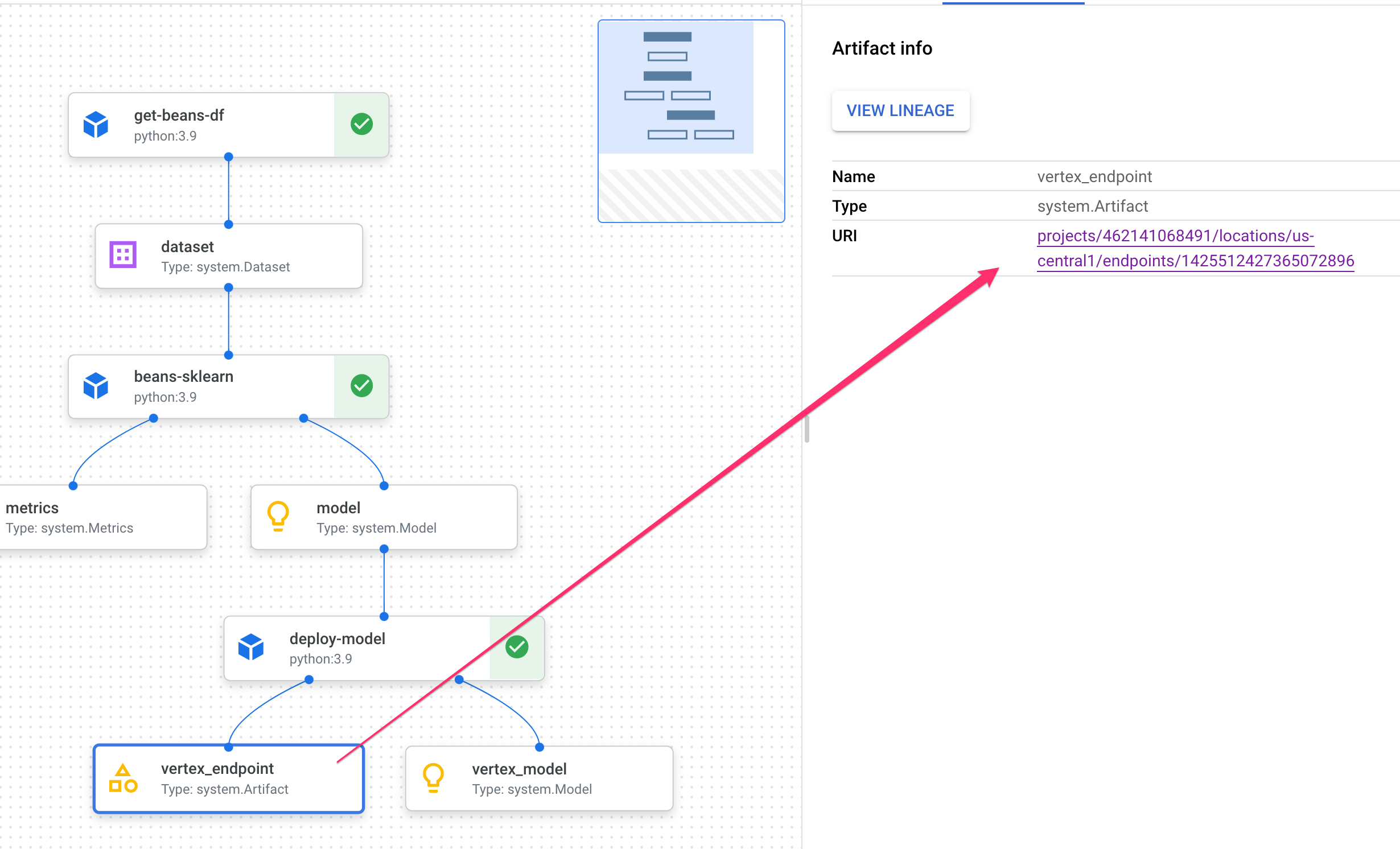
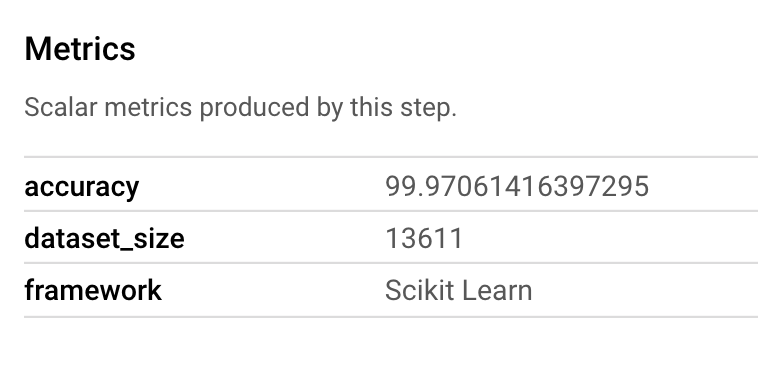
Metrics 아티팩트를 사용하면 특정 파이프라인 단계와 연결된 맞춤 측정항목을 전달할 수 있습니다. 파이프라인의 sklearn_train 구성요소에서 모델의 정확도, 프레임워크, 데이터 세트 크기에 관한 측정항목을 로깅했습니다. 측정항목 아티팩트를 클릭하여 다음 세부정보를 확인합니다.
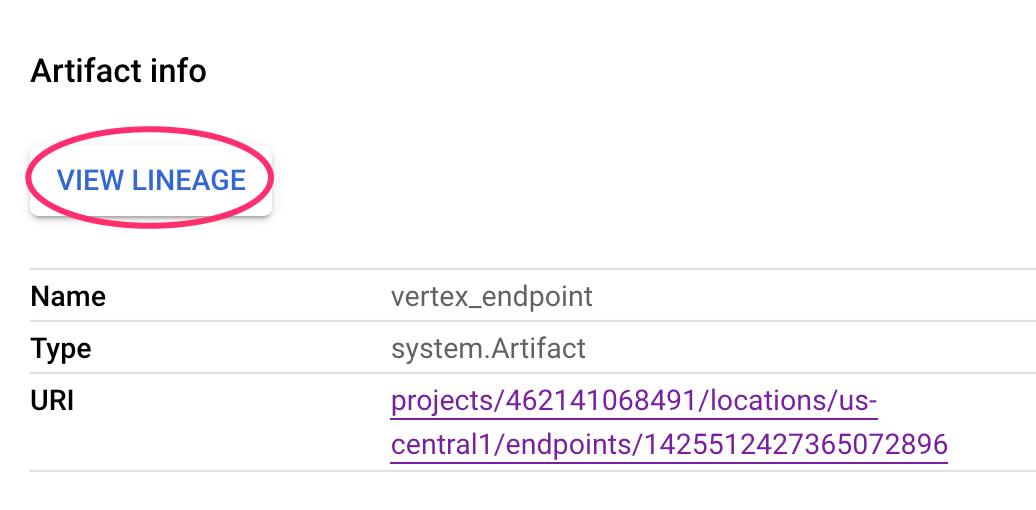
모든 아티팩트에는 연결된 다른 아티팩트를 설명하는 계보가 있습니다. 파이프라인의 vertex_endpoint 아티팩트를 다시 클릭한 다음 계보 보기 버튼을 클릭합니다.
그러면 선택한 아티팩트에 연결된 모든 아티팩트를 볼 수 있는 새 탭이 열립니다. 계보 그래프는 다음과 같이 표시됩니다.
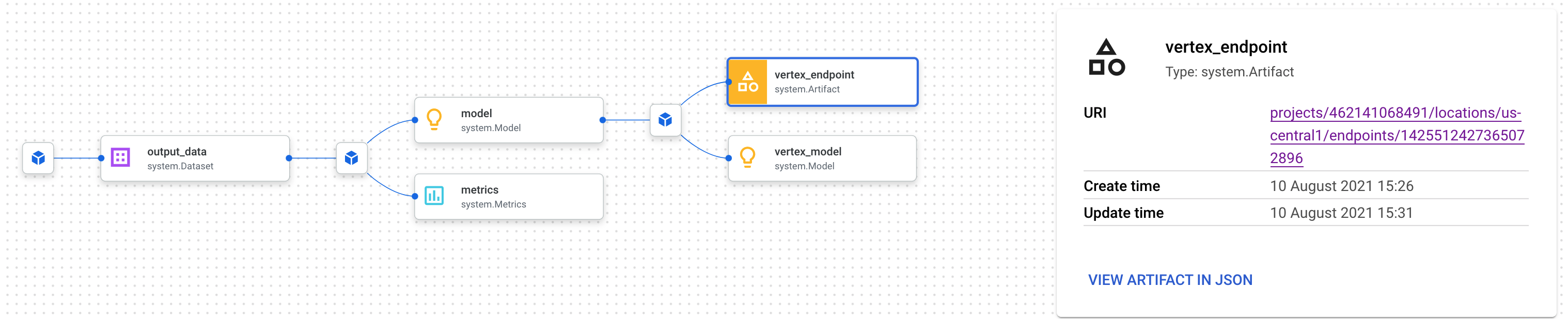
이 섹션에는 이 엔드포인트와 연결된 모델, 측정항목, 데이터 세트가 표시됩니다. 이것이 왜 유용할까요? 여러 엔드포인트에 모델이 배포되어 있거나, 보고 있는 엔드포인트에 배포된 모델을 학습하는 데 사용된 특정 데이터 세트를 알아야 할 수 있습니다. 계보 그래프를 사용하면 나머지 ML 시스템의 컨텍스트에서 각 아티팩트를 이해할 수 있습니다. 이 Codelab의 뒷부분에서 살펴보겠지만 계보에 프로그래매틱 방식으로 액세스할 수도 있습니다.
7. 파이프라인 실행 비교
단일 파이프라인이 여러 번 실행될 가능성이 높습니다. 입력 매개변수가 다르거나, 새 데이터가 있거나, 팀의 여러 사람이 실행할 수 있습니다. 파이프라인 실행을 추적하려면 다양한 측정항목에 따라 비교할 수 있는 방법이 있으면 편리합니다. 이 섹션에서는 두 가지 방법으로 실행을 비교해 보겠습니다.
파이프라인 UI에서 실행 비교
Cloud 콘솔에서 파이프라인 대시보드로 이동합니다. 여기에는 실행한 모든 파이프라인 실행이 개요로 표시됩니다. 마지막 두 실행을 확인한 다음 상단의 비교 버튼을 클릭합니다.
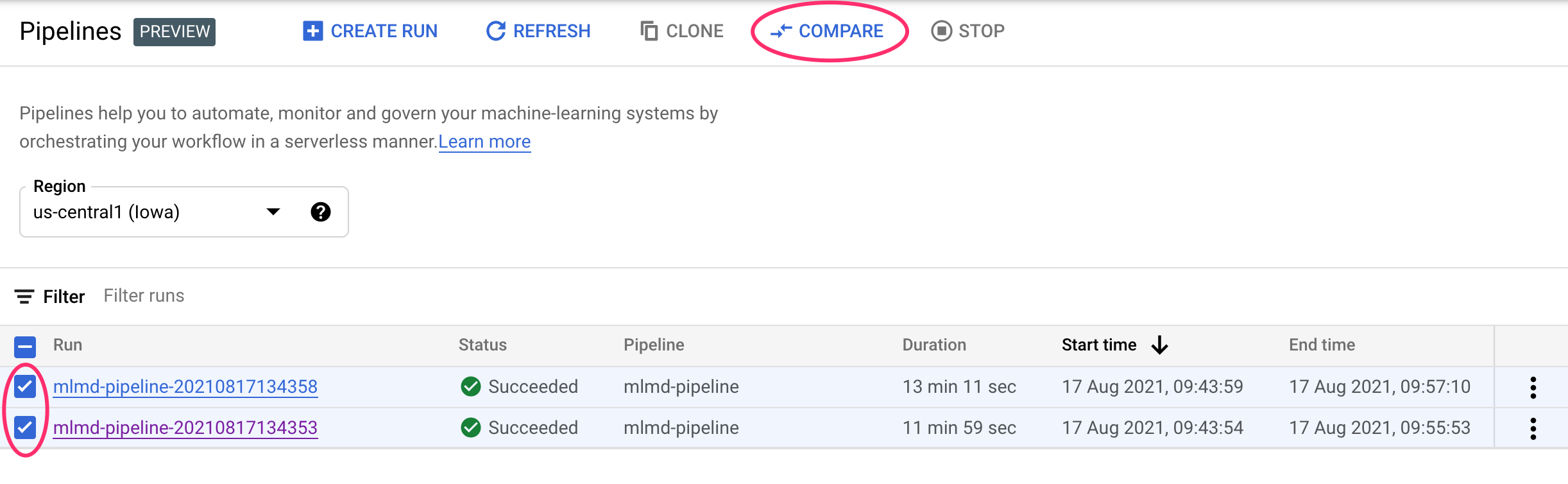
그러면 선택한 각 실행의 입력 매개변수와 측정항목을 비교할 수 있는 페이지로 이동합니다. 이 두 실행의 BigQuery 테이블, 데이터 세트 크기, 정확도 값이 서로 다릅니다.
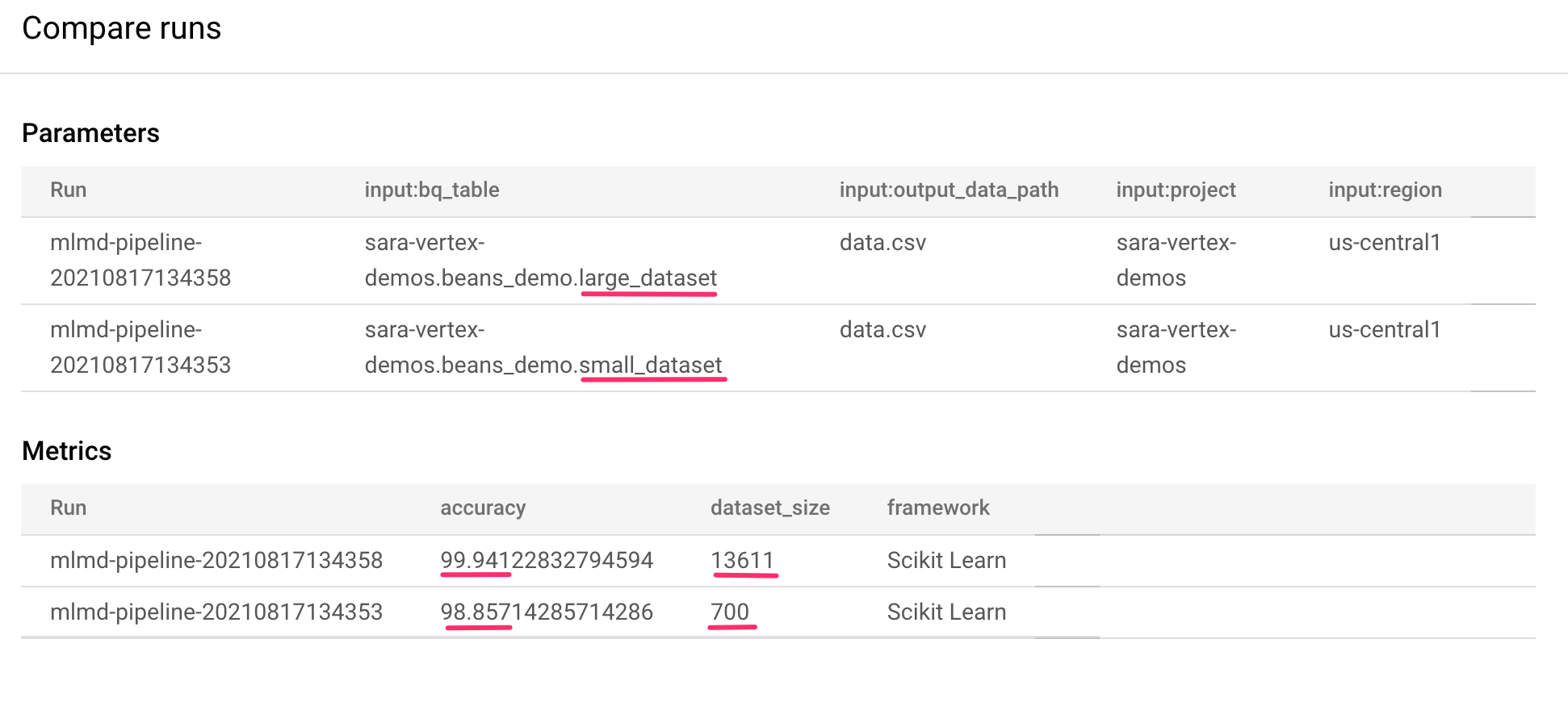
이 UI 기능을 사용하면 2개 이상의 실행을 비교할 수 있으며, 서로 다른 파이프라인의 실행도 비교할 수 있습니다.
Vertex AI SDK로 실행 비교
파이프라인 실행이 많은 경우 이러한 비교 측정항목을 프로그래매틱 방식으로 가져와 측정항목 세부정보를 자세히 살펴보고 시각화를 만들 수 있습니다.
aiplatform.get_pipeline_df() 메서드를 사용하여 실행 메타데이터에 액세스할 수 있습니다. 여기서는 동일한 파이프라인의 마지막 두 실행에 대한 메타데이터를 구한 다음 Pandas DataFrame에 로드할 예정입니다. 여기서 pipeline 매개변수는 파이프라인 정의에서 파이프라인에 지정한 이름을 참조합니다.
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
DataFrame을 출력하면 다음과 같이 표시됩니다.

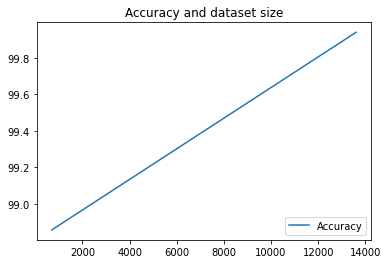
여기서는 파이프라인을 두 번만 실행했지만 더 많이 실행하면 얼마나 많은 측정항목이 생성될지 상상해 보세요. 다음으로 Matplotlib을 사용하여 맞춤 시각화를 만들어 모델의 정확도와 학습에 사용된 데이터 양 간의 관계를 확인합니다.
새 노트북 셀에서 다음을 실행합니다.
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
다음과 같은 결과를 확인할 수 있습니다.
8. 파이프라인 측정항목 쿼리
모든 파이프라인 측정항목의 DataFrame을 가져오는 것 외에도 ML 시스템에서 생성된 아티팩트를 프로그래매틱 방식으로 쿼리할 수 있습니다. 여기에서 맞춤 대시보드를 만들거나 조직의 다른 사용자가 특정 아티팩트에 대한 세부정보를 확인할 수 있습니다.
모든 모델 아티팩트 가져오기
이러한 방식으로 아티팩트를 쿼리하려면 MetadataServiceClient를 만듭니다.
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
그런 다음 해당 엔드포인트에 list_artifacts 요청을 보내고 응답에 포함할 아티팩트를 나타내는 필터를 전달합니다. 먼저 프로젝트에서 모델인 모든 아티팩트를 가져옵니다. 이렇게 하려면 노트북에서 다음을 실행하세요.
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
결과 model_artifacts 응답에는 프로젝트의 각 모델 아티팩트에 대한 반복 가능한 객체와 각 모델의 연결된 메타데이터가 포함됩니다.
객체 필터링 및 DataFrame에 표시
결과 아티팩트 쿼리를 더 쉽게 시각화할 수 있으면 유용할 것입니다. 다음으로 2021년 8월 10일 이후에 생성되고 LIVE 상태인 모든 아티팩트를 가져옵니다. 이 요청을 실행하면 결과가 Pandas DataFrame에 표시됩니다. 먼저 요청을 실행합니다.
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
그런 다음 결과를 DataFrame에 표시합니다.
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
다음과 같이 표시됩니다.

여기에서 시도한 것 외에도 다른 기준으로 아티팩트를 필터링할 수 있습니다.
이로써 실습을 완료했습니다.
🎉 수고하셨습니다. 🎉
Vertex AI를 사용하여 다음을 수행하는 방법을 배웠습니다.
- Kubeflow Pipelines SDK를 사용하여 Vertex AI에서 데이터 세트를 만들고 해당 데이터 세트에서 맞춤 Scikit-learn 모델을 학습시키고 배포하는 ML 파이프라인을 빌드합니다.
- 아티팩트와 메타데이터를 생성하는 커스텀 파이프라인 구성요소를 작성합니다.
- Cloud 콘솔과 프로그래매틱 방식으로 Vertex Pipelines 실행을 비교합니다.
- 파이프라인 생성 아티팩트의 계보 추적
- 파이프라인 실행 메타데이터를 쿼리합니다.
Vertex의 다른 부분에 대해 자세히 알아보려면 문서를 확인하세요.
9. 삭제
요금이 청구되지 않도록 이 실습 전반에 걸쳐 생성된 리소스를 삭제하는 것이 좋습니다.
Notebooks 인스턴스 중지 또는 삭제
이 실습에서 만든 노트북을 계속 사용하려면 사용하지 않을 때 노트북을 끄는 것이 좋습니다. Cloud 콘솔의 Notebooks UI에서 노트북을 선택한 다음 중지를 선택합니다. 인스턴스를 완전히 삭제하려면 삭제를 선택합니다.
Vertex AI 엔드포인트 삭제
배포한 엔드포인트를 삭제하려면 Vertex AI 콘솔의 엔드포인트 섹션으로 이동하여 삭제 아이콘을 클릭합니다.

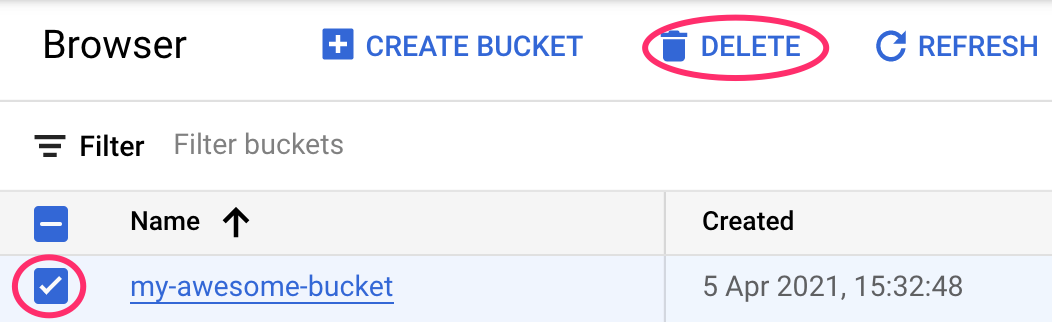
Cloud Storage 버킷 삭제
스토리지 버킷을 삭제하려면 Cloud 콘솔의 탐색 메뉴를 사용하여 스토리지로 이동하고 버킷을 선택하고 '삭제'를 클릭합니다.