
1. Ringkasan
Di lab ini, Anda akan mempelajari cara menganalisis metadata dari operasi Vertex Pipelines dengan Vertex ML Metadata.
Yang Anda pelajari
Anda akan mempelajari cara:
- Gunakan Kubeflow Pipelines SDK untuk membangun pipeline ML yang membuat set data di Vertex AI, serta melatih dan men-deploy model Scikit-learn kustom pada set data tersebut
- Menulis komponen pipeline kustom yang menghasilkan artefak dan metadata
- Membandingkan operasi Vertex Pipelines, baik di Cloud Console maupun secara terprogram
- Melacak silsilah untuk artefak yang dihasilkan pipeline
- Kueri metadata operasi pipeline
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $2.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI.
Selain layanan pelatihan dan deployment model, Vertex AI juga menyertakan berbagai produk MLOps, termasuk Vertex Pipelines, ML Metadata, Model Monitoring, Feature Store, dan lainnya. Anda dapat melihat semua penawaran produk Vertex AI dalam diagram di bawah.
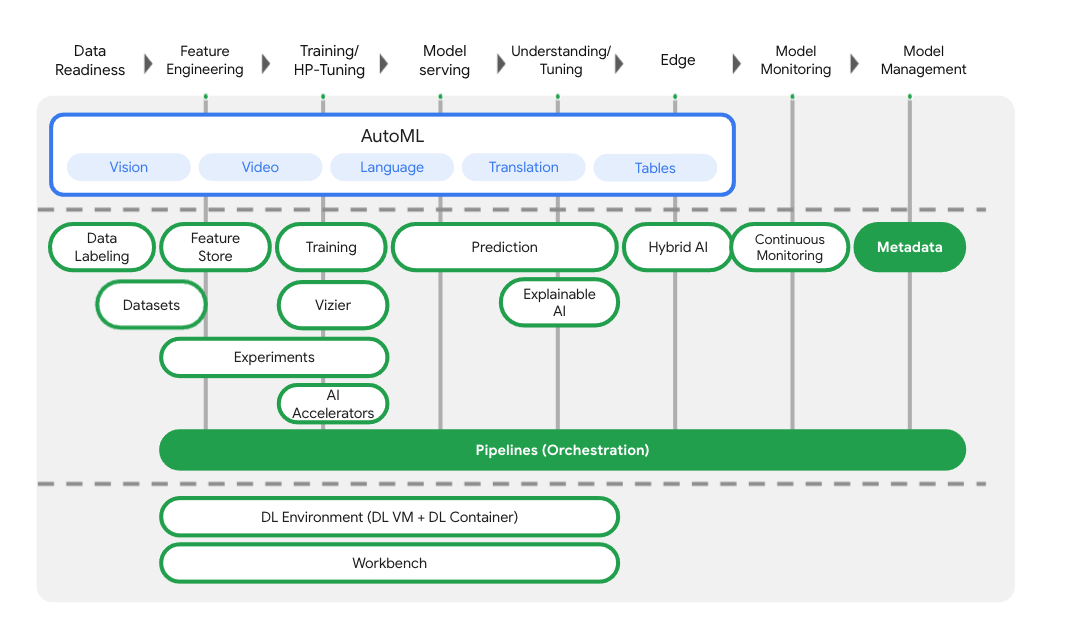
Lab ini berfokus pada Vertex Pipelines dan Vertex ML Metadata.
Jika Anda memiliki masukan tentang Vertex AI, harap lihat halaman dukungan.
Mengapa harus menggunakan pipeline ML?
Sebelum memulai, Anda perlu memahami terlebih dahulu alasan pentingnya menggunakan pipeline. Bayangkan Anda sedang membuat alur kerja ML yang mencakup pemrosesan data, pelatihan model, penyesuaian hyperparameter, evaluasi, dan deployment model. Setiap langkah ini mungkin memiliki dependensi berbeda, yang mungkin menyulitkan jika Anda memperlakukan keseluruhan alur kerja sebagai monolit. Saat mulai menskalakan proses ML, Anda mungkin ingin berbagi alur kerja ML Anda dengan anggota lain di tim Anda sehingga mereka dapat menjalankannya dan memberikan kontribusi kode. Tanpa proses yang andal dan dapat direproduksi, berbagi alur kerja ML bisa menjadi sulit. Dengan pipeline, setiap langkah dalam proses ML Anda berlangsung dalam container-nya sendiri. Hal ini memungkinkan Anda mengembangkan langkah-langkah secara independen serta memantau input dan output dari setiap langkah dengan cara yang dapat direproduksi. Anda juga dapat menjadwalkan atau memicu jalannya pipeline berdasarkan peristiwa lain di lingkungan Cloud Anda, seperti memulai jalannya pipeline saat data pelatihan baru tersedia.
Singkatnya: pipeline membantu Anda mengotomatiskan dan mereproduksi alur kerja ML Anda.
3. Penyiapan lingkungan cloud
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Mulai Cloud Shell
Dalam lab ini, Anda akan bekerja di sesi Cloud Shell, yang merupakan interpreter perintah yang dihosting oleh mesin virtual yang berjalan di cloud Google. Anda dapat menjalankan bagian ini dengan mudah secara lokal di komputer Anda sendiri, tetapi menggunakan Cloud Shell memberi semua orang akses ke pengalaman yang dapat direproduksi dalam lingkungan yang konsisten. Setelah menyelesaikan lab ini, Anda dapat mencoba kembali bagian ini di komputer Anda sendiri.
Mengaktifkan Cloud Shell
Dari kanan atas Konsol Cloud, klik tombol di bawah untuk Activate Cloud Shell:

Jika belum pernah memulai Cloud Shell, Anda akan melihat layar perantara (di paruh bawah) yang menjelaskan apa itu Cloud Shell. Jika demikian, klik Continue (dan Anda tidak akan pernah melihatnya lagi). Berikut tampilan layar sekali-tampil tersebut:
Perlu waktu beberapa saat untuk menyediakan dan terhubung ke Cloud Shell.

Virtual machine ini dimuat dengan semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Sebagian besar pekerjaan Anda dalam codelab ini dapat dilakukan hanya dengan browser atau Chromebook.
Setelah terhubung ke Cloud Shell, Anda akan melihat bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda.
Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa Anda telah diautentikasi:
gcloud auth list
Output perintah
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda:
gcloud config list project
Output perintah
[core] project = <PROJECT_ID>
Jika tidak, Anda dapat menyetelnya dengan perintah ini:
gcloud config set project <PROJECT_ID>
Output perintah
Updated property [core/project].
Cloud Shell memiliki beberapa variabel lingkungan, termasuk GOOGLE_CLOUD_PROJECT yang berisi nama project Cloud saat ini. Kita akan menggunakannya di berbagai tempat di sepanjang lab ini. Anda dapat melihatnya dengan menjalankan:
echo $GOOGLE_CLOUD_PROJECT
Mengaktifkan API
Pada langkah-langkah selanjutnya, Anda akan melihat tempat layanan ini diperlukan (dan alasannya), tetapi untuk saat ini, jalankan perintah ini untuk memberi project Anda akses ke layanan Compute Engine, Container Registry, dan Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Perintah di atas akan menampilkan pesan seperti berikut yang menandakan bahwa proses berhasil:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Membuat Bucket Cloud Storage
Untuk menjalankan tugas pelatihan di Vertex AI, kita memerlukan bucket penyimpanan untuk menyimpan aset model tersimpan. Bucket harus bersifat regional. Di sini kita menggunakan us-central, tetapi Anda dapat menggunakan region lain (cukup ganti di seluruh lab ini). Jika sudah memiliki bucket, Anda dapat melewati langkah ini.
Jalankan perintah berikut di terminal Cloud Shell untuk membuat bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
Selanjutnya, kita akan memberi akun layanan Compute Engine akses ke bucket ini. Tindakan ini akan memastikan bahwa Vertex Pipelines memiliki izin yang diperlukan untuk menulis file ke bucket ini. Jalankan perintah berikut untuk menambahkan izin ini:
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
Membuat instance Vertex AI Workbench
Dari bagian Vertex AI di Cloud Console Anda, klik Workbench:
Dari sana, di user-managed notebooks, klik New Notebook:

Kemudian, pilih jenis instance TensorFlow Enterprise 2.3 (with LTS) tanpa GPU:

Gunakan opsi default, lalu klik Buat.
Membuka Notebook Anda
Setelah instance dibuat, pilih Open JupyterLab:

4. Penyiapan Vertex Pipelines
Ada beberapa library tambahan yang perlu kita instal agar dapat menggunakan Vertex Pipelines:
- Kubeflow Pipelines: Ini adalah SDK yang akan kita gunakan untuk membangun pipeline. Vertex Pipelines dapat menjalankan pipeline yang dibangun dengan Kubeflow Pipelines atau TFX.
- Vertex AI SDK: SDK ini mengoptimalkan pengalaman untuk memanggil Vertex AI API. Kita akan menggunakannya untuk menjalankan pipeline di Vertex AI.
Membuat notebook Python dan menginstal library
Pertama, dari menu Peluncur di instance Notebook Anda, buat notebook dengan memilih Python 3:

Untuk menginstal kedua layanan yang akan kita gunakan di lab ini, tetapkan terlebih dahulu flag pengguna di sel notebook:
USER_FLAG = "--user"
Kemudian jalankan kode berikut dari notebook Anda:
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
Setelah menginstal paket ini, Anda perlu memulai ulang kernel:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Selanjutnya, pastikan Anda telah menginstal versi KFP SDK dengan benar. Nilainya harus >=1,8:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
Kemudian, pastikan versi Vertex AI SDK Anda adalah >= 1.6.2:
!pip list | grep aiplatform
Menetapkan project ID dan bucket Anda
Di sepanjang lab ini, Anda akan mereferensikan Project ID Cloud dan bucket yang telah Anda buat sebelumnya. Selanjutnya, kita akan membuat variabel untuk masing-masing.
Jika tidak mengetahui project ID Anda, Anda bisa mendapatkannya dengan menjalankan kode berikut:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
Jika tidak, setel di sini:
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
Lalu buat variabel untuk menyimpan nama bucket Anda. Jika Anda membuatnya di lab ini, perintah berikut akan berfungsi. Jika tidak, Anda harus menyetelnya secara manual:
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
Mengimpor library
Tambahkan kode berikut untuk mengimpor library yang akan kita gunakan di sepanjang codelab ini:
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
Menentukan konstanta
Hal terakhir yang perlu kita lakukan sebelum membangun pipeline adalah menentukan beberapa variabel konstan. PIPELINE_ROOT adalah jalur Cloud Storage tempat artefak yang dibuat oleh pipeline kita akan ditulis. Kita menggunakan us-central1 sebagai region di sini, tetapi jika Anda menggunakan region lain saat membuat bucket, perbarui variabel REGION dalam kode di bawah ini:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Setelah menjalankan kode di atas, Anda akan melihat direktori root untuk pipeline Anda ditampilkan. Ini adalah lokasi Cloud Storage tempat artefak dari pipeline Anda akan ditulis. URL tersebut akan ditampilkan dalam format gs://YOUR-BUCKET-NAME/pipeline_root/
5. Membuat pipeline 3 langkah dengan komponen kustom
Lab ini berfokus pada pemahaman metadata dari eksekusi pipeline. Untuk melakukannya, kita memerlukan pipeline yang akan dijalankan di Vertex Pipelines, yang akan menjadi titik awal kita. Di sini kita akan menentukan pipeline 3 langkah dengan komponen kustom berikut:
get_dataframe: Mengambil data dari tabel BigQuery dan mengonversinya menjadi DataFrame Pandastrain_sklearn_model: Menggunakan Pandas DataFrame untuk melatih dan mengekspor model Scikit Learn, beserta beberapa metrikdeploy_model: Deploy model Scikit Learn yang diekspor ke endpoint di Vertex AI
Di pipeline ini, kita akan menggunakan set data Kacang kering UCI Machine Learning, dari: KOKLU, M. dan OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques."In Computers and Electronics in Agriculture, 174, 105507. DOI.
Ini adalah set data tabulasi, dan di pipeline kita akan menggunakan set data ini untuk melatih, mengevaluasi, dan men-deploy model Scikit-learn yang mengklasifikasi kacang ke dalam salah satu dari 7 jenis berdasarkan karakteristiknya. Mari mulai coding.
Membuat komponen berbasis fungsi Python
Dengan menggunakan KFP SDK, kita dapat membuat komponen berdasarkan fungsi Python. Kita akan menggunakannya untuk 3 komponen dalam pipeline ini.
Mendownload data BigQuery dan mengonversi ke CSV
Pertama, kita akan membuat komponen get_dataframe:
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
Mari kita lihat lebih dekat apa yang terjadi dalam komponen ini:
- Dekorator
@componentmengompilasi fungsi ini ke komponen saat pipeline dijalankan. Anda akan menggunakannya setiap kali Anda menulis komponen kustom. - Parameter
base_imagemenentukan image container yang akan digunakan komponen ini. - Komponen ini akan menggunakan beberapa library Python, yang kita tentukan melalui parameter
packages_to_install. - Parameter
output_component_filebersifat opsional, dan menentukan file yaml tempat komponen yang dikompilasi akan ditulis. Setelah menjalankan sel, Anda akan melihat file tersebut ditulis ke instance notebook Anda. Jika Anda ingin membagikan komponen ini kepada seseorang, Anda dapat mengirimi orang tersebut file yaml yang dihasilkan, dan kemudian dia dapat memuatnya dengan kode berikut:
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- Selanjutnya, komponen ini menggunakan library klien Python BigQuery untuk mendownload data kita dari BigQuery ke dalam DataFrame Pandas, lalu membuat artefak output data tersebut sebagai file CSV. Ini akan diteruskan sebagai input ke komponen berikutnya
Membuat komponen untuk melatih model Scikit-learn
Dalam komponen ini, kita akan mengambil CSV yang kita buat sebelumnya dan menggunakannya untuk melatih model pohon keputusan Scikit-learn. Komponen ini mengekspor model Scikit yang dihasilkan, beserta artefak Metrics yang mencakup akurasi model, framework, dan ukuran set data yang digunakan untuk melatihnya:
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
Tentukan komponen untuk mengupload dan men-deploy model ke Vertex AI
Terakhir, komponen terakhir kita akan mengambil model terlatih dari langkah sebelumnya, menguploadnya ke Vertex AI, dan men-deploy-nya ke endpoint:
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Di sini, kita menggunakan Vertex AI SDK untuk mengupload model menggunakan container bawaan untuk prediksi. Kemudian, model di-deploy ke endpoint dan URI ke resource model dan endpoint ditampilkan. Nanti dalam codelab ini, Anda akan mempelajari lebih lanjut arti menampilkan data ini sebagai artefak.
Menentukan dan mengompilasi pipeline
Setelah menentukan ketiga komponen, selanjutnya kita akan membuat definisi pipeline. Bagian ini menjelaskan cara artefak input dan output mengalir di antara langkah-langkah:
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
Kode berikut akan menghasilkan file JSON yang akan Anda gunakan untuk menjalankan pipeline:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
Mulai dua operasi pipeline
Selanjutnya, kita akan memulai dua proses pipeline. Pertama, tentukan stempel waktu yang akan digunakan untuk ID tugas pipeline:
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Ingatlah bahwa pipeline kita mengambil satu parameter saat kita menjalankannya: bq_table yang ingin kita gunakan untuk data pelatihan. Jalannya pipeline ini akan menggunakan versi yang lebih kecil dari set data beans:
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
Selanjutnya, buat eksekusi pipeline lain menggunakan versi yang lebih besar dari set data yang sama.
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
Terakhir, mulai eksekusi pipeline untuk kedua proses. Sebaiknya lakukan ini dalam dua sel notebook terpisah sehingga Anda dapat melihat output untuk setiap proses.
run1.submit()
Kemudian, mulai proses kedua:
run2.submit()
Setelah menjalankan sel ini, Anda akan melihat link untuk melihat setiap pipeline di konsol Vertex AI. Buka link tersebut untuk melihat detail selengkapnya tentang pipeline Anda:

Setelah selesai (pipeline ini memerlukan waktu sekitar 10-15 menit per eksekusi), Anda akan melihat tampilan seperti ini:

Setelah memiliki dua operasi pipeline yang selesai, Anda siap untuk mempelajari lebih lanjut artefak, metrik, dan silsilah pipeline.
6. Memahami artefak dan silsilah pipeline
Dalam grafik pipeline, Anda akan melihat kotak kecil setelah setiap langkah. Itu adalah artefak, atau output yang dihasilkan dari langkah pipeline. Ada banyak jenis artefak. Dalam pipeline khusus ini, kita memiliki artefak set data, metrik, model, dan endpoint. Klik penggeser Luaskan Artefak di bagian atas UI untuk melihat detail selengkapnya pada setiap artefak:
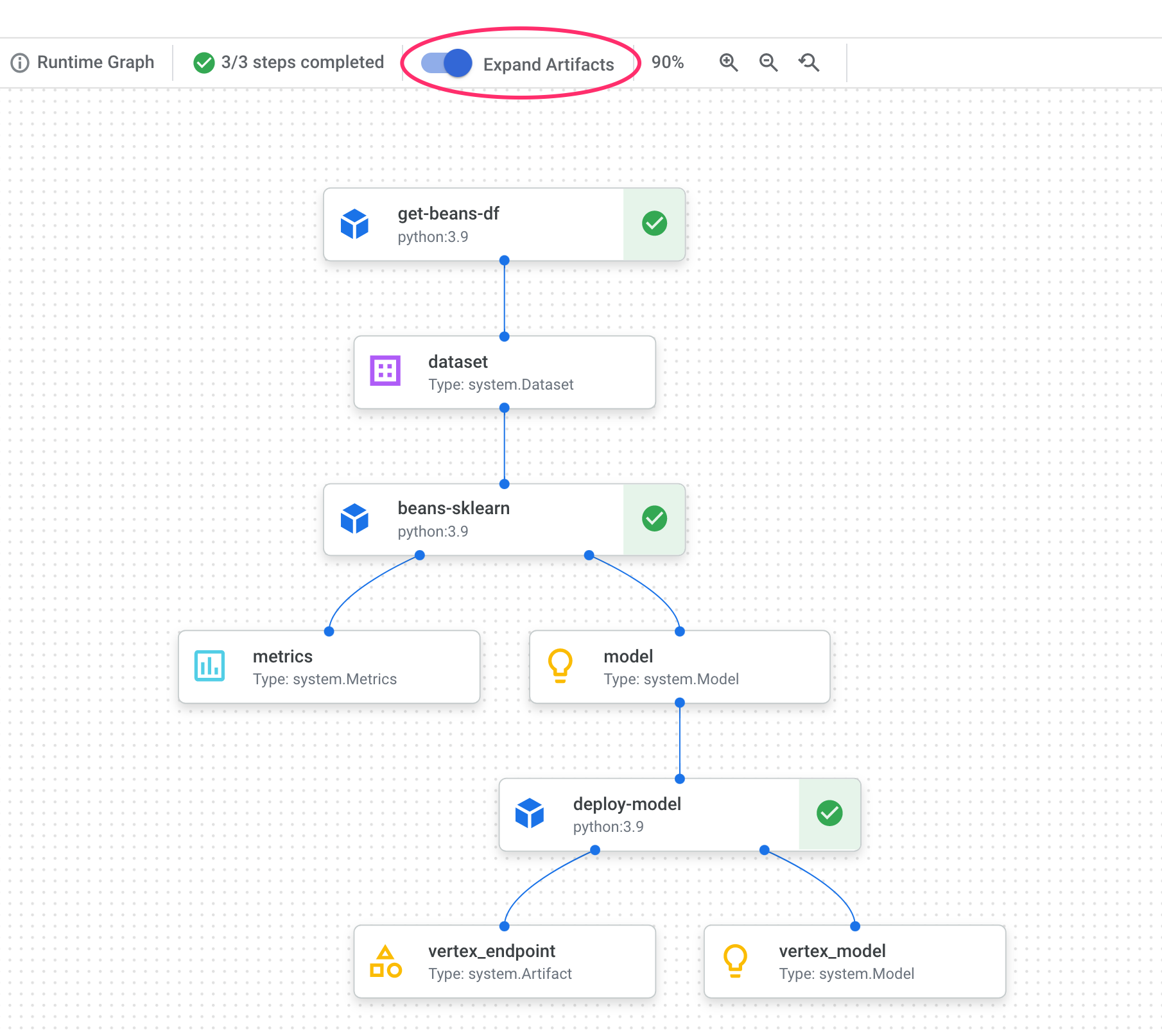
Dengan mengklik artefak, Anda akan melihat detail selengkapnya tentang artefak tersebut, termasuk URI-nya. Misalnya, mengklik artefak vertex_endpoint akan menampilkan URI tempat Anda dapat menemukan endpoint yang di-deploy tersebut di konsol Vertex AI:

Artefak Metrics memungkinkan Anda meneruskan metrik kustom yang terkait dengan langkah pipeline tertentu. Dalam komponen sklearn_train pipeline, kami mencatat metrik tentang akurasi, framework, dan ukuran set data model. Klik artefak metrik untuk melihat detail tersebut:

Setiap artefak memiliki Silsilah, yang menjelaskan artefak lain yang terhubung dengannya. Klik artefak vertex_endpoint pipeline Anda lagi, lalu klik tombol View Lineage:

Tindakan ini akan membuka tab baru tempat Anda dapat melihat semua artefak yang terhubung dengan artefak yang telah Anda pilih. Grafik silsilah Anda akan terlihat seperti ini:
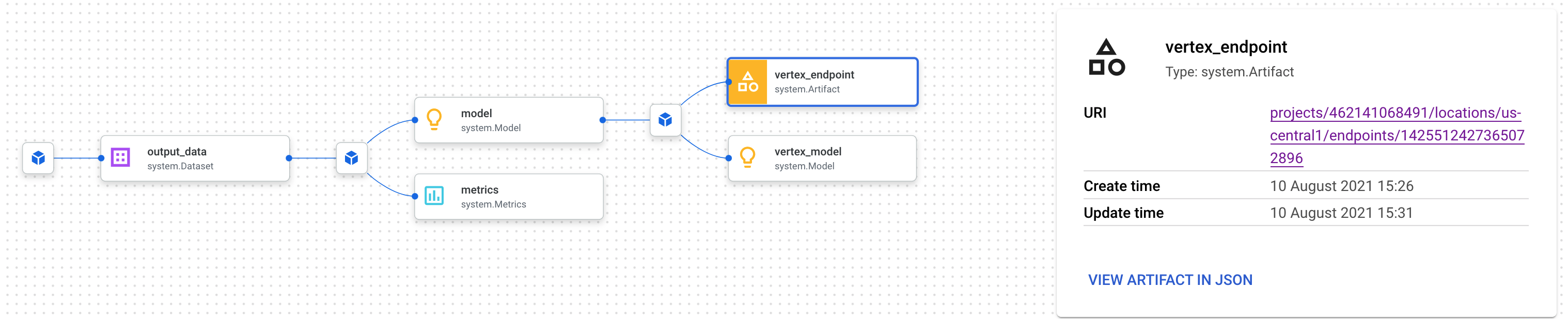
Bagian ini menunjukkan model, metrik, dan set data yang terkait dengan endpoint ini. Mengapa ini bermanfaat? Anda mungkin memiliki model yang di-deploy ke beberapa endpoint, atau perlu mengetahui set data spesifik yang digunakan untuk melatih model yang di-deploy ke endpoint yang Anda lihat. Grafik silsilah membantu Anda memahami setiap artefak dalam konteks sistem ML Anda. Anda juga dapat mengakses silsilah secara terprogram, seperti yang akan kita lihat nanti dalam codelab ini.
7. Membandingkan operasi pipeline
Kemungkinan besar satu pipeline akan dijalankan beberapa kali, mungkin dengan parameter input yang berbeda, data baru, atau oleh orang-orang di seluruh tim Anda. Untuk melacak proses pipeline, akan lebih mudah jika ada cara untuk membandingkannya menurut berbagai metrik. Di bagian ini, kita akan mempelajari dua cara untuk membandingkan eksekusi.
Membandingkan operasi di UI Pipelines
Di Konsol Cloud, buka dasbor Pipelines. Bagian ini memberikan ringkasan setiap proses pipeline yang telah Anda jalankan. Periksa dua operasi terakhir, lalu klik tombol Bandingkan di bagian atas:

Tindakan ini akan mengarahkan kita ke halaman tempat kita dapat membandingkan parameter input dan metrik untuk setiap proses yang telah kita pilih. Untuk kedua proses ini, perhatikan perbedaan tabel BigQuery, ukuran set data, dan nilai akurasi:

Anda dapat menggunakan fungsi UI ini untuk membandingkan lebih dari dua operasi, dan bahkan operasi dari pipeline yang berbeda.
Membandingkan operasi dengan Vertex AI SDK
Dengan banyaknya eksekusi pipeline, Anda mungkin menginginkan cara untuk mendapatkan metrik perbandingan ini secara terprogram untuk mempelajari lebih dalam detail metrik dan membuat visualisasi.
Anda dapat menggunakan metode aiplatform.get_pipeline_df() untuk mengakses metadata yang dijalankan. Di sini, kita akan mendapatkan metadata untuk dua proses terakhir dari pipeline yang sama dan memuatnya ke dalam DataFrame Pandas. Parameter pipeline di sini merujuk pada nama yang kami berikan pada pipeline dalam definisi pipeline:
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
Saat mencetak DataFrame, Anda akan melihat sesuatu seperti ini:

Di sini, kita hanya menjalankan pipeline dua kali, tetapi Anda dapat membayangkan berapa banyak metrik yang akan Anda miliki dengan lebih banyak eksekusi. Selanjutnya, kita akan membuat visualisasi kustom dengan matplotlib untuk melihat hubungan antara akurasi model dan jumlah data yang digunakan untuk pelatihan.
Jalankan kode berikut dalam sel notebook baru:
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
Anda akan melihat yang seperti ini:

8. Mengkueri metrik pipeline
Selain mendapatkan DataFrame semua metrik pipeline, Anda mungkin ingin membuat kueri artefak yang dibuat dalam sistem ML Anda secara terprogram. Dari sana, Anda dapat membuat dasbor kustom atau membiarkan orang lain di organisasi Anda mendapatkan detail tentang artefak tertentu.
Mendapatkan semua artefak Model
Untuk mengkueri artefak dengan cara ini, kita akan membuat MetadataServiceClient:
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
Selanjutnya, kita akan membuat permintaan list_artifacts ke endpoint tersebut dan meneruskan filter yang menunjukkan artefak mana yang kita inginkan dalam respons. Pertama, mari kita dapatkan semua artefak dalam project kita yang merupakan model. Untuk melakukannya, jalankan perintah berikut di notebook Anda:
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
Respons model_artifacts yang dihasilkan berisi objek yang dapat diiterasi untuk setiap artefak model dalam project Anda, beserta metadata terkait untuk setiap model.
Memfilter objek dan menampilkannya dalam DataFrame
Akan lebih mudah jika kita dapat memvisualisasikan kueri artefak yang dihasilkan dengan lebih mudah. Selanjutnya, mari kita dapatkan semua artefak yang dibuat setelah 10 Agustus 2021 dengan status LIVE. Setelah menjalankan permintaan ini, kita akan menampilkan hasilnya dalam Pandas DataFrame. Pertama, jalankan permintaan:
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
Kemudian, tampilkan hasilnya dalam DataFrame:
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
Anda akan melihat sesuatu seperti ini:

Anda juga dapat memfilter artefak berdasarkan kriteria lain selain yang Anda coba di sini.
Dengan demikian, Anda telah menyelesaikan lab ini.
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Gunakan Kubeflow Pipelines SDK untuk membangun pipeline ML yang membuat set data di Vertex AI, serta melatih dan men-deploy model Scikit-learn kustom pada set data tersebut
- Menulis komponen pipeline kustom yang menghasilkan artefak dan metadata
- Membandingkan operasi Vertex Pipelines, baik di Cloud Console maupun secara terprogram
- Melacak silsilah untuk artefak yang dihasilkan pipeline
- Kueri metadata operasi pipeline
Untuk mempelajari lebih lanjut berbagai bagian Vertex, lihat dokumentasinya.
9. Pembersihan
Agar tidak ditagih, sebaiknya hapus resource yang dibuat selama lab ini.
Menghentikan atau menghapus instance Notebooks
Jika Anda ingin terus menggunakan notebook yang Anda buat di lab ini, sebaiknya nonaktifkan notebook tersebut saat tidak digunakan. Dari UI Notebook di Konsol Cloud Anda, pilih notebook, lalu pilih Stop. Jika Anda ingin menghapus instance sepenuhnya, pilih Hapus:

Menghapus endpoint Vertex AI
Untuk menghapus endpoint yang Anda deploy, buka bagian Endpoints di konsol Vertex AI, lalu klik ikon hapus:

Menghapus bucket Cloud Storage
Untuk menghapus Bucket Penyimpanan menggunakan menu Navigasi di Cloud Console, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus:
