
1. Panoramica
In questo lab imparerai ad analizzare i metadati delle esecuzioni di Vertex Pipelines con Vertex ML Metadata.
Cosa imparerai
Al termine del corso sarai in grado di:
- Utilizza l'SDK Kubeflow Pipelines per creare una pipeline ML che crea un set di dati in Vertex AI e addestra ed esegue il deployment di un modello Scikit-learn personalizzato su questo set di dati
- Scrivere componenti della pipeline personalizzati che generano artefatti e metadati
- Confronta le esecuzioni di Vertex Pipelines, sia nella console Google Cloud che a livello di programmazione
- Tracciare la derivazione degli artefatti generati dalla pipeline
- Esegui query sui metadati di esecuzione della pipeline
Il costo totale per eseguire questo lab su Google Cloud è di circa 2$.
2. Introduzione a Vertex AI
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI.
Oltre ai servizi di addestramento e deployment dei modelli, Vertex AI include anche una varietà di prodotti MLOps, tra cui Vertex Pipelines, ML Metadata, Model Monitoring, Feature Store e altri. Puoi vedere tutte le offerte di prodotti Vertex AI nel diagramma seguente.
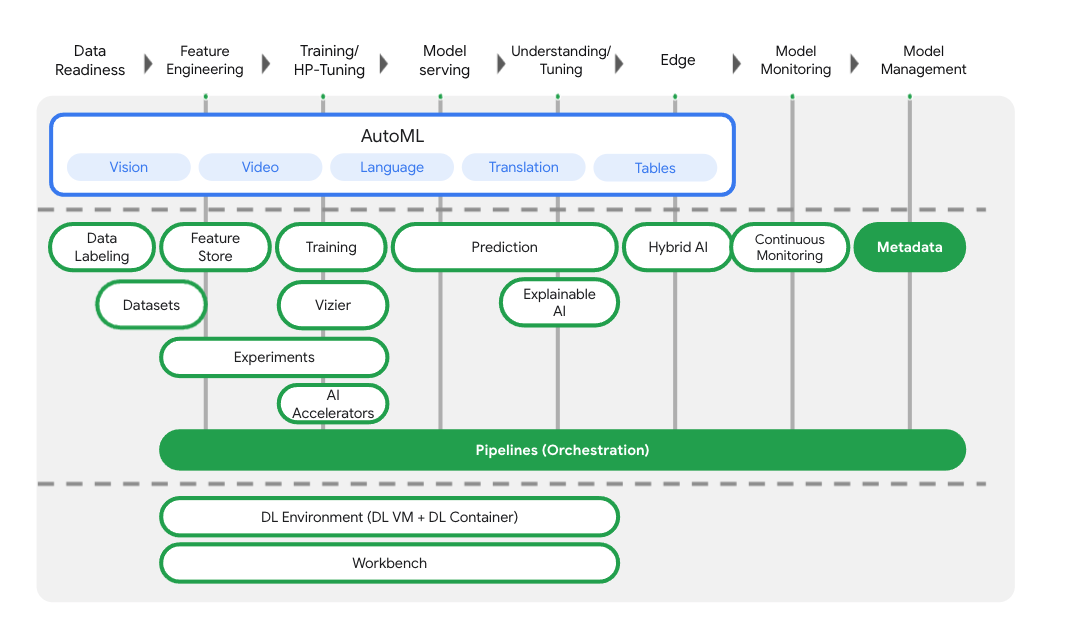
Questo lab si concentra su Vertex Pipelines e Vertex ML Metadata.
In caso di feedback su Vertex AI, consulta la pagina di assistenza.
Perché le pipeline ML sono utili?
Prima di entrare nel dettaglio dell'argomento, capiamo innanzitutto perché potresti voler utilizzare una pipeline. Immagina di creare un workflow ML che includa l'elaborazione dei dati, l'addestramento di un modello, l'ottimizzazione degli iperparametri, la valutazione e il deployment del modello. Ciascuno di questi passaggi può avere dipendenze diverse, che potrebbero diventare difficili da gestire se consideri l'intero workflow come un monolite. Quando inizi a scalare il tuo processo ML, potresti voler condividere il tuo workflow ML con altri membri del tuo team in modo che possano eseguirlo e contribuire al codice. Senza un processo affidabile e riproducibile, questo può diventare difficile. Con le pipeline, ogni passaggio del processo ML è un container a sé stante. Ciò consente di sviluppare passaggi in modo indipendente e tenere traccia dell'input e output di ciascun passaggio in modo riproducibile. Puoi anche pianificare o attivare esecuzioni della pipeline in base ad altri eventi nel tuo ambiente Cloud, ad esempio l'avvio di un'esecuzione della pipeline quando sono disponibili nuovi dati di addestramento.
In breve: le pipeline ti aiutano ad automatizzare e riprodurre il tuo workflow ML.
3. Configurazione dell'ambiente cloud
Per eseguire questo codelab, devi avere un progetto Google Cloud Platform con la fatturazione abilitata. Per creare un progetto, segui le istruzioni riportate qui.
Avvia Cloud Shell
In questo lab lavorerai in una sessione di Cloud Shell, un interprete di comandi ospitato da una macchina virtuale in esecuzione nel cloud di Google. Potresti eseguire facilmente questa sezione in locale sul tuo computer, ma l'utilizzo di Cloud Shell offre a chiunque l'accesso a un'esperienza riproducibile in un ambiente coerente. Dopo il lab, puoi riprovare questa sezione sul tuo computer.

Attiva Cloud Shell
In alto a destra della console Cloud, fai clic sul pulsante seguente per attivare Cloud Shell:

Se non hai mai avviato Cloud Shell, viene visualizzata una schermata intermedia (sotto la piega) che ne descrive le funzionalità. In questo caso, fai clic su Continua e non comparirà più. Ecco come si presenta la schermata intermedia:
Bastano pochi istanti per eseguire il provisioning e connettersi a Cloud Shell.

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui hai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Gran parte del lavoro per questo codelab, se non tutto, può essere svolto semplicemente con un browser o con Chromebook.
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo ID progetto.
Esegui questo comando in Cloud Shell per verificare che l'account sia autenticato:
gcloud auth list
Output comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto:
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
In caso contrario, puoi impostarlo con questo comando:
gcloud config set project <PROJECT_ID>
Output comando
Updated property [core/project].
Cloud Shell include alcune variabili di ambiente, tra cui GOOGLE_CLOUD_PROJECT che contiene il nome del nostro progetto Cloud corrente. La utilizzeremo in vari punti di questo lab. Puoi visualizzarla eseguendo questo comando:
echo $GOOGLE_CLOUD_PROJECT
Abilita API
Nei passaggi successivi vedrai dove (e perché) sono necessari questi servizi, ma per il momento esegui questo comando per concedere al tuo progetto l'accesso ai servizi Compute Engine, Container Registry e Vertex AI:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
Dovrebbe essere visualizzato un messaggio di operazione riuscita simile a questo:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Crea un bucket Cloud Storage
Per eseguire un job di addestramento su Vertex AI, abbiamo bisogno di un bucket di archiviazione in cui archiviare gli asset salvati nel modello. Il bucket deve essere regionale. Qui utilizziamo us-central, ma puoi anche usare un'altra regione (basta sostituirla in questo lab). Se hai già un bucket, puoi saltare questo passaggio.
Esegui questi comandi nel terminale Cloud Shell per creare un bucket:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
A questo punto concediamo al nostro service account Compute l'accesso al bucket. In questo modo, Vertex Pipelines disporrà delle autorizzazioni necessarie per scrivere file nel bucket. Esegui questo comando per aggiungere l'autorizzazione:
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
crea un'istanza di Vertex AI Workbench
Nella sezione Vertex AI della console Cloud, fai clic su Workbench:

Da qui, in Blocchi note gestiti dall'utente, fai clic su Nuovo blocco note:

Poi seleziona il tipo di istanza TensorFlow Enterprise 2.3 (con LTS) senza GPU:

Utilizza le opzioni predefinite e poi fai clic su Crea.
Aprire il notebook
Una volta creata l'istanza, seleziona Apri JupyterLab:

4. Configurazione di Vertex Pipelines
Per utilizzare Vertex Pipelines, devi installare alcune librerie aggiuntive:
- Kubeflow Pipelines: questo è l'SDK che utilizzeremo per creare la pipeline. Vertex Pipelines supporta l'esecuzione di pipeline create con Kubeflow Pipelines o TFX.
- SDK Vertex AI: questo SDK ottimizza l'esperienza di chiamata dell'API Vertex AI. Lo utilizzeremo per eseguire la pipeline su Vertex AI.
Crea un notebook Python e installa le librerie
Innanzitutto, dal menu Avvio app nell'istanza del notebook, crea un notebook selezionando Python 3:

Per installare entrambi i servizi che utilizzeremo in questo lab, imposta prima il flag utente in una cella del notebook:
USER_FLAG = "--user"
Poi esegui questo codice dal notebook:
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
Dopo aver installato questi pacchetti, devi riavviare il kernel:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Il passaggio successivo consiste nel verificare di aver installato correttamente la versione dell'SDK KFP. Deve essere >=1,8:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
Poi verifica che la versione dell'SDK Vertex AI sia >= 1.6.2:
!pip list | grep aiplatform
Imposta l'ID progetto e il bucket
Durante questo lab, farai riferimento all'ID progetto Cloud e al bucket che hai creato in precedenza. Poi creeremo le variabili per ciascuno di questi.
Se non conosci l'ID progetto, potresti recuperarlo eseguendo questo comando:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
In caso contrario, impostalo qui:
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
Adesso crea una variabile per archiviare il nome del bucket. Se l'hai creato in questo lab, funzionerà quanto segue. In caso contrario, dovrai impostarlo manualmente:
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
Importa le librerie
Aggiungi quanto segue per importare le librerie che utilizzeremo in questo codelab:
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
Definisci le costanti
L'ultima cosa da fare prima di creare la pipeline è definire alcune variabili delle costanti. PIPELINE_ROOT è il percorso Cloud Storage in cui verranno scritti gli artefatti creati dalla pipeline. Qui utilizziamo us-central1 come regione, ma se hai utilizzato una regione diversa quando hai creato il bucket, aggiorna la variabile REGION nel codice riportato di seguito:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
Dopo aver eseguito il codice in alto, dovresti visualizzare la directory principale della pipeline. Questa è la posizione di Cloud Storage in cui verranno scritti gli artefatti della pipeline. Sarà nel formato gs://YOUR-BUCKET-NAME/pipeline_root/
5. Creazione di una pipeline in tre passaggi con componenti personalizzati
Questo lab si concentra sulla comprensione dei metadati delle esecuzioni della pipeline. Per farlo, avremo bisogno di una pipeline da eseguire su Vertex Pipelines, da cui inizieremo. Qui definiremo una pipeline in tre passaggi con i seguenti componenti personalizzati:
get_dataframe: recupera i dati da una tabella BigQuery e convertili in un DataFrame Pandastrain_sklearn_model: utilizza il DataFrame Pandas per addestrare ed esportare un modello Scikit Learn, insieme ad alcune metrichedeploy_model: Esegui il deployment del modello Scikit-Learn esportato in un endpoint in Vertex AI
In questa pipeline, utilizzeremo il set di dati UCI Machine Learning Dry Beans da KOKLU, M. e OZKAN, I.A., (2020), "Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques."In Computers and Electronics in Agriculture, 174, 105507. DOI.
Questo è un set di dati tabulare che utilizzeremo nella pipeline per addestrare, valutare ed eseguire il deployment di un modello Scikit-learn che classifica i bean in una di sette tipologie in base alle loro caratteristiche. Iniziamo a programmare.
Crea componenti basati su funzioni Python
Utilizzando l'SDK KFP, possiamo creare componenti basati su funzioni Python. Lo utilizzeremo per i tre componenti di questa pipeline.
Scarica i dati di BigQuery e convertili in CSV
Per prima cosa, creiamo il componente get_dataframe:
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
Diamo un'occhiata più da vicino a cosa succede in questo componente:
- Il decorator
@componentcompila questa funzione in un componente quando viene eseguita la pipeline. Lo utilizzerai ogni volta che scrivi un componente personalizzato. - Il parametro
base_imagespecifica l'immagine container che verrà utilizzata da questo componente. - Questo componente utilizzerà alcune librerie Python, che specifichiamo tramite il parametro
packages_to_install. - Il parametro
output_component_fileè facoltativo e specifica il file YAML in cui scrivere il componente compilato. Dopo aver eseguito la cella, dovresti vedere il file scritto nell'istanza del notebook. Per condividere questo componente con qualcuno, potresti inviare il file YAML generato e chiedere di caricarlo con il seguente comando:
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- Successivamente, questo componente utilizza la libreria client Python di BigQuery per scaricare i dati da BigQuery in un DataFrame Pandas e poi crea un artefatto di output di questi dati come file CSV. che verrà passato come input al componente successivo.
Crea un componente per addestrare un modello Scikit-learn
In questo componente prenderemo il file CSV generato in precedenza e lo utilizzeremo per addestrare un modello ad albero decisionale Scikit-learn. Questo componente esporta il modello Scikit risultante, insieme a un artefatto Metrics che include l'accuratezza, il framework e le dimensioni del set di dati utilizzato per addestrarlo:
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
Definisci un componente per caricare ed eseguire il deployment del modello in Vertex AI
Infine, l'ultimo componente prenderà il modello addestrato del passaggio precedente, lo caricherà su Vertex AI ed eseguirà il deployment su un endpoint:
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Qui utilizziamo l'SDK Vertex AI per caricare il modello utilizzando un container predefinito per la previsione. Poi esegue il deployment del modello su un endpoint e restituisce gli URI alle risorse del modello e dell'endpoint. Più avanti in questo codelab scoprirai di più su cosa significa restituire questi dati come artefatti.
Definisci e compila la pipeline
Ora che abbiamo definito i tre componenti, creiamo la definizione della pipeline. Descrive il flusso degli artefatti di input e output tra i passaggi:
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
Il seguente comando genererà un file JSON che utilizzerai per eseguire la pipeline:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
Avvia due esecuzioni pipeline
Ora avvieremo due esecuzioni della pipeline. Innanzitutto, definiamo un timestamp da utilizzare per gli ID job della pipeline:
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Ricorda che la nostra pipeline accetta un parametro quando la eseguiamo: il bq_table che vogliamo utilizzare per i dati di addestramento. Questa esecuzione della pipeline utilizzerà una versione più piccola del set di dati beans:
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
Successivamente, crea un'altra esecuzione della pipeline utilizzando una versione più grande dello stesso set di dati.
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
Infine, avvia le esecuzioni della pipeline per entrambe le esecuzioni. È meglio farlo in due celle del notebook separate per poter visualizzare l'output di ogni esecuzione.
run1.submit()
Quindi, avvia la seconda esecuzione:
run2.submit()
Dopo aver eseguito questa cella, vedrai un link per visualizzare ogni pipeline nella console Vertex AI. Apri questo link per visualizzare ulteriori dettagli sulla pipeline:

Al termine (questa pipeline richiede circa 10-15 minuti per l'esecuzione), vedrai un risultato simile a questo:

Ora che hai completato due esecuzioni della pipeline, puoi esaminare più da vicino gli artefatti, le metriche e la derivazione della pipeline.
6. Informazioni sugli artefatti e sulla derivazione della pipeline
Nel grafico della pipeline, noterai dei piccoli riquadri dopo ogni passaggio. Si tratta di artefatti, ovvero output generati da un passaggio della pipeline. Esistono molti tipi di artefatti. In questa pipeline specifica abbiamo artefatti di set di dati, metriche, modello ed endpoint. Fai clic sul cursore Espandi artefatti nella parte superiore dell'interfaccia utente per visualizzare ulteriori dettagli su ciascun artefatto:
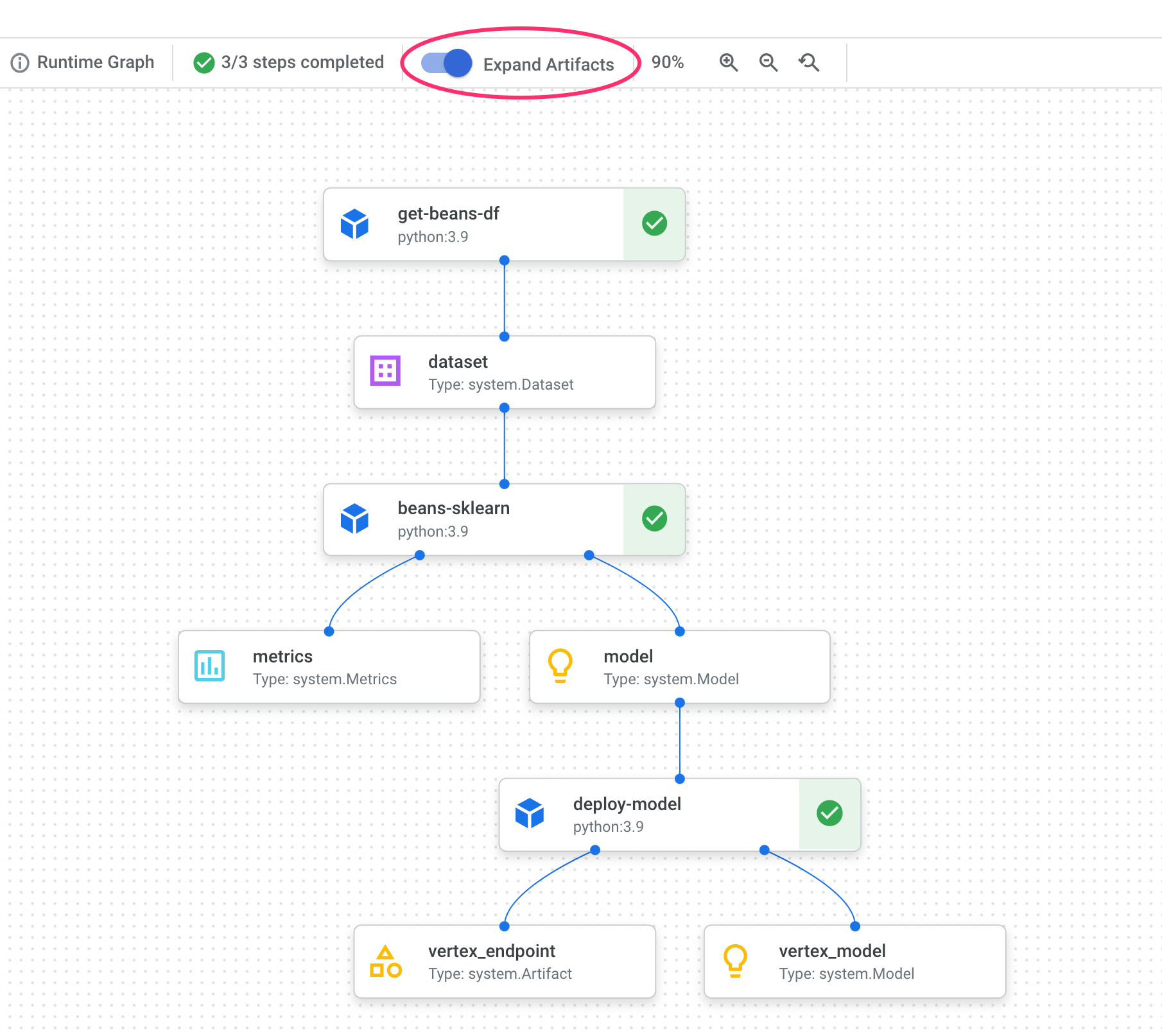
Se fai clic su un artefatto, vengono visualizzati ulteriori dettagli, incluso il relativo URI. Ad esempio, se fai clic sull'artefatto vertex_endpoint, viene visualizzato l'URI in cui puoi trovare l'endpoint di cui è stato eseguito il deployment nella console Vertex AI:

Un artefatto Metrics consente di trasmettere metriche personalizzate associate a un particolare passaggio della pipeline. Nel componente sklearn_train della nostra pipeline, abbiamo registrato le metriche relative ad accuratezza, framework e dimensioni del set di dati del nostro modello. Fai clic sull'artefatto delle metriche per visualizzare questi dettagli:

Ogni artefatto ha una derivazione, che descrive gli altri artefatti a cui è collegato. Fai di nuovo clic sull'artefatto vertex_endpoint della pipeline, quindi sul pulsante Visualizza derivazione:

Si aprirà una nuova scheda in cui potrai visualizzare tutti gli artefatti collegati a quello selezionato. Il grafico della discendenza sarà simile a questo:

In questo modo vengono visualizzati il modello, le metriche e il set di dati associati a questo endpoint. Perché è utile? Potresti avere un modello di cui è stato eseguito il deployment in più endpoint o devi conoscere il set di dati specifico utilizzato per addestrare il modello di cui è stato eseguito il deployment nell'endpoint che stai esaminando. Il grafico della derivazione ti aiuta a comprendere ogni artefatto nel contesto del resto del sistema ML. Puoi anche accedere alla derivazione in modo programmatico, come vedremo più avanti in questo codelab.
7. Confronto tra le esecuzioni delle pipeline
È probabile che una singola pipeline venga eseguita più volte, magari con parametri di input diversi, nuovi dati o da persone del tuo team. Per tenere traccia delle esecuzioni della pipeline, sarebbe utile avere un modo per confrontarle in base a varie metriche. In questa sezione esploreremo due modi per confrontare le corse.
Confrontare le esecuzioni nell'interfaccia utente di Pipelines
Nella console Google Cloud, vai alla dashboard delle pipeline. Fornisce una panoramica di ogni esecuzione della pipeline che hai eseguito. Controlla le ultime due esecuzioni e poi fai clic sul pulsante Confronta in alto:

Si apre una pagina in cui possiamo confrontare i parametri di input e le metriche per ciascuna delle esecuzioni selezionate. Per queste due esecuzioni, nota le diverse tabelle BigQuery, le dimensioni dei set di dati e i valori di accuratezza:

Puoi utilizzare questa funzionalità dell'interfaccia utente per confrontare più di due esecuzioni e persino esecuzioni di pipeline diverse.
Confrontare le esecuzioni con l'SDK Vertex AI
Con molte esecuzioni della pipeline, potresti voler ottenere queste metriche di confronto in modo programmatico per analizzare più in dettaglio le metriche e creare visualizzazioni.
Puoi utilizzare il metodo aiplatform.get_pipeline_df() per accedere ai metadati dell'esecuzione. Qui recupereremo i metadati per le ultime due esecuzioni della stessa pipeline e li caricheremo in un DataFrame Pandas. Il parametro pipeline qui si riferisce al nome che abbiamo dato alla nostra pipeline nella definizione della pipeline:
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
Quando stampi il DataFrame, vedrai qualcosa di simile a questo:

Qui abbiamo eseguito la pipeline solo due volte, ma puoi immaginare quante metriche avresti con più esecuzioni. Successivamente, creeremo una visualizzazione personalizzata con matplotlib per vedere la relazione tra l'accuratezza del modello e la quantità di dati utilizzati per l'addestramento.
Esegui il seguente codice in una nuova cella del notebook:
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
Il risultato dovrebbe essere simile a questo:

8. Esecuzione di query sulle metriche pipeline
Oltre a ottenere un DataFrame di tutte le metriche della pipeline, potresti voler eseguire query a livello di programmazione sugli artefatti creati nel tuo sistema ML. Da qui puoi creare una dashboard personalizzata o consentire ad altri membri della tua organizzazione di ottenere dettagli su artefatti specifici.
Recupero di tutti gli artefatti del modello
Per eseguire query sugli artefatti in questo modo, creeremo un MetadataServiceClient:
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
Successivamente, invieremo una richiesta list_artifacts a questo endpoint e passeremo un filtro che indica gli artefatti che vorremmo nella nostra risposta. Innanzitutto, recuperiamo tutti gli artefatti del progetto che sono modelli. Per farlo, esegui questo comando nel notebook:
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
La risposta model_artifacts risultante contiene un oggetto iterabile per ogni artefatto del modello nel progetto, insieme ai metadati associati per ogni modello.
Filtrare gli oggetti e visualizzarli in un DataFrame
Sarebbe utile poter visualizzare più facilmente la query dell'artefatto risultante. Successivamente, recuperiamo tutti gli artefatti creati dopo il 10 agosto 2021 con stato LIVE. Dopo aver eseguito questa richiesta, mostreremo i risultati in un DataFrame Pandas. Innanzitutto, esegui la richiesta:
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
Quindi, visualizza i risultati in un DataFrame:
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
Visualizzerai un messaggio simile a questo:

Puoi anche filtrare gli artefatti in base ad altri criteri oltre a quelli che hai provato qui.
Con questo, hai completato il lab.
🎉 Congratulazioni! 🎉
Hai imparato come utilizzare Vertex AI per:
- Utilizza l'SDK Kubeflow Pipelines per creare una pipeline ML che crea un set di dati in Vertex AI e addestra ed esegue il deployment di un modello Scikit-learn personalizzato su questo set di dati
- Scrivere componenti della pipeline personalizzati che generano artefatti e metadati
- Confronta le esecuzioni di Vertex Pipelines, sia nella console Google Cloud che a livello di programmazione
- Tracciare la derivazione degli artefatti generati dalla pipeline
- Esegui query sui metadati di esecuzione della pipeline
Per saperne di più sulle diverse parti di Vertex, consulta la documentazione.
9. Esegui la pulizia
Per evitare addebiti, ti consigliamo di eliminare le risorse create durante questo lab.
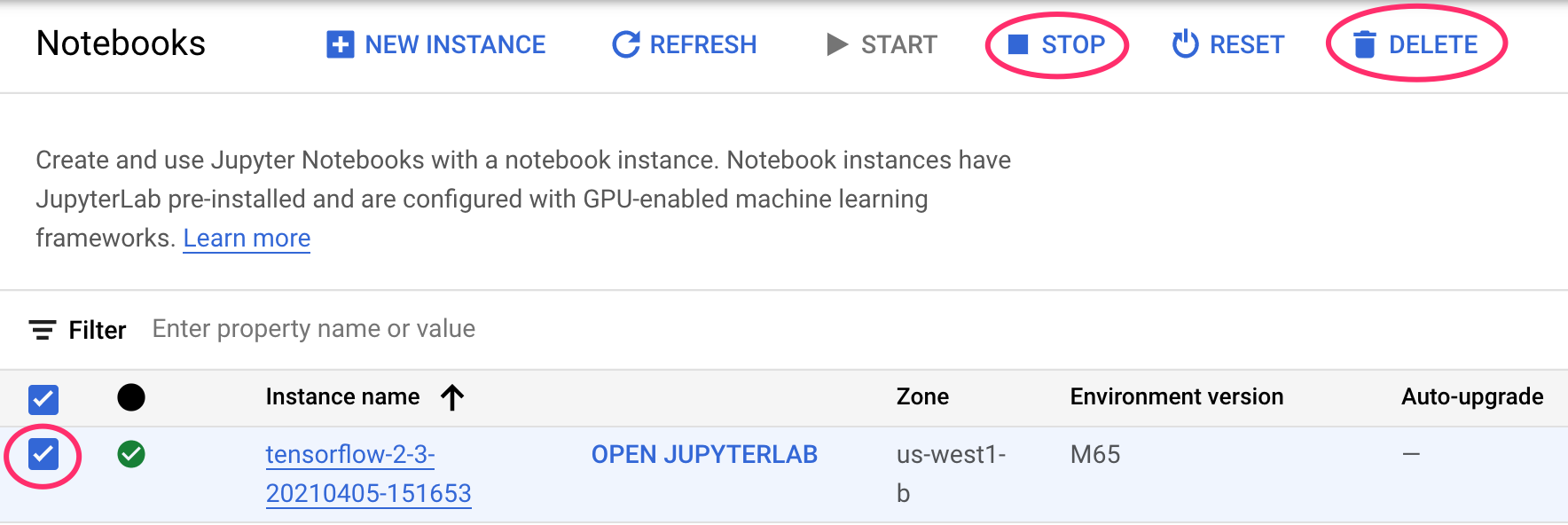
Interrompere o eliminare l'istanza di Notebooks
Se vuoi continuare a utilizzare il blocco note creato in questo lab, ti consigliamo di disattivarlo quando non lo usi. Dall'interfaccia utente di Notebooks nella console Cloud, seleziona il blocco note, quindi seleziona Interrompi. Se vuoi eliminare completamente l'istanza, seleziona Elimina:
Elimina gli endpoint Vertex AI
Per eliminare l'endpoint di cui hai eseguito il deployment, vai alla sezione Endpoint della console Vertex AI e fai clic sull'icona di eliminazione:

Elimina il bucket Cloud Storage
Per eliminare il bucket di archiviazione, utilizza il menu di navigazione nella console Google Cloud, vai a Storage, seleziona il bucket e fai clic su Elimina:
