
1. 概要
このラボでは、Vertex ML Metadata を使用して Vertex Pipelines の実行からメタデータを分析する方法について学習します。
学習内容
次の方法を学習します。
- Kubeflow Pipelines SDK を使用して、Vertex AI にデータセットを作成し、そのデータセットでカスタム Scikit-learn モデルをトレーニングしてデプロイする ML パイプラインを構築する
- アーティファクトとメタデータを生成するカスタム パイプライン コンポーネントを作成する
- Cloud コンソールとプログラムの両方で Vertex Pipelines の実行を比較する
- パイプライン生成アーティファクトのリネージを追跡する
- パイプライン実行メタデータをクエリする
このラボを Google Cloud で実行するための総費用は約 $2 です。
2. Vertex AI の概要
このラボでは、Google Cloud で利用できる最新の AI プロダクトを使用します。Vertex AI は Google Cloud 全体の ML サービスを統合してシームレスな開発エクスペリエンスを提供します。以前は、AutoML でトレーニングしたモデルやカスタムモデルにそれぞれ個別のサービスを介してアクセスする必要がありましたが、Vertex AI は、これらの個別のサービスを他の新しいプロダクトとともに 1 つの API へと結合します。既存のプロジェクトを Vertex AI に移行することもできます。
Vertex AI には、モデルのトレーニングとデプロイ サービスに加え、Vertex Pipelines、ML Metadata、Model Monitoring、Feature Store など、さまざまな MLOps プロダクトが含まれています。以下の図ですべての Vertex AI プロダクトを確認できます。

このラボでは、Vertex Pipelines と Vertex ML Metadata に焦点を当てます。
Vertex AI に関するフィードバックがございましたら、サポートページをご覧ください。
ML パイプラインはなぜ有用か?
本題に入る前に、なぜパイプラインを使用するのかについて理解しておきましょう。データの処理、モデルのトレーニング、ハイパーパラメータのチューニング、評価、モデルのデプロイを含む ML ワークフローを構築しているとします。これらのステップにはそれぞれ異なる依存関係があり、ワークフロー全体をモノリスとして扱うと、扱いづらくなる場合があります。また、ML プロセスをスケーリングする際は、チームの他のメンバーがワークフローを実行し、コーディングに参加できるように、ML ワークフローを共有したいところですが、信頼性と再現性のあるプロセスがなければ困難です。パイプラインでは、ML プロセスの各ステップがそれぞれのコンテナとなります。これにより、ステップを独立して開発し、各ステップからの入力と出力を再現可能な方法で追跡できます。また、新しいトレーニング データが利用可能になったらパイプラインの実行を開始するなど、クラウド環境内の他のイベントに基づいてパイプラインの実行をスケジュールまたはトリガーすることもできます。
要約: パイプラインを使用すると、ML ワークフローを自動化し、再現できます。
3. クラウド環境の設定
この Codelab を実行するには、課金が有効になっている Google Cloud Platform プロジェクトが必要です。プロジェクトを作成するには、こちらの手順を行ってください。
Cloud Shell の起動
このラボでは、Cloud Shell セッションで作業します。Cloud Shell は、Google のクラウド内で実行されている仮想マシンによってホストされたコマンド インタープリタです。このセクションは、パソコンでもローカルで簡単に実行できますが、Cloud Shell を使用することで、誰もが一貫した環境での再現可能な操作性を利用できるようになります。本ラボの後、このセクションをパソコン上で再度実行してみてください。

Cloud Shell をアクティブにする
Cloud コンソールの右上にある次のボタンをクリックして、Cloud Shell をアクティブにします。

Cloud Shell を初めて起動した場合は、その内容を説明する画面が(スクロールしなければ見えない位置に)表示されます。その場合は、[続行] をクリックしてください(以後表示されなくなります)。この中間画面は次のようになります。

すぐにプロビジョニングが実行され、Cloud Shell に接続されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。このコードラボでの作業のほとんどは、ブラウザまたは Chromebook から実行できます。
Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自のプロジェクト ID が設定されていることがわかります。
Cloud Shell で次のコマンドを実行して、認証されたことを確認します。
gcloud auth list
コマンド出力
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
上記のようになっていない場合は、次のコマンドで設定できます。
gcloud config set project <PROJECT_ID>
コマンド出力
Updated property [core/project].
Cloud Shell には、現在のクラウド プロジェクトの名前が格納されている GOOGLE_CLOUD_PROJECT など、いくつかの環境変数があります。本ラボではさまざまな場所でこれを使用します。次を実行すると確認できます。
echo $GOOGLE_CLOUD_PROJECT
API を有効にする
これらのサービスがどんな場面で(なぜ)必要になるのかは、後の手順でわかります。とりあえず、次のコマンドを実行して Compute Engine、Container Registry、Vertex AI の各サービスへのアクセス権をプロジェクトに付与します。
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
成功すると次のようなメッセージが表示されます。
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
Cloud Storage バケットを作成する
Vertex AI でトレーニング ジョブを実行するには、保存対象のモデルアセットを格納するストレージ バケットが必要です。これはリージョンのバケットである必要があります。ここでは us-central を使用しますが、別のリージョンを使用することもできます(その場合はラボ内の該当箇所をすべて置き換えてください)。すでにバケットがある場合は、この手順を省略できます。
Cloud Shell で次のコマンドを実行して、バケットを作成します。
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
次に、このバケットへのアクセス権をコンピューティング サービス アカウントに付与します。こうすることで、Vertex Pipelines にこのバケットへのファイルの書き込みに必要な権限を付与できます。次のコマンドを実行してこの権限を付与します。
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
Vertex AI Workbench インスタンスを作成する
Cloud Console の [Vertex AI] セクションで [ワークベンチ] をクリックします。
[ユーザー管理のノートブック] で、[新しいノートブック] をクリックします。

次に、GPU なしの TensorFlow Enterprise 2.3(LTS 版)インスタンス タイプを選択します。

デフォルトのオプションを使用して、[作成] をクリックします。
ノートブックを開く
インスタンスが作成されたら、[JUPYTERLAB を開く] を選択します。

4. Vertex Pipelines の設定
Vertex Pipelines を使用するためには、いくつかのライブラリを追加でインストールする必要があります。
- Kubeflow Pipelines: パイプラインの構築に使用する SDK です。Vertex Pipelines は、Kubeflow Pipelines と TFX の両方で構築されたパイプラインの実行をサポートします。
- Vertex AI SDK: この SDK は、Vertex AI API の呼び出しエクスペリエンスを最適化します。これを使用して、Vertex AI でパイプラインを実行します。
Python ノートブックを作成してライブラリをインストールする
まず、ノートブック インスタンスのランチャー メニューから [Python 3] を選択して、ノートブックを作成します。

このラボで使用する両方のサービスをインストールするために、最初にノートブック セルでユーザーフラグを設定します。
USER_FLAG = "--user"
続いて、ノートブックから次のコードを実行します。
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
これらのパッケージをインストールした後、カーネルを再起動する必要があります。
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
次に、KFP SDK のバージョンが正しくインストールされていることを確認します。1.8 以上である必要があります。
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
次に、Vertex AI SDK のバージョンが 1.6.2 以降であることを確認します。
!pip list | grep aiplatform
プロジェクト ID とバケットを設定する
このラボ全体を通じて、自分のクラウド プロジェクト ID と前に作成したバケットを参照します。以下でこれらを格納する変数をそれぞれ作成します。
プロジェクト ID がわからない場合は、次のコードを実行して取得できる可能性があります。
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
それ以外の場合は、こちらで設定します。
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
次に、バケット名を格納する変数を作成します。このラボで作成した場合は以下のコマンドを使用します。作成していない場合は以下を手動で設定する必要があります。
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
ライブラリをインポートする
この Codelab 全体を通して使用するライブラリをインポートするために、次のコードを追加します。
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
定数を定義する
パイプラインの構築前に最後に行うのが、いくつかの定数変数の定義です。PIPELINE_ROOT は、パイプラインによって作成されるアーティファクトを書き込む Cloud Storage のパスです。ここではリージョンとして us-central1 を使用しますが、バケットの作成時に別のリージョンを使用した場合は、次のコード内の REGION 変数を更新します。
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
上のコードを実行すると、パイプラインのルート ディレクトリがプリントされます。これは、パイプラインからのアーティファクトが書き込まれる Cloud Storage の場所です。形式は gs://YOUR-BUCKET-NAME/pipeline_root/ です。
5. カスタム コンポーネントを使用して 3 ステップのパイプラインを作成する
このラボでは、パイプライン実行のメタデータを理解することに重点を置きます。そのためには、Vertex Pipelines で実行するパイプラインが必要です。ここから始めましょう。ここでは、次のカスタム コンポーネントを使用して 3 ステップのパイプラインを定義します。
get_dataframe: BigQuery テーブルからデータを取得し、Pandas DataFrame に変換しますtrain_sklearn_model: Pandas DataFrame を使用して、Scikit Learn モデルといくつかの指標をトレーニングしてエクスポートするdeploy_model: エクスポートされた Scikit Learn モデルを Vertex AI のエンドポイントにデプロイする
このパイプラインでは、UCI Machine Learning の Dry beans データセットを使用します(出典: KOKLU, M. および OZKAN, I.A.(2020 年)「Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques」、Computers and Electronics in Agriculture、174、105507。DOI。
これは表形式のデータセットです。パイプラインでこのデータセットを使用し、豆をその特徴に基づいて 7 種類に分類する Scikit-learn モデルのトレーニング、評価、デプロイを行います。コーディングを始めましょう。
Python 関数ベースのコンポーネントを作成する
KFP SDK を使用して、Python の関数に基づくコンポーネントを作成できます。このパイプラインの 3 つのコンポーネントで KFP SDK を使用します。
BigQuery データをダウンロードして CSV に変換する
まず、get_dataframe コンポーネントを構築します。
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
このコンポーネントで何が起こっているのかを詳しく見てみましょう。
@componentデコレータにより、この関数はパイプラインの実行時にコンポーネントへとコンパイルされます。カスタム コンポーネントを記述するときには、これを使用します。base_imageパラメータは、このコンポーネントが使用するコンテナ イメージを指定します。- このコンポーネントは、
packages_to_installパラメータで指定するいくつかの Python ライブラリを使用します。 output_component_fileパラメータは省略可能で、コンパイルしたコンポーネントを書き込む yaml ファイルを指定します。セルの実行後、そのファイルがノートブック インスタンスに書き込まれているのを確認できます。このコンポーネントを他のユーザーと共有したい場合は、生成した yaml ファイルをそのユーザーに送信し、次のコードでそれを読み込んでもらうことができます。
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- 次に、このコンポーネントは BigQuery Python クライアント ライブラリを使用して、BigQuery から Pandas DataFrame にデータをダウンロードし、そのデータの出力アーティファクトを CSV ファイルとして作成します。これは次のコンポーネントへの入力として渡されます。
Scikit-learn モデルをトレーニングするコンポーネントを作成する
このコンポーネントでは、前に生成した CSV を取得し、それを使用して Scikit-learn の決定木モデルをトレーニングします。このコンポーネントは、結果の Scikit モデルと、モデルの精度、フレームワーク、トレーニングに使用されたデータセットのサイズを含む Metrics アーティファクトをエクスポートします。
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
モデルを Vertex AI にアップロードしてデプロイするコンポーネントを定義する
最後に、最後のコンポーネントは、前のステップでトレーニングしたモデルを取得し、Vertex AI にアップロードして、エンドポイントにデプロイします。
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
ここでは、Vertex AI SDK を使用して、予測用のビルド済みコンテナを使用してモデルをアップロードします。次に、モデルをエンドポイントにデプロイし、モデルとエンドポイントの両方のリソースの URI を返します。この Codelab の後半で、このデータをアーティファクトとして返すことの意味について詳しく説明します。
パイプラインを定義してコンパイルする
3 つのコンポーネントを定義したので、次はパイプライン定義を作成します。これは、入出力アーティファクトがステップ間でどのように流れるかを記述したものです。
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
次のコードで、パイプラインの実行に使用する JSON ファイルを生成します。
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
2 つのパイプライン実行を開始する
次に、パイプラインの実行を 2 回開始します。まず、パイプライン ジョブ ID に使用するタイムスタンプを定義します。
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
パイプラインの実行時に 1 つのパラメータ(トレーニング データに使用する bq_table)が渡されることを思い出してください。このパイプライン実行では、beans データセットの小さいバージョンが使用されます。
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
次に、同じデータセットのより大きなバージョンを使用して、別のパイプライン実行を作成します。
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
最後に、両方の実行のパイプライン実行を開始します。各実行の出力を確認できるように、2 つの別々のノートブック セルでこれを行うことをおすすめします。
run1.submit()
次に、2 回目の実行を開始します。
run2.submit()
このセルを実行すると、Vertex AI コンソールで各パイプラインを表示するためのリンクが表示されます。そのリンクを開くと、パイプラインの詳細が表示されます。

完了すると(このパイプラインは実行ごとに約 10 ~ 15 分かかります)、次のような内容が表示されます。

2 つのパイプライン実行が完了したので、パイプライン アーティファクト、指標、リネージを詳しく見てみましょう。
6. パイプライン アーティファクトとリネージについて
パイプライン グラフでは、各ステップの後に小さなボックスが表示されます。これらはアーティファクト、つまりパイプライン ステップから生成された出力です。アーティファクトにはさまざまな種類があります。このパイプラインには、データセット、指標、モデル、エンドポイントのアーティファクトがあります。UI の上部にある [アーティファクトを展開] スライダーをクリックすると、各アーティファクトの詳細が表示されます。

アーティファクトをクリックすると、URI などの詳細が表示されます。たとえば、vertex_endpoint アーティファクトをクリックすると、Vertex AI コンソールでデプロイされたエンドポイントを確認できる URI が表示されます。

Metrics アーティファクトを使用すると、特定のパイプライン ステップに関連付けられているカスタム指標を渡すことができます。パイプラインの sklearn_train コンポーネントで、モデルの精度、フレームワーク、データセット サイズに関する指標をロギングしました。指標アーティファクトをクリックすると、次の詳細が表示されます。

すべてのアーティファクトには、接続されている他のアーティファクトを記述するリネージがあります。パイプラインの vertex_endpoint アーティファクトをもう一度クリックし、[リネージを表示] ボタンをクリックします。

新しいタブが開き、選択したアーティファクトに関連付けられているすべてのアーティファクトが表示されます。系統グラフは次のようになります。

このエンドポイントに関連付けられているモデル、指標、データセットが表示されます。なぜこれが有用なのでしょうか。複数のエンドポイントにデプロイされたモデルがある場合や、表示しているエンドポイントにデプロイされたモデルのトレーニングに使用された特定のデータセットを知る必要がある場合があります。リネージ グラフを使用すると、ML システムの他の部分との関連で各アーティファクトを理解できます。この Codelab の後半で説明するように、リネージにはプログラムでアクセスすることもできます。
7. パイプライン実行の比較
1 つのパイプラインが複数回実行される可能性が高く、入力パラメータが異なる場合や、新しいデータが使用される場合、チームの複数の担当者が実行する場合などがあります。パイプライン実行を追跡するには、さまざまな指標に基づいて比較できる方法があると便利です。このセクションでは、実行を比較する 2 つの方法について説明します。
Pipelines UI で実行を比較する
Cloud コンソールで、パイプライン ダッシュボードに移動します。実行したすべてのパイプライン実行の概要が表示されます。最後の 2 回の実行を確認し、上部の [比較] ボタンをクリックします。

選択した実行の入力パラメータと指標を比較できるページが表示されます。この 2 つの実行では、BigQuery テーブル、データセット サイズ、精度値が異なります。

この UI 機能を使用すると、2 つ以上の実行を比較できます。異なるパイプラインの実行を比較することもできます。
Vertex AI SDK を使用して実行を比較する
パイプラインの実行回数が多い場合は、これらの比較指標をプログラムで取得して、指標の詳細を掘り下げ、可視化を作成する方法が必要になることがあります。
aiplatform.get_pipeline_df() メソッドを使用して、実行のメタデータにアクセスできます。ここでは、同じパイプラインの最後の 2 回の実行のメタデータを取得し、Pandas DataFrame に読み込みます。ここで pipeline パラメータは、パイプライン定義でパイプラインに付けた名前を参照します。
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
DataFrame を出力すると、次のように表示されます。

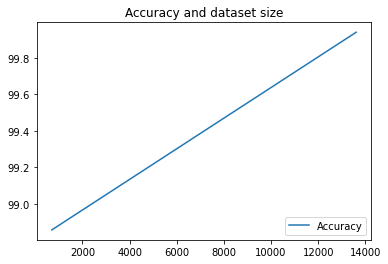
ここではパイプラインを 2 回実行しただけですが、実行回数が増えると指標の数も増えることがわかります。次に、matplotlib を使用してカスタムのビジュアリゼーションを作成し、モデルの精度とトレーニングに使用されたデータ量の関係を確認します。
新しいノートブックのセルで次のコマンドを実行します。
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
次のように表示されます。
8. パイプライン指標のクエリ
すべてのパイプライン指標の DataFrame を取得するだけでなく、ML システムで作成されたアーティファクトをプログラムでクエリすることもできます。そこからカスタム ダッシュボードを作成したり、組織内の他のユーザーが特定のアーティファクトの詳細を取得できるようにしたりできます。
すべてのモデル アーティファクトを取得する
このようにアーティファクトをクエリするには、MetadataServiceClient を作成します。
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
次に、そのエンドポイントに list_artifacts リクエストを送信し、レスポンスで取得するアーティファクトを示すフィルタを渡します。まず、プロジェクト内のすべての モデルを取得します。これを行うには、ノートブックで次のコマンドを実行します。
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
結果の model_artifacts レスポンスには、プロジェクト内の各モデル アーティファクトの反復可能オブジェクトと、各モデルの関連メタデータが含まれます。
オブジェクトをフィルタして DataFrame に表示する
結果のアーティファクト クエリをより簡単に可視化できると便利です。次に、2021 年 8 月 10 日以降に作成された LIVE 状態のアーティファクトをすべて取得します。このリクエストを実行すると、結果が Pandas DataFrame に表示されます。まず、リクエストを実行します。
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
次に、結果を DataFrame に表示します。
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
次のような出力が表示されます。

ここで試した条件以外にも、他の条件に基づいてアーティファクトをフィルタすることもできます。
これでラボは完了です。
お疲れさまでした
Vertex AI を使って次のことを行う方法を学びました。
- Kubeflow Pipelines SDK を使用して、Vertex AI にデータセットを作成し、そのデータセットでカスタム Scikit-learn モデルをトレーニングしてデプロイする ML パイプラインを構築する
- アーティファクトとメタデータを生成するカスタム パイプライン コンポーネントを作成する
- Cloud コンソールとプログラムの両方で Vertex Pipelines の実行を比較する
- パイプライン生成アーティファクトのリネージを追跡する
- パイプライン実行メタデータをクエリする
Vertex のさまざまな部分の説明については、ドキュメントをご覧ください。
9. クリーンアップ
課金されないようにするには、このラボ全体で作成したリソースを削除することをおすすめします。
Notebooks インスタンスを停止または削除する
このラボで作成したノートブックを引き続き使用する場合は、未使用時にオフにすることをおすすめします。Cloud コンソールの Notebooks UI で、ノートブックを選択して [停止] を選択します。インスタンスを完全に削除する場合は、[削除] を選択します。

Vertex AI エンドポイントを削除する
デプロイしたエンドポイントを削除するには、Vertex AI コンソールの [エンドポイント] セクションに移動し、削除アイコンをクリックします。

Cloud Storage バケットの削除
ストレージ バケットを削除するには、Cloud コンソールのナビゲーション メニューで [ストレージ] に移動してバケットを選択し、[削除] をクリックします。
