
1. 概览
在本实验中,您将学习如何使用 Vertex ML Metadata 分析 Vertex Pipelines 运行产生的元数据。
学习内容
您将了解如何:
- 使用 Kubeflow Pipelines SDK 构建一个机器学习流水线,该流水线可在 Vertex AI 中创建数据集,并基于该数据集训练和部署自定义 Scikit-learn 模型
- 编写用于生成工件和元数据的自定义流水线组件
- 比较 Cloud 控制台和编程中的 Vertex Pipelines 运行
- 跟踪流水线生成的工件的沿袭
- 查询流水线运行的元数据
在 Google Cloud 上运行此实验的总费用约为 2 美元。
2. Vertex AI 简介
本实验使用的是 Google Cloud 上提供的最新 AI 产品。Vertex AI 将整个 Google Cloud 的机器学习产品集成到无缝的开发体验中。以前,使用 AutoML 训练的模型和自定义模型是通过不同的服务访问的。现在,该新产品与其他新产品一起将这两种模型合并到一个 API 中。您还可以将现有项目迁移到 Vertex AI。
除了模型训练和部署服务之外,Vertex AI 还包含各种 MLOps 产品,包括 Vertex Pipelines、ML Metadata、Model Monitoring、Feature Store 等。您可以在下图中查看所有 Vertex AI 产品。
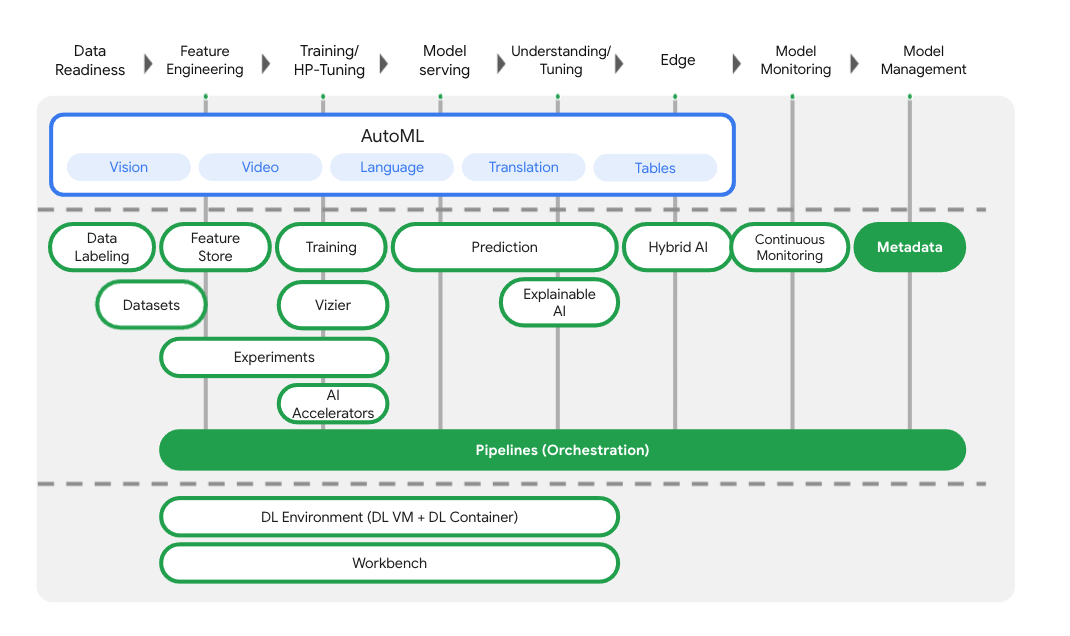
本实验重点介绍 Vertex Pipelines 和 Vertex ML Metadata。
如果您有任何 Vertex AI 反馈,请参阅支持页面。
机器学习流水线有哪些优势?
在深入探讨之前,先来了解一下为什么要使用流水线。假设您正在构建一个机器学习工作流,该工作流中包含数据处理、模型训练、超参数调优、评估和模型部署步骤。每个步骤可能有不同的依赖项,如果将整个工作流作为一个单体式应用来处理,可能会变得难以管理。在开始扩展机器学习流程时,您可能需要与团队中的其他成员共享您的机器学习工作流,以便其运行该工作流并贡献代码。但如果没有可靠且可重复的流程,将很难做到这一点。有了流水线,机器学习流程中的每个步骤都是其各自的容器。这样您就能独立开发各个步骤,并以可重复的方式跟踪每个步骤的输入和输出。您还可以基于云环境中的其他事件(比如有新训练数据可用时)来安排或触发流水线的运行。
总结:流水线有助于自动执行和重复执行机器学习工作流。
3. 云环境设置
您需要一个启用了结算功能的 Google Cloud Platform 项目才能运行此 Codelab。如需创建项目,请按照此处的说明操作。
启动 Cloud Shell
在本实验中,您将使用 Cloud Shell 会话,这是一个由在 Google 云中运行的虚拟机托管的命令解释器。您也可以在自己的计算机上本地运行本部分,但使用 Cloud Shell 可让每个人在一致的环境中获得可重现的体验。完成本实验后,欢迎您在自己的计算机上重试本部分。

激活 Cloud Shell
在 Cloud 控制台的右上角,点击下方按钮以激活 Cloud Shell:

如果您以前从未启动过 Cloud Shell,将看到一个中间屏幕(非首屏),描述它是什么。如果是这种情况,请点击继续(您将永远不会再看到它)。一次性屏幕如下所示:
预配和连接到 Cloud Shell 只需花几分钟时间。

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5GB 主目录,并且在 Google Cloud 中运行,大幅提高了网络性能和身份验证效率。只需使用一个浏览器或 Google Chromebook 即可完成本 Codelab 中的大部分(甚至全部)工作。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的项目 ID:
在 Cloud Shell 中运行以下命令以确认您已通过身份验证:
gcloud auth list
命令输出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目:
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果不是上述结果,您可以使用以下命令进行设置:
gcloud config set project <PROJECT_ID>
命令输出
Updated property [core/project].
Cloud Shell 有几个环境变量,包括 GOOGLE_CLOUD_PROJECT,其中包含当前云项目的名称。在本实验中,我们将在多个地方使用此变量。您可以通过运行以下命令查看:
echo $GOOGLE_CLOUD_PROJECT
启用 API
在后续步骤中,您将了解在哪些情况下需要这些服务(以及原因),但现在,请运行以下命令,以授予您的项目对 Compute Engine、Container Registry 和 Vertex AI 服务的访问权限:
gcloud services enable compute.googleapis.com \
containerregistry.googleapis.com \
aiplatform.googleapis.com
这应该会生成类似如下内容的成功消息:
Operation "operations/acf.cc11852d-40af-47ad-9d59-477a12847c9e" finished successfully.
创建 Cloud Storage 存储桶
如需在 Vertex AI 上运行训练作业,我们需要一个存储分区来存储已保存的模型资产。存储分区必须是区域级存储分区。我们在此处使用的是 us-central,但您也可以使用其他区域(只需在本实验中将其替换掉即可)。如果您已有存储分区,则可以跳过此步骤。
在 Cloud Shell 终端中运行以下命令以创建存储分区:
BUCKET_NAME=gs://$GOOGLE_CLOUD_PROJECT-bucket
gsutil mb -l us-central1 $BUCKET_NAME
接下来,我们将向计算服务账号授予对此存储分区的访问权限。这样可确保 Vertex Pipelines 拥有将文件写入此存储分区所需的权限。运行以下命令可添加此权限:
gcloud projects describe $GOOGLE_CLOUD_PROJECT > project-info.txt
PROJECT_NUM=$(cat project-info.txt | sed -nre 's:.*projectNumber\: (.*):\1:p')
SVC_ACCOUNT="${PROJECT_NUM//\'/}-compute@developer.gserviceaccount.com"
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member serviceAccount:$SVC_ACCOUNT --role roles/storage.objectAdmin
创建 Vertex AI Workbench 实例
在 Cloud Console 的 Vertex AI 部分中,点击“Workbench”:
然后,在用户管理的笔记本中,点击新建笔记本:

然后选择不带 GPU 的 TensorFlow 企业版 2.3(提供长期支持)实例类型:

使用默认选项,然后点击创建。
打开笔记本
创建实例后,选择打开 JupyterLab:

4. Vertex Pipelines 设置
若要使用 Vertex Pipelines,我们还需要额外安装几个库:
- Kubeflow Pipelines:此 SDK 将用于构建流水线。Vertex Pipelines 支持运行使用 Kubeflow Pipelines 或 TFX 构建的流水线。
- Vertex AI SDK:此 SDK 可优化调用 Vertex AI API 的体验。我们将使用它在 Vertex AI 上运行流水线。
创建 Python 笔记本并安装库
首先,在笔记本实例页面中,从“启动器”菜单中选择 Python 3 以创建笔记本:

如需安装本实验中要使用的两项服务,请先在笔记本单元中设置用户标志:
USER_FLAG = "--user"
然后,从笔记本中运行以下命令:
!pip3 install {USER_FLAG} google-cloud-aiplatform==1.7.0
!pip3 install {USER_FLAG} kfp==1.8.9
安装这些软件包后,需要重启内核:
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
接下来,检查您是否已正确安装 KFP SDK 版本。它应大于等于 1.8:
!python3 -c "import kfp; print('KFP SDK version: {}'.format(kfp.__version__))"
然后,确认您的 Vertex AI SDK 版本为 1.6.2 或更高版本:
!pip list | grep aiplatform
设置项目 ID 和存储分区
在本实验中,您将全程引用之前创建的云项目 ID 和存储分区。接下来,我们将为每个变量创建变量。
如果不知道项目 ID,可运行以下命令来获取:
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
否则,请在此处进行设置:
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "your-project-id" # @param {type:"string"}
然后,创建一个变量来存储您的存储分区名称。如果您是在本实验中创建的,则以下操作会奏效。否则,您需要手动设置此项:
BUCKET_NAME="gs://" + PROJECT_ID + "-bucket"
导入库
添加以下命令,以导入我们将在整个 Codelab 中使用的库:
import matplotlib.pyplot as plt
import pandas as pd
from kfp.v2 import compiler, dsl
from kfp.v2.dsl import pipeline, component, Artifact, Dataset, Input, Metrics, Model, Output, InputPath, OutputPath
from google.cloud import aiplatform
# We'll use this namespace for metadata querying
from google.cloud import aiplatform_v1
定义常量
在构建流水线之前,我们需要做的最后一件事是定义一些常量变量。PIPELINE_ROOT 是一个 Cloud Storage 路径,流水线创建的制品将写入该路径。这里我们使用的区域是 us-central1,如果您在创建存储分区时使用了其他区域,请运行以下代码来更新 REGION 变量:
PATH=%env PATH
%env PATH={PATH}:/home/jupyter/.local/bin
REGION="us-central1"
PIPELINE_ROOT = f"{BUCKET_NAME}/pipeline_root/"
PIPELINE_ROOT
运行上述代码后,您应该会看到输出的流水线根目录。来自流水线的制品将写入此 Cloud Storage 位置。它将采用 gs://YOUR-BUCKET-NAME/pipeline_root/ 格式
5. 创建包含自定义组件的 3 步流水线
本实验的重点是了解流水线运行中的元数据。为此,我们需要在 Vertex Pipelines 上运行流水线,接下来我们就从这里开始。在此示例中,我们将定义一个包含以下自定义组件的 3 步流水线:
get_dataframe:从 BigQuery 表中检索数据并将其转换为 Pandas DataFrametrain_sklearn_model:使用 Pandas DataFrame 训练和导出 Scikit Learn 模型,并提供一些指标deploy_model:将导出的 Scikit Learn 模型部署到 Vertex AI 中的端点
在此流水线中,我们将使用“UCI Machine Learning 干豆数据集”,该数据集来自 KOKLU, M. 和 OZKAN, I.A.于 2020 年在《Computers and Electronics in Agriculture》上发表的“Multiclass Classification of Dry Beans Using Computer Vision and Machine Learning Techniques.”(利用计算机视觉和机器学习技术对干豆进行多类别分类)一文 (174, 105507. DOI。
这是一个表格数据集。在此流水线中,我们将使用该数据集来训练、评估和部署一个 Scikit-learn 模型。该模型会根据豆子特征将不同豆子分为 7 种类型之一。让我们开始编码吧!
创建基于 Python 函数的组件
利用 KFP SDK,我们可以根据 Python 函数来创建组件。我们将使用该变量来表示此流水线中的 3 个组件。
下载 BigQuery 数据并转换为 CSV 格式
首先,我们将构建 get_dataframe 组件:
@component(
packages_to_install=["google-cloud-bigquery", "pandas", "pyarrow", "db-dtypes"],
base_image="python:3.9",
output_component_file="create_dataset.yaml"
)
def get_dataframe(
bq_table: str,
output_data_path: OutputPath("Dataset")
):
from google.cloud import bigquery
import pandas as pd
import os
project_number = os.environ["CLOUD_ML_PROJECT_ID"]
bqclient = bigquery.Client(project=project_number)
table = bigquery.TableReference.from_string(
bq_table
)
rows = bqclient.list_rows(
table
)
dataframe = rows.to_dataframe(
create_bqstorage_client=True,
)
dataframe = dataframe.sample(frac=1, random_state=2)
dataframe.to_csv(output_data_path)
我们来详细了解一下此组件中发生了什么:
- 流水线运行时,
@component修饰器会将此函数编译为一个组件。您每次编写自定义组件时都会用到它。 base_image参数用于指定此组件将使用的容器映像。- 此组件将使用一些 Python 库,我们通过
packages_to_install参数指定这些库。 output_component_file是可选参数,用于指定要在其中写入已编译组件的 yaml 文件。运行此单元后,您应该会看到该文件已写入您的笔记本实例中。如果您想与其他人共享此组件,可以将生成的 yaml 文件发送给相关人员,并让他们运行以下命令来加载该文件:
# This is optional, it shows how to load a component from a yaml file
# dataset_component = kfp.components.load_component_from_file('./create_dataset.yaml')
- 接下来,此组件使用 BigQuery Python 客户端库将数据从 BigQuery 下载到 Pandas DataFrame 中,然后以 CSV 文件的形式创建该数据的输出制品。这将作为输入传递给我们的下一个组件
创建用于训练 Scikit-learn 模型的组件
在此组件中,我们将使用之前生成的 CSV 文件来训练 Scikit-learn 决策树模型。此组件会导出生成的 Scikit 模型,以及一个 Metrics 制品,其中包含模型的准确率、框架和用于训练模型的数据集的大小:
@component(
packages_to_install=["sklearn", "pandas", "joblib", "db-dtypes"],
base_image="python:3.9",
output_component_file="beans_model_component.yaml",
)
def sklearn_train(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model]
):
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_curve
from sklearn.model_selection import train_test_split
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
labels = df.pop("Class").tolist()
data = df.values.tolist()
x_train, x_test, y_train, y_test = train_test_split(data, labels)
skmodel = DecisionTreeClassifier()
skmodel.fit(x_train,y_train)
score = skmodel.score(x_test,y_test)
print('accuracy is:',score)
metrics.log_metric("accuracy",(score * 100.0))
metrics.log_metric("framework", "Scikit Learn")
metrics.log_metric("dataset_size", len(df))
dump(skmodel, model.path + ".joblib")
定义一个用于将模型上传并部署到 Vertex AI 的组件
最后,我们的最后一个组件将获取上一步中训练的模型,将其上传到 Vertex AI,并将其部署到端点:
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
output_component_file="beans_deploy_component.yaml",
)
def deploy_model(
model: Input[Model],
project: str,
region: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
):
from google.cloud import aiplatform
aiplatform.init(project=project, location=region)
deployed_model = aiplatform.Model.upload(
display_name="beans-model-pipeline",
artifact_uri = model.uri.replace("model", ""),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save data to the output params
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
在此示例中,我们使用 Vertex AI SDK 通过用于预测的预构建容器上传模型。然后,将模型部署到端点,并返回模型和端点资源的 URI。在本 Codelab 的后半部分,您将详细了解以制品形式返回这些数据意味着什么。
定义并编译流水线
现在,我们已经定义了三个组件,接下来将创建流水线定义。此图描述了输入和输出制品在各个步骤之间的流动方式:
@pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT,
# A name for the pipeline.
name="mlmd-pipeline",
)
def pipeline(
bq_table: str = "",
output_data_path: str = "data.csv",
project: str = PROJECT_ID,
region: str = REGION
):
dataset_task = get_dataframe(bq_table)
model_task = sklearn_train(
dataset_task.output
)
deploy_task = deploy_model(
model=model_task.outputs["model"],
project=project,
region=region
)
以下命令将生成一个用于运行流水线的 JSON 文件:
compiler.Compiler().compile(
pipeline_func=pipeline, package_path="mlmd_pipeline.json"
)
启动两个流水线运行作业
接下来,我们将启动流水线的两次运行。首先,我们来定义一个时间戳,用于流水线作业 ID:
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
请注意,我们的流水线在运行时需要一个参数:我们想要用于训练数据的 bq_table。此流水线运行将使用较小版本的 beans 数据集:
run1 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-small-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.small_dataset"},
enable_caching=True,
)
接下来,使用同一数据集的较大版本创建另一个流水线运行。
run2 = aiplatform.PipelineJob(
display_name="mlmd-pipeline",
template_path="mlmd_pipeline.json",
job_id="mlmd-pipeline-large-{0}".format(TIMESTAMP),
parameter_values={"bq_table": "sara-vertex-demos.beans_demo.large_dataset"},
enable_caching=True,
)
最后,启动两次运行的流水线执行。最好在两个单独的笔记本单元中执行此操作,以便查看每次运行的输出。
run1.submit()
然后,启动第二次运行:
run2.submit()
运行此单元后,您会看到一个链接,用于在 Vertex AI 控制台中查看每个流水线。打开该链接可查看流水线的更多详情:

当流水线完成时(此流水线每次运行大约需要 10-15 分钟),您会看到如下内容:

现在,您已完成两次流水线运行,接下来可以仔细查看流水线制品、指标和沿袭了。
6. 了解流水线工件和沿袭
在流水线图中,您会注意到每个步骤后都有小方框。这些是制品,即流水线步骤生成的输出。制品有很多种。在此特定流水线中,我们有数据集、指标、模型和端点制品。点击界面顶部的展开制品滑块,即可查看每个制品的更多详细信息:

点击制品会显示有关该制品的更多详细信息,包括其 URI。例如,点击 vertex_endpoint 制品会显示一个 URI,您可以在 Vertex AI 控制台中找到该已部署的端点:

借助 Metrics 制品,您可以传递与特定流水线步骤相关联的自定义指标。在流水线的 sklearn_train 组件中,我们记录了模型准确率、框架和数据集大小方面的指标。点击指标制品可查看以下详细信息:

每个制品都有沿袭,用于描述它与其他制品的关联。再次点击流水线的 vertex_endpoint 制品,然后点击查看沿袭按钮:

系统随即会打开一个新标签页,您可以在其中查看与所选制品相关联的所有制品。您的谱系图将如下所示:
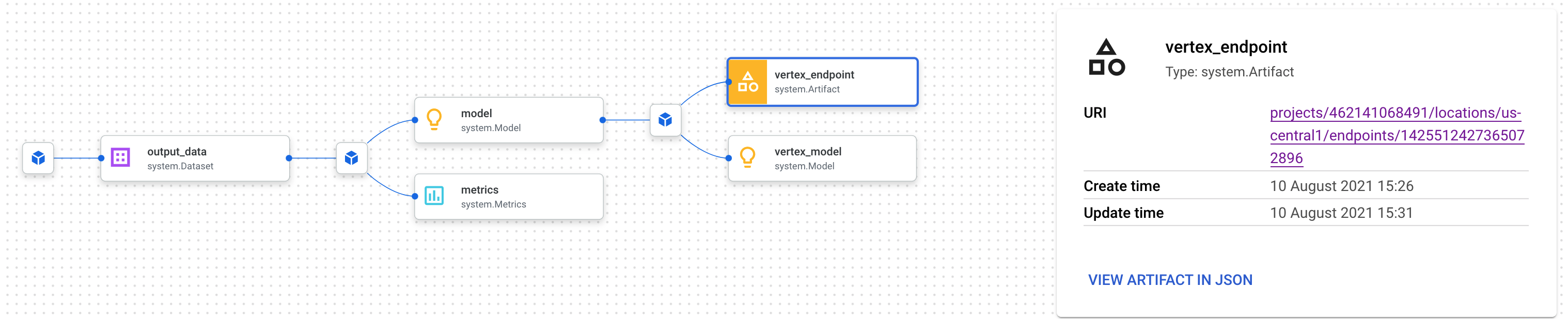
这会显示与此端点关联的模型、指标和数据集。这项测试的价值何在?您可能已将模型部署到多个端点,或者需要了解用于训练部署到您正在查看的端点的模型的特定数据集。沿袭图有助于您了解机器学习系统中每个工件的上下文。您还可以通过编程方式访问谱系,我们将在本 Codelab 的后续部分中看到这一点。
7. 比较流水线运行
单个流水线很可能会多次运行,可能使用不同的输入参数、新数据,也可能由团队中的不同人员运行。为了跟踪流水线运行情况,最好能有一种方法可以根据各种指标比较流水线运行情况。在本部分中,我们将探讨比较运行的两种方式。
在 Pipelines 界面中比较运行
在 Cloud 控制台中,前往流水线信息中心。此页面会显示您执行的每个流水线运行的概览。检查最后两次运行,然后点击顶部的比较按钮:

这样一来,系统会转到相应页面,我们可以在其中比较所选每次运行的输入参数和指标。对于这两次运行,请注意不同的 BigQuery 表、数据集大小和准确率值:
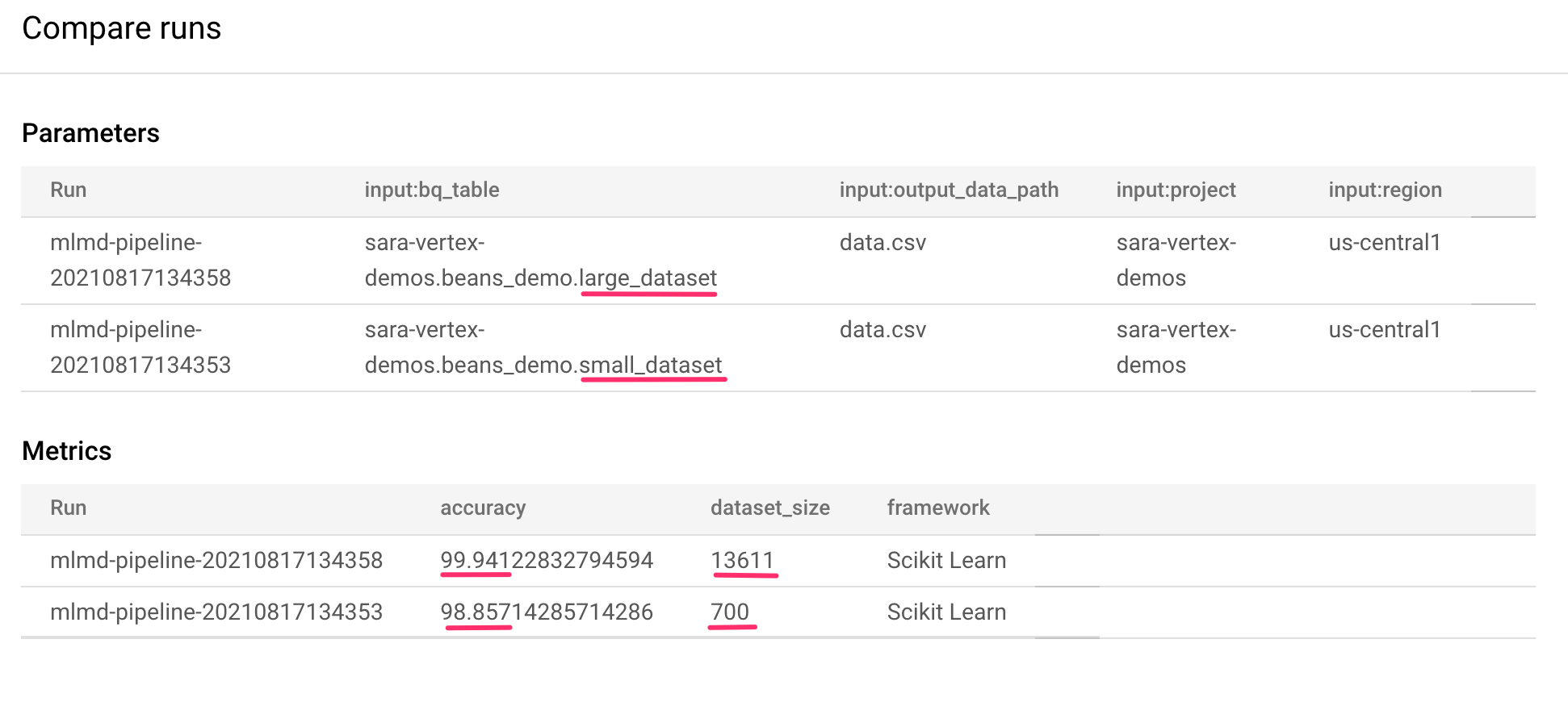
您可以使用此界面功能比较两次以上的运行,甚至可以比较来自不同流水线的运行。
使用 Vertex AI SDK 比较运行
在多次执行流水线后,您可能希望以编程方式获取这些比较指标,以便更深入地了解指标详情并创建可视化图表。
您可以使用 aiplatform.get_pipeline_df() 方法来获取运行元数据。在此示例中,我们将获取同一流水线最近两次运行的元数据,并将其加载到 Pandas DataFrame 中。此处的 pipeline 参数是指我们在流水线定义中为流水线指定的名称:
df = aiplatform.get_pipeline_df(pipeline="mlmd-pipeline")
df
打印 DataFrame 时,您会看到如下内容:

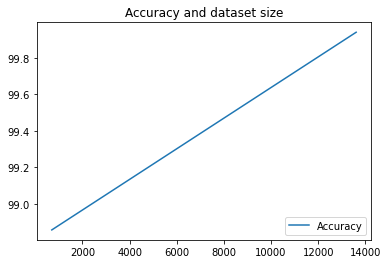
我们在这里只执行了两次流水线,但您可以想象,如果执行更多次,您将获得多少指标。接下来,我们将使用 matplotlib 创建自定义可视化图表,以查看模型准确率与用于训练的数据量之间的关系。
在新的笔记本单元中运行以下代码:
plt.plot(df["metric.dataset_size"], df["metric.accuracy"],label="Accuracy")
plt.title("Accuracy and dataset size")
plt.legend(loc=4)
plt.show()
您应该会看到与以下类似的内容:
8. 查询流水线指标
除了获取包含所有流水线指标的 DataFrame 之外,您可能还希望以编程方式查询机器学习系统中创建的制品。然后,您可以创建自定义信息中心,也可以让组织中的其他用户获取特定制品的相关详细信息。
获取所有模型制品
如需以这种方式查询制品,我们将创建一个 MetadataServiceClient:
API_ENDPOINT = "{}-aiplatform.googleapis.com".format(REGION)
metadata_client = aiplatform_v1.MetadataServiceClient(
client_options={
"api_endpoint": API_ENDPOINT
}
)
接下来,我们将向该端点发出 list_artifacts 请求,并传递一个过滤条件,指明我们希望在响应中包含哪些制品。首先,我们来获取项目中所有属于模型的制品。为此,请在笔记本中运行以下代码:
MODEL_FILTER="schema_title = \"system.Model\""
artifact_request = aiplatform_v1.ListArtifactsRequest(
parent="projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
filter=MODEL_FILTER
)
model_artifacts = metadata_client.list_artifacts(artifact_request)
生成的 model_artifacts 响应包含项目中每个模型制品的迭代对象,以及每个模型的关联元数据。
过滤对象并显示在 DataFrame 中
如果我们能更轻松地直观呈现生成的制品查询,那就方便多了。接下来,我们获取 2021 年 8 月 10 日之后创建的所有状态为 LIVE 的制品。运行此请求后,我们会以 Pandas DataFrame 的形式显示结果。首先,执行请求:
LIVE_FILTER = "create_time > \"2021-08-10T00:00:00-00:00\" AND state = LIVE"
artifact_req = {
"parent": "projects/{0}/locations/{1}/metadataStores/default".format(PROJECT_ID, REGION),
"filter": LIVE_FILTER
}
live_artifacts = metadata_client.list_artifacts(artifact_req)
然后,以 DataFrame 形式显示结果:
data = {'uri': [], 'createTime': [], 'type': []}
for i in live_artifacts:
data['uri'].append(i.uri)
data['createTime'].append(i.create_time)
data['type'].append(i.schema_title)
df = pd.DataFrame.from_dict(data)
df
您会看到类似如下的内容:

除了您在此处尝试的条件之外,您还可以根据其他条件过滤制品。
至此,您已完成本实验!
🎉 恭喜!🎉
您学习了如何使用 Vertex AI 执行以下操作:
- 使用 Kubeflow Pipelines SDK 构建一个机器学习流水线,该流水线可在 Vertex AI 中创建数据集,并基于该数据集训练和部署自定义 Scikit-learn 模型
- 编写用于生成工件和元数据的自定义流水线组件
- 比较 Cloud 控制台和编程中的 Vertex Pipelines 运行
- 跟踪流水线生成的工件的沿袭
- 查询流水线运行的元数据
如需详细了解 Vertex 的不同部分,请参阅相关文档。
9. 清理
为避免产生费用,建议您删除在本实验中创建的资源。
停止或删除 Notebooks 实例
如果您想继续使用在本实验中创建的笔记本,建议您在不使用时将其关闭。在 Cloud 控制台的笔记本界面中,选择笔记本,然后选择停止。如果您想完全删除该实例,请选择删除:

删除 Vertex AI 端点
如需删除已部署的端点,请前往 Vertex AI 控制台的端点部分,然后点击删除图标:

删除您的 Cloud Storage 存储桶
如需删除存储桶,请使用 Cloud Console 中的导航菜单,浏览到“存储空间”,选择您的存储桶,然后点击“删除”:
