1. Présentation
Dans cet atelier, vous allez utiliser Vertex AI pour exécuter un job d'entraînement distribué sur Vertex AI Training à l'aide de TensorFlow.
Cet atelier fait partie d'une série de vidéos appelée Passer du prototype à la mise en production. Assurez-vous d'avoir terminé les ateliers précédents avant de commencer celui-ci. Vous pouvez consulter la série de vidéos associée pour approfondir vos connaissances :
.
Objectifs de l'atelier
Vous allez apprendre à effectuer les opérations suivantes :
- Exécuter un entraînement distribué sur une seule machine avec plusieurs GPU
- Exécuter un entraînement distribué sur plusieurs machines
Le coût total d'exécution de cet atelier sur Google Cloud est d'environ 2 $.
2. Présentation de Vertex AI
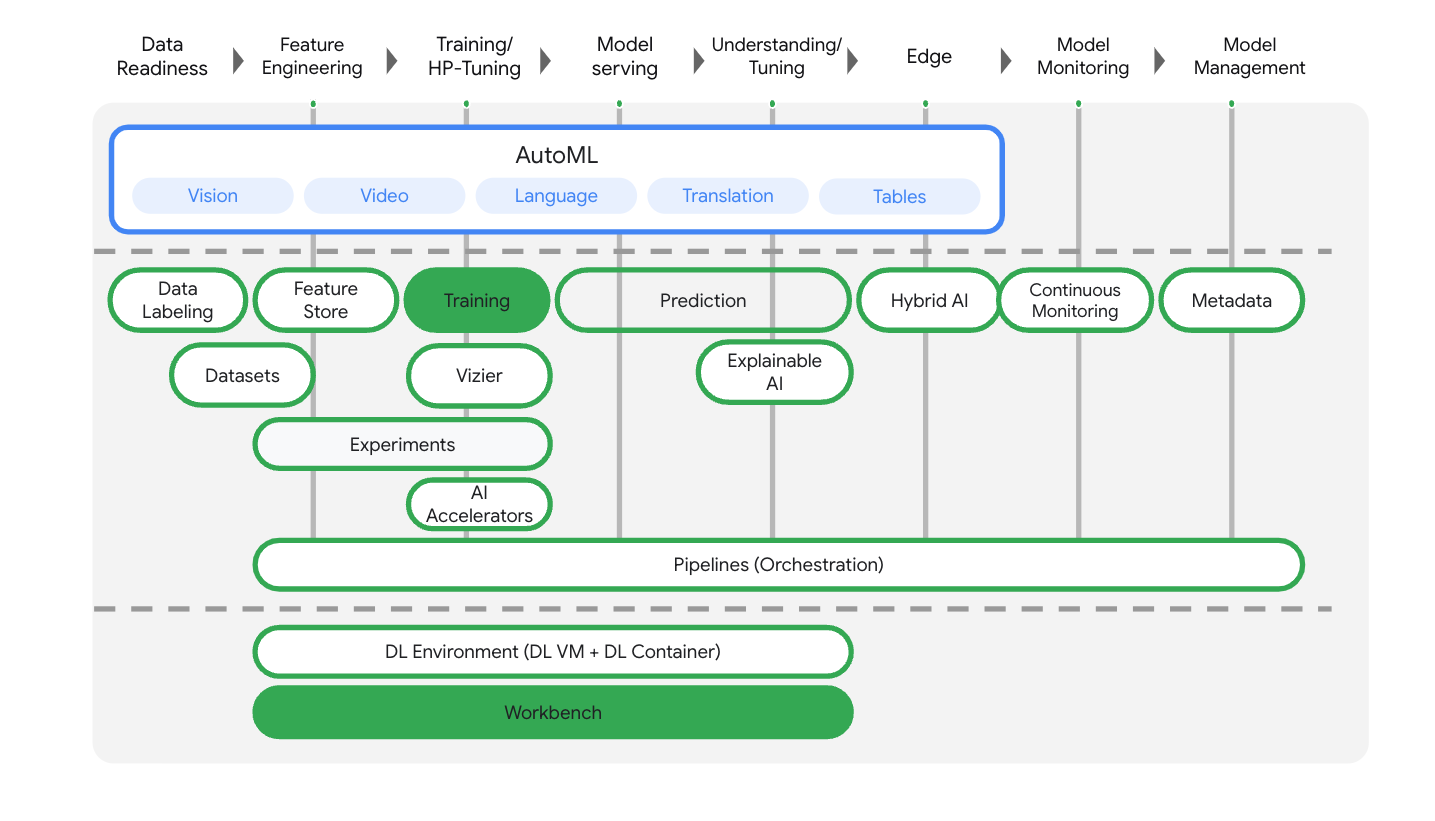
Cet atelier utilise la toute dernière offre de produits d'IA de Google Cloud. Vertex AI simplifie l'expérience de développement en intégrant toutes les offres de ML de Google Cloud. Auparavant, les modèles entraînés avec AutoML et les modèles personnalisés étaient accessibles via des services distincts. La nouvelle offre regroupe ces deux types de modèles mais aussi d'autres nouveaux produits en une seule API. Vous pouvez également migrer des projets existants vers Vertex AI.
Vertex AI comprend de nombreux produits différents qui permettent de gérer les workflows de ML de bout en bout. Cet atelier se concentre sur les produits mis en évidence ci-dessous : Training et Workbench.
3. Présentation de l'entraînement distribué
Si vous disposez d'un seul GPU, TensorFlow utilisera cet accélérateur pour entraîner le modèle plus rapidement, sans qu'aucune action supplémentaire de votre part ne soit nécessaire. Toutefois, si vous souhaitez bénéficier d'un avantage supplémentaire en utilisant plusieurs GPU, vous devez utiliser tf.distribute, le module de TensorFlow qui permet d'effectuer des calculs sur plusieurs appareils.
La première section de cet atelier utilise tf.distribute.MirroredStrategy, que vous pouvez ajouter à vos applications d'entraînement avec un nombre réduit de modifications du code. Cette stratégie crée une copie du modèle sur chaque GPU de votre ordinateur. Les mises à jour de gradient suivantes s'effectueront de manière synchrone. Cela signifie que chaque GPU calcule la propagation avant et arrière du modèle sur une autre tranche des données d'entrée. Les gradients calculés à partir de chacune de ces tranches sont ensuite agrégés sur l'ensemble des GPU, puis une moyenne est calculée dans un processus appelé all-reduce. Les paramètres du modèle sont mis à jour à l'aide de la moyenne des gradients.
La section facultative à la fin de l'atelier utilise tf.distribute.MultiWorkerMirroredStrategy, qui est semblable à MirroredStrategy, mais fonctionne sur plusieurs machines. Chacune de ces machines peut également disposer de plusieurs GPU. Comme MirroredStrategy, MultiWorkerMirroredStrategy est une stratégie de chargement de données synchrones en parallèle que vous pouvez utiliser avec un nombre réduit de modifications du code. Lors du passage au chargement de données synchrones en parallèle sur plusieurs machines, la synchronisation des gradients à la fin de chaque étape doit être effectuée sur l'ensemble des GPU d'une machine et sur toutes les machines du cluster, ce qui diffère du fonctionnement sur une seule machine.
Vous n'avez pas besoin de connaître tous les détails pour suivre cet atelier, mais si vous souhaitez en savoir plus sur le fonctionnement de l'entraînement distribué dans TensorFlow, vous pouvez consulter la vidéo ci-dessous :
4. Configurer votre environnement
Suivez les étapes de l'atelier Entraîner des modèles personnalisés avec Vertex AI pour configurer votre environnement.
5. Machine unique, entraînement avec plusieurs GPU
Vous allez soumettre ce job d'entraînement distribué à Vertex AI en plaçant votre code d'application d'entraînement dans un conteneur Docker et en déployant ce conteneur dans Google Artifact Registry. Cette approche vous permet d'entraîner un modèle créé avec n'importe quel framework.
Pour commencer, ouvrez une fenêtre de terminal à partir du menu de lancement du notebook Workbench que vous avez créé lors des ateliers précédents.

Étape 1 : Rédigez le code d'entraînement
Créez un répertoire appelé flowers-multi-gpu et utilisez la commande cd pour y accéder :
mkdir flowers-multi-gpu
cd flowers-multi-gpu
Exécutez la commande suivante afin de créer un répertoire pour le code d'entraînement et un fichier Python dans lequel vous pourrez ajouter le code ci-dessous :
mkdir trainer
touch trainer/task.py
Votre répertoire flowers-multi-gpu/ doit maintenant contenir les éléments suivants :
+ trainer/
+ task.py
Ouvrez ensuite le fichier task.py que vous venez de créer et copiez-y le code ci-dessous.
Dans BUCKET_ROOT, vous devez remplacer {your-gcs-bucket} par le bucket Cloud Storage où vous avez stocké l'ensemble de données "Flowers" dans l'atelier 1.
import tensorflow as tf
import numpy as np
import os
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model():
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
return model
def main():
# Create distribution strategy
strategy = tf.distribute.MirroredStrategy()
# Get data
GLOBAL_BATCH_SIZE = BATCH_SIZE * strategy.num_replicas_in_sync
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
# Wrap model creation and compilation within scope of strategy
with strategy.scope():
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=EPOCHS
)
model.save(f'{BUCKET_ROOT}/model_output')
if __name__ == "__main__":
main()
Avant de créer le conteneur, examinons le code de plus près. Certains composants sont utilisés spécifiquement pour l'entraînement distribué.
- L'objet
MirroredStrategyest créé dans la fonctionmain(). Vous devez ensuite encapsuler la création des variables du modèle dans le champ d'application de la stratégie. Cette étape indique à TensorFlow les variables à mettre en miroir sur les GPU. - La taille du lot est mise à l'échelle par la valeur
num_replicas_in_sync. La mise à l'échelle de la taille de lot est une bonne pratique lorsque vous utilisez des stratégies de chargement de données synchrones en parallèle dans TensorFlow. Pour en savoir plus, accédez à cette page.
Étape 2 : Créez un Dockerfile
Pour conteneuriser votre code, vous devrez créer un Dockerfile. Vous allez placer dans ce Dockerfile toutes les commandes nécessaires à l'exécution de l'image. Il installera toutes les bibliothèques nécessaires et configurera le point d'entrée du code d'entraînement.
Depuis votre terminal, créez un Dockerfile vide à la racine de votre répertoire "flowers" :
touch Dockerfile
Votre répertoire flowers-multi-gpu/ doit maintenant contenir les éléments suivants :
+ Dockerfile
+ trainer/
+ task.py
Ouvrez le Dockerfile et copiez-y le code suivant :
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Étape 3 : Créez le conteneur
Depuis votre terminal, exécutez la commande suivante afin de définir une variable d'environnement pour votre projet, en veillant à remplacer your-cloud-project par l'ID de votre projet :
PROJECT_ID='your-cloud-project'
Créez un dépôt dans Artifact Registry. Vous allez utiliser le dépôt créé dans le premier atelier.
REPO_NAME='flower-app'
Définissez une variable avec l'URI de votre image de conteneur dans Artifact Registry :
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image_distributed:single_machine
Configurez Docker.
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Ensuite, créez le conteneur en exécutant la commande suivante à partir de la racine de votre répertoire flowers-multi-gpu :
docker build ./ -t $IMAGE_URI
Enfin, déployez-le dans Artifact Registry :
docker push $IMAGE_URI
Maintenant que le conteneur a été transféré vers Artifact Registry, vous êtes prêt à lancer un job d'entraînement.
Étape 4 : Exécutez le job avec le SDK
Dans cette section, vous allez voir comment configurer et lancer le job d'entraînement distribué à l'aide du SDK Vertex AI pour Python.
Créez un notebook TensorFlow 2 via le lanceur.

Importez le SDK Vertex AI.
from google.cloud import aiplatform
Ensuite, définissez un CustomContainerTrainingJob.
Vous devez remplacer la valeur de {PROJECT_ID} dans container_uri, et celle de {YOUR_BUCKET} dans staging_bucket.
job = aiplatform.CustomContainerTrainingJob(display_name='flowers-multi-gpu',
container_uri='us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_distributed:single_machine',
staging_bucket='gs://{YOUR_BUCKET}')
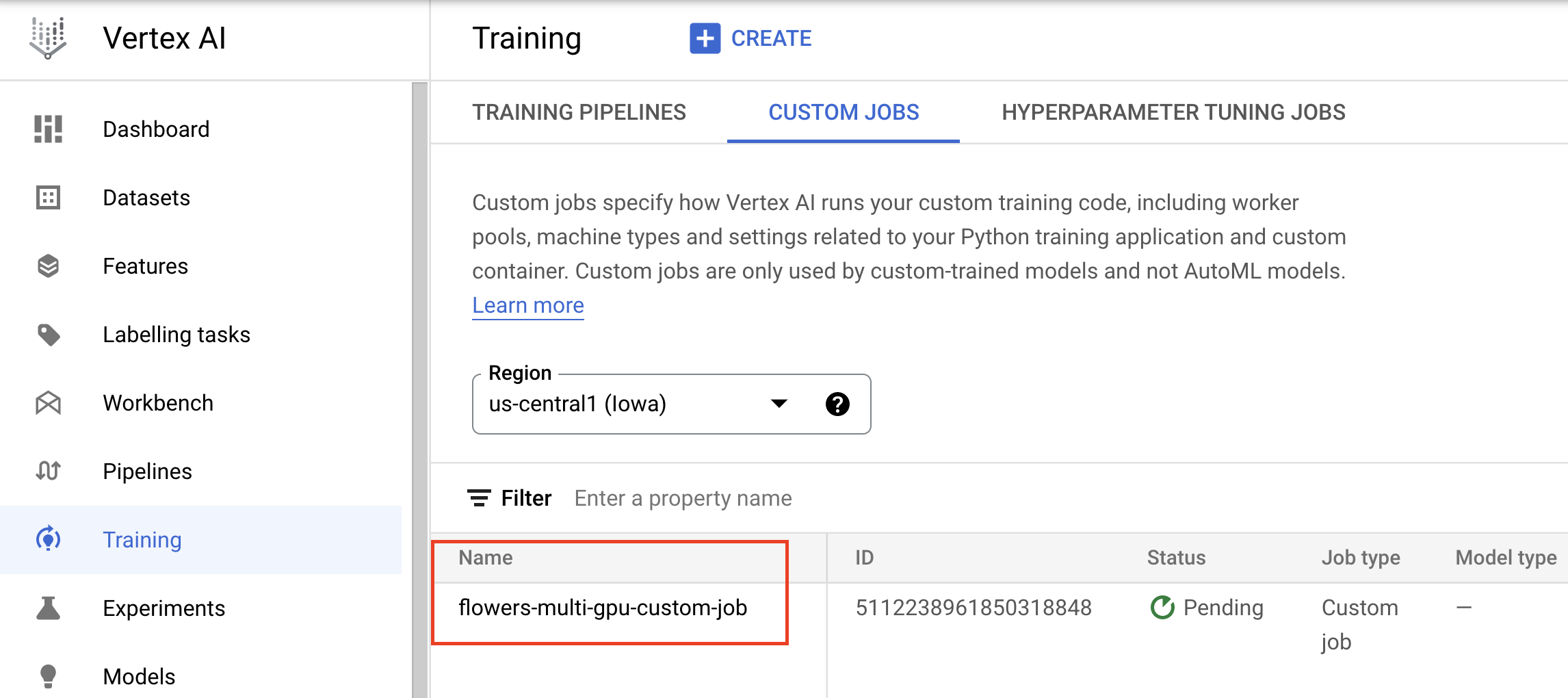
Une fois le job défini, vous pouvez l'exécuter. Vous allez définir le nombre d'accélérateurs sur 2. Si vous n'utilisez qu'un seul GPU, il ne s'agit pas d'un entraînement distribué. L'entraînement distribué sur une seule machine consiste à utiliser deux accélérateurs ou plus.
my_custom_job.run(replica_count=1,
machine_type='n1-standard-4',
accelerator_type='NVIDIA_TESLA_V100',
accelerator_count=2)
La console affiche des informations sur la progression du job.
6. [Facultatif] entraînement avec plusieurs nœuds de calcul
Maintenant que vous avez terminé cet exercice d'entraînement distribué sur une seule machine avec plusieurs GPU, vous pouvez passer au niveau supérieur : l'entraînement sur plusieurs machines. Pour réduire les coûts, nous n'allons ajouter aucun GPU à ces machines, mais vous pouvez tester cette approche si vous le souhaitez.
Ouvrez une nouvelle fenêtre de terminal dans votre instance de notebook :
Étape 1 : Rédigez le code d'entraînement
Créez un répertoire appelé flowers-multi-machine et utilisez la commande cd pour y accéder :
mkdir flowers-multi-machine
cd flowers-multi-machine
Exécutez la commande suivante afin de créer un répertoire pour le code d'entraînement et un fichier Python dans lequel vous pourrez ajouter le code ci-dessous :
mkdir trainer
touch trainer/task.py
Votre répertoire flowers-multi-machine/ doit maintenant contenir les éléments suivants :
+ trainer/
+ task.py
Ouvrez ensuite le fichier task.py que vous venez de créer et copiez-y le code ci-dessous.
Dans BUCKET_ROOT, vous devez remplacer {your-gcs-bucket} par le bucket Cloud Storage où vous avez stocké l'ensemble de données "Flowers" dans l'atelier 1.
import tensorflow as tf
import numpy as np
import os
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
SAVE_MODEL_DIR = f'{BUCKET_ROOT}/multi-machine-output'
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model():
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
return model
def _is_chief(task_type, task_id):
'''Helper function. Determines if machine is chief.'''
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
'''Helper function. Gets temporary directory for saving model.'''
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
'''Helper function. Gets filepath to save model.'''
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
def main():
# Create distribution strategy
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# Get data
GLOBAL_BATCH_SIZE = BATCH_SIZE * strategy.num_replicas_in_sync
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
# Wrap variable creation within strategy scope
with strategy.scope():
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=EPOCHS
)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(SAVE_MODEL_DIR, task_type, task_id)
model.save(write_model_path)
if __name__ == "__main__":
main()
Avant de créer le conteneur, examinons le code de plus près. Certains composants du code sont nécessaires pour que votre application d'entraînement fonctionne avec MultiWorkerMirroredStrategy.
- L'objet
MultiWorkerMirroredStrategyest créé dans la fonctionmain(). Vous devez ensuite encapsuler la création des variables du modèle dans le champ d'application de la stratégie. Cette étape essentielle indique à TensorFlow les variables à mettre en miroir sur les instances répliquées. - La taille du lot est mise à l'échelle par la valeur
num_replicas_in_sync. La mise à l'échelle de la taille de lot est une bonne pratique lorsque vous utilisez des stratégies de chargement de données synchrones en parallèle dans TensorFlow. - L'enregistrement de votre modèle est un peu plus compliqué avec plusieurs nœuds de calcul, car la destination doit être différente pour chacun des nœuds de calcul. Le nœud de calcul chef procède à l'enregistrement dans le répertoire du modèle souhaité, tandis que les autres nœuds de calcul enregistrent le modèle dans des répertoires temporaires. Ces répertoires temporaires doivent impérativement être uniques afin d'éviter que plusieurs nœuds écrivent au même emplacement. Les opérations d'enregistrement peuvent être collectives. En d'autres termes, tous les nœuds doivent procéder à l'enregistrement et pas seulement le nœud chef. Les fonctions
_is_chief(),_get_temp_dir(),write_filepath()ainsi que la fonctionmain()comportent toutes du code récurrent qui permet de sauvegarder le modèle.
Étape 2 : Créez un Dockerfile
Pour conteneuriser votre code, vous devrez créer un Dockerfile. Vous allez placer dans ce Dockerfile toutes les commandes nécessaires à l'exécution de l'image. Il installera toutes les bibliothèques nécessaires et configurera le point d'entrée du code d'entraînement.
Depuis votre terminal, créez un Dockerfile vide à la racine de votre répertoire "flowers" :
touch Dockerfile
Votre répertoire flowers-multi-machine/ doit maintenant contenir les éléments suivants :
+ Dockerfile
+ trainer/
+ task.py
Ouvrez le Dockerfile et copiez-y le code suivant :
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Étape 3 : Créez le conteneur
Depuis votre terminal, exécutez la commande suivante afin de définir une variable d'environnement pour votre projet, en veillant à remplacer your-cloud-project par l'ID de votre projet :
PROJECT_ID='your-cloud-project'
Créez un dépôt dans Artifact Registry. Vous allez utiliser le dépôt créé dans le premier atelier.
REPO_NAME='flower-app'
Définissez une variable avec l'URI de votre image de conteneur dans Google Artifact Registry :
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image_distributed:multi_machine
Configurez Docker.
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Ensuite, créez le conteneur en exécutant la commande suivante à partir de la racine de votre répertoire flowers-multi-machine :
docker build ./ -t $IMAGE_URI
Enfin, déployez-le dans Artifact Registry :
docker push $IMAGE_URI
Maintenant que le conteneur a été transféré vers Artifact Registry, vous êtes prêt à lancer un job d'entraînement.
Étape 4 : Exécutez le job avec le SDK
Dans cette section, vous allez voir comment configurer et lancer le job d'entraînement distribué à l'aide du SDK Vertex AI pour Python.
Créez un notebook TensorFlow 2 via le lanceur.
Importez le SDK Vertex AI.
from google.cloud import aiplatform
Ensuite, configurez worker_pool_specs.
Vertex AI fournit quatre pools de nœuds de calcul pour couvrir les différents types de tâches de la machine.
Le pool de nœuds de calcul 0 configure le nœud principal, chef, programmateur ou "maître". Dans la stratégie MultiWorkerMirroredStrategy, toutes les machines sont désignées comme des nœuds de calcul (machines physiques sur lesquelles les calculs répliqués sont exécutés). Outre le fait que chaque machine constitue un nœud de calcul, l'un des ces nœuds doit effectuer des tâches supplémentaires, telles que l'enregistrement de points de contrôle et l'écriture de fichiers récapitulatifs sur TensorBoard. Cette machine est appelée "chef". Il n'existe qu'un nœud de calcul chef. Ainsi, le nombre de vos nœuds de calcul pour le pool de nœuds de calcul 0 sera toujours 1.
Le pool de nœuds de calcul 1 est l'endroit où vous configurez les nœuds de calcul supplémentaires pour votre cluster.
Le premier dictionnaire de la liste worker_pool_specs représente le pool de nœuds de calcul 0, tandis que le deuxième dictionnaire représente le pool de nœuds de calcul 1. Dans cet exemple, les deux configurations sont identiques. Cependant, si vous souhaitez effectuer l'entraînement sur trois machines, vous devez ajouter des nœuds de calcul au pool de nœuds de calcul 1 en définissant replica_count sur 2. Si vous souhaitez ajouter des GPU, vous devez ajouter les arguments accelerator_type et accelerator_count aux paramètres machine_spec pour les deux pools de nœuds de calcul. Notez que si vous souhaitez utiliser des GPU avec MultiWorkerMirroredStrategy, le nombre de GPU doit être identique pour chaque machine du cluster. Sinon, le job échoue.
Vous devez remplacer la valeur de {PROJECT_ID} dans image_uri.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the "image_uri" with your project.
worker_pool_specs=[
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-4",
},
"container_spec": {"image_uri": "us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_distributed:multi_machine"}
},
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-4",
},
"container_spec": {"image_uri": "us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_distributed:multi_machine"}
}
]
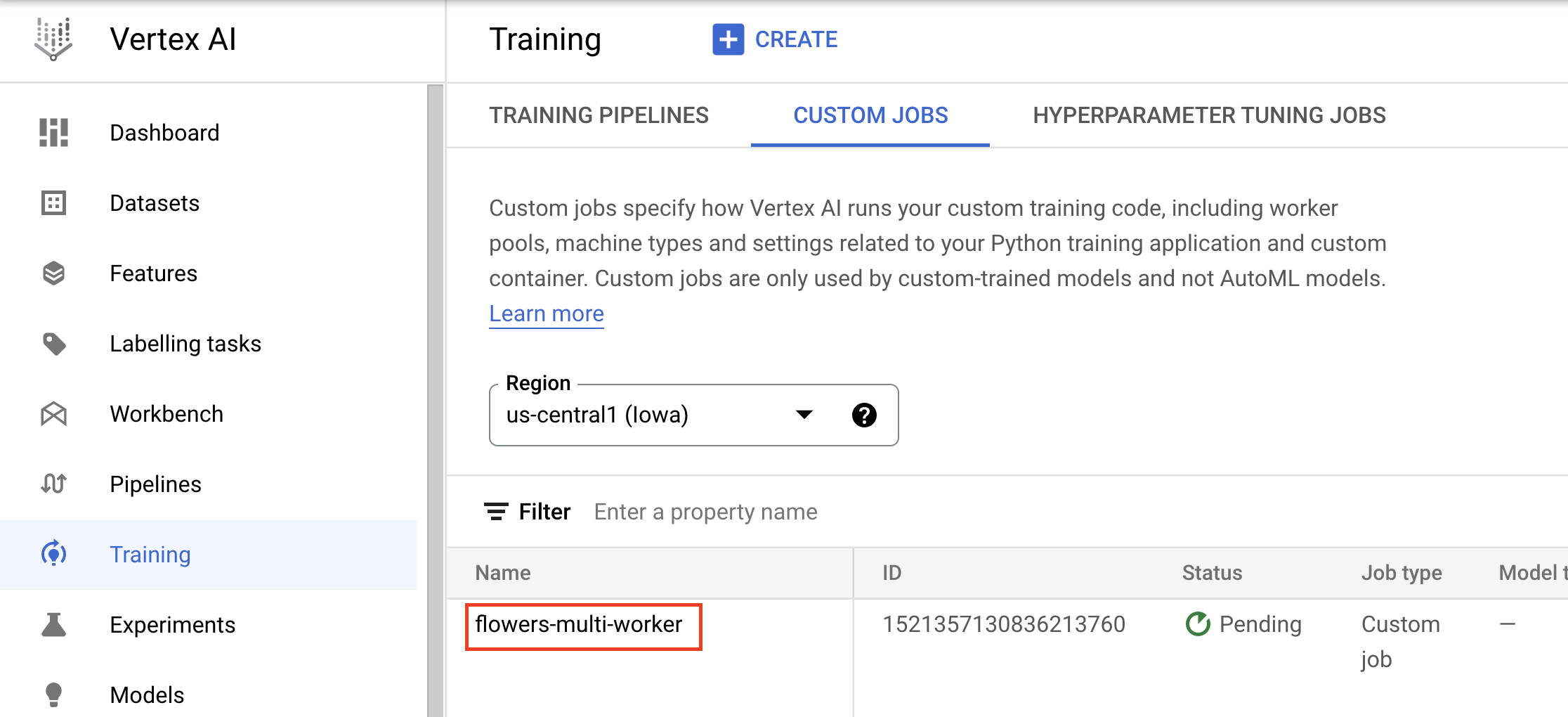
Ensuite, créez et exécutez un CustomJob, en remplaçant la valeur de {YOUR_BUCKET} dans staging_bucket par un bucket de votre projet de préproduction.
my_custom_job = aiplatform.CustomJob(display_name='flowers-multi-worker',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
my_custom_job.run()
La console affiche des informations sur la progression du job.
🎉 Félicitations ! 🎉
Vous savez désormais utiliser Vertex AI pour :
- exécuter des jobs d'entraînement distribués avec TensorFlow.
Pour en savoir plus sur les différents composants de Vertex, consultez la documentation.
7. Nettoyage
Comme le notebook est configuré pour expirer au bout de 60 minutes d'inactivité, il n'est pas nécessaire d'arrêter l'instance. Si vous souhaitez arrêter l'instance manuellement, cliquez sur le bouton "Arrêter" dans la section "Vertex AI Workbench" de la console. Si vous souhaitez supprimer le notebook définitivement, cliquez sur le bouton "Supprimer".

Pour supprimer le bucket de stockage, utilisez le menu de navigation de la console Cloud pour accéder à Stockage, sélectionnez votre bucket puis cliquez sur "Supprimer" :