1. Ringkasan
Di lab ini, Anda akan menggunakan Vertex AI untuk menjalankan tugas pelatihan terdistribusi pada Pelatihan Vertex AI menggunakan TensorFlow.
Lab ini merupakan bagian dari seri video Prototipe ke Produksi. Pastikan untuk menyelesaikan lab sebelumnya sebelum mencoba lab ini. Anda dapat menonton seri video yang disertakan untuk mempelajari lebih lanjut:
.
Yang Anda pelajari
Anda akan mempelajari cara:
- Menjalankan pelatihan terdistribusi pada satu mesin dengan beberapa GPU
- Menjalankan pelatihan terdistribusi di beberapa mesin
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $2.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI.
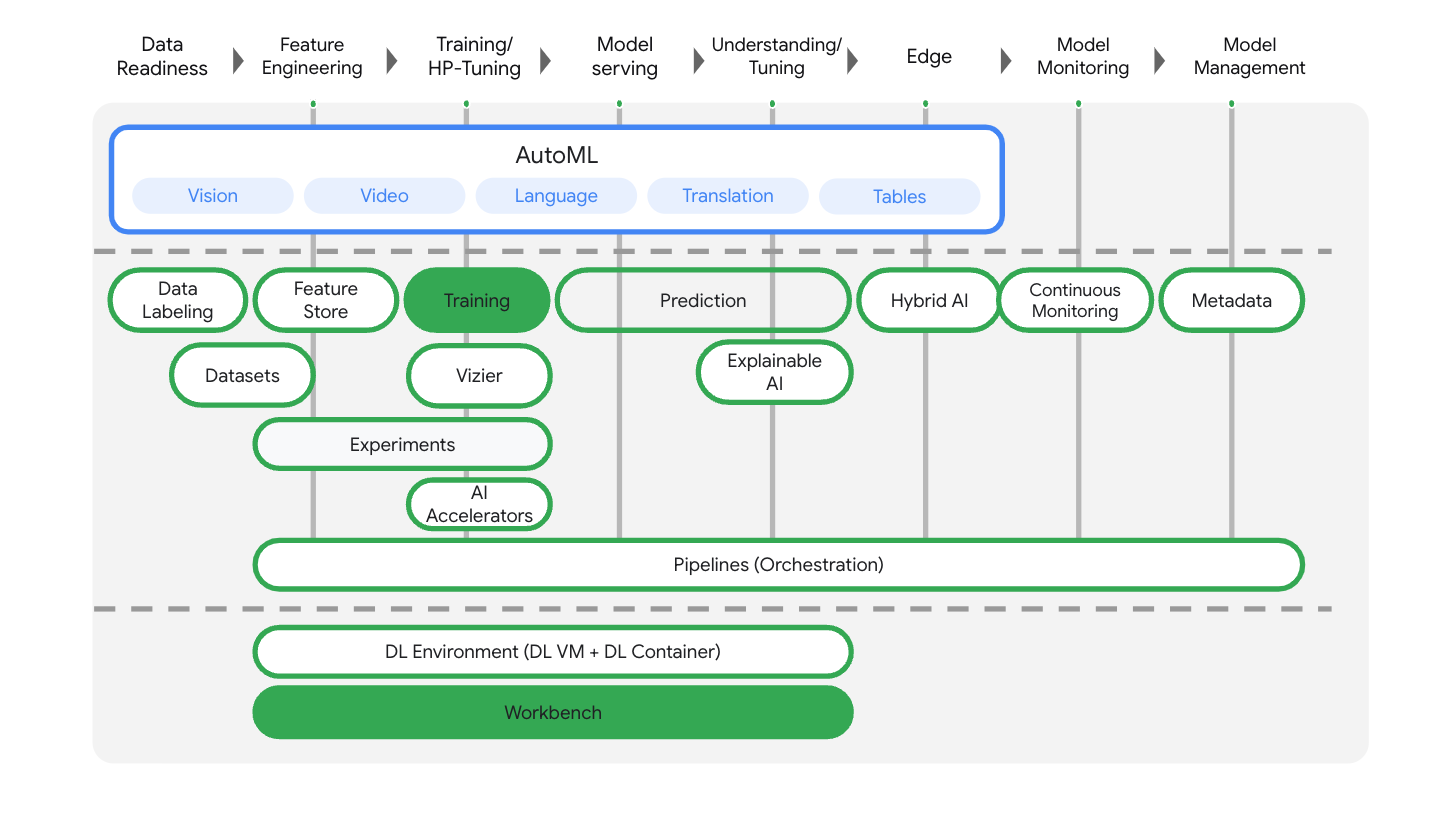
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada produk yang disorot di bawah: Pelatihan dan Workbench
3. Ringkasan pelatihan terdistribusi
Jika Anda memiliki satu GPU, TensorFlow akan menggunakan akselerator ini untuk mempercepat pelatihan model tanpa perlu melakukan upaya lain. Namun, jika Anda ingin mendapatkan peningkatan tambahan dari penggunaan beberapa GPU, Anda harus menggunakan tf.distribute, yang merupakan modul TensorFlow untuk menjalankan komputasi dalam beberapa perangkat.
Bagian pertama lab ini menggunakan tf.distribute.MirroredStrategy, yang dapat Anda tambahkan ke aplikasi pelatihan hanya dengan beberapa perubahan kode. Strategi ini akan membuat salinan model di setiap GPU pada mesin Anda. Update gradien berikutnya akan berlangsung secara sinkron. Artinya, setiap GPU menghitung penerusan maju dan mundur melalui model pada bagian data input yang berbeda. Gradien yang dihitung dari setiap bagian tersebut kemudian digabungkan di semua GPU dan dirata-ratakan dalam proses yang dikenal sebagai all-reduce. Parameter model diperbarui menggunakan gradien rata-rata ini.
Bagian opsional di akhir lab menggunakan tf.distribute.MultiWorkerMirroredStrategy, yang mirip dengan MirroredStrategy, tetapi berfungsi di beberapa mesin. Setiap mesin ini mungkin juga memiliki beberapa GPU. Misalnya, MirroredStrategy, MultiWorkerMirroredStrategy adalah strategi paralelisme data sinkron yang dapat Anda gunakan hanya dengan beberapa perubahan kode. Perbedaan utama saat beralih dari paralelisme data sinkron di satu mesin adalah bahwa gradien di akhir setiap langkah sekarang harus disinkronkan di semua GPU dalam mesin dan di semua mesin dalam cluster.
Anda tidak perlu mengetahui detailnya untuk menyelesaikan lab ini, tetapi jika ingin mempelajari lebih lanjut cara kerja pelatihan terdistribusi di TensorFlow, lihat video di bawah ini:
4. Menyiapkan lingkungan Anda
Selesaikan langkah-langkah di lab Melatih model kustom dengan Vertex AI untuk menyiapkan lingkungan Anda.
5. Pelatihan satu mesin, multi GPU
Anda akan mengirim tugas pelatihan terdistribusi ke Vertex AI dengan menempatkan kode aplikasi pelatihan dalam container Docker dan mengirim container ini ke Google Artifact Registry. Menggunakan pendekatan ini, Anda dapat melatih model yang di-build dengan framework apa pun.
Untuk memulai, dari menu Peluncur pada notebook Workbench yang telah Anda buat di lab sebelumnya, buka jendela terminal.

Langkah 1: Tulis kode pelatihan
Buat direktori baru bernama flowers-multi-gpu dan cd ke dalamnya:
mkdir flowers-multi-gpu
cd flowers-multi-gpu
Jalankan perintah berikut guna membuat direktori untuk kode pelatihan dan file Python tempat Anda akan menambahkan kode di bawah.
mkdir trainer
touch trainer/task.py
Sekarang Anda akan memiliki kode berikut di direktori flowers-multi-gpu/ Anda:
+ trainer/
+ task.py
Selanjutnya, buka file task.py yang baru saja Anda buat dan salin kode di bawah.
Anda harus mengganti {your-gcs-bucket} dalam BUCKET_ROOT dengan bucket Cloud Storage tempat Anda menyimpan set data bunga di Lab 1.
import tensorflow as tf
import numpy as np
import os
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model():
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
return model
def main():
# Create distribution strategy
strategy = tf.distribute.MirroredStrategy()
# Get data
GLOBAL_BATCH_SIZE = BATCH_SIZE * strategy.num_replicas_in_sync
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
# Wrap model creation and compilation within scope of strategy
with strategy.scope():
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=EPOCHS
)
model.save(f'{BUCKET_ROOT}/model_output')
if __name__ == "__main__":
main()
Sebelum Anda mem-build container, mari pelajari lebih lanjut kode tersebut. Ada beberapa komponen yang spesifik untuk penggunaan pelatihan terdistribusi.
- Dalam fungsi
main(), objekMirroredStrategydibuat. Selanjutnya, gabungkan pembuatan variabel model Anda dalam cakupan strategi. Langkah ini memberi tahu TensorFlow terkait variabel mana yang harus dicerminkan di seluruh GPU. - Ukuran tumpukan ditingkatkan skalanya menurut
num_replicas_in_sync. Penskalaan ukuran tumpukan adalah praktik terbaik saat menggunakan strategi paralelisme data sinkron di TensorFlow. Anda dapat mempelajari lebih lanjut di sini.
Langkah 2: Buat Dockerfile
Untuk menyimpan kode dalam container, Anda harus membuat Dockerfile. Dalam Dockerfile, Anda akan menyertakan semua perintah yang diperlukan untuk menjalankan image. Tindakan ini akan menginstal semua library yang diperlukan dan menyiapkan titik entri untuk kode pelatihan.
Dari Terminal Anda, buat Dockerfile kosong dalam root direktori bunga Anda:
touch Dockerfile
Sekarang Anda akan memiliki kode berikut di direktori flowers-multi-gpu/ Anda:
+ Dockerfile
+ trainer/
+ task.py
Buka Dockerfile dan salin kode berikut ke dalamnya:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Langkah 3: Bangun container
Dari Terminal Anda, jalankan perintah berikut guna menentukan variabel env untuk project Anda, pastikan untuk mengganti your-cloud-project dengan ID project Anda:
PROJECT_ID='your-cloud-project'
Buat repositori di Artifact Registry. Kita akan menggunakan repositori yang kita buat di lab pertama.
REPO_NAME='flower-app'
Tentukan variabel dengan URI image container Anda di Artifact Registry:
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image_distributed:single_machine
Mengonfigurasi Docker
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Kemudian, bangun container dengan menjalankan perintah berikut dari root direktori flowers-multi-gpu Anda:
docker build ./ -t $IMAGE_URI
Terakhir, kirim ke Artifact Registry:
docker push $IMAGE_URI
Dengan container yang dikirim ke Artifact Registry, sekarang Anda siap untuk memulai tugas pelatihan.
Langkah 4: Jalankan tugas dengan SDK
Di bagian ini, Anda akan melihat cara mengonfigurasi dan meluncurkan tugas pelatihan terdistribusi menggunakan Vertex AI Python SDK.
Dari Peluncur, buat notebook TensorFlow 2.

Impor Vertex AI SDK.
from google.cloud import aiplatform
Lalu, tentukan CustomContainerTrainingJob.
Anda harus mengganti {PROJECT_ID} dalam container_uri, dan {YOUR_BUCKET} dalam staging_bucket.
job = aiplatform.CustomContainerTrainingJob(display_name='flowers-multi-gpu',
container_uri='us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_distributed:single_machine',
staging_bucket='gs://{YOUR_BUCKET}')
Setelah tugas ditentukan, Anda dapat menjalankan tugas tersebut. Anda perlu menetapkan angka akselerator ke 2. Jika kita hanya menggunakan 1 GPU, hal ini tidak akan dianggap sebagai pelatihan terdistribusi. Pelatihan terdistribusi pada satu mesin adalah saat Anda menggunakan 2 akselerator atau lebih.
my_custom_job.run(replica_count=1,
machine_type='n1-standard-4',
accelerator_type='NVIDIA_TESLA_V100',
accelerator_count=2)
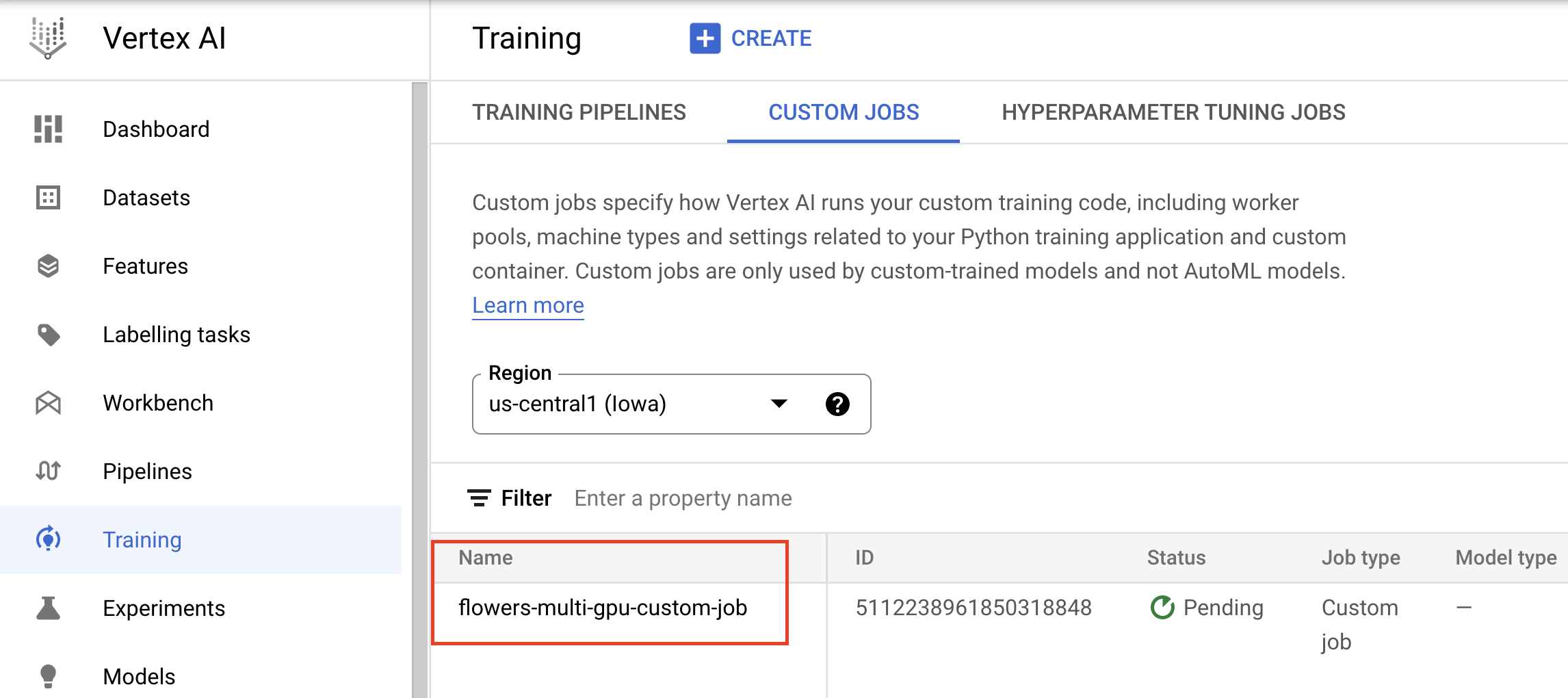
Di konsol, Anda dapat melihat progres tugas Anda.
6. [Opsional] Pelatihan multipekerja
Setelah Anda mencoba pelatihan terdistribusi pada satu mesin dengan beberapa GPU, Anda dapat meningkatkan kemampuan pelatihan terdistribusi Anda dengan pelatihan di beberapa mesin. Untuk menekan biaya, kita tidak akan menambahkan GPU apa pun ke mesin tersebut, tetapi Anda dapat bereksperimen dengan menambahkan GPU jika ingin.
Buka jendela terminal baru di instance notebook Anda:
Langkah 1: Tulis kode pelatihan
Buat direktori baru bernama flowers-multi-machine dan cd ke dalamnya:
mkdir flowers-multi-machine
cd flowers-multi-machine
Jalankan perintah berikut guna membuat direktori untuk kode pelatihan dan file Python tempat Anda akan menambahkan kode di bawah.
mkdir trainer
touch trainer/task.py
Sekarang Anda akan memiliki kode berikut di direktori flowers-multi-machine/ Anda:
+ trainer/
+ task.py
Selanjutnya, buka file task.py yang baru saja Anda buat dan salin kode di bawah.
Anda harus mengganti {your-gcs-bucket} dalam BUCKET_ROOT dengan bucket Cloud Storage tempat Anda menyimpan set data bunga di Lab 1.
import tensorflow as tf
import numpy as np
import os
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
SAVE_MODEL_DIR = f'{BUCKET_ROOT}/multi-machine-output'
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model():
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
return model
def _is_chief(task_type, task_id):
'''Helper function. Determines if machine is chief.'''
return task_type == 'chief'
def _get_temp_dir(dirpath, task_id):
'''Helper function. Gets temporary directory for saving model.'''
base_dirpath = 'workertemp_' + str(task_id)
temp_dir = os.path.join(dirpath, base_dirpath)
tf.io.gfile.makedirs(temp_dir)
return temp_dir
def write_filepath(filepath, task_type, task_id):
'''Helper function. Gets filepath to save model.'''
dirpath = os.path.dirname(filepath)
base = os.path.basename(filepath)
if not _is_chief(task_type, task_id):
dirpath = _get_temp_dir(dirpath, task_id)
return os.path.join(dirpath, base)
def main():
# Create distribution strategy
strategy = tf.distribute.MultiWorkerMirroredStrategy()
# Get data
GLOBAL_BATCH_SIZE = BATCH_SIZE * strategy.num_replicas_in_sync
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
# Wrap variable creation within strategy scope
with strategy.scope():
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=EPOCHS
)
# Determine type and task of the machine from
# the strategy cluster resolver
task_type, task_id = (strategy.cluster_resolver.task_type,
strategy.cluster_resolver.task_id)
# Based on the type and task, write to the desired model path
write_model_path = write_filepath(SAVE_MODEL_DIR, task_type, task_id)
model.save(write_model_path)
if __name__ == "__main__":
main()
Sebelum Anda mem-build container, mari pelajari lebih lanjut kode tersebut. Ada beberapa komponen dalam kode yang diperlukan agar aplikasi pelatihan Anda berfungsi dengan MultiWorkerMirroredStrategy.
- Dalam fungsi
main(), objekMultiWorkerMirroredStrategydibuat. Selanjutnya, gabungkan pembuatan variabel model Anda dalam cakupan strategi. Langkah penting ini memberi tahu TensorFlow terkait variabel mana yang harus dicerminkan di seluruh replika. - Ukuran tumpukan ditingkatkan skalanya menurut
num_replicas_in_sync. Penskalaan ukuran tumpukan adalah praktik terbaik saat menggunakan strategi paralelisme data sinkron di TensorFlow. - Proses menyimpan model Anda sedikit lebih rumit dalam kasus multipekerja karena tujuannya harus berbeda untuk setiap pekerja. Ketua pekerja akan menyimpan direktori model yang diinginkan, sedangkan pekerja lainnya akan menyimpan model ke direktori sementara. Direktori sementara ini harus unik untuk mencegah beberapa pekerja menulis ke lokasi yang sama. Proses menyimpan dapat mencakup operasi kolektif, yang artinya semua pekerja harus menyimpan, bukan hanya ketua. Fungsi
_is_chief(),_get_temp_dir(),write_filepath(), serta fungsimain(), semuanya mencakup kode boilerplate yang membantu menyimpan model.
Langkah 2: Buat Dockerfile
Untuk menyimpan kode dalam container, Anda harus membuat Dockerfile. Dalam Dockerfile, Anda akan menyertakan semua perintah yang diperlukan untuk menjalankan image. Tindakan ini akan menginstal semua library yang diperlukan dan menyiapkan titik entri untuk kode pelatihan.
Dari Terminal Anda, buat Dockerfile kosong dalam root direktori bunga Anda:
touch Dockerfile
Sekarang Anda akan memiliki kode berikut di direktori flowers-multi-machine/ Anda:
+ Dockerfile
+ trainer/
+ task.py
Buka Dockerfile dan salin kode berikut ke dalamnya:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Langkah 3: Bangun container
Dari Terminal Anda, jalankan perintah berikut guna menentukan variabel env untuk project Anda, pastikan untuk mengganti your-cloud-project dengan ID project Anda:
PROJECT_ID='your-cloud-project'
Buat repositori di Artifact Registry. Kita akan menggunakan repositori yang kita buat di lab pertama.
REPO_NAME='flower-app'
Tentukan variabel dengan URI image container Anda di Google Artifact Registry:
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image_distributed:multi_machine
Mengonfigurasi Docker
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Kemudian, bangun container dengan menjalankan perintah berikut dari root direktori flowers-multi-machine Anda:
docker build ./ -t $IMAGE_URI
Terakhir, kirim ke Artifact Registry:
docker push $IMAGE_URI
Dengan container yang dikirim ke Artifact Registry, sekarang Anda siap untuk memulai tugas pelatihan.
Langkah 4: Jalankan tugas dengan SDK
Di bagian ini, Anda akan melihat cara mengonfigurasi dan meluncurkan tugas pelatihan terdistribusi menggunakan Vertex AI Python SDK.
Dari Peluncur, buat notebook TensorFlow 2.
Impor Vertex AI SDK.
from google.cloud import aiplatform
Lalu, tentukan worker_pool_specs.
Vertex AI menyediakan 4 kumpulan pekerja untuk mendukung berbagai jenis tugas mesin.
Kumpulan pekerja 0 mengonfigurasi Utama, ketua, penjadwal, atau "master". Dalam MultiWorkerMirroredStrategy, semua mesin ditetapkan sebagai pekerja, yang merupakan mesin fisik tempat komputasi yang direplikasi dijalankan. Meskipun setiap mesin menjadi pekerja, perlu ada satu pekerja yang melakukan sedikit tugas tambahan, seperti menyimpan checkpoint dan menulis file ringkasan ke TensorBoard. Mesin ini dikenal sebagai ketua. Hanya ada satu ketua pekerja, jadi jumlah pekerja Anda untuk kumpulan Pekerja 0 akan selalu 1.
Kumpulan Pekerja 1 adalah tempat Anda mengonfigurasi pekerja tambahan untuk cluster Anda.
Kamus pertama dalam daftar worker_pool_specs mewakili kumpulan Pekerja 0, dan kamus kedua mewakili kumpulan Pekerja 1. Dalam contoh ini, dua konfigurasi bersifat identik. Namun, jika ingin melatih di 3 mesin, Anda perlu menambahkan pekerja tambahan ke kumpulan Pekerja 1 dengan menetapkan replica_count menjadi 2. Jika ingin menambahkan GPU, Anda perlu menambahkan argumen accelerator_type dan accelerator_count ke machine_spec untuk kedua kumpulan pekerja. Perhatikan bahwa jika Anda ingin menggunakan GPU dengan MultiWorkerMirroredStrategy, setiap mesin di cluster harus memiliki nomor GPU identik. Jika tidak, tugas akan gagal.
Anda perlu mengganti {PROJECT_ID} dalam image_uri.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the "image_uri" with your project.
worker_pool_specs=[
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-4",
},
"container_spec": {"image_uri": "us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_distributed:multi_machine"}
},
{
"replica_count": 1,
"machine_spec": {
"machine_type": "n1-standard-4",
},
"container_spec": {"image_uri": "us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_distributed:multi_machine"}
}
]
Selanjutnya, buat dan jalankan CustomJob, yang menggantikan {YOUR_BUCKET} dalam staging_bucket dengan bucket dalam project untuk staging.
my_custom_job = aiplatform.CustomJob(display_name='flowers-multi-worker',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
my_custom_job.run()
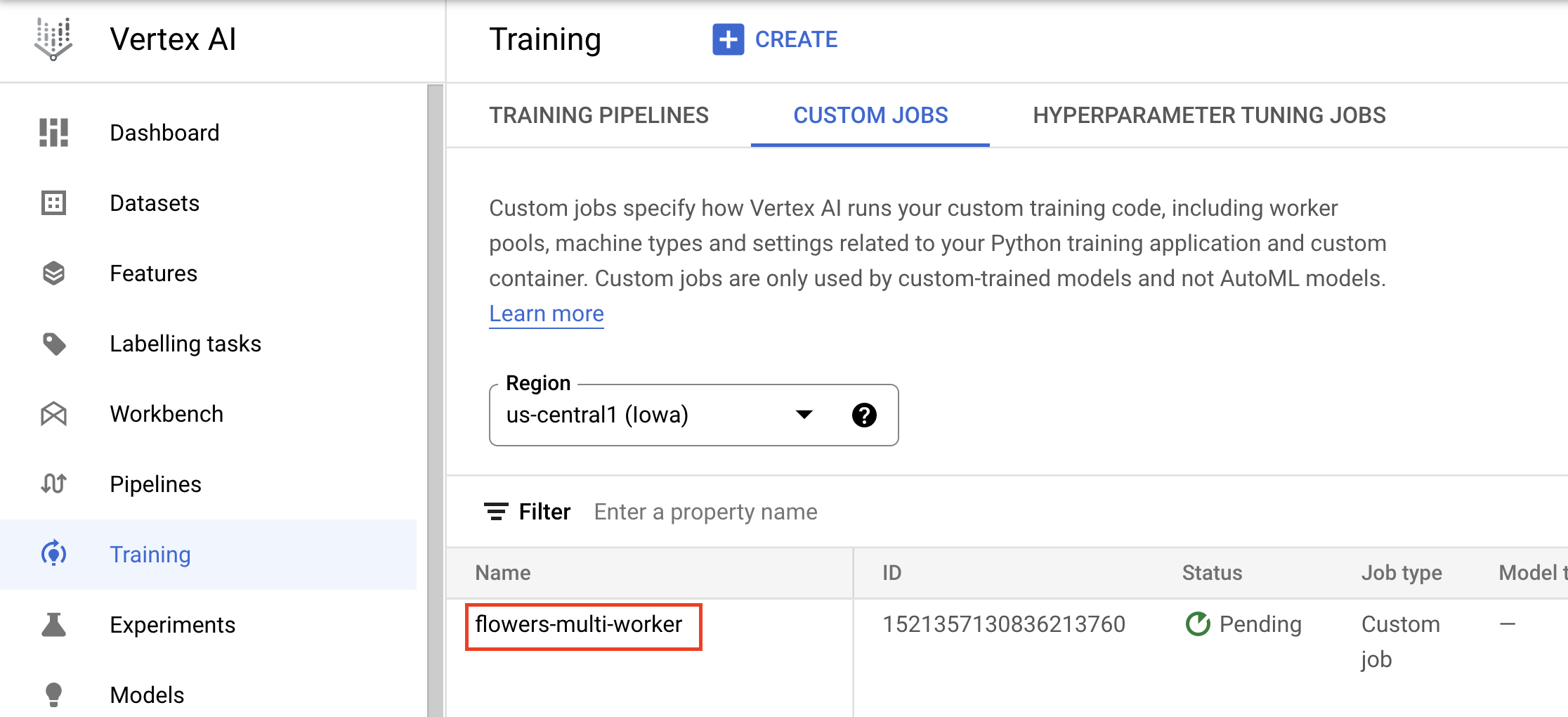
Di konsol, Anda dapat melihat progres tugas Anda.
🎉 Selamat! 🎉
Anda telah mempelajari cara menggunakan Vertex AI untuk:
- Menjalankan tugas pelatihan terdistribusi dengan TensorFlow
Untuk mempelajari lebih lanjut berbagai bagian Vertex, lihat dokumentasinya.
7. Pembersihan
Karena sebelumnya kita telah mengonfigurasi notebook agar kehabisan waktu setelah 60 menit tidak ada aktivitas, jangan khawatir untuk menonaktifkan instance-nya. Jika Anda ingin menonaktifkan instance secara manual, klik tombol Hentikan di bagian Vertex AI Workbench pada konsol. Jika Anda ingin menghapus notebook secara keseluruhan, klik tombol Hapus.

Untuk menghapus Bucket Penyimpanan, menggunakan menu Navigasi di Konsol Cloud, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus: