1. ภาพรวม
ใน Lab นี้ คุณจะได้ใช้ Vertex AI เพื่อเรียกใช้ชื่องานการปรับแต่งไฮเปอร์พารามิเตอร์ในการฝึก Vertex AI
แล็บนี้เป็นส่วนหนึ่งของวิดีโอซีรีส์ต้นแบบสู่การผลิต โปรดทำแล็บก่อนหน้าให้เสร็จก่อนที่จะลองใช้แล็บนี้ คุณดูชุดวิดีโอประกอบเพื่อดูข้อมูลเพิ่มเติมได้
.
สิ่งที่คุณจะได้เรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- แก้ไขโค้ดของแอปพลิเคชันการฝึกเพื่อการปรับแต่งไฮเปอร์พารามิเตอร์อัตโนมัติ
- กำหนดค่าและเปิดใช้งานงานการปรับแต่งไฮเปอร์พารามิเตอร์ด้วย Vertex AI Python SDK
ค่าใช้จ่ายทั้งหมดในการเรียกใช้ Lab นี้ใน Google Cloud อยู่ที่ประมาณ $1
2. ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
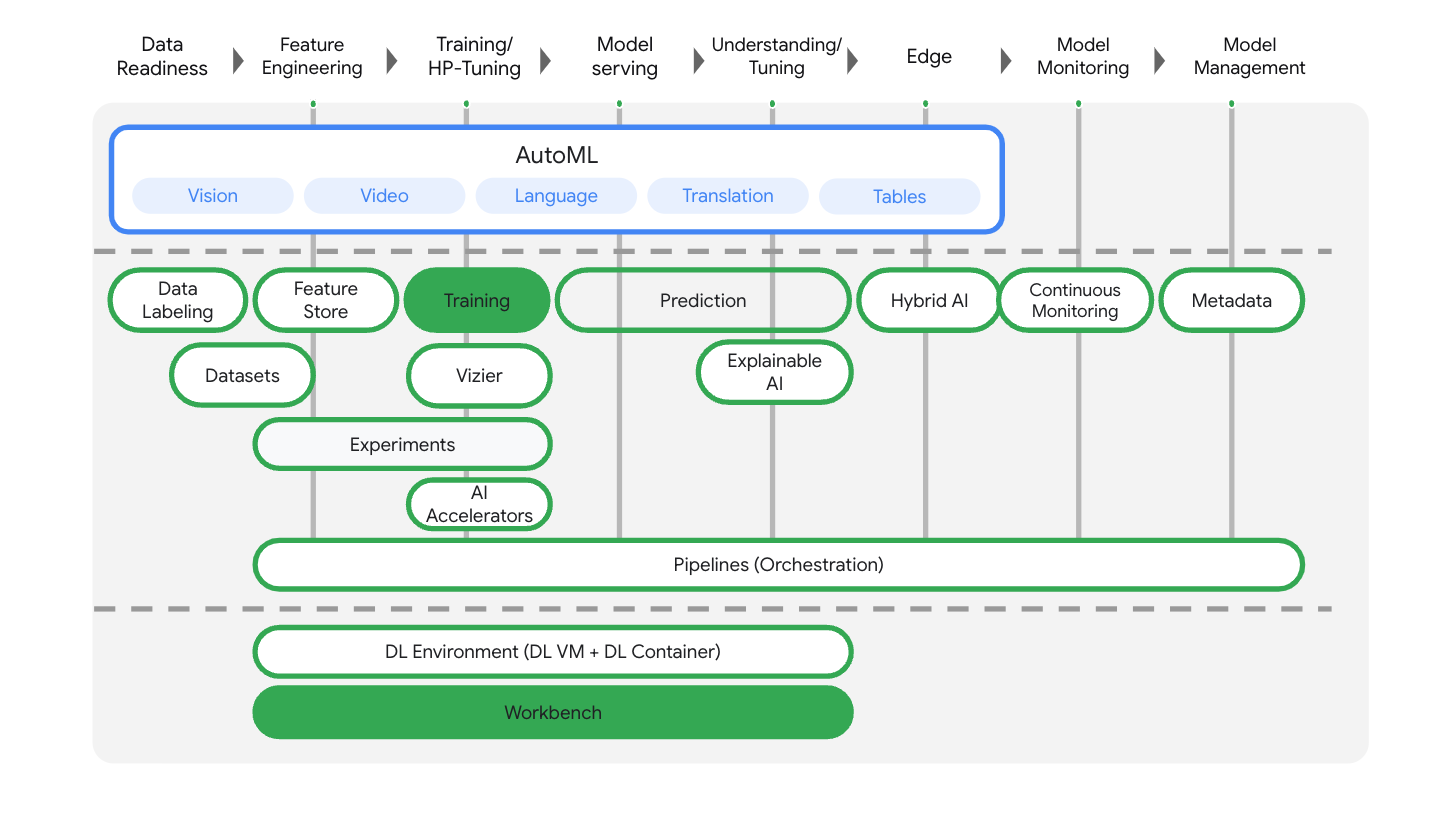
แล็บนี้ใช้ผลิตภัณฑ์ AI ใหม่ล่าสุดที่พร้อมให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้ากับประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้ โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองจะเข้าถึงได้ผ่านบริการแยกต่างหาก ข้อเสนอใหม่นี้จะรวมทั้ง 2 อย่างไว้ใน API เดียว พร้อมกับผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย
Vertex AI มีผลิตภัณฑ์มากมายที่แตกต่างกันเพื่อรองรับเวิร์กโฟลว์ ML แบบครบวงจร Lab นี้จะมุ่งเน้นที่ผลิตภัณฑ์ที่ไฮไลต์ไว้ด้านล่าง ได้แก่ Training และ Workbench
3. ตั้งค่าสภาพแวดล้อม
ทำตามขั้นตอนในแล็บการฝึกโมเดลที่กำหนดเองด้วย Vertex AI เพื่อตั้งค่าสภาพแวดล้อม
4. สร้างคอนเทนเนอร์โค้ดของแอปพลิเคชันการฝึก
คุณจะส่งงานการฝึกนี้ไปยัง Vertex AI โดยใส่โค้ดของแอปพลิเคชันการฝึกในคอนเทนเนอร์ Docker และพุชคอนเทนเนอร์นี้ไปยัง Google Artifact Registry การใช้แนวทางนี้จะช่วยให้คุณฝึกและปรับแต่งโมเดลที่สร้างด้วยเฟรมเวิร์กใดก็ได้
หากต้องการเริ่มต้น ให้เปิดหน้าต่างเทอร์มินัลจากเมนู Launcher ของ Notebook Workbench ที่คุณสร้างไว้ใน Lab ก่อนหน้า

ขั้นตอนที่ 1: เขียนโค้ดการฝึก
สร้างไดเรกทอรีใหม่ชื่อ flowers-hptune แล้วใช้คำสั่ง cd เพื่อเข้าไปในไดเรกทอรีดังกล่าว
mkdir flowers-hptune
cd flowers-hptune
เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างไดเรกทอรีสำหรับโค้ดการฝึกและไฟล์ Python ที่คุณจะเพิ่มโค้ดด้านล่าง
mkdir trainer
touch trainer/task.py
ตอนนี้คุณควรมีรายการต่อไปนี้ในไดเรกทอรี flowers-hptune/
+ trainer/
+ task.py
จากนั้นเปิดไฟล์ task.py ที่เพิ่งสร้างและคัดลอกโค้ดด้านล่าง
คุณจะต้องแทนที่ {your-gcs-bucket} ใน BUCKET_ROOT ด้วย Bucket ของ Cloud Storage ที่คุณจัดเก็บชุดข้อมูลดอกไม้ไว้ในแล็บ 1
import tensorflow as tf
import numpy as np
import os
import hypertune
import argparse
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model(num_units, learning_rate, momentum):
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(num_units, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_dataset, validation_data=validation_dataset, epochs=EPOCHS)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=EPOCHS)
if __name__ == "__main__":
main()
ก่อนที่จะสร้างคอนเทนเนอร์ เรามาดูโค้ดกันให้ลึกซึ้งยิ่งขึ้น มีคอมโพเนนต์บางอย่างที่เฉพาะเจาะจงสำหรับการใช้บริการการปรับไฮเปอร์พารามิเตอร์
- สคริปต์จะนำเข้าไลบรารี
hypertune - ฟังก์ชัน
get_args()กําหนดอาร์กิวเมนต์บรรทัดคําสั่งสําหรับไฮเปอร์พารามิเตอร์แต่ละรายการที่ต้องการปรับ ในตัวอย่างนี้ ไฮเปอร์พารามิเตอร์ที่จะได้รับการปรับคืออัตราการเรียนรู้ ค่าโมเมนตัมในเครื่องมือเพิ่มประสิทธิภาพ และจำนวนหน่วยในเลเยอร์ที่ซ่อนสุดท้ายของโมเดล แต่คุณสามารถทดลองใช้พารามิเตอร์อื่นๆ ได้ จากนั้นระบบจะใช้ค่าที่ส่งในอาร์กิวเมนต์เหล่านั้นเพื่อตั้งค่าไฮเปอร์พารามิเตอร์ที่เกี่ยวข้องในโค้ด - ที่ส่วนท้ายของฟังก์ชัน
main()จะใช้ไลบรารีhypertuneเพื่อกำหนดเมตริกที่คุณต้องการเพิ่มประสิทธิภาพ ใน TensorFlow เมธอดmodel.fitของ Keras จะแสดงผลออบเจ็กต์Historyแอตทริบิวต์History.historyคือบันทึกค่าการสูญเสียการฝึกและค่าเมตริกใน Epoch ที่ต่อเนื่องกัน หากคุณส่งข้อมูลการตรวจสอบไปยังmodel.fitแอตทริบิวต์History.historyจะรวมการสูญเสียการตรวจสอบและค่าเมตริกด้วย ตัวอย่างเช่น หากคุณฝึกโมเดลเป็นเวลา 3 Epoch ด้วยข้อมูลการตรวจสอบและระบุaccuracyเป็นเมตริก แอตทริบิวต์History.historyจะมีลักษณะคล้ายกับพจนานุกรมต่อไปนี้
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
หากต้องการให้บริการปรับแต่ง Hyperparameter ค้นพบค่าที่เพิ่มความแม่นยำในการตรวจสอบของโมเดลสูงสุด ให้กำหนดเมตริกเป็นรายการสุดท้าย (หรือ NUM_EPOCS - 1) ของval_accuracy list จากนั้นส่งเมตริกนี้ไปยังอินสแตนซ์ของ HyperTune คุณเลือกสตริงใดก็ได้สำหรับ hyperparameter_metric_tag แต่จะต้องใช้สตริงนั้นอีกครั้งในภายหลังเมื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์
ขั้นตอนที่ 2: สร้าง Dockerfile
หากต้องการสร้างคอนเทนเนอร์โค้ด คุณจะต้องสร้าง Dockerfile ใน Dockerfile คุณจะต้องใส่คำสั่งทั้งหมดที่จำเป็นในการเรียกใช้อิมเมจ โดยจะติดตั้งไลบรารีที่จำเป็นทั้งหมดและตั้งค่าจุดแรกเข้าสำหรับโค้ดการฝึก
จากเทอร์มินัล ให้สร้าง Dockerfile ว่างในรูทของไดเรกทอรี flowers-hptune
touch Dockerfile
ตอนนี้คุณควรมีรายการต่อไปนี้ในไดเรกทอรี flowers-hptune/
+ Dockerfile
+ trainer/
+ task.py
เปิด Dockerfile แล้วคัดลอกข้อมูลต่อไปนี้ลงในไฟล์ คุณจะเห็นว่าไฟล์นี้เกือบจะเหมือนกับ Dockerfile ที่เราใช้ใน Lab แรก เว้นแต่ว่าตอนนี้เราจะติดตั้งไลบรารี cloudml-hypertune
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
ขั้นตอนที่ 3: สร้างคอนเทนเนอร์
จากเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้เพื่อกำหนดตัวแปรสภาพแวดล้อมสำหรับโปรเจ็กต์ของคุณ โดยอย่าลืมแทนที่ your-cloud-project ด้วยรหัสโปรเจ็กต์ของคุณ
PROJECT_ID='your-cloud-project'
กำหนดที่เก็บใน Artifact Registry เราจะใช้ที่เก็บที่สร้างขึ้นในแล็บแรก
REPO_NAME='flower-app'
กำหนดตัวแปรด้วย URI ของอิมเมจคอนเทนเนอร์ใน Google Artifact Registry โดยทำดังนี้
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image_hptune:latest
กำหนดค่า Docker
gcloud auth configure-docker \
us-central1-docker.pkg.dev
จากนั้นสร้างคอนเทนเนอร์โดยเรียกใช้คำสั่งต่อไปนี้จากรูทของไดเรกทอรี flower-hptune
docker build ./ -t $IMAGE_URI
สุดท้าย ให้พุชไปยัง Artifact Registry โดยทำดังนี้
docker push $IMAGE_URI
เมื่อพุชคอนเทนเนอร์ไปยัง Artifact Registry แล้ว คุณก็พร้อมที่จะเริ่มงานการฝึกแล้ว
5. เรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์ด้วย SDK
ในส่วนนี้ คุณจะได้เรียนรู้วิธีกำหนดค่าและส่งงานการปรับไฮเปอร์พารามิเตอร์โดยใช้ Vertex Python API
สร้าง Notebook ของ TensorFlow 2 จากตัวเรียกใช้

นำเข้า Vertex AI SDK
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
หากต้องการเปิดใช้งานงานการปรับแต่งไฮเปอร์พารามิเตอร์ คุณต้องกำหนด worker_pool_specs ก่อน ซึ่งจะระบุประเภทเครื่องและอิมเมจ Docker ข้อกำหนดต่อไปนี้กำหนดเครื่อง 1 เครื่องที่มี NVIDIA Tesla V100 GPU 2 ตัว
คุณจะต้องแทนที่ {PROJECT_ID} ใน image_uri ด้วยโปรเจ็กต์ของคุณ
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_hptune:latest"
}
}]
จากนั้นกําหนด parameter_spec ซึ่งเป็นพจนานุกรมที่ระบุพารามิเตอร์ที่คุณต้องการเพิ่มประสิทธิภาพ คีย์พจนานุกรมคือสตริงที่คุณกําหนดให้กับอาร์กิวเมนต์บรรทัดคําสั่งสําหรับไฮเปอร์พารามิเตอร์แต่ละรายการ และค่าพจนานุกรมคือข้อกําหนดพารามิเตอร์
สำหรับไฮเปอร์พารามิเตอร์แต่ละรายการ คุณต้องกำหนดประเภทและขอบเขตของค่าที่บริการปรับแต่งจะลองใช้ ไฮเปอร์พารามิเตอร์อาจเป็นประเภท Double, Integer, Categorical หรือ Discrete หากเลือกประเภทเป็น Double หรือ Integer คุณจะต้องระบุค่าต่ำสุดและสูงสุด และหากเลือก "เชิงหมวดหมู่" หรือ "ไม่ต่อเนื่อง" คุณจะต้องระบุค่า สำหรับประเภท Double และ Integer คุณจะต้องระบุค่าการปรับขนาดด้วย ดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีเลือกขนาดที่ดีที่สุดได้ในวิดีโอนี้
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
ข้อกำหนดสุดท้ายที่ต้องกำหนดคือ metric_spec ซึ่งเป็นพจนานุกรมที่แสดงเมตริกที่จะเพิ่มประสิทธิภาพ คีย์พจนานุกรมคือ hyperparameter_metric_tag ที่คุณตั้งค่าไว้ในโค้ดของแอปพลิเคชันการฝึก และค่าคือเป้าหมายการเพิ่มประสิทธิภาพ
# Dictionary representing metric to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
เมื่อกำหนดสเปคแล้ว คุณจะสร้าง CustomJob ซึ่งเป็นสเปคทั่วไปที่จะใช้ในการเรียกใช้ชื่องานในการทดลองการปรับไฮเปอร์พารามิเตอร์แต่ละครั้ง
คุณจะต้องแทนที่ {YOUR_BUCKET} ด้วย Bucket ที่คุณสร้างขึ้นก่อนหน้านี้
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='flowers-hptune-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
จากนั้นสร้างและเรียกใช้ HyperparameterTuningJob
hp_job = aiplatform.HyperparameterTuningJob(
display_name='flowers-hptune-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
ข้อโต้แย้งบางประการที่ควรทราบมีดังนี้
- max_trial_count: คุณจะต้องกำหนดขอบเขตบนของจำนวนการทดลองที่บริการจะเรียกใช้ โดยทั่วไปแล้วการทดลองใช้ที่มากขึ้นจะให้ผลลัพธ์ที่ดีกว่า แต่จะมีจุดที่ผลลัพธ์ลดลง หลังจากนั้นการทดลองใช้เพิ่มเติมจะไม่มีผลต่อเมตริกที่คุณพยายามเพิ่มประสิทธิภาพ แนวทางปฏิบัติแนะนำคือให้เริ่มด้วยการทดลองจำนวนน้อยๆ และดูว่าไฮเปอร์พารามิเตอร์ที่เลือกมีผลมากน้อยเพียงใดก่อนที่จะเพิ่มจำนวนการทดลอง
- parallel_trial_count: หากใช้การทดลองแบบคู่ขนาน บริการจะจัดสรรคลัสเตอร์การประมวลผลการฝึกหลายรายการ การเพิ่มจำนวนการทดลองใช้แบบขนานจะช่วยลดระยะเวลาที่ใช้ในการเรียกใช้งานการปรับแต่ง Hyperparameter แต่ก็อาจลดประสิทธิภาพของงานโดยรวมได้ เนื่องจากกลยุทธ์การปรับแต่งเริ่มต้นใช้ผลลัพธ์ของการทดสอบก่อนหน้าเพื่อแจ้งการกำหนดค่าในการทดสอบครั้งต่อๆ ไป
- search_algorithm: คุณตั้งค่าอัลกอริทึมการค้นหาเป็นตาราง สุ่ม หรือค่าเริ่มต้น (ไม่มี) ได้ ตัวเลือกเริ่มต้นจะใช้การเพิ่มประสิทธิภาพแบบ Bayesian เพื่อค้นหาพื้นที่ของค่าไฮเปอร์พารามิเตอร์ที่เป็นไปได้ และเป็นอัลกอริทึมที่แนะนำ ดูข้อมูลเพิ่มเติมเกี่ยวกับอัลกอริทึมนี้ได้ที่นี่
คุณจะดูความคืบหน้าของงานได้ในคอนโซล

เมื่อการทดสอบเสร็จสิ้น คุณจะดูผลลัพธ์ของการทดสอบแต่ละครั้งและชุดค่าที่มีประสิทธิภาพดีที่สุดได้

🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI เพื่อทำสิ่งต่อไปนี้
- เรียกใช้งานการปรับแต่งไฮเปอร์พารามิเตอร์อัตโนมัติ
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex ได้ที่เอกสารประกอบ
6. ล้างข้อมูล
เนื่องจากเรากำหนดค่า Notebook ให้หมดเวลาหลังจากไม่มีการใช้งาน 60 นาที จึงไม่ต้องกังวลเรื่องการปิดอินสแตนซ์ หากต้องการปิดอินสแตนซ์ด้วยตนเอง ให้คลิกปุ่มหยุดในส่วน Vertex AI Workbench ของคอนโซล หากต้องการลบ Notebook ทั้งหมด ให้คลิกปุ่มลบ

หากต้องการลบ Storage Bucket ให้ใช้เมนูการนำทางใน Cloud Console ไปที่ Storage เลือก Bucket แล้วคลิกลบ