1. Genel Bakış
Bu laboratuvarda, Vertex AI Training'de hiperparametre ayarlama işi çalıştırmak için Vertex AI'ı kullanacaksınız.
Bu laboratuvar, Prototype to Production (Prototipten Üretime) video serisinin bir parçasıdır. Bu laboratuvarı denemeden önce önceki laboratuvarı tamamladığınızdan emin olun. Daha fazla bilgi edinmek için ilgili video serisini izleyebilirsiniz:
.
Öğrenecekleriniz
Öğrenecekleriniz:
- Otomatik hiperparametre ayarı için eğitim uygulaması kodunu değiştirme
- Vertex AI Python SDK ile hiperparametre ayarlama işini yapılandırma ve başlatma
Bu laboratuvarı Google Cloud'da çalıştırmanın toplam maliyeti yaklaşık 1 ABD dolarıdır.
2. Vertex AI'a giriş
Bu laboratuvarda, Google Cloud'da sunulan en yeni yapay zeka ürünü kullanılmaktadır. Vertex AI, Google Cloud'daki makine öğrenimi tekliflerini sorunsuz bir geliştirme deneyimi için entegre eder. Daha önce, AutoML ile eğitilmiş modeller ve özel modeller ayrı hizmetler üzerinden erişilebiliyordu. Yeni teklif, diğer yeni ürünlerle birlikte bu iki ürünü tek bir API'de birleştirir. Mevcut projeleri de Vertex AI'a taşıyabilirsiniz.
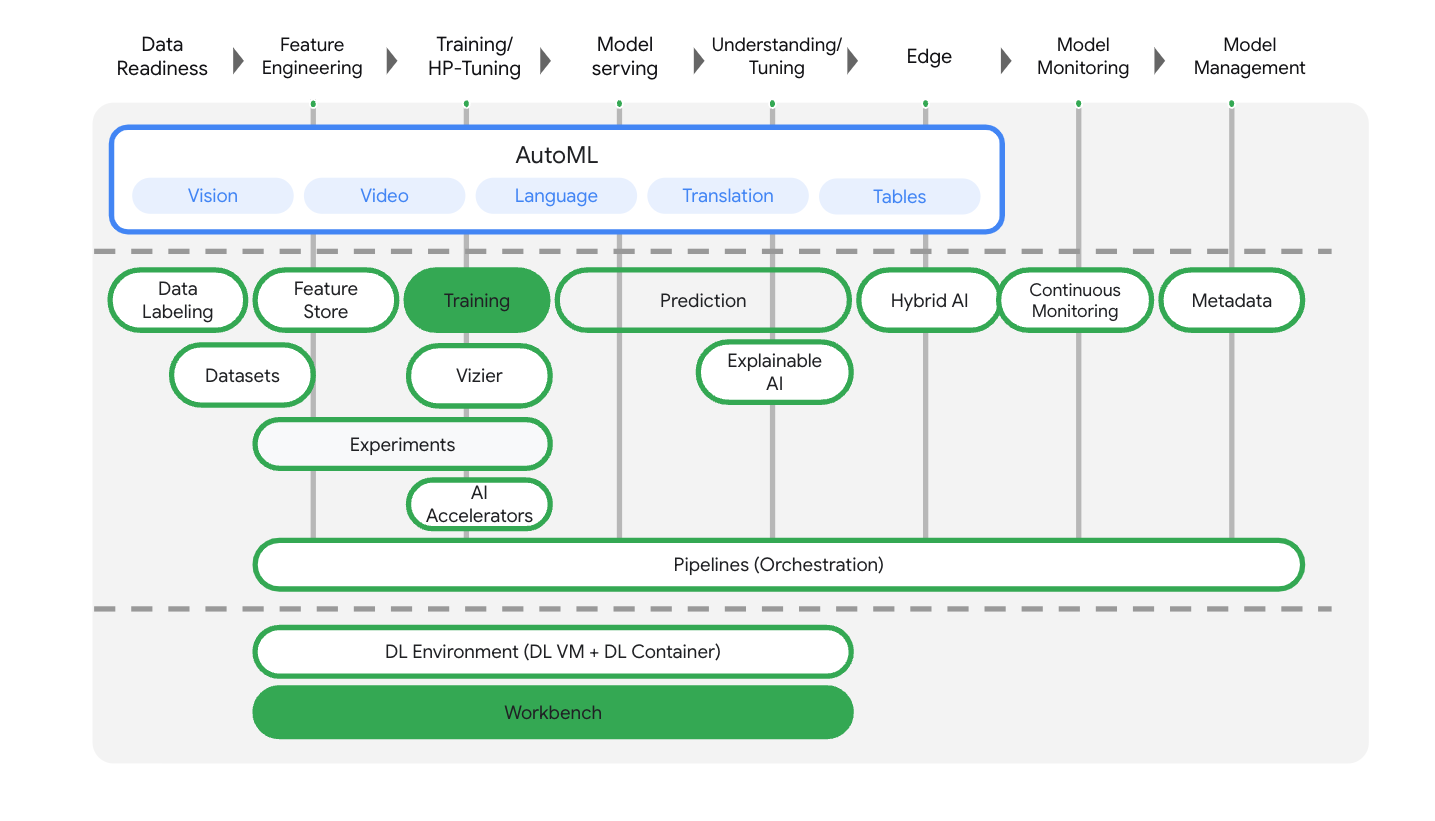
Vertex AI, uçtan uca makine öğrenimi iş akışlarını desteklemek için birçok farklı ürün içerir. Bu laboratuvarda, aşağıda vurgulanan ürünlere odaklanılacaktır: Training ve Workbench
3. Ortamınızı ayarlama
Ortamınızı ayarlamak için Vertex AI ile özel modelleri eğitme laboratuvarındaki adımları tamamlayın.
4. Eğitim uygulaması kodunu kapsayıcıya alma
Eğitim uygulama kodunuzu bir Docker container'ına yerleştirip bu container'ı Google Artifact Registry'ye aktararak bu eğitim işini Vertex AI'a gönderirsiniz. Bu yaklaşımı kullanarak herhangi bir çerçeveyle oluşturulmuş bir modeli eğitebilir ve ayarlayabilirsiniz.
Başlamak için önceki laboratuvarlarda oluşturduğunuz Workbench not defterinin Başlatıcı menüsünden bir terminal penceresi açın.

1. adım: Eğitim kodu yazın
flowers-hptune adlı yeni bir dizin oluşturun ve bu dizine gidin:
mkdir flowers-hptune
cd flowers-hptune
Eğitim kodu için bir dizin ve aşağıdaki kodu ekleyeceğiniz bir Python dosyası oluşturmak üzere aşağıdaki komutu çalıştırın.
mkdir trainer
touch trainer/task.py
flowers-hptune/ dizininizde artık şunlar olmalıdır:
+ trainer/
+ task.py
Ardından, yeni oluşturduğunuz task.py dosyasını açın ve aşağıdaki kodu kopyalayın.
BUCKET_ROOT içindeki {your-gcs-bucket} yerine, 1. Laboratuvar'da çiçek veri kümesini depoladığınız Cloud Storage paketini girmeniz gerekir.
import tensorflow as tf
import numpy as np
import os
import hypertune
import argparse
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
def get_args():
'''Parses args. Must include all hyperparameters you want to tune.'''
parser = argparse.ArgumentParser()
parser.add_argument(
'--learning_rate',
required=True,
type=float,
help='learning rate')
parser.add_argument(
'--momentum',
required=True,
type=float,
help='SGD momentum value')
parser.add_argument(
'--num_units',
required=True,
type=int,
help='number of units in last hidden layer')
args = parser.parse_args()
return args
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model(num_units, learning_rate, momentum):
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(num_units, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=momentum),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
return model
def main():
args = get_args()
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
model = create_model(args.num_units, args.learning_rate, args.momentum)
history = model.fit(train_dataset, validation_data=validation_dataset, epochs=EPOCHS)
# DEFINE METRIC
hp_metric = history.history['val_accuracy'][-1]
hpt = hypertune.HyperTune()
hpt.report_hyperparameter_tuning_metric(
hyperparameter_metric_tag='accuracy',
metric_value=hp_metric,
global_step=EPOCHS)
if __name__ == "__main__":
main()
Kapsayıcıyı oluşturmadan önce koda daha yakından bakalım. Hiperparametre ayarlama hizmetini kullanmaya özgü birkaç bileşen vardır.
- Komut dosyası,
hypertunekitaplığını içe aktarır. get_args()işlevi, ayarlamak istediğiniz her hiperparametre için bir komut satırı bağımsız değişkeni tanımlar. Bu örnekte, ayarlanacak hiperparametreler öğrenme hızı, optimize edicideki momentum değeri ve modelin son gizli katmanındaki birim sayısıdır. Ancak diğerleriyle de deneme yapabilirsiniz. Bu bağımsız değişkenlerde iletilen değer, daha sonra kodda ilgili hiperparametreyi ayarlamak için kullanılır.main()işlevinin sonunda, optimize etmek istediğiniz metriği tanımlamak içinhypertunekitaplığı kullanılır. TensorFlow'da kerasmodel.fityöntemi,Historynesnesi döndürür.History.historyözelliği, eğitim kaybı değerlerinin ve metrik değerlerinin ardışık dönemlerdeki kaydıdır. Doğrulama verilerinimodel.fitöğesine iletirsenizHistory.historyözelliği, doğrulama kaybını ve metrik değerlerini de içerir. Örneğin, doğrulama verileriyle üç dönem boyunca bir modeli eğittiyseniz ve metrik olarakaccuracysağladıysanızHistory.historyözelliği aşağıdaki sözlüğe benzer görünür.
{
"accuracy": [
0.7795261740684509,
0.9471358060836792,
0.9870933294296265
],
"loss": [
0.6340447664260864,
0.16712145507335663,
0.04546636343002319
],
"val_accuracy": [
0.3795261740684509,
0.4471358060836792,
0.4870933294296265
],
"val_loss": [
2.044623374938965,
4.100203514099121,
3.0728273391723633
]
Hiperparametre ayarlama hizmetinin, modelin doğrulama doğruluğunu en üst düzeye çıkaran değerleri bulmasını istiyorsanız metriği val_accuracy listesinin son girişi (veya NUM_EPOCS - 1) olarak tanımlarsınız. Ardından, bu metriği HyperTune örneğine iletin. hyperparameter_metric_tag için istediğiniz dizeyi seçebilirsiniz ancak hiperparametre ayarlama işini başlattığınızda bu dizeyi tekrar kullanmanız gerekir.
2. adım: Dockerfile oluşturun
Kodunuzu kapsüllemek için bir Dockerfile oluşturmanız gerekir. Dockerfile'da, görüntüyü çalıştırmak için gereken tüm komutları eklersiniz. Bu işlem, gerekli tüm kitaplıkları yükler ve eğitim kodu için giriş noktasını ayarlar.
Terminalinizden flowers-hptune dizininizin kök kısmında boş bir Dockerfile oluşturun:
touch Dockerfile
flowers-hptune/ dizininizde artık şunlar olmalıdır:
+ Dockerfile
+ trainer/
+ task.py
Dockerfile'ı açın ve aşağıdakileri kopyalayıp içine yapıştırın. Bu dosyanın, ilk laboratuvarda kullandığımız Dockerfile ile neredeyse aynı olduğunu fark edeceksiniz. Tek fark, artık cloudml-hypertune kitaplığını yüklüyor olmamızdır.
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Installs hypertune library
RUN pip install cloudml-hypertune
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
3. adım: Kapsayıcıyı oluşturun
Terminalinizde, projeniz için bir ortam değişkeni tanımlamak üzere aşağıdakileri çalıştırın. your-cloud-project yerine projenizin kimliğini yazdığınızdan emin olun:
PROJECT_ID='your-cloud-project'
Artifact Registry'de bir depo tanımlayın. İlk laboratuvarda oluşturduğumuz depoyu kullanacağız.
REPO_NAME='flower-app'
Google Artifact Registry'deki container görüntünüzün URI'siyle bir değişken tanımlayın:
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image_hptune:latest
Docker'ı yapılandırma
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Ardından, flower-hptune dizininizin kökünden aşağıdaki komutu çalıştırarak kapsayıcıyı oluşturun:
docker build ./ -t $IMAGE_URI
Son olarak, Artifact Registry'ye aktarın:
docker push $IMAGE_URI
Kapsayıcı Artifact Registry'ye aktarıldığına göre artık eğitim işini başlatmaya hazırsınız.
5. SDK ile hiperparametre ayarlama işi çalıştırma
Bu bölümde, Vertex Python API'yi kullanarak hiperparametre ayarlama işini nasıl yapılandıracağınızı ve göndereceğinizi öğreneceksiniz.
Başlatıcı'dan TensorFlow 2 not defteri oluşturun.

Vertex AI SDK'yı içe aktarın.
from google.cloud import aiplatform
from google.cloud.aiplatform import hyperparameter_tuning as hpt
Hiperparametre ayarlama işini başlatmak için önce makine türünü ve Docker görüntüsünü belirten worker_pool_specs tanımlamanız gerekir. Aşağıdaki spesifikasyon, iki NVIDIA Tesla V100 GPU'ya sahip bir makineyi tanımlar.
image_uri içindeki {PROJECT_ID} yerine projenizi yazmanız gerekir.
# The spec of the worker pools including machine type and Docker image
# Be sure to replace PROJECT_ID in the `image_uri` with your project.
worker_pool_specs = [{
"machine_spec": {
"machine_type": "n1-standard-4",
"accelerator_type": "NVIDIA_TESLA_V100",
"accelerator_count": 1
},
"replica_count": 1,
"container_spec": {
"image_uri": "us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image_hptune:latest"
}
}]
Ardından, optimize etmek istediğiniz parametreleri belirten bir sözlük olan parameter_spec değerini tanımlayın. Sözlük anahtarı, her hiperparametre için komut satırı bağımsız değişkenine atadığınız dizedir. Sözlük değeri ise parametre spesifikasyonudur.
Her hiperparametre için Tür'ü ve ayarlama hizmetinin deneyeceği değerlerin sınırlarını tanımlamanız gerekir. Hiperparametreler; Double, Integer, Categorical veya Discrete türünde olabilir. Çift veya Tam Sayı türünü seçerseniz minimum ve maksimum değer sağlamanız gerekir. Kategorik veya Ayrı seçeneğini belirlerseniz değerleri sağlamanız gerekir. Çift ve Tam Sayı türleri için ölçekleme değerini de sağlamanız gerekir. En iyi ölçeği seçme hakkında daha fazla bilgiyi bu videoda bulabilirsiniz.
# Dictionary representing parameters to optimize.
# The dictionary key is the parameter_id, which is passed into your training
# job as a command line argument,
# And the dictionary value is the parameter specification of the metric.
parameter_spec = {
"learning_rate": hpt.DoubleParameterSpec(min=0.001, max=1, scale="log"),
"momentum": hpt.DoubleParameterSpec(min=0, max=1, scale="linear"),
"num_units": hpt.DiscreteParameterSpec(values=[64, 128, 512], scale=None)
}
Tanımlanacak son özellik, optimize edilecek metriği temsil eden bir sözlük olan metric_spec'dır. Sözlük anahtarı, eğitim uygulama kodunuzda ayarladığınız hyperparameter_metric_tag, değer ise optimizasyon hedefidir.
# Dictionary representing metric to optimize.
# The dictionary key is the metric_id, which is reported by your training job,
# And the dictionary value is the optimization goal of the metric.
metric_spec={'accuracy':'maximize'}
Özellikler tanımlandıktan sonra, işinizi her bir hiperparametre ayarlama denemesinde çalıştırmak için kullanılacak ortak özellik olan bir CustomJob oluşturursunuz.
{YOUR_BUCKET} ifadesini daha önce oluşturduğunuz paketle değiştirmeniz gerekir.
# Replace YOUR_BUCKET
my_custom_job = aiplatform.CustomJob(display_name='flowers-hptune-job',
worker_pool_specs=worker_pool_specs,
staging_bucket='gs://{YOUR_BUCKET}')
Ardından, HyperparameterTuningJob oluşturup çalıştırın.
hp_job = aiplatform.HyperparameterTuningJob(
display_name='flowers-hptune-job',
custom_job=my_custom_job,
metric_spec=metric_spec,
parameter_spec=parameter_spec,
max_trial_count=15,
parallel_trial_count=3)
hp_job.run()
Dikkat edilmesi gereken birkaç nokta vardır:
- max_trial_count: Hizmetin çalıştıracağı deneme sayısına bir üst sınır koymanız gerekir. Daha fazla deneme genellikle daha iyi sonuçlar verir ancak ek denemelerin, optimize etmeye çalıştığınız metrik üzerinde çok az etkisi olacağı veya hiç etkisi olmayacağı bir nokta vardır. Daha az sayıda denemeyle başlayıp ölçeği büyütmeden önce seçtiğiniz hiperparametrelerin ne kadar etkili olduğunu anlamak en iyi uygulamadır.
- parallel_trial_count: Paralel denemeler kullanıyorsanız hizmet, birden fazla eğitim işleme kümesi sağlar. Paralel deneme sayısını artırmak, hiperparametre ince ayarı işinin çalışması için gereken süreyi azaltır ancak işin genel etkinliğini düşürebilir. Bunun nedeni, varsayılan ayarlama stratejisinin sonraki denemelerde değer ataması hakkında bilgi vermek için önceki denemelerin sonuçlarını kullanmasıdır.
- search_algorithm: Arama algoritmasını ızgara, rastgele veya varsayılan (Yok) olarak ayarlayabilirsiniz. Varsayılan seçenek, olası hiperparametre değerleri alanında arama yapmak için Bayes optimizasyonunu uygular ve önerilen algoritmadır. Bu algoritma hakkında daha fazla bilgiyi buradan edinebilirsiniz.
Konsolda işinizin ilerleme durumunu görebilirsiniz.

İşlem tamamlandığında her denemenin sonuçlarını ve hangi değer grubunun en iyi performansı gösterdiğini görebilirsiniz.

🎉 Tebrikler! 🎉
Vertex AI'ı kullanarak şunları yapmayı öğrendiniz:
- Otomatik hiperparametre ayarlama işi çalıştırma
Vertex'in farklı bölümleri hakkında daha fazla bilgi edinmek için belgelere göz atın.
6. Temizleme
Not defterini 60 dakika boşta kaldıktan sonra zaman aşımına uğrayacak şekilde yapılandırdığımız için örneği kapatmamız gerekmez. Örneği manuel olarak kapatmak istiyorsanız konsolun Vertex AI Workbench bölümündeki Durdur düğmesini tıklayın. Not defterini tamamen silmek isterseniz Sil düğmesini tıklayın.

Cloud Console'unuzdaki gezinme menüsünü kullanarak depolama paketini silmek için Storage'a gidin, paketinizi seçin ve Sil'i tıklayın: