
1. Обзор
В этой лабораторной работе вы используете Vertex AI для выполнения пользовательского задания по обучению.
Эта лабораторная работа является частью видеосерии «От прототипа к производству» . Вы создадите модель классификации изображений, используя набор данных Flowers . Для получения дополнительной информации вы можете посмотреть прилагаемое видео:
.
Чему вы научитесь
Вы научитесь:
- Создайте управляемый блокнот Vertex AI Workbench.
- Настройте и запустите пользовательское задание обучения из пользовательского интерфейса Vertex AI.
- Настройте и запустите пользовательское задание обучения с помощью Python SDK от Vertex AI.
Общая стоимость запуска этой лабораторной работы в Google Cloud составляет около 1 доллара .
2. Введение в Vertex AI
В этой лабораторной работе используется новейший продукт для искусственного интеллекта, доступный в Google Cloud. Vertex AI интегрирует предложения машинного обучения в Google Cloud в единый процесс разработки. Ранее модели, обученные с помощью AutoML, и пользовательские модели были доступны через отдельные сервисы. Новое предложение объединяет оба варианта в единый API, а также включает другие новые продукты. Вы также можете перенести существующие проекты в Vertex AI.
Vertex AI предлагает множество различных продуктов для поддержки комплексных рабочих процессов машинного обучения. В этой лабораторной работе мы сосредоточимся на продуктах, перечисленных ниже: Training и Workbench.

3. Настройте свою среду.
Для выполнения этого практического задания вам потребуется проект Google Cloud Platform с включенной оплатой. Чтобы создать проект, следуйте инструкциям здесь .
Шаг 1: Включите API Compute Engine.
Перейдите в раздел Compute Engine и выберите «Включить», если эта функция еще не включена.
Шаг 2: Включите API реестра артефактов.
Перейдите в раздел «Реестр артефактов» и выберите «Включить», если эта опция еще не включена. Это позволит создать контейнер для вашей пользовательской задачи обучения.
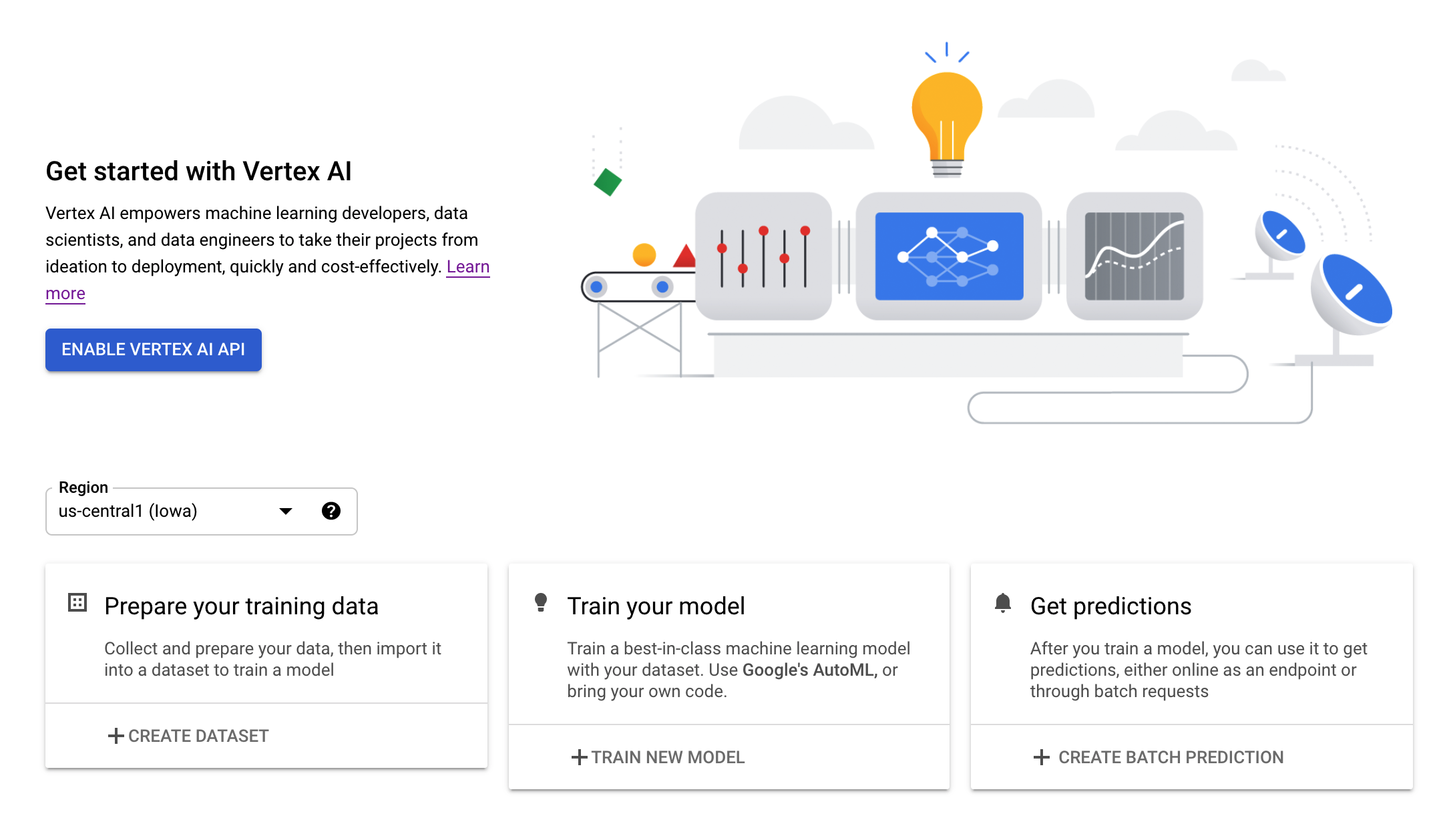
Шаг 3: Включите API Vertex AI
Перейдите в раздел Vertex AI в вашей облачной консоли и нажмите «Включить API Vertex AI» .
Шаг 4: Создайте экземпляр Vertex AI Workbench.
В разделе Vertex AI вашей облачной консоли нажмите на Workbench:

Включите API для блокнотов, если он еще не включен.

После включения нажмите «УПРАВЛЯЕМЫЕ ЗАПИСНЫЕ КНИЖКИ» :

Затем выберите «Создать новый блокнот» .
Присвойте своему блокноту имя, а в разделе «Разрешения» выберите «Учетная запись службы».

Выберите «Расширенные настройки» .
В разделе «Безопасность» выберите «Включить терминал», если он еще не включен.

Все остальные расширенные настройки можно оставить без изменений.
Далее нажмите «Создать» . Создание экземпляра займет несколько минут.
После создания экземпляра выберите «ОТКРЫТЬ JUPYTERLAB» .

4. Контейнеризация кода обучающего приложения
Для отправки задания на обучение в Vertex AI вам потребуется поместить код вашего обучающего приложения в контейнер Docker и загрузить этот контейнер в Google Artifact Registry . Используя этот подход, вы можете обучить модель, созданную с помощью любого фреймворка.
Для начала откройте окно Терминала в вашем ноутбуке из меню «Запуск»:

Шаг 1: Создайте сегмент облачного хранилища.
В этой задаче по обучению вам нужно будет экспортировать обученную модель TensorFlow в хранилище Cloud Storage. Вы также будете хранить данные для обучения в хранилище Cloud Storage.
В терминале выполните следующую команду, чтобы определить переменную окружения для вашего проекта, заменив your-cloud-project на идентификатор вашего проекта:
PROJECT_ID='your-cloud-project'
Далее выполните в терминале следующую команду, чтобы создать новый бакет в вашем проекте.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Шаг 2: Скопируйте данные в хранилище Cloud Storage.
Нам нужно загрузить наш набор данных о цветах в Cloud Storage. В демонстрационных целях сначала загрузите набор данных в этот экземпляр Workbench, а затем скопируйте его в хранилище (bucket).
Скачайте и распакуйте архив.
wget https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
tar xvzf flower_photos.tgz
Затем скопируйте его в только что созданный вами бакет. Мы добавляем параметр -r, потому что хотим скопировать всю директорию целиком, и -m для выполнения многопроцессорного копирования, что ускорит процесс.
gsutil -m cp -r flower_photos $BUCKET
Шаг 3: Напишите код для обучения.
Создайте новую директорию с именем flowers и перейдите в неё с помощью команды cd:
mkdir flowers
cd flowers
Выполните следующую команду, чтобы создать директорию для кода обучения и файл Python, куда вы добавите этот код.
mkdir trainer
touch trainer/task.py
Теперь в папке flowers/ у вас должно быть следующее:
+ trainer/
+ task.py
Для получения более подробной информации о структуре кода вашего обучающего приложения ознакомьтесь с документацией.
Далее откройте только что созданный файл task.py и скопируйте приведенный ниже код.
Вам нужно заменить {your-gcs-bucket} на имя созданного вами хранилища Cloud Storage.
С помощью инструмента Cloud Storage FUSE обучающие задачи на платформе Vertex AI Training могут получать доступ к данным в Cloud Storage в виде файлов в локальной файловой системе. При запуске пользовательской обучающей задачи она видит каталог /gcs , содержащий все ваши сегменты Cloud Storage в качестве подкаталогов. Именно поэтому пути к данным в коде обучения начинаются с /gcs .
import tensorflow as tf
import numpy as np
import os
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model():
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
return model
# CREATE DATASETS
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
# CREATE/COMPILE MODEL
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# TRAIN MODEL
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=EPOCHS
)
# SAVE MODEL
model.save(f'{BUCKET_ROOT}/model_output')
Шаг 4: Создайте Dockerfile.
Для контейнеризации вашего кода вам потребуется создать Dockerfile. В Dockerfile вы укажете все команды, необходимые для запуска образа. Он установит все необходимые библиотеки и настроит точку входа для кода обучения.
В терминале создайте пустой Dockerfile в корневом каталоге вашего проекта flowers:
touch Dockerfile
Теперь в папке flowers/ у вас должно быть следующее:
+ Dockerfile
+ trainer/
+ task.py
Откройте Dockerfile и скопируйте в него следующее:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Давайте рассмотрим команды в этом файле.
Команда FROM указывает базовый образ, который является родительским образом, на основе которого будет создан создаваемый вами образ. В качестве базового образа вы будете использовать образ Docker Deep Learning Container TensorFlow Enterprise 2.8 GPU . Контейнеры глубокого обучения в Google Cloud поставляются со многими распространенными фреймворками для машинного обучения и анализа данных, предварительно установленными.
Команда WORKDIR указывает каталог на образе, в котором выполняются последующие инструкции.
Команда COPY копирует код обучения в образ Docker. Обратите внимание, что в этом примере у нас в каталоге trainer находится только один файл Python, но в более реалистичном примере у вас, вероятно, будет больше файлов. Возможно, один с именем data.py , который обрабатывает предварительную обработку данных, и один с именем model.py , который содержит только код модели и т. д. Для более сложного кода обучения ознакомьтесь с документацией Python по упаковке проектов Python.
Если вам нужно добавить какие-либо дополнительные библиотеки, вы можете использовать команду RUN для установки pip (например: RUN pip install -r requirements.txt ). Но для нашего примера нам ничего дополнительного не нужно.
Наконец, команда ENTRYPOINT устанавливает точку входа для запуска программы обучения. Именно она будет выполняться при запуске нашей задачи обучения. В нашем случае это выполнение файла task.py
Подробнее о написании Docker-файлов для обучения Vertex AI можно узнать здесь.
Шаг 4: Создайте контейнер
В терминале вашего блокнота Workbench выполните следующую команду, чтобы определить переменную окружения для вашего проекта, обязательно заменив your-cloud-project на идентификатор вашего проекта:
PROJECT_ID='your-cloud-project'
Создайте репозиторий в реестре артефактов.
REPO_NAME='flower-app'
gcloud artifacts repositories create $REPO_NAME --repository-format=docker \
--location=us-central1 --description="Docker repository"
Создайте переменную с URI вашего образа контейнера в реестре артефактов Google:
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image:latest
Настройка Docker
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Затем соберите контейнер, выполнив следующую команду из корневой директории вашего каталога flower :
docker build ./ -t $IMAGE_URI
Наконец, отправьте его в Реестр артефактов:
docker push $IMAGE_URI
После загрузки контейнера в реестр артефактов вы готовы приступить к обучению.
5. Запустите пользовательское задание обучения на Vertex AI.
В этой лабораторной работе используется пользовательское обучение с помощью пользовательского контейнера в Google Artifact Registry, но вы также можете запустить задачу обучения с использованием предварительно созданных контейнеров .
Для начала перейдите в раздел «Обучение» в разделе Vertex вашей облачной консоли:

Шаг 1: Настройка задания обучения
Нажмите «Создать» , чтобы ввести параметры для вашего задания по обучению.

- В разделе «Набор данных» выберите «Нет управляемого набора данных» .
- Затем выберите в качестве метода обучения «Пользовательское обучение (расширенное)» и нажмите «Продолжить» .
- Выберите «Обучить новую модель» , затем введите
flowers-model(или любое другое название вашей модели) в поле «Имя модели» . - Нажмите «Продолжить»
На этапе настройки контейнера выберите «Пользовательский контейнер» :

В первом поле ( Образ контейнера ) введите значение вашей переменной IMAGE_URI из предыдущего раздела. Оно должно быть следующим: us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image:latest , указав идентификатор вашего проекта. Оставьте остальные поля пустыми и нажмите «Продолжить» .
Чтобы пропустить шаг с гиперпараметрами, снова нажмите кнопку «Продолжить» .
Шаг 2: Настройка вычислительного кластера
Настройте пул рабочих процессов 0 следующим образом:

Шаг 6 пока пропустите, а настройку контейнера прогнозирования вы выполните в следующей лабораторной работе из этой серии.
Нажмите кнопку «НАЧАТЬ ОБУЧЕНИЕ» , чтобы запустить процесс обучения. В разделе «Обучение» вашей консоли на вкладке «КОНВЕЙЕРЫ ОБУЧЕНИЯ» вы увидите только что запущенное задание:

🎉 Поздравляем! 🎉
Вы научились использовать Vertex AI для:
- Запустите пользовательское задание обучения для кода обучения, предоставленного в пользовательском контейнере. В этом примере вы использовали модель TensorFlow, но вы можете обучить модель, созданную с помощью любой платформы, используя пользовательские или встроенные контейнеры.
Чтобы узнать больше о различных компонентах Vertex, ознакомьтесь с документацией .
6. [Необязательно] Используйте Python SDK от Vertex AI.
В предыдущем разделе было показано, как запустить задачу обучения через пользовательский интерфейс. В этом разделе вы увидите альтернативный способ отправки задачи обучения с помощью Python SDK от Vertex AI .
Вернитесь к своему экземпляру блокнота и создайте блокнот TensorFlow 2 из панели запуска:

Импортируйте Vertex AI SDK.
from google.cloud import aiplatform
Затем создайте объект CustomContainerTrainingJob . Вам нужно будет заменить {PROJECT_ID} в container_uri на имя вашего проекта, а {BUCKET} в staging_bucket на созданный вами ранее бакет.
my_job = aiplatform.CustomContainerTrainingJob(display_name='flower-sdk-job',
container_uri='us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image:latest',
staging_bucket='gs://{BUCKET}')
Затем запустите задание.
my_job.run(replica_count=1,
machine_type='n1-standard-8',
accelerator_type='NVIDIA_TESLA_V100',
accelerator_count=1)
В демонстрационных целях данная задача настроена для выполнения на более мощном компьютере, чем в предыдущем разделе. Кроме того, мы используем графический процессор (GPU). Если вы не укажете machine-type , accelerator_type или accelerator_count , задача по умолчанию будет выполняться на n1-standard-4 .
В разделе «Обучение» вашей консоли, на вкладке «ПОЛЬЗОВАТЕЛЬСКИЕ ЗАДАНИЯ», вы увидите свое задание по обучению.
7. Уборка
Поскольку управляемые Vertex AI Workbench ноутбуки имеют функцию автоматического завершения работы в режиме ожидания, нам не нужно беспокоиться о выключении экземпляра. Если вы хотите выключить экземпляр вручную, нажмите кнопку «Стоп» в разделе Vertex AI Workbench консоли. Если вы хотите полностью удалить ноутбук, нажмите кнопку «Удалить».

Чтобы удалить сегмент хранилища, воспользуйтесь меню навигации в консоли Cloud Console, перейдите в раздел «Хранилище», выберите свой сегмент и нажмите «Удалить».
