
1. סקירה כללית
בשיעור ה-Lab הזה תלמדו איך להשתמש ב-Vertex AI Workbench כדי לחקור נתונים ולאמן מודלים של ML.
מה לומדים
במאמר הזה נסביר איך:
- יצירה והגדרה של מכונת Vertex AI Workbench
- שימוש במחבר BigQuery של Vertex AI Workbench
- אימון מודל בקרנל של Vertex AI Workbench
העלות הכוללת להרצת שיעור ה-Lab הזה ב-Google Cloud היא בערך 1$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את מוצרי ה-ML ב-Google Cloud לחוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שאומנו באמצעות AutoML ולמודלים בהתאמה אישית דרך שירותים נפרדים. המוצר החדש משלב את שניהם ב-API אחד, יחד עם מוצרים חדשים אחרים. אפשר גם להעביר פרויקטים קיימים אל Vertex AI.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. ה-Lab הזה מתמקד ב-Vertex AI Workbench.
Vertex AI Workbench עוזר למשתמשים ליצור במהירות תהליכי עבודה מבוססי מחברות מקצה לקצה באמצעות שילוב עמוק עם שירותי נתונים (כמו Dataproc, Dataflow, BigQuery ו-Dataplex) ועם Vertex AI. היא מאפשרת למדעני נתונים להתחבר לשירותי נתונים של GCP, לנתח מערכי נתונים, להתנסות בטכניקות שונות של מידול, לפרוס מודלים מאומנים בסביבת ייצור ולנהל MLOps לאורך מחזור החיים של המודל.
3. סקירה כללית של תרחיש לדוגמה
בשיעור ה-Lab הזה תבחנו את מערך הנתונים London Bicycles Hire. הנתונים האלה מכילים מידע על נסיעות באופניים מתוכנית שיתוף האופניים הציבורית של לונדון מאז 2011. תתחילו בבדיקה של מערך הנתונים הזה ב-BigQuery באמצעות המחבר של BigQuery ב-Vertex AI Workbench. לאחר מכן תטענו את הנתונים ל-Jupyter Notebook באמצעות pandas ותאמנו מודל TensorFlow כדי לחזות את משך הנסיעה באופניים על סמך התאריך והמרחק של הנסיעה.
בשיעור ה-Lab הזה נעשה שימוש בשכבות לעיבוד מקדים של Keras כדי לבצע טרנספורמציה של נתוני הקלט ולהכין אותם לאימון המודל. ממשק ה-API הזה מאפשר לכם לשלב עיבוד מקדים ישירות בתרשים של מודל TensorFlow, וכך לצמצם את הסיכון להטיה באימון או בהצגת המודל. הסיבה לכך היא שממשק ה-API מבטיח שנתוני האימון ונתוני ההצגה יעברו טרנספורמציות זהות. הערה: החל מ-TensorFlow 2.6, ה-API הזה יציב. אם אתם משתמשים בגרסה ישנה יותר של TensorFlow, תצטרכו לייבא את הסמל experimental.
4. הגדרת הסביבה
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud Platform שמופעל בו חיוב. כדי ליצור פרויקט, פועלים לפי ההוראות האלה.
שלב 1: הפעלת Compute Engine API
עוברים אל Compute Engine ובוחרים באפשרות הפעלה אם הוא עדיין לא מופעל.
שלב 2: הפעלת Vertex AI API
עוברים אל הקטע Vertex AI במסוף Cloud ולוחצים על הפעלת Vertex AI API.

שלב 3: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:

מפעילים את Notebooks API אם הוא עדיין לא מופעל.

אחרי ההפעלה, לוחצים על מחברות מנוהלות:

לאחר מכן בוחרים באפשרות מחברת חדשה.

נותנים שם למחברת, ובקטע הרשאה בוחרים באפשרות חשבון שירות.

לוחצים על הגדרות מתקדמות.
בקטע אבטחה, בוחרים באפשרות 'הפעלת מסוף' אם היא עדיין לא מופעלת.

אפשר להשאיר את כל ההגדרות המתקדמות האחרות כמו שהן.
אחרי כן, לוחצים על יצירה.
אחרי שיוצרים את המופע, בוחרים באפשרות OPEN JUPYTERLAB (פתיחת JupyterLab).

5. סקירת מערך נתונים ב-BigQuery
במופע של Vertex AI Workbench, עוברים לצד ימין ולוחצים על המחבר BigQuery in Notebooks.

מחבר BigQuery מאפשר לכם לחקור בקלות מערכי נתונים של BigQuery ולהריץ עליהם שאילתות. בנוסף למערכי הנתונים בפרויקט, אפשר לעיין במערכי נתונים בפרויקטים אחרים על ידי לחיצה על הלחצן הוספת פרויקט.

בשיעור ה-Lab הזה תשתמשו בנתונים ממערכי הנתונים הציבוריים של BigQuery. גוללים למטה עד שמוצאים את מערך הנתונים london_bicycles. אפשר לראות שמערך הנתונים הזה כולל שתי טבלאות: cycle_hire ו-cycle_stations. בואו נבחן כל אחד מהם.

קודם כל, לוחצים לחיצה כפולה על הטבלה cycle_hire. הטבלה תיפתח בכרטיסייה חדשה עם הסכימה של הטבלה וגם מטא-נתונים כמו מספר השורות והגודל.

אם לוחצים על הכרטיסייה תצוגה מקדימה, אפשר לראות דוגמה של הנתונים. נריץ שאילתה פשוטה כדי לראות מהם מסלולי ההמרה הפופולריים. קודם לוחצים על הלחצן Query table.

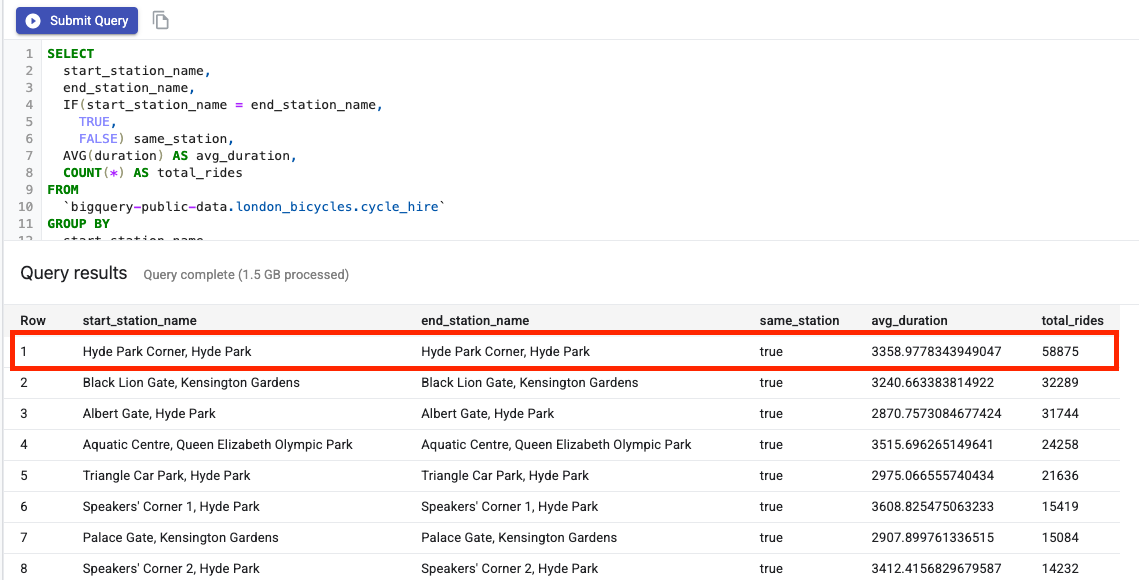
לאחר מכן, מדביקים את השאילתה הבאה בעורך ה-SQL ולוחצים על Submit Query (שליחת שאילתה).
SELECT
start_station_name,
end_station_name,
IF(start_station_name = end_station_name,
TRUE,
FALSE) same_station,
AVG(duration) AS avg_duration,
COUNT(*) AS total_rides
FROM
`bigquery-public-data.london_bicycles.cycle_hire`
GROUP BY
start_station_name,
end_station_name,
same_station
ORDER BY
total_rides DESC
מתוצאות השאילתה אפשר לראות שנסיעות באופניים אל תחנת הייד פארק קורנר וממנה היו הפופולריות ביותר.
אחר כך לוחצים לחיצה כפולה על הטבלה cycle_stations, שכוללת מידע על כל תחנה.
אנחנו רוצים להצטרף לטבלאות cycle_hire ו-cycle_stations. הטבלה cycle_stations מכילה את קווי הרוחב והאורך של כל תחנה. תשתמשו במידע הזה כדי להעריך את המרחק שנסעתם בכל נסיעה באופניים, על ידי חישוב המרחק בין תחנת ההתחלה לתחנת הסיום.
כדי לבצע את החישוב הזה, תשתמשו בפונקציות גיאוגרפיות של BigQuery. בפרט, תמירו כל מחרוזת של קו רוחב/קו אורך ל-ST_GEOGPOINT ותשתמשו בפונקציה ST_DISTANCE כדי לחשב את המרחק בקו ישר במטרים בין שתי הנקודות. הערך הזה ישמש כשרת proxy למרחק הנסיעה בכל נסיעה באופניים.
מעתיקים את השאילתה הבאה לעורך ה-SQL ולוחצים על Submit Query (שליחת שאילתה). שימו לב שיש שלושה טבלאות בתנאי ה-JOIN כי צריך לבצע JOIN לטבלה stations פעמיים כדי לקבל את קווי הרוחב והאורך של נקודת ההתחלה ונקודת הסיום של הנסיעה באופניים.
WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING
6. אימון מודל ML בגרעין TensorFlow
ל-Vertex AI Workbench יש שכבת תאימות לחישובים שמאפשרת להפעיל ליבות של TensorFlow, PySpark, R וכו', והכול מתוך מופע notebook יחיד. בשיעור ה-Lab הזה תיצרו מחברת באמצעות ליבת TensorFlow.
יצירת DataFrame
אחרי שהשאילתה מורצת, לוחצים על 'העתקת הקוד של DataFrame'. כך תוכלו להדביק קוד Python במחברת שמתחברת ללקוח BigQuery ומחלצת את הנתונים האלה כ-DataFrame של pandas.

לאחר מכן, חוזרים אל מרכז האפליקציות ויוצרים מחברת TensorFlow 2.

בתא הראשון של המחברת, מדביקים את הקוד שהועתק מעורך השאילתות. הוא אמור להיראות כך:
# The following two lines are only necessary to run once.
# Comment out otherwise for speed-up.
from google.cloud.bigquery import Client, QueryJobConfig
client = Client()
query = """WITH staging AS (
SELECT
STRUCT(
start_stn.name,
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude) AS POINT,
start_stn.docks_count,
start_stn.install_date
) AS starting,
STRUCT(
end_stn.name,
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude) AS point,
end_stn.docks_count,
end_stn.install_date
) AS ending,
STRUCT(
rental_id,
bike_id,
duration, --seconds
ST_DISTANCE(
ST_GEOGPOINT(start_stn.longitude, start_stn.latitude),
ST_GEOGPOINT(end_stn.longitude, end_stn.latitude)
) AS distance, --meters
start_date,
end_date
) AS bike
FROM `bigquery-public-data.london_bicycles.cycle_stations` AS start_stn
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_hire` as b
ON start_stn.id = b.start_station_id
LEFT JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS end_stn
ON end_stn.id = b.end_station_id
LIMIT 700000)
SELECT * from STAGING"""
job = client.query(query)
df = job.to_dataframe()
לצורך המעבדה הזו, הגבלנו את קבוצת הנתונים ל-700,000 כדי לקצר את זמן האימון. אבל אתם יכולים לשנות את השאילתה ולנסות את כל מערך הנתונים.
בשלב הבא, מייבאים את הספריות הנדרשות.
from datetime import datetime
import pandas as pd
import tensorflow as tf
מריצים את הקוד הבא כדי ליצור מסגרת נתונים מצומצמת שמכילה רק את העמודות שדרושות לחלק של ה-ML בתרגיל הזה.
values = df['bike'].values
duration = list(map(lambda a: a['duration'], values))
distance = list(map(lambda a: a['distance'], values))
dates = list(map(lambda a: a['start_date'], values))
data = pd.DataFrame(data={'duration': duration, 'distance': distance, 'start_date':dates})
data = data.dropna()
העמודה start_date היא Python datetime. במקום להשתמש ב-datetime הזה במודל ישירות, תיצרו שני מאפיינים חדשים שמציינים את היום בשבוע ואת השעה ביום שבהם התרחש הנסיעה באופניים.
data['weekday'] = data['start_date'].apply(lambda a: a.weekday())
data['hour'] = data['start_date'].apply(lambda a: a.time().hour)
data = data.drop(columns=['start_date'])
לבסוף, ממירים את עמודת משך הזמן משניות לדקות כדי שיהיה קל יותר להבין את הנתונים
data['duration'] = data['duration'].apply(lambda x:float(x / 60))
בודקים את כמה השורות הראשונות של ה-DataFrame המעוצב. לכל נסיעה באופניים יש עכשיו נתונים על היום בשבוע והשעה ביום שבהם התרחשה הנסיעה, וגם על המרחק שהיה בנסיעה. על סמך המידע הזה, תנסו לחזות כמה זמן נמשכה הנסיעה.
data.head()

לפני שיוצרים את המודל ומאמנים אותו, צריך לפצל את הנתונים למערכי אימון ואימות.
# Use 80/20 train/eval split
train_size = int(len(data) * .8)
print ("Train size: %d" % train_size)
print ("Evaluation size: %d" % (len(data) - train_size))
# Split data into train and test sets
train_data = data[:train_size]
val_data = data[train_size:]
יצירת מודל TensorFlow
תצרו מודל TensorFlow באמצעות Keras Functional API. כדי לבצע עיבוד מראש של נתוני הקלט, תשתמשו ב-Keras preprocessing layers API.
פונקציה בסיסית הבאה תיצור tf.data.Dataset מ-pandas Dataframe.
def df_to_dataset(dataframe, label, shuffle=True, batch_size=32):
dataframe = dataframe.copy()
labels = dataframe.pop(label)
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
ds = ds.prefetch(batch_size)
return ds
משתמשים בפונקציה שלמעלה כדי ליצור שני tf.data.Datasets, אחד לאימון ואחד לאימות. יכול להיות שיוצגו אזהרות, אבל אפשר להתעלם מהן.
train_dataset = df_to_dataset(train_data, 'duration')
validation_dataset = df_to_dataset(val_data, 'duration')
תשתמשו בשכבות הבאות של עיבוד מקדים במודל:
- שכבת נירמול: מבצעת נירמול של תכונות הקלט לפי תכונה.
- שכבת IntegerLookup: הופכת ערכים קטגוריים של מספרים שלמים לאינדקסים של מספרים שלמים.
- שכבת CategoryEncoding: הופכת תכונות קטגוריות של מספרים שלמים לייצוגים צפופים של one-hot, multi-hot או TF-IDF.
חשוב לזכור שלא ניתן לאמן את השכבות האלה. במקום זאת, מגדירים את המצב של שכבת העיבוד המקדים על ידי חשיפתה לנתוני אימון באמצעות השיטה adapt().
הפונקציה הבאה תיצור שכבת נורמליזציה שתוכלו להשתמש בה בתכונת המרחק. תגדירו את המצב לפני התאמת המודל באמצעות השיטה adapt() בנתוני האימון. המערכת תחשב את הממוצע והשונות שישמשו לנרמול. בהמשך, כשמעבירים את מערך נתוני האימות למודל, הממוצע והשונות שחושבו על נתוני האימון ישמשו לשינוי קנה המידה של נתוני האימות.
def get_normalization_layer(name, dataset):
# Create a Normalization layer for our feature.
normalizer = tf.keras.layers.Normalization(axis=None)
# Prepare a Dataset that only yields our feature.
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the statistics of the data.
normalizer.adapt(feature_ds)
return normalizer
באופן דומה, הפונקציה הבאה יוצרת קידוד קטגוריה שבו תשתמשו בתכונות של השעה ויום השבוע.
def get_category_encoding_layer(name, dataset, dtype, max_tokens=None):
index = tf.keras.layers.IntegerLookup(max_tokens=max_tokens)
# Prepare a Dataset that only yields our feature
feature_ds = dataset.map(lambda x, y: x[name])
# Learn the set of possible values and assign them a fixed integer index.
index.adapt(feature_ds)
# Create a Discretization for our integer indices.
encoder = tf.keras.layers.CategoryEncoding(num_tokens=index.vocabulary_size())
# Apply one-hot encoding to our indices. The lambda function captures the
# layer so we can use them, or include them in the functional model later.
return lambda feature: encoder(index(feature))
לאחר מכן, יוצרים את החלק של העיבוד המקדים של המודל. קודם יוצרים tf.keras.Input שכבה לכל אחת מהתכונות.
# Create a Keras input layer for each feature
numeric_col = tf.keras.Input(shape=(1,), name='distance')
hour_col = tf.keras.Input(shape=(1,), name='hour', dtype='int64')
weekday_col = tf.keras.Input(shape=(1,), name='weekday', dtype='int64')
לאחר מכן יוצרים את שכבות הנורמליזציה והקידוד של הקטגוריות, ושומרים אותן ברשימה.
all_inputs = []
encoded_features = []
# Pass 'distance' input to normalization layer
normalization_layer = get_normalization_layer('distance', train_dataset)
encoded_numeric_col = normalization_layer(numeric_col)
all_inputs.append(numeric_col)
encoded_features.append(encoded_numeric_col)
# Pass 'hour' input to category encoding layer
encoding_layer = get_category_encoding_layer('hour', train_dataset, dtype='int64')
encoded_hour_col = encoding_layer(hour_col)
all_inputs.append(hour_col)
encoded_features.append(encoded_hour_col)
# Pass 'weekday' input to category encoding layer
encoding_layer = get_category_encoding_layer('weekday', train_dataset, dtype='int64')
encoded_weekday_col = encoding_layer(weekday_col)
all_inputs.append(weekday_col)
encoded_features.append(encoded_weekday_col)
אחרי שמגדירים את שכבות העיבוד המקדים, אפשר להגדיר את שאר המודל. תשרשרו את כל תכונות הקלט ותעבירו אותן לשכבה צפופה. שכבת הפלט היא יחידה אחת כי זו בעיית רגרסיה.
all_features = tf.keras.layers.concatenate(encoded_features)
x = tf.keras.layers.Dense(64, activation="relu")(all_features)
output = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(all_inputs, output)
לבסוף, מקמפלים את המודל.
model.compile(optimizer = tf.keras.optimizers.Adam(0.001),
loss='mean_squared_logarithmic_error')
אחרי שהגדרתם את המודל, תוכלו לראות את הארכיטקטורה
tf.keras.utils.plot_model(model, show_shapes=True, rankdir="LR")

שימו לב שהמודל הזה די מורכב בשביל מערך הנתונים הפשוט הזה. הוא מיועד למטרות הדגמה.
נריץ אימון למשך תקופה אחת רק כדי לוודא שהקוד פועל.
model.fit(train_dataset, validation_data = validation_dataset, epochs = 1)
אימון מודל באמצעות GPU
בשלב הבא, מאמנים את המודל למשך זמן ארוך יותר ומשתמשים במעבר בין החומרה כדי להאיץ את האימון. ב-Vertex AI Workbench אפשר לשנות את החומרה בלי להשבית את המכונה. אם מוסיפים את ה-GPU רק כשצריך, אפשר להקטין את העלויות.
כדי לשנות את פרופיל החומרה, לוחצים על סוג המכונה בפינה השמאלית העליונה ובוחרים באפשרות שינוי החומרה.

בוחרים באפשרות 'צירוף GPU' ובוחרים ב-GPU מסוג NVIDIA T4 Tensor Core.

הגדרת החומרה תימשך כחמש דקות. אחרי שהתהליך יסתיים, נאמן את המודל קצת יותר זמן. תשימו לב שכל תקופה לוקחת עכשיו פחות זמן.
model.fit(train_dataset, validation_data = validation_dataset, epochs = 5)
🎉 איזה כיף! 🎉
למדתם איך להשתמש ב-Vertex AI Workbench כדי:
- סקירת הנתונים ב-BigQuery
- שימוש בלקוח BigQuery לטעינת נתונים ב-Python
- אימון מודל TensorFlow עם שכבות עיבוד מראש של Keras ו-GPU
מידע נוסף על חלקים שונים ב-Vertex AI זמין בתיעוד.
7. הסרת המשאבים
הגדרנו את מחברת ה-Jupyter כך שתפסיק לפעול אחרי 60 דקות של חוסר פעילות, ולכן אין צורך לדאוג להשבתת המופע. כדי לכבות את המופע באופן ידני, לוחצים על הלחצן Stop (עצירה) בקטע Vertex AI Workbench במסוף. כדי למחוק את ה-Notebook לגמרי, לוחצים על לחצן המחיקה.
